为了保证MQ的数据不丢失而且具备一定的高可用性,所以一般都是得将Broker部署成Master-Slave模式的,也就是—个Master Broker对应一个Slave Broker Master需要在接收到消息之后,将数据同步给Slave,这样一旦Master Broker挂了,还有Slave上有一份数据。
Master上有全量数据,但是去Master上消费,Master压力会很大,但去Slave上去读,数据不全,但是很快。
那RocketMQ如何取舍? ---》当然是两者相结合。
比如说,Master上有10w条数据,第一次先去Master上读,
-
如果Master发现她只想读第5W条数据,那就直接让他去Slave上读,下次这个消费者也去Slave上读了,
-
如果Master发现她要读第10W条数据,要读的比较新,那就让他去Master上读,下一次也是Master上读。
-
如果Master负载很重,再从Master上拉取数据就不合适了。
1 Broker的主从架构有没有实现读写分离?
作为消费者的系统在获取消息的时候,是从Master Broker获取的?还是从Slave Broker获取的?其实都不是。答案是:有可能从Master Broker获取消息,也有可能从Slave Broker获取消息。
作为消费者的系统在获取消息的时候会先发送请求到Master Broker上去,请求获取一批消息,此时Master Broker是会返回一批消息给消费者系统的
Master Broker在返回消息给消费者系统的时候,会根据当时Master Broker的负载情况和Slave Broker的同步情况,向消费者系统建议下一次拉取消息的时候是从Master Broker拉取还是从Slave Broker拉取。
举个例子,要是这个时候Master Broker负载很重,本身要抗10万写并发了,你还要从他这里拉取消息,给他加重负担,那肯定是不合适的。所以此时Master Broker就会建议你从Slave Broker去拉取消息。或者举另外一个例子,本身这个时候Master Broker上都已经写入了100万条数据了,结果Slave Broke不知道啥原因,同步的特别慢,才同步了96万条数据,落后了整整4万条消息的同步,这个时候你作为消费者系统可能都获取到96万条数据了,那么下次还是只能从Master Broker去拉取消息。因为Slave Broker同步太慢了,导致你没法从他那里获取更新的消息了。
所以这一切都会由Master Broker根据情况来决定。
2 RocketMQ版本不同broker主从自动切换的区别
在RocketMQ 4.5版本之前,都是用Slave Broker同步数据,尽量保证数据不丢失,但是一旦Master故障了,Slave是没法自动切换成Master的。
所以在这种情况下,如果Master Broker宕机了,这时就得手动做一些运维操作,把Slave Broker重新修改一些配置,重启机器给调整为Master Broker,这是有点麻烦的,而且会导致中间一段时间不可用。
在RocketMQ 4.5之后,这种情况得到了改变,因为RocketMQ支持了一种新的机制,叫做Dledger。
简单来说,把Dledger融入RocketMQ之后,就可以让一个Master Broker对应多个Slave Broker,也就是说一份数据可以有多份副本,比如一个Master Broker对应两个Slave Broker。
此时一旦Master Broker宕机了,就可以在多个副本,也就是多个Slave中,通过Dledger技术和Raft协议算法进行leader选举,直接将一个Slave Broker选举为新的Master Broker,然后这个新的Master Broker就可以对外提供服务了。
整个过程也许只要几秒的时间就可以完成,这样的话,就可以实现Master Broker挂掉之后,自动从多个Slave Broker中选举出来一个新的Master Broker,继续对外服务,一切都是自动的。
3 Topic作为一个数据集合是怎么在Broker集群里存储的
首先我们来想一下,比如我们有一个订单Topic,可能订单系统每天都会往里面投递几百万条数据,然后这些数据在MQ集群上还得保留好多天,那么最终可能会有几千万的数据量,这还只是一个Topic。
那么如果有很多的Topic,并且里面都有大量的数据,最终加起来的总和也许是一个惊人的数字,此时这么大量的数据本身是不太可能存放在一台机器上的。如果一台机器没法放下那么多的数据,应该怎么办呢?
很简单,分布式存储。
我们可以在创建Topic的时候指定让他里面的数据分散存储在多台Broker机器上,比如一个Topic里有1000万条数据,此时有2台Broker,那么就可以让每台Broker上都放500万条数据。
这样就可以把一个Topic代表的数据集合分布式存储在多台机器上了。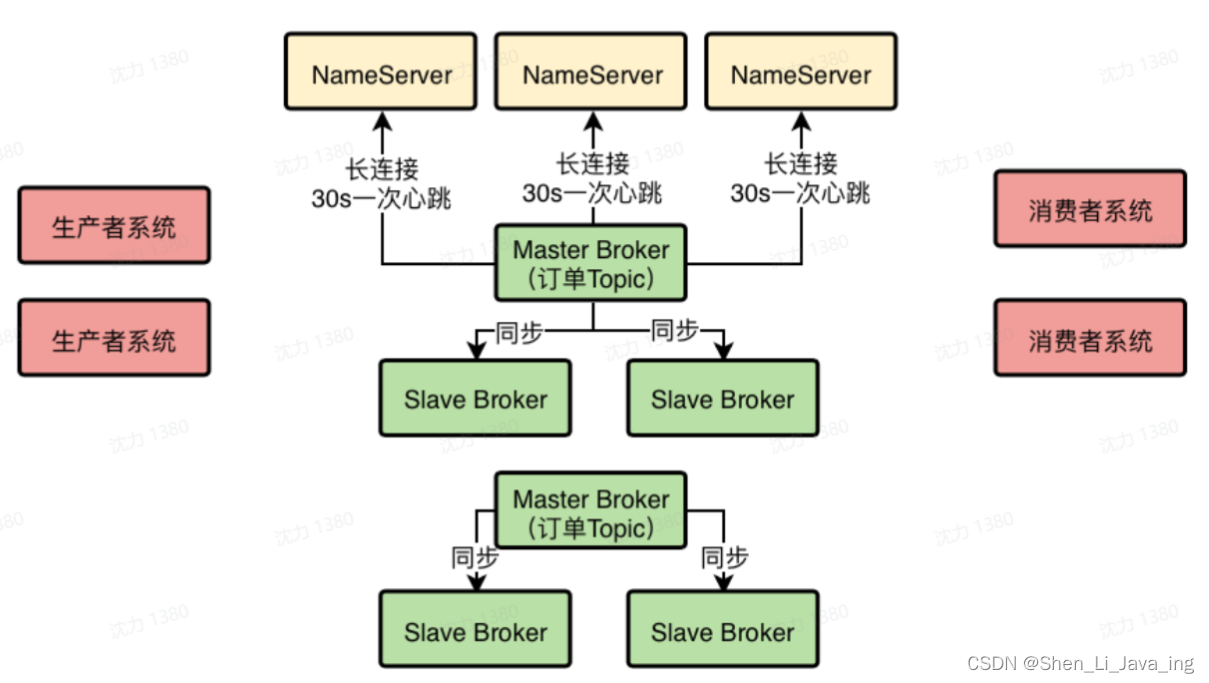
4 生产者系统是如何将消息发送给Broker的?
在发送消息之前,得先有一个Topic,然后在发送消息的时候你得指定你要发送到哪个Topic里面去。
接着既然你知道你要发送的Topic,那么就可以跟NameServer建立一个TCP长连接,然后定时从他那里拉取到最新的路由信息,包括集群里有哪些Broker,集群里有哪些Topic,每个Topic都存储在哪些Broker上。
然后生产者系统自然就可以通过路由信息找到自己要投递消息的Topic分布在哪几台Broker上,此时可以根据负载均衡算法,从里面选择一台Broke机器出来,比如round robine轮询算法,或者是hash算法,都可以。
总之,选择一台Broker之后,就可以跟那个Broker也建立一个TCP长连接,然后通过长连接向Broker发送消息即可。
生产者一定是投递消息到Master Broker的,然后Master Broker会同步数据给他的Slave Brokers,实现一份数据多份副本,保证Master故障的时候数据不丢失,而且可以自动把Slave切换为Master提供服务。





 322. 零钱兑换 279.完全平方数)
之扩展小部件(二十六):如何是drop_down部件来构建下拉菜单?)









 的 Sync Target(复制源))


递归、快速排序)