这里写目录标题
- 贝叶斯公式
- 模型概率的公式
- 1/n 形式的贝叶斯公式
- 全概率公式
- 全概率公式的积分形式
- 后验推理
- 后验预测分布 posterior predictive distribution
- KL 散度
- 平均场 VI
- Bayes by Backprop 代码
- 重新参数化
贝叶斯公式
模型概率的公式
一开始看了这个 https://zhuanlan.zhihu.com/p/98756147
假设模型参数满足一个高斯分布 W ∼ N ( 0 , 1 ) W \sim N(0,1) W∼N(0,1),观测数据集 X , Y X,Y X,Y 然后他介绍了一个公式说是贝叶斯公式:
p ( W ∣ X , Y ) = p ( Y ∣ X , W ) p ( W ) p ( Y ∣ X ) p(W \vert X,Y) = \dfrac{p(Y \vert X,W)p(W)}{p(Y|X)} p(W∣X,Y)=p(Y∣X)p(Y∣X,W)p(W)
我一开始是不知道贝叶斯公式是这个,感觉跟我知道的不一样;然后我还不知道他为什么说似然是 p ( W , X ∣ Y ) p(W, X|Y) p(W,X∣Y),对先验、后验、似然的理解我是看 https://blog.csdn.net/kww_kww/article/details/52527888 的,所以我就固定死了理解右边分子上的是似然
之后看了别人的文章,也挺多看不懂,但是看到别人提了关键的一句
X 和 W 之间是相互独立的
这之后就好办了
其实我觉得贝叶斯公式本质上就是一个恒等式
p ( X , Y ) = p ( X ∣ Y ) p ( Y ) = p ( Y ∣ X ) p ( X ) p(X,Y) = p(X \vert Y)p(Y) = p(Y \vert X)p(X) p(X,Y)=p(X∣Y)p(Y)=p(Y∣X)p(X)
它的物理意义就是,两个事件同时发生的概率用两种条件概率的计算方法都是一样的
可以写:
p ( X , Y , W ) = p ( W ∣ X , Y ) p ( X , Y ) = p ( Y ∣ X , W ) p ( X , W ) p(X,Y,W) = p(W \vert X,Y)p(X,Y) = p(Y \vert X,W)p(X,W) p(X,Y,W)=p(W∣X,Y)p(X,Y)=p(Y∣X,W)p(X,W)
然后根据隐含条件,X 和 W 是互相独立的,有 P ( X , W ) = p ( X ) p ( W ) P(X,W) = p(X)p(W) P(X,W)=p(X)p(W)
有:
p ( W ∣ X , Y ) p ( X , Y ) = p ( Y ∣ X , W ) p ( X , W ) ⇒ p ( W ∣ X , Y ) p ( Y ∣ X ) p ( X ) = p ( Y ∣ X , W ) p ( X ) p ( W ) ⇒ p ( W ∣ X , Y ) p ( Y ∣ X ) = p ( Y ∣ X , W ) p ( W ) ⇒ p ( W ∣ X , Y ) = p ( Y ∣ X , W ) p ( W ) p ( Y ∣ X ) \begin{align} \notag p(W \vert X,Y)p(X,Y) &= p(Y \vert X,W)p(X,W) \\ \notag \Rightarrow p(W \vert X,Y)p(Y \vert X)p(X) &= p(Y \vert X,W)p(X)p(W) \\ \notag \Rightarrow p(W \vert X,Y)p(Y \vert X) &= p(Y \vert X,W)p(W) \\ \notag \Rightarrow p(W \vert X,Y) &= \dfrac{p(Y \vert X,W)p(W)}{p(Y|X)} \end{align} p(W∣X,Y)p(X,Y)⇒p(W∣X,Y)p(Y∣X)p(X)⇒p(W∣X,Y)p(Y∣X)⇒p(W∣X,Y)=p(Y∣X,W)p(X,W)=p(Y∣X,W)p(X)p(W)=p(Y∣X,W)p(W)=p(Y∣X)p(Y∣X,W)p(W)
似然的理解,其实就是,联合概率 = 似然 * 先验,不用纠结在公式的哪里,因为我们可以写 联合概率 = 似然1 * 先验1 = 似然2 * 先验2,所以我们根据需要的物理意义称其中一个似然为后验的时候,另外一个就叫似然就行了,就是这样
1/n 形式的贝叶斯公式
一开始我看不懂这个公式是怎么来的
p ( θ ∣ D ) = p ( D y ∣ D x , θ ) p ( θ ) ∫ θ p ( D y ∣ D x , θ ′ ) p ( θ ′ ) d θ ′ p(\theta \vert D) = \dfrac{p(D_y \vert D_x, \theta)p(\theta)}{\int_{\theta} p(D_y \vert D_x, \theta')p(\theta')\mathrm{d}\theta'} p(θ∣D)=∫θp(Dy∣Dx,θ′)p(θ′)dθ′p(Dy∣Dx,θ)p(θ)
看了这个才理解 https://www.zhihu.com/question/21134457/answer/169523403
”1/n 形式的贝叶斯公式“这个名称是我瞎起的……主要是我感觉,它的物理意义就是跟 1/n 很像
就是, p ( θ ∣ D ) p(\theta \vert D) p(θ∣D) 中的 θ \theta θ 只是一个分布,但是 θ \theta θ 可以有很多种可能,就是说他是一个自变量,然后现在如果我们给定一个 θ \theta θ,那么想要知道单独这一个 θ \theta θ 在所有可能的 θ \theta θ 中的概率,所以我们分母就是已知发生 θ ′ \theta' θ′ 然后同时也发生 D D D 的所有可能的 θ ′ \theta' θ′ 的情况的概率之和,然后分子就是单独 θ \theta θ 那一种情况的概率
全概率公式
全概率公式的积分形式
离散形式的全概率公式:
p ( A ) = ∑ i p ( A ∣ B i ) p ( B i ) p(A) = \sum_i{p(A \vert B_i)p(B_i)} p(A)=i∑p(A∣Bi)p(Bi)
积分形式:
p ( A ) = ∫ p ( A ∣ B ) p ( B ) d B p(A) = \int p(A \vert B)p(B)\mathrm{d}B p(A)=∫p(A∣B)p(B)dB
也可以写为
p ( A ) = ∫ p ( A , B ) d B p(A) = \int p(A, B)\mathrm{d}B p(A)=∫p(A,B)dB
后验推理
后验预测分布 posterior predictive distribution
后验预测分布的公式:
p ( y ∣ x , D ) = ∫ θ p ( y ∣ x , θ ′ ) p ( θ ′ ∣ D ) d θ ′ p(y \vert x, D) = \int_{\theta} p(y \vert x, \theta')p(\theta' \vert D)\mathrm{d}\theta' p(y∣x,D)=∫θp(y∣x,θ′)p(θ′∣D)dθ′
或者这个参数 θ ′ \theta' θ′ 也有人写作 W
p ( y ∣ x , D ) = ∫ p ( y ∣ x , W ) p ( W ∣ D ) d W p(y \vert x, D) = \int p(y \vert x, W)p(W \vert D)\mathrm{d}W p(y∣x,D)=∫p(y∣x,W)p(W∣D)dW
一开始不知道这个公式怎么来的
看了 https://math.stackexchange.com/questions/1606372/how-to-derive-the-posterior-predictive-distribution 才懂
他这里写的形式又不一样,好像是把 x , D x, D x,D 写成了 D D D, y y y 写成了 D ′ D' D′
p ( D ′ ∣ D ) = ∫ θ p ( D ′ ∣ θ ′ ) p ( θ ′ ∣ D ) d θ ′ p(D' \vert D) = \int_{\theta} p(D' \vert \theta')p(\theta' \vert D)\mathrm{d}\theta' p(D′∣D)=∫θp(D′∣θ′)p(θ′∣D)dθ′
这里有点让我迷惑的是, y ∣ x , D y \vert x, D y∣x,D 这个形式到底是代表着 y ∣ ( x , D ) y \vert (x, D) y∣(x,D) 还是 ( y ∣ x ) , D (y \vert x), D (y∣x),D
按照他这么写,似乎是代表着 y ∣ ( x , D ) y \vert (x, D) y∣(x,D)
假设按照他这么写
使用全概率公式
p ( A ) = ∫ p ( A , B ) d B p(A) = \int p(A, B)\mathrm{d}B p(A)=∫p(A,B)dB
得到
p ( D ′ ∣ D ) = ∫ p ( D ′ , θ ∣ D ) d θ p(D' \vert D) = \int p(D', \theta \vert D)\mathrm{d}\theta p(D′∣D)=∫p(D′,θ∣D)dθ
p ( W ∣ D ) p(W \vert D) p(W∣D) 就是我们的神经网络,所以它的解析式很难写
所以我们需要一个变分推断
KL 散度

w 是模型参数,D 是数据集,θ 是 (μ,σ),是模型参数的概率分布的参数,他现在应该是要用 θ 来近似 w,所以他这里写的是用 w|θ 来近似 w|D,w|D 我觉得应该是指的用数据集训练出来的真实的 w,w|θ 我觉得是,我们实际上不知道 w,所以我们就用 θ 表示的概率分布在计算机上代表 w
现在就是,我觉得可能是,D 数据集不依赖于模型参数 w……?因为我是从现实世界中获得数据,然后这个模型参数 w 并不是我获得 D 的原因,所以 D 不依赖于 w,但是模型参数 w 是根据 D 训练出来的,所以依赖于 D?
所以他这里才直接让 E_w(p(D)) = p(D) 了
平均场 VI
在看别人的讲座 https://www.youtube.com/watch?v=xH1mBw3tb_c&list=PLe5rNUydzV9QHe8VDStpU0o8Yp63OecdW&index=4
他有一个推导我一时间没看懂

我一开始还以为是

于是我写成

后来看到别人的推导,才觉得这个变换这里应该是先写一下积分的形式才比较好懂
https://bjlkeng.io/posts/variational-bayes-and-the-mean-field-approximation/

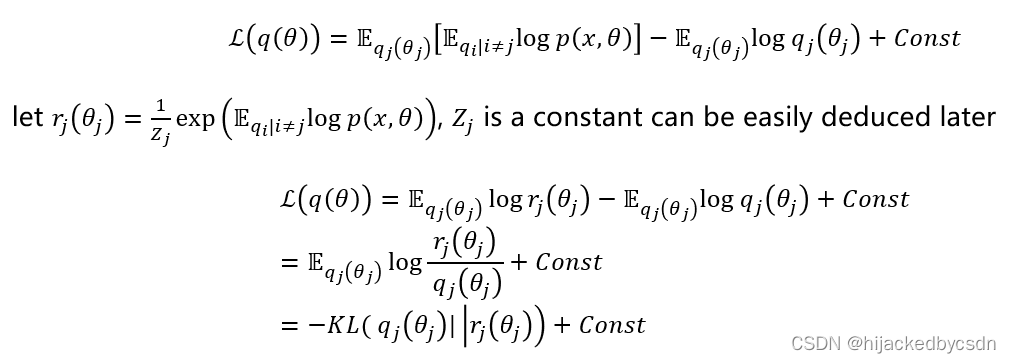
Bayes by Backprop 代码
重新参数化
一开始我看的是这个 https://www.zhihu.com/tardis/zm/art/263053978?source_id=1003
他算的损失是
loss = log_post - log_prior - log_like
对应
L = ∑ i l o g q ( w i ∣ θ i ) − ∑ i l o g P ( w i ) − ∑ i l o g p ( y i ∣ w i , x i ) \mathcal L = \sum_i \mathrm{log} q(w_i \vert \theta_i) - \sum_i \mathrm{log} P(w_i) - \sum_i \mathrm{log}p(y_i \vert w_i,x_i) L=i∑logq(wi∣θi)−i∑logP(wi)−i∑logp(yi∣wi,xi)
其中前两个的计算的方式看了一会还是可以理解的
对于 log_prior
# sample weights
w_epsilon = Normal(0, 1).sample(self.w_mu.shape)
self.w = self.w_mu + torch.log(1+torch.exp(self.w_rho)) * w_epsilon# sample bias
b_epsilon = Normal(0, 1).sample(self.b_mu.shape)
self.b = self.b_mu + torch.log(1+torch.exp(self.b_rho)) * b_epsilon# record log prior by evaluating log pdf of prior at sampled weight and bias
w_log_prior = self.prior.log_prob(self.w)
b_log_prior = self.prior.log_prob(self.b)
self.log_prior = torch.sum(w_log_prior) + torch.sum(b_log_prior)
对应到公式中 w w w 为模型参数, θ = ( μ , ρ ) \theta = (\mu, \rho) θ=(μ,ρ) 的话,首先要知道,这里的模型是啥,这里的模型是一个普通的线性层,他这里甚至都没写激活函数,就是一个线性层,线性层的参数是 w 和 b,也就是缩放和偏置,那么其实公式中的模型参数 w w w 对应到代码中就是 w 和 b,那么其实我要算 p ( w ) p(w) p(w) 的话,我其实就是要算出来代码中对应到公式中的 w w w 的值,然后再放到 prior 分布中计算对应的函数值
他这个文章没有说的是,他应该是假设了 p(w) 的分布是正态分布
然后他说明了,假设 q(w|θ) 是 θ 决定的 w 的正态分布
那么这个后验 log_post 的计算也很合理
self.w_post = Normal(self.w_mu.data, torch.log(1+torch.exp(self.w_rho)))
self.b_post = Normal(self.b_mu.data, torch.log(1+torch.exp(self.b_rho)))
self.log_post = self.w_post.log_prob(self.w).sum() + self.b_post.log_prob(self.b).sum()
最后他那个似然 log_like 的计算我有点不懂
def sample_elbo(self, input, target, samples):# we calculate the negative elbo, which will be our loss function#initialize tensorsoutputs = torch.zeros(samples, target.shape[0])log_priors = torch.zeros(samples)log_posts = torch.zeros(samples)log_likes = torch.zeros(samples)# make predictions and calculate prior, posterior, and likelihood for a given number of samplesfor i in range(samples):outputs[i] = self(input).reshape(-1) # make predictionslog_priors[i] = self.log_prior() # get log priorlog_posts[i] = self.log_post() # get log variational posteriorlog_likes[i] = Normal(outputs[i], self.noise_tol).log_prob(target.reshape(-1)).sum() # calculate the log likelihood# calculate monte carlo estimate of prior posterior and likelihoodlog_prior = log_priors.mean()log_post = log_posts.mean()log_like = log_likes.mean()
主要我是不知道为什么这个分布是均值是 y_pred 的正态分布
之后看到 https://krasserm.github.io/2019/03/14/bayesian-neural-networks/,发现这只是别人的假设而已




渗透分析)



-基础版(客户端))







)


