Attention相关问题笔试解析。
- 题目描述一:【选择】
- 题目描述二:【简答】
- 题目描述三:【代码】
- Scaled Dot-Product Attention:下面是用PyTorch实现的一个Attention机制的代码。这个实现包括一个简单的Scaled Dot-Product Attention机制和一个Multi-Head Attention机制。
- Multi-Head Attention:
- 无注释背诵版:
题目描述一:【选择】
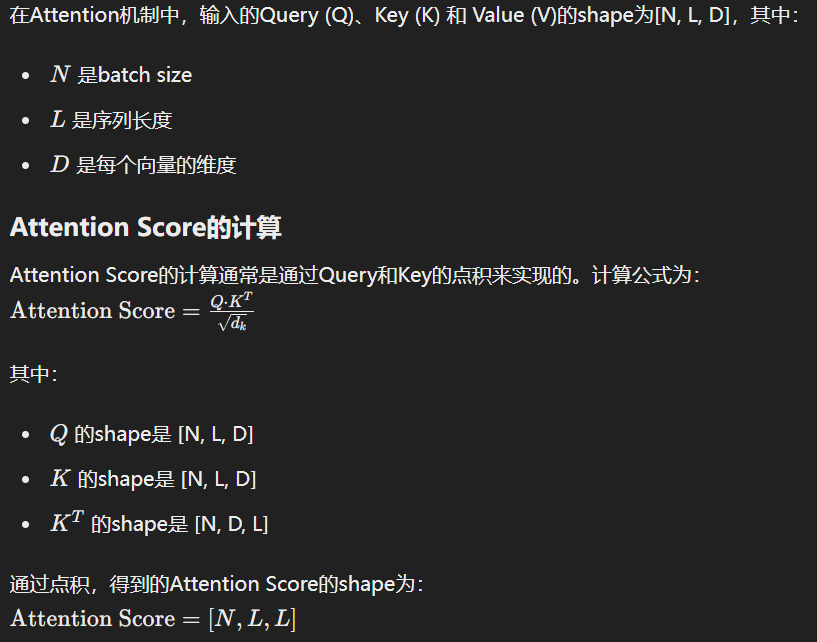
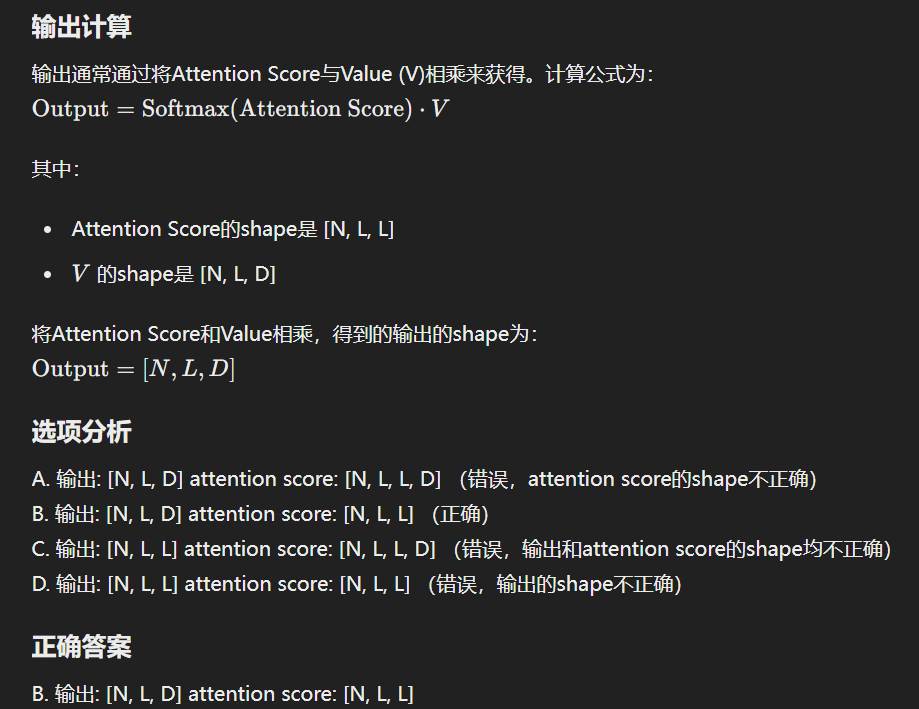
Attention 机制中,输入QKV的shape为[N,L,D],请问 输出的shape和attention score 的shape分别是多少?
A. 输出:[N,L,D] attention score: [N,L,L,D]
B.输出:[N,L,D] attention score: [N,L,L]
C.输出:[N,L,L] attention score: [N,L,L,D]
D.输出:[N,L,L] attention score: [N,L,L]
正确答案是:B
题目描述二:【简答】
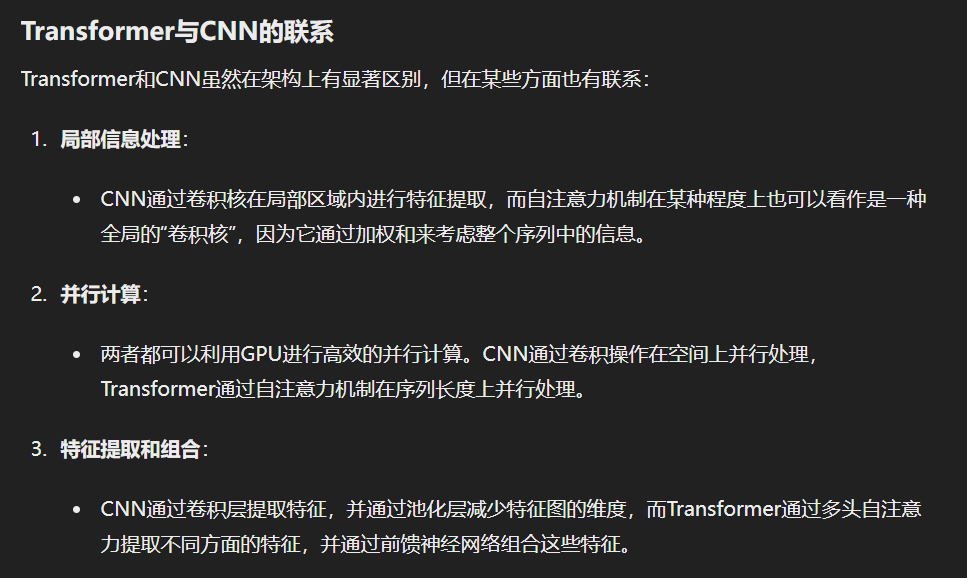
Transformer的核心思想是什么?它较之前的方法有什么优势(举例说明)?他和CNN有什么联系(开放问题)?
答:
Transformer的核心思想是使用自注意力机制(Self-Attention Mechanism)来建模序列数据中的依赖关系,取代传统的递归神经网络(RNN)和卷积神经网络(CNN)在处理序列任务时的局限性。具体来说,Transformer的架构主要由编码器(Encoder)和解码器(Decoder)组成,每个编码器和解码器模块由多头自注意力机制(Multi-Head Self-Attention Mechanism)和前馈神经网络(Feed-Forward Neural Network)组成。


总结:
Transformer通过自注意力机制实现了高效的序列建模,克服了RNN在长距离依赖和并行处理上的局限性。它在自然语言处理(如机器翻译、文本生成)和其他序列任务中表现出色。虽然与CNN在结构上不同,但两者都能高效地进行特征提取和处理,并利用并行计算加速训练和推理过程。
题目描述三:【代码】
请使用torch 或者numpy 编写attention机制。QKV都是三维张量。
- 实现一个attention 类
- 需要说明函数入参含义、输入输出shape
- 完成简单的scaled dot-product attention即可
- 有把握的,可以实现multi-head attentlon
Scaled Dot-Product Attention:下面是用PyTorch实现的一个Attention机制的代码。这个实现包括一个简单的Scaled Dot-Product Attention机制和一个Multi-Head Attention机制。
首先,我们实现一个简单的Scaled Dot-Product Attention机制。
import torch
import torch.nn.functional as Fclass ScaledDotProductAttention:def __init__(self, d_k):"""初始化函数:param d_k: int, 每个attention头的维度"""self.d_k = d_kdef __call__(self, Q, K, V):"""执行Scaled Dot-Product Attention:param Q: torch.Tensor, 形状为[N, L, D]:param K: torch.Tensor, 形状为[N, L, D]:param V: torch.Tensor, 形状为[N, L, D]:return: 输出张量的形状为[N, L, D], attention score的形状为[N, L, L]"""# 计算注意力分数scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))attention_scores = F.softmax(scores, dim=-1)# 计算注意力输出attention_output = torch.matmul(attention_scores, V)return attention_output, attention_scores# 使用示例
N, L, D = 2, 5, 64
d_k = DQ = torch.rand(N, L, D)
K = torch.rand(N, L, D)
V = torch.rand(N, L, D)attention = ScaledDotProductAttention(d_k)
output, scores = attention(Q, K, V)print(f"Output shape: {output.shape}")
print(f"Attention scores shape: {scores.shape}")Multi-Head Attention:
接下来,我们实现一个Multi-Head Attention机制,它是基于多个Scaled Dot-Product Attention头的。
class MultiHeadAttention:def __init__(self, num_heads, d_model):"""初始化函数:param num_heads: int, 注意力头的数量:param d_model: int, 输入的特征维度"""assert d_model % num_heads == 0, "d_model必须是num_heads的整数倍"self.num_heads = num_headsself.d_model = d_modelself.d_k = d_model // num_headsself.W_q = torch.nn.Linear(d_model, d_model)self.W_k = torch.nn.Linear(d_model, d_model)self.W_v = torch.nn.Linear(d_model, d_model)self.W_o = torch.nn.Linear(d_model, d_model)self.attention = ScaledDotProductAttention(self.d_k)def split_heads(self, x, batch_size):"""将最后一维分裂成(num_heads, d_k)形状,并将张量重塑为(batch_size * num_heads, seq_length, d_k):param x: torch.Tensor, 形状为(batch_size, seq_length, d_model):param batch_size: int, batch大小:return: torch.Tensor, 形状为(batch_size * num_heads, seq_length, d_k)"""x = x.view(batch_size, -1, self.num_heads, self.d_k)return x.transpose(1, 2).contiguous().view(batch_size * self.num_heads, -1, self.d_k)def __call__(self, Q, K, V):"""执行Multi-Head Attention:param Q: torch.Tensor, 形状为[N, L, D]:param K: torch.Tensor, 形状为[N, L, D]:param V: torch.Tensor, 形状为[N, L, D]:return: 输出张量的形状为[N, L, D], attention score的形状为[N * num_heads, L, L]"""batch_size = Q.size(0)Q = self.split_heads(self.W_q(Q), batch_size)K = self.split_heads(self.W_k(K), batch_size)V = self.split_heads(self.W_v(V), batch_size)attention_output, attention_scores = self.attention(Q, K, V)attention_output = attention_output.view(batch_size, self.num_heads, -1, self.d_k)attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)return self.W_o(attention_output), attention_scores.view(batch_size, self.num_heads, -1, attention_scores.size(-1))# 使用示例
N, L, D = 2, 5, 64
num_heads = 8
d_model = DQ = torch.rand(N, L, D)
K = torch.rand(N, L, D)
V = torch.rand(N, L, D)multi_head_attention = MultiHeadAttention(num_heads, d_model)
output, scores = multi_head_attention(Q, K, V)print(f"Output shape: {output.shape}")
print(f"Attention scores shape: {scores.shape}")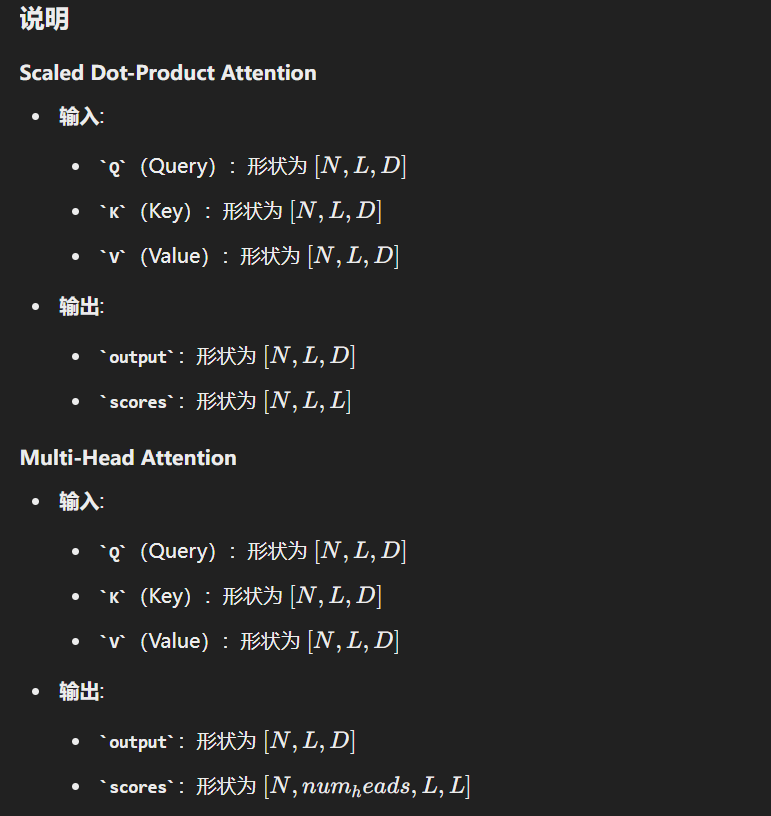
以上实现了简单的Scaled Dot-Product Attention和Multi-Head Attention机制,并包含示例代码用于测试。
无注释背诵版:
- __init__是初始化d_k是每个向量的维度
- torch.matmul,转置K.transpose(-2, -1),/根号sqrt(d_k)
- F.softmax(scores, dim=-1)得注意力分数
- torch.matmul与V乘得输出
import torch
import torch.nn.functional as Fclass Attention:def __init__(self, d_k): self.d_k = d_kdef __call__(self, Q, K, V):scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))attention_scores = F.softmax(scores, dim=-1)attention_output = torch.matmul(attention_scores, V)return attention_output, attention_scoresclass MultiHeadAttention:def __init__(self, num_heads, d_model):assert d_model % num_heads == 0self.nums_heads = num_headsself.d_model = d_modelself.d_k = d_model // num_headsself.W_q = torch.nn.Linear(d_model, d_model)self.W_k = torch.nn.Linear(d_model, d_model)self.W_v = torch.nn.Linear(d_model, d_model)self.W_o = torch.nn.Linear(d_model, d_model)self.attention = Attention(self.d_k)def split_heads(self, x, batch_size):x = x.view(batch_size, -1, self.nums_heads, self.d_k)return x.transpose(1, 2).contiguous().view(batch_size * self.nums_heads, -1, self.d_k)def __call__(self, Q, K, V):batch_size = Q.size(0)Q = self.split_heads(self.W_q(Q), batch_size)K = self.split_heads(self.W_k(K), batch_size)V = self.split_heads(self.W_v(V), batch_size)attention_output, attention_score = self.attention(Q, K, V)attention_output = attention_output.view(batch_size, self.nums_heads, -1, self.d_k)attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)return self.W_o(attention_output), attention_score.view(batch_size, self.nums_heads, -1, attention_score.size(-1))
使用示例
N, L, D = 2, 5, 64
num_heads = 8
d_model = DQ = torch.rand(N, L, D)
K = torch.rand(N, L, D)
V = torch.rand(N, L, D)multi_head_attention = MultiHeadAttention(num_heads, d_model)
output, scores = multi_head_attention(Q, K, V)print(f"Output shape: {output.shape}")
print(f"Attention scores shape: {scores.shape}")



♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠


)





(二))










