1、条件语句
(1)if条件
if条件表达式,每一个分支最后一条语句就是该分支的返回值。适用于每个分支返回值类型一致这种情况。
fun getDegree(score: Int): String{val result: String = if(score == 100){"非常优秀"}else if(score >= 90){"优秀"}else if(score >= 80){"良好"}else if(score >= 70){"中等"}else if(score >= 60){"及格"}else{"不及格"}return result
}
只有两个条件时,简化如下
val result = if(10 > 20) "no" else "yes"
(2)range
… 表示范围,左闭右闭
for (i in 0..5){println(i) // [0, 5]}
until 创建区间,左闭右开
for (i in 0 until 5){println(i) // [0, 5)}
(3)when条件
只要代码包含 else if 分支,都建议改用 when 表达式。
fun getDegree1(score: Int): String{val result = when(score){100 -> "非常优秀"in 90..99 -> "优秀" // 在某个范围使用 inin 80..89 -> "良好"in 70..79 -> "中等"in 60..69 -> "及格"in 0..59 -> "不及格"else -> "非法数据" // 必须加上else出口}return result
}
(4)string模版
val name = "JPC客栈"// 引用某个变量println("my name is $name")// 进行简单计算val sex = 1println("my sex is ${ if(sex == 1) "男" else "女"}")
2、函数
(1)匿名函数
使用 点语法,只要一个函数在某个数据类型的定义里,就
可以用点语法调用它
val letterCount = "hello kotlin java android jetpack compose".count()println(letterCount)
把一个匿名函数作为参数传递给 count 函数
val letterCount = "hello kotlin java android jetpack compose".count { letter ->letter == 'a'}println(letterCount)
String 类型的 count 函数使用匿名函数来决定该如何统计字符串中的字符。
println({val currentYear = 2018"Welcome to SimVillage, Mayor! (copyright $currentYear)"}())
在花括号的后面跟上一对空的圆括号,表示调用匿名函数。圆括号不能省,否则就不会输出信息。和具名函数一样,要让匿名函数工作,就得调用它,并在参数圆括号里传入对应的值参(没参数就空着)。
(2)函数类型
匿名函数也有类型,我们称其为函数类型(function type)。匿名函数可以当作变量值赋给函数类型变量。然后,就像其他变量一样,匿名函数就可以在代码里传递了。
函数类型定义包括两个部分,它们以箭头符号隔开:一对圆括号里面的函数参数和紧跟着的返回数据类型。
任何不需要参数(以圆空括号表示)、能返回 String 的函数,都可以赋给 printlnFunction变量。
和具名函数不一样,除了极少数的情况外,匿名函数不需要 return 关键字来返回数据。没有 return 关键字,为了返回数据,匿名函数会隐式或自动返回函数体最后一行语句的结果。
// : () -> String 表示变量存储的是哪种类型的函数
val printlnFunction: () -> String = {val currentYear = 2018// 自动返回最后一行语句的执行结果"Welcome to SimVillage, Mayor! (copyright $currentYear)"}
// 运行需要使用括号println(printlnFunction())
和具名函数一样,匿名函数可以不带参数,也可以带一个或多个任何类型的参数。需要带参数时,参数的类型放在匿名函数的类型定义中,参数名则放在函数定义中。
val printlnFunction: (String) -> String = {name ->"Welcome to SimVillage, Mayor! (copyright $name)"}println(printlnFunction("JPC"))
(3)it关键字
定义只有一个参数的匿名函数时,可以使用 it 关键字来表示参数名。当你有一个只有一个参数的匿名函数时,it 和命名参数都有效。
val printlnFunction: (String) -> String = {"Welcome to SimVillage, Mayor! (copyright $it)"}println(printlnFunction("JPC"))
(4)定义参数是函数的函数
函数支持包括函数在内的任何类型的参数。一个函数类型的参数定义起来和其他类型的参数一样:在函数名后的一对圆括号内列出,再加上类型。
// 类型自动推断val greetingFunction = { name: String, numBuildings: Int ->println("add $numBuildings houses")"hello $name"}printFunction("JPC", greetingFunction)
}fun printFunction(name: String, greetingFunction: (String, Int) -> String){// shuffle() 方法用于打乱集合中元素的顺序 last() 方法用于获取集合中的最后一个元素val numBuildings = (1..3).shuffled().last()println(greetingFunction(name, numBuildings))
}
如果一个函数的 lambda 参数排在最后,或者是唯一的参数,那么括住 lambda 值参的一对圆括号就可以省略。这种简略写法只支持 lambda 参数排在最后的情况,所以,定义函数时,建议把函数类型的参数放在最后,以方便调用者使用。
// 将lambda表达式写在外面printFunction("JPC"){name, numBuildings ->println("add $numBuildings houses")"hello $name"}
}fun printFunction(name: String, greetingFunction: (String, Int) -> String){// shuffle() 方法用于打乱集合中元素的顺序 last() 方法用于获取集合中的最后一个元素val numBuildings = (1..3).shuffled().last()println(greetingFunction(name, numBuildings))
}
(5)函数内联
lambda 可以让你更灵活地编写应用。然而,灵活也是要付出代价的。在 JVM 上,你定义的 lambda 会以对象实例的形式存在。JVM 会为所有同 lambda 打交道的变量分配内存,这就产生了内存开销。更糟的是,lambda 的内存开销会带来严重的性能问题。显然,这种性能问题应当避免。
幸运的是,Kotlin 有一种优化机制叫内联,可以解决 lambda 引起的内存开销问题。有了内联,JVM 就不需要使用 lambda 对象实例了,因而避免了变量内存分配。
为了使用内联方法优化 lambda,以 inline 关键字标记使用 lambda 的函数即可。
有了 inline 关键字后,调用 runSimulation 函数就不会使用 lambda 对象实例了 。哪里需要使用 lambda,编译器就会将函数体复制粘贴到哪里。
inline fun printFunction(name: String, greetingFunction: (String, Int) -> String){// shuffle() 方法用于打乱集合中元素的顺序 last() 方法用于获取集合中的最后一个元素val numBuildings = (1..3).shuffled().last()println(greetingFunction(name, numBuildings))
}
现在,runSimulation 函数调用 lambda 执行的工作已直接内联到 main 函数里了。这避免了 lambda 函数的传递,因此也就不需要创建新的对象实例了。
通常来说,使用 inline 关键字标记使用 lambda 的函数是个好主意。然而,有时却不一定行。
例如,使用 lambda 的递归函数就无法内联,因为内联递归函数会让复制粘贴函数体的行为无限循环。
(6)函数引用
要把函数作为参数传给其他函数使用,我们都是先定义一个 lambda,然后把它作为参数传给另一个函数使用。除了传 lambda 表达式,Kotlin 还提供了其他方法:传递函数引用。函数引用可以把一个具名函数(使用 fun 关键字定义的函数)转换成一个值参。凡是使用lambda 表达式的地方,都可以使用函数引用。
函数引用在很多场景都很有用。例如,如果需要一个具名函数作为值参传给其他函数,采用函数引用方法代替 lambda 就能达到同样的目的。或者在需要使用 Kotlin 标准库函数作为值参传给其他函数使用时,也可以使用函数引用。
要获得函数引用,使用::操作符,后跟要引用的函数名。
printFunction("JPC", ::printCost){name, numBuildings ->println("add $numBuildings houses")"hello $name"}
}inline fun printFunction(name: String, costPrintln: (Int) -> Unit, greetingFunction: (String, Int) -> String){// shuffle() 方法用于打乱集合中元素的顺序 last() 方法用于获取集合中的最后一个元素val numBuildings = (1..3).shuffled().last()costPrintln(numBuildings)println(greetingFunction(name, numBuildings))
}fun printCost(numBuildings: Int){println("build cost ${numBuildings * 500}")
}
(7)函数类型作为函数返回值的类型
函数类型作为返回类型和其他数据类型一样,函数类型也是有效的返回类型,也就是说,你可以定义一个能返回函数的函数。
fun main() {runSimulation()
}
fun runSimulation() {val greetingFunction = configureGreetingFunction()println(greetingFunction("JPC"))
}
fun configureGreetingFunction(): (String) -> String {val structureType = "hospitals"var numBuildings = 5// 返回一个函数return { playerName: String -> // 参数val currentYear = 2018numBuildings += 1println("Adding $numBuildings $structureType")// 返回值"Welcome to SimVillage, $playerName! (copyright $currentYear)"}
}
可以把 configureGreetingFunction 函数看作“函数工厂”,即配置产生函数的函数。该函数声明必要的变量并在 lambda 中使用,然后把 lambda 返回给 runSimulation 调用者。
尽管 numBuildings 和 structureType 这两个局部变量是定义在返回 lambda 的configureGreetingFunction 函数中,但 configureGreetingFunction 函数返回的 lambda依然能使用它们。之所以会这样,是因为 Kotlin 中的 lambda 是闭包。闭包能使用定义自己的外部函数的变量。
能接受函数(以函数值参传入)或者返回函数的函数又叫高级函数。
在 Kotlin 中,匿名函数能修改并引用定义在自己的作用域之外的变量。这表明,匿名函数引用着定义自身的函数里的变量。
fun main() {runSimulation()
}
fun runSimulation() {val greetingFunction = configureGreetingFunction()println(greetingFunction("JPC"))// 再调用一次println(greetingFunction("JPC"))
}
fun configureGreetingFunction(): (String) -> String {val structureType = "hospitals"var numBuildings = 5return { playerName: String -> // 参数val currentYear = 2018numBuildings += 1println("Adding $numBuildings $structureType")// 返回值"Welcome to SimVillage, $playerName! (copyright $currentYear)"}
}
第二次输出了 7,说明匿名函数可以持有并修改定义自身的函数里面的变量。
Adding 6 hospitals
Welcome to SimVillage, JPC! (copyright 2018)
Adding 7 hospitals
Welcome to SimVillage, JPC! (copyright 2018)
3、null 安全与异常
如果一个 var 或 val 变量能接受 null 值,Kotlin 需要你做个特别声明。这有助于避免 null 相关的应用崩溃。
因为变量属于非空类型(String),而非空类型不支持赋 null 值
// 编译都不通过var name = "JPC"name = null
Kotlin 是一门编译型语言。这表明,Kotlin 应用代码先编译成机器语言指令,再由一个叫编译器的特殊程序执行。在编译阶段,编译器会先检查代码是否符合特定要求,确认没问题后再编译生成机器指令。例如,编译器会检查是否有 null 值赋给了非空类型。你已经知道,如果真的把null 值赋给了非空类型,Kotlin 就会拒绝编译程序。
Kotlin 区分可空类型和非可空类型,所以,你要一个可空类型变量做事,而它又可能不存在,对于这种潜在危险,编译器时刻警惕着。为了应对这种风险,Kotlin 不允许你在可空类型值上调用函数,除非你主动接手安全管理。
(1)安全调用操作符
操作一段无法控制的代码中的变量,你不确定它会不会返回 null。这种情况下,在函数调用时,最好的选择就是使用安全调用操作符(?.)
编译器看到有安全调用操作符,所以它知道如何检查 null值。如果遇到 null 值,它就跳过函数调用,而不是返回 null。
val res = readLine()?.replaceFirstChar { it.uppercaseChar() }println(res)
(2)使用带 let 的安全调用
安全调用允许在可空类型上调用函数。但是,如果还想做点额外的事,比如创建新值,或判断变量不为 null 就调用其他函数,那该怎么办呢?使用带 let 函数的安全调用操作符是个办法。
你可以在任何类型上调用 let 函数,它的主要作用是让你在指定的作用域内定义一个或多个变量。
因为 let 提供了自己的函数作用域,所以你可以使用带 let 的安全调用限定多个表达式,然后,在这些表达式里判断变量不为空时,做出相应的变量操作。
val result = readLine()?.let {if(it.isNotBlank()){// 隐式返回结果it.replaceFirstChar {char -> char.uppercase() }}else{""}}println(result)
在 let 函数里,it 指向的变量就是你在其上调 let 函数的变量。
由于 it 可以确保非空,所以可以直接调用isNotBlank、replaceFirstChar 函数。
使用 let 的第二个好处体现在后台:let 会隐式返回表达式结果。这样,在表达式有了结果值后,你就能把结果赋值给一个变量。
(3)使用!!.操作符
!!.操作符也能用来在可空类型上调用函数。但我要给你个警告:相比安全调用操作符,!!.操作符太激进,一般应该避免使用。视觉上看,代码中的!!.操作符也给人语气很重的感觉,因为它真的很危险。
!!.的官方名字是非空断言操作符,但开发人员更喜欢叫它“感叹号操作符”。
val result = readLine()!!.replaceFirstChar { it.uppercase() }println(result)
result = readLine()!!.replaceFirstChar代码片段的意思很明确:“result 变量是否为 null 我不管,请做首字符大写转换!”如果 result 变量值真的为 null,就会抛出 KotlinNullPointerException。
虽然不推荐,但!!.操作符也有其适用的场景。例如,某个变量的类型你控制不了,但你确信它不会为 null,这时,!!.操作符就是个不错的选择。
(4)使用 if 判断 null 值情况
安全处理 null 值的第三个办法是执行 if 条件表达式,判断变量是否为 null 值。
什么时候该用 if/else 语句做 null 值检查呢?如果需要一些复杂的逻辑运算才能判断某个变量是否为 null,选择它就最合适。而且,使用 if/else 语句组织复杂逻辑,代码看起来会更清晰可读。
(5)使用空合并操作符
另一种检查 null 值的方式是使用 Kotlin 的空合并操作符?:
这种操作符的意思是,“如果我左边的求值结果是 null,就使用右边的结果值”。
val x = nullval result = x?: "default"println(result)
val x = readLine()val result = x?.let { it.uppercase() } ?: "default"println(result)
(6)异常
例如,对于一个可空类型,如果它的值为null,调用函数就会抛出运行时错误
fun main() {var num: Int? = nullval flag = (1..3).shuffled().last() == 3if(flag) num = 2num!!.plus(1) // !!. 让编译通过println(num)
}
Exception in thread "main" java.lang.NullPointerException
在众多异常里面,IllegalStateException 是最常见的一个。看名字虽然比较含糊,但有一点可以肯定——你的应用程序有了不合法的行为。这很有用,因为你可以传递字符串给IllegalStateException,实现在抛出异常时打印出具体的出错信息。
fun main() {var num: Int? = nullval flag = (1..3).shuffled().last() == 3if(flag) num = 2// 如果num 不为null就继续执行,否则抛出异常num ?: throw IllegalStateException("num is null")num.plus(1) // 编译就可以通过println(num)
}
自定义异常,提高代码复用性
fun main() {var num: Int? = nullval flag = (1..3).shuffled().last() == 3if(flag) num = 2num ?: throw NumIsNull()num.plus(1)println(num)
}
// 自定义异常
class NumIsNull: IllegalStateException("num is null")
使用try-catch捕获异常
fun main() {var num: Int? = nullval flag = (1..3).shuffled().last() == 3if(flag) num = 2try {numCheck(num)num!!.plus(1)}catch (e: Exception){println(e)}println(num)
}
fun numCheck(num: Int?){num ?: throw NumIsNull()
}
// 自定义异常
class NumIsNull: IllegalStateException("num is null")
虽然num为null,但是代码可以继续执行
NumIsNull: num is null
null
try/catch 之后的代码也执行了。一个未捕获异常会中止执行,让程序崩溃。但因为你用try/catch 代码块处理了异常,所以代码依然正常运行,就好像什么事都没发生一样。
(7)先决条件函数
用它定义先决条件——条件必须满足,目标代码才能执行。
checkNotNull 是个先决条件函数,它会检查某个值是否为 null,如果不是,就返回该值,反之就抛出 IllegalStateException 异常。
checkNotNull 函数需要两个参数:第一个用于检查是否为 null,第二个是打印到控制台的错误信息,当然前提是第一个参数为 null。
fun main() {var num: Int? = nullval flag = (1..3).shuffled().last() == 3if(flag) num = 2try {numCheck(num)num!!.plus(1)}catch (e: Exception){println(e)}println(num)
}
fun numCheck(num: Int?){checkNotNull(num) { "num is null" }
}
java.lang.IllegalStateException: num is null
null
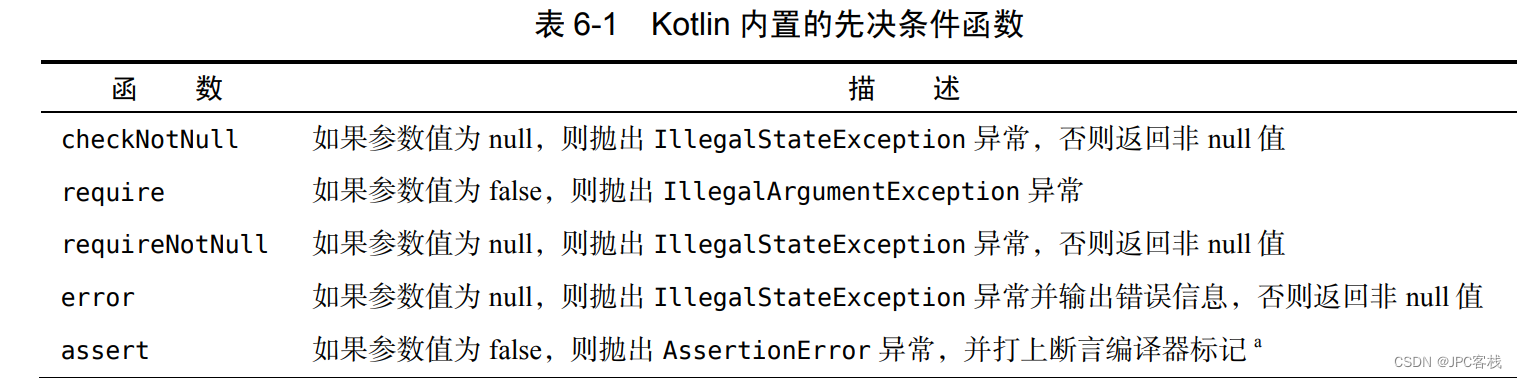
fun main() {var num: Int? = nullval flag = (1..3).shuffled().last() == 3if(flag) num = 2try {numCheck(num)num = num!!.plus(1)}catch (e: Exception){println(e)}println(num)
}
fun numCheck(num: Int?){checkNotNull(num){ "num is null" }require(num >= 2){ "num is less 2" }
}
Kotlin 编译器又向前迈了一步:使用 Intrinsics.checkParameterIsNotNull 方法。每个非空参数上都会调用这个方法,如果传来的值参是 null 值,它会抛出 IllegalArgumentException 异常。
4、字符串
(1)字符串截取
两种方式实现字符串截取:使用 substring 和 split函数
fun main() {val fileName: String = "hello.txt"val index = fileName.indexOf('.') // 对应 .val type = fileName.substring(index+1..<fileName.length)println(type) // txt
}
fun main() {val fileName: String = "hello.txt"val split = fileName.split('.')val name = split[0] // 通过索引访问val type = split[1]println("name is $name, type is $type")
}name is hello, type is txt
split 函数返回的是 List 集合数据,而 List 集合又支持一种叫解构(destructuring)的语法特性(这个 Kotlin 特性允许你在一个表达式里给多个变量赋值)。
val split = fileName.split('.')val (name, type) = splitprintln("name is $name, type is $type")
解构常用来简化变量的赋值。只要是集合结果,就可以使用解构赋值。除了 List 集合,其他支持解构语法的数据类型有 Maps、Pairs 以及数据类。
(2)字符串操作
replace函数能按给定规则替换字符串中的字符。replace 函数支持用正则表达式(稍后会展开讨论)确定要操作哪些字符,然后调用你定义的匿名函数来确定如何替换匹配字符。
使用的 replace 函数需要两个值参。第一个是正则表达式(regex),用来决定要替换哪些字符。正则表达式可以针对你要搜索的字符定义通用的搜索模式。第二个值参是匿名函数,用来
确定该如何替换正则表达式搜索到的字符。
实际上,replace 函数不会替换 phrase 变量的任何部分。恰恰相反,replace 函数会创建一个新字符串。它使用输入的旧字符串,然后使用你提供的正则表达式,找到匹配字符后,生成
新的字符串。不管是用 var 还是 val 定义,Kotlin 中的所有字符串都是不可变的(和 Java 里的一样)。如果一个字符串变量定义为 var 变量,即使你可以给它赋新值,原字符串实例本身也不会被改变。
对于类似于 replace 的任何函数,在改变字符串的值时,它都是保持原值不变,创建一个更改过的新字符串。
replaceString()}
fun replaceString(){val phrase = "hello java kotlin android"val newString = replaceChar(phrase)println(newString)
}
fun replaceChar(phrase: String): String{return phrase.replace(Regex("[aeiou]")){when(it.value){"a" -> "1""e" -> "2""i" -> "3""o" -> "4""u" -> "5"else -> it.value}}
}
使用结构相等操作符 == 来判断 name 变量值和"Dragon’s Breath"是否结构相等。之前,你已见过用 == 判断数值相等的例子。用于字符串时,它会检查两个字符串中的字符是否都匹配,顺序是否一致。
判断两个变量相等还有另一种方式:引用相等。这种方式会检查两个变量是否引用着同一个类实例,也就是说两个变量是否指向内存堆上的同一对象。做引用相等判断时使用===符号。
引用相等比较很少用于比较字符串。一般来说,相比关心两个字符串是不是同一实例,我们更关心它们是不是相等字符,以及顺序是否一致(或者说两个不同的类实例是否结构相同)。
"hello java kotlin android".forEach {println(it)}
5、标准函数库
(1)apply
在 lambda 表达式里,apply 能让每个配置函数都作用于接收者。这种行为有时又叫作相关作用域(relative scoping),因为 lambda 表达式里的所有函数调用都是针对接收者的。或者说,它们是针对接收者的隐式调用。
val numList = ArrayList<Int>()numList.add(1)numList.add(2)numList.add(3)val numList1 = ArrayList<Int>().apply {add(1)add(2)add(3)}for (i in numList1){println(i)}
(2)let
let 函数能使某个变量作用于其 lambda 表达式里,让 it 关键字能引用它。let 和 apply 用法上有几点不一样。let 会把接收者传给 lambda,而 apply 什么都不传。另外,匿名函数执行完,apply 会返回当前接收者,而 let会返回 lambda 的最后一行(lambda 结果值)。
像 let 这样的标准函数还可以用来防止变量值被不小心修改,因为 let 传给 lambda 的值参是只读参数。
支持链式调用
fun sayHello(name: String?): String{return name?.let { "hello $name"} ?: "hello default"
}
(3)run
光看作用域行为,run 和 apply 差不多。但与 apply 不同,run
函数不返回接收者。使用 run 的链式函数调用会让代码的逻辑更清晰,更易读。
"jpcjpc".run(::nameIsLong).run(::checkName).run(::println)
}fun nameIsLong(name: String) = name.length > 5fun checkName(flag: Boolean): String{return if (flag){"name is too long"}else{"name is ok"}
}
(4)with
with 函数是 run 的变体。它们的功能行为是一样的,但 with 的调用方式不同。和之前介绍的标准函数都不一样,调用 with 时需要值参作为其第一个参数传入。但是with不常用。
val nameIsLong1 = with("jpc"){length > 20
}
(5)also
also 函数和 let 函数功能相似。和 let 一样,also 也是把接收者作为值参传给 lambda。但有一点不同:also 返回接收者对象,而 let 返回 lambda 结果。因为这个差异,also 尤其适合针对同一原始对象,利用副作用做事。
// 可以对原对象进行链式调用"hello jpc".also {println(it)}.also {println(it.toUpperCase())}
(6)takeIf
takeIf 函数需要判断 lambda中提供的条件表达式(叫predicate),给出 true 或 false 结果。如果判断结果是 true,从 takeIf函数返回接收者对象;如果是 false,则返回 null。
下面这段代码逻辑是,当且仅当文件可读且可写时,才读取文件内容。
val result = File("hello.txt").takeIf { it.canRead() && it.canWrite() }?.readLines()
7、List与Set
(1)List
不可变列表
getOrElse 就是这样一个安全索引取值函数,它需要两个参数:第一个是索引值(放在圆括号而不是方括号里);第二个是能提供默认值的 lambda 表达式,如果索引值不存在的话,可用来代替异常。
getOrNull 是 Kotlin 提供的另一个安全索引取值函数。它会返回 null 结果,而不是抛出异常。使用该函数时,需要处理 null 值情况。
可以使用contains、containsAll函数判断是否含有指定的元素。
fun main() {// listOf返回只读列表val list1 = listOf(1, 2, 3)// 获取下标为4的元素,如果不存在返回默认值 "num is null"val value1 = list1.getOrElse(4) { "num is null" }println(value1)// 使用getOrNull根据下标获取元素,不存在返回null,在使用空合并操作符处理null的情况val value2 = list1.getOrNull(4) ?: "num is null"println(value2)// 判断是否包含元素val contains2 = list1.contains(2)// 是否包含这多个元素val containsAll = list1.containsAll(listOf(2, 3))
}
可变列表
使用mutableListof函数创建可变列表,可以使用add、remove等函数添加、删除元素。
fun testMutableList(){val mutableList = mutableListOf(1, 2, 3)mutableList.add(4)// 一次添加多个元素mutableList.addAll(listOf(5, 6))// 删除某个元素mutableList.remove(5)// 删除指定下标的元素mutableList.removeAt(4)// 删除最后一个元素mutableList.removeLast()// 基于 lambda 表达式指定的条件删除元素mutableList.removeIf{ it > 3}// for循环遍历列表println("for循环遍历列表")for (value in mutableList){println(value)}// 使用indices获取下标println("使用indices获取下标")for (index in mutableList.indices){println("the $index value is ${mutableList[index]}")}// 使用迭代器遍历println("使用迭代器遍历")mutableList.forEach { println(it) }// 迭代器同时遍历下标和值println("迭代器同时遍历下标和值")mutableList.forEachIndexed { index, value ->println("the $index value is $value")}
}
解构
fun jieGou(){val list = listOf("zhangsan", "man", "23", "other")// 使用 _代替不需要解构的值val (name, sex, age, _) = listprintln("my name is $name, I am a $age $sex")
}
(2)Set
Set 集合里的所有元素都具有唯一性;Set 集合不支持基于索引的存取值函数,因为它里面的元素顺序不固定。
使用索引值读取 Set 集合的元素虽然可行,但因为 elementAt 函数内部实现机制的问题,相比按索引读取 List 集合的元素,读取速度要慢上一个数量级。调用 Set 集合的 elementAt函数时,Set 会按照你指示的位置一次一个元素地遍历寻找。这意味着,如果 Set 集合里有很多元素,读取高位元素要比按索引取值的 List 慢好多。考虑到这个因素,如果需要基于索引值读取元素,最好选用 List 集合。
联合使用Set 集合和 List 集合:创建一个 Set 集合以去除重复元素,然后把它转成一个 List 集合使用。
fun testSet(){// 不可变Setval set1 = setOf(1, 2, 3, 3)for (value in set1){println(value)}// 可变MutableSetval mutableSet = mutableSetOf<Int>(1, 2, 3, 4)mutableSet.add(4)mutableSet.addAll(setOf(5, 6))for (value in mutableSet){println(value)}// 获取指定位置的元素val elementAt = mutableSet.elementAt(3)println(elementAt)
}
(3)集合转换
使用 toSet 和 toList 函数(或者 toMutableSet 和 toMutableList 可变集合版本),可以实现 List 集合和 Set 集合的相互转换。开发时,一个常用的小技巧就是调用 toSet去掉 list 集合里的重复元素。
fun convert(){val list = listOf(1, 2, 3)// 转为可变的Listval toMutableList = list.toMutableList()// 转为不可变的Setval toSet = list.toSet()// 转为可变的Setval toMutableSet = list.toMutableSet()
}
由于这种转来转去的用法太常见了,Kotlin 干脆封装了对 toSet 和 toList 函数的调用逻辑,提供了 distinct 这样一个快捷函数,专门用于元素去重。
fun testDistinct(){val distinct = listOf(1, 2, 3, 3, 4).distinct()
}
(4)Array类型
Kotlin 也提供了各种 Array 引用类型。虽然是引用类型,但可以编译成 Java 基本数据类型。Kotlin 提供 Array 类型的主要目的是支持和 Java 互操作。
使用了 IntArray 类型并调用了 intArrayOf 函数。IntArray 类型和 List 集合一样,可容纳一组元素,但只限于整数类型。和 List 集合类型不一样的是,在编译成字节码时,IntArray 类型会将基本数据类型化。

应该尽量使用集合,如果需要和Java代码互操作,可以使用Array类型。
fun testArray(){val intArrayOf = intArrayOf(1, 2, 3)val doubleArrayOf = doubleArrayOf(1.2, 3.4)// List集合转为Array类型val toIntArray = listOf(1, 2, 3).toIntArray()
}
8、Map
为定义 Map 集合里的元素(键值对),我们使用了 to,是个省略了点号和参数圆括号的特殊函数,to 函数将它左边和右边的值转化成一个对(Pair)——一种表示两个元素一组(键和值)的特
殊类型。
val map = mapOf(1 to "java", 2 to "Kotlin", 3 to "Android")// 可变的Mapval mutableMapOf = mutableMapOf(Pair(1, "java"), Pair(2, "kotlin"))
获取键对应的值
fun readMap(){val map = mapOf(1 to "java", 2 to "Kotlin", 3 to "Android")// 1、[] 读取对应的值,若键不存在就返回nullval first = map[1]// 2、getValue 如果键不存在就抛出异常val value = map.getValue(4)// 3、getOrElse 可以使用匿名函数返回默认值map.getOrElse(4){ "key is null" }// 4、getOrDefault 键不存在就返回默认值map.getOrDefault(4, "null")
}
fun addMap(){val map = mutableMapOf(1 to "java")// 1、使用运算符map[2] = "Kotlin" // 添加新键map += mapOf(3 to "android") // 追加// 2、put函数map.put(4 ,"c++")// 3、putAllmap.putAll(mapOf(5 to "python"))// 4、getOrPut 键值不存在就添加并返回结果,否则返回已有的值map.getOrPut(6){ "linux" }// 5、remove 删除只读键的元素map.remove(4)
}
9、类
(1)普通类使用class定义
class Demo10 {
}fun main() {// 调用类的主构造函数获得实例对象val demo10 = Demo10()
}
定义在类里的函数叫类函数。

一个类实例一旦创建,它的所有属性都必须有值。这表明,和普通变量不一样,类属性必须有初始值。
class Demo10 {var name: String = "jpc" // 必须有初始值
}
尽管 Kotlin 会自动提供默认的 getter 和 setter 方法,但在需要控制如何读写属性数据时,你也可以自定义它们。我们把这种自定义行为叫作覆盖 getter 和 setter 方法。
class Demo10 {var name: String = "jpc" // 必须有初始值get(){return field.capitalize()}// 只有var修饰的类属性才有set方法private set(value: String){field = value.uppercase()}
}
对于 getter 和 setter 方法怎样读取和修改数据,属性提供了比较细致的控制。无论你是否自定义,所有的属性都有 getter 方法,所有的 var 属性都有 setter 方法。默认情况下,属性的 getter
和 setter 方法的可见性与属性一致。所以,如果属性是 public,那么它的 getter 和 setter 方法也是 public 的。
如果只想暴露属性,不想暴露它的 setter 方法,那该怎么办?你可以为属性的 setter 方法单独定义可见性。
在你定义属性时,Kotlin 都会产生一个 field 来存储属性封装的值。这话没错,但也有个特例:计算属性。计算属性是通过一个覆盖的 get 和(或)set 运算符来定义的,这时 field就不需要了。也就是说,Kotlin 在碰到这种情况时就不会产生 field。
val age: Intget(){return (1..100).shuffled().first()}
使用 var(可写) 关键字和 val (只读)关键字定义属性的区别就是属性值是否可改(setter 方法没了)。
防范竞态条件
例如以下代码
如果一个类属性既可空又可变,那么引用它之前你必须保证它非空。但是代码竟然无法编译,因为可能会导致竞态条件(race condition)问题,如果应用程序里有其他代码同时修改某个代码状态,并产生了难以预料的结果,就可以说出现了竞态条件问题。
class Test01(val name: String){
}
class Test02{var test: Test01? = Test01("jpc")fun getName(){if (test != null){println(test.name)}}
}
解决办法
用了 also 标准函数,代码编译终于可以通过了。作为 also 函数的值参,it 取代了之前的类属性,它现在是匿名函数作用域内的局部变量。因而,it 变量值有了保障,任何别的代码都动不了它。取代原来可空的类属性,改后代码使用的是一个只读、不可空局部变量(test?.also表明,also 函数是在安全调用操作符之后调用的),因而强制类型转换问题完全避免了。
class Test01(val name: String){
}
class Test02{var test: Test01? = Test01("jpc")fun getName(){test?.also { println(it.name)}}
}
Kotlin 还提供了 Java 里没有的 internal 可见性修饰符。internal 可见性可以让函数、类和属性被同一模块(module)内的其他函数、类和属性使用。模块是独立的功能单元,你可以单独运行、测试或调试它。
(2)初始化
给对象分配内存就是实例化对象,给对象赋值就是初始化对象。然而,实战中这两个术语有不同的用法。通常,初始化是指为让变
量、属性或类实例可用而做的一切工作。而实例化倾向于仅仅指“创建一个类实例”。
主构造函数
对于 name 以外的构造函数参数,你都要指定它是可写还是只读。通过在构造函数里使用 val或 var 关键字指定参数,你定义了类属性。无论是 val 属性还是 var 属性,构造函数都需要对应参数的值参。而且,每个属性都被隐式地赋予了对应值参。
重复的代码会更难修改。通常,我们更喜欢用这种方式定义类属性,因为它会减少重复的代码。由于需要自定义 getter 和 setter 方法,name 属性无法使用这样的属性定义语法。但不管怎样,在 Kotlin 中,在主构造函数中定义类属性往往最简单直接。
class Demo11(_name: String, val age: Int, var sex: String) {var name: String = _name // _表示是一个临时变量get() = field.capitalize()set(value: String){field = value.uppercase()}
}
次构造函数
次构造函数要么直接调用主构造函数(传入它需要的值参),要么通过调用另一个次构造函数间接调用主构造函数。例如,正常情况下,玩家的开局状况都会是 100 健康值,很走运,并且总是会死。你可以定义一个次构造函数来配置这种状态属性。
初始化顺序
(1) 主构造函数里声明的属性(val health: Int)。
(2) 类级别的属性赋值(val race = “DWARF”,val
town = “Bavaria”,val name = _name)。
(3) init 初始化块里的属性赋值和函数调用(alignment
= “GOOD”、println 函数)。
(4) 次构造函数里的属性赋值和函数调用(town = “The Shire”)
需要说明的是,init 初始化块和类级别的属性赋值的顺序取决于定义的先后。如果 init 初始化块定义在类级别的属性赋值之前,那么它就比类级别的属性赋值早一步初始化。
class Demo11(_name: String, var age: Int = 20, var sex: String = "man") {// 初始化块 初始化块代码会在构造类实例时执行init {if (age <= 0 || age >= 120)age = 20}var name: String = _name // _表示是一个临时变量get() = field.capitalize()set(value: String){field = value.uppercase()}// 次构造函数// this 关键字指的是构造函数所在的类实例,也就是调用主构造函数constructor(name: String): this(name, age = 20, sex = "man")
}
延迟初始化
只要在引用之前能保证初始化延迟初始化变量,一切都没问题,
否则就会触发 UninitializedPropertyAccessException 异常。
class Test03{private lateinit var name: Stringfun setName(name: String){this.name = name}
}
惰性初始化
延迟初始化并不是推后初始化的唯一方式。你也可以暂时不初始化某个变量,直到首次使用它。这个概念名叫惰性初始化。尽管名字听起来不够积极向上,但它确实能让代码执行更有效率。
惰性初始化在 Kotlin 里是使用一种叫代理的机制来实现的。代理负责约定属性该如何初始化。使用代理要用到 by 关键字。Kotlin 标准库里有一些预先配置好的代理可用,lazy 就是其中
一个。惰性初始化会用到 lambda 表达式,你可以在表达式里定义属性初始化需要执行的代码。
class Test04{val name:String by lazy { initName() }fun initName(): String{return "jpc"}
}
name直到首次被引用时才会被初始化。到那时,lazy 的 lambda 表达式中的所有代码都会被执行一次且只会执行一次。
惰性初始化虽然有用,但代码实现稍显烦琐,建议在处理计算密集型任务时使用。
计算密集型和IO密集型是指在计算机系统中不同类型的任务负载。
- 计算密集型任务是指需要大量CPU计算资源来执行的任务,通常涉及大量的数学运算或逻辑判断。这种任务通常会占用大量的CPU时间,但对于内存和硬盘的需求相对较低。
- IO密集型任务是指需要大量输入/输出操作(如读写文件、网络通信等)来执行的任务。这种任务通常会占用大量的IO资源,包括磁盘IO、网络IO等,而对于CPU的需求相对较低。
在设计和优化系统时,了解任务的类型可以帮助我们选择合适的硬件配置和优化策略,以提高系统的性能和效率。
(3)继承
类默认都是封闭的,也就是说不允许其他类来继承自己。要让某个类开放继承,必须使用 open 关键字修饰它。
要想某个函数不被子类覆盖,就使用 final 关键字修饰它。
open class Father{open fun say(){println("father say")}
}class Son: Father(){// 子类覆盖父类的方法,父类方法需要使用open关键字override fun say(){println("son say")}
}
Kotlin中使用 is关键字进行类型检查
fun main() {val son = Son()println(son is Father)
}
在 Kotlin中,无须在代码里显式指定,每一个类都会继承一个共同的叫作 Any 的超类。
Kotlin中类型转换使用 as 关键字。
fun testAs(any: Any){if (any is Father){// 因为any是Father类型,所以可以直接调用函数// 这叫做 智能类型转换any.say()}else{(any as Father).say()}
}
(4)object 关键字
使用 object 关键字有三种方式:对象声明(object declaration)、对象表达式(object expression)和伴生对象(companion object)。
对象声明
// 这是一个 object 对象声明,表示这个对象是单例的,就像Java中的类的静态方法一样
object Class1{init {println("这是object 对象声明")}fun say(){println("hello kotlin")}
}fun main() {// 可以直接通过对象名调用对象的方法Class1.say()
}
对象表达式
有时候你不一定非要定义一个新的命名类不可。也许你需要某个现有类的一种变体实例,但只需用一次就行了。事实上,对于这种用完就丢的类实例,连命名都可以省了。
open class TestObject{open fun say(){println("hello")}
}fun main() {// 这是 object对象表达式,表示这个对象是匿名的,就像Java中的匿名内部类一样val clazz = object : TestObject(){// 重写父类的方法override fun say(){super.say()println("kotlin")}}clazz.say()
}
伴生对象
如果你想将某个对象的初始化和一个类实例捆绑在一起,可以考虑使用伴生对象。使用companion 修饰符,你可以在一个类定义里声明一个伴生对象。一个类里只能有一个伴生对象。
伴生对象初始化也分两种情况。
- 第一种,包含伴生对象的类初始化时,伴生对象就会被初始化。由于这种相伴关系,伴生对象就适合用来存放和类定义有上下文关系的单例数据。
- 第二种,只要直接访问伴生对象的某个属性或函数,就会触发伴生对象的初始化。
伴生对象本质上依然是个对象声明,所以不需要使用类实例来访问它内部定义的函数或属性。
class TestCompanion{// 无论 TestCompanion 类有多少个实例,只有一个 NAMEcompanion object{const val NAME: String = "kotlin"}
}// 调用
println(TestCompanion.NAME)
(5)嵌套类
使用 class 关键字定义一个嵌套在另一个类里的命名类。
class TestClass{fun say(){val innerClass = InnerClass()innerClass.say()}private class InnerClass{fun say(){println("hello")}}
}
(6)数据类
数据类就是专门设计用来存储数据的类,使用data修饰。
一个类要成为数据类,也要符合一定条件。总结下来,主要有三个方面:
- 数据类必须有至少带一个参数的主构造函数;
- 数据类主构造函数的参数必须是 val 或 var;
- 数据类不能使用abstract、open、sealed 和 inner 修饰符。
data class Data(val name: String, val age: Int) {// 数据类默认实现了 toString()、hashCode()、equals()、copy() 方法
}
(7)枚举类
枚举类(enumerated class),或简称为“enum”,是用来定义常量集合的一种特殊类,也叫枚举类型(enumerated types)。
enum class Color{RED, GREEN, BLUE;// 定义一个方法fun getMnemonic(color: Color) =when(color) {Color.RED -> "Richard"Color.GREEN -> "Gave"Color.BLUE -> "Battle"}
}
代数数据类型(ADT,algebraic data type)可以用来表示一组子类型的闭集。实际上,枚举类就是一种简单的 ADT。
使用枚举类型和其他代数数据类型有一个好处,即编译器会帮你检查代码处理是否有遗漏,因为代数数据类型表示的是一组子类型的闭集。
对于更复杂的 ADT,你可以使用 Kotlin 的密封类(sealed class)来实现更复杂的定义。密封类可以用来定义一个类似于枚举类的 ADT,但你可以更灵活地控制某个子类型。
enum class StudentStatus { NOT_ENROLLED, ACTIVE, GRADUATED; var courseId: String? = null // Used for ACTIVE only
}
// 一个更好的方案是使用密封类来表示学生状态:
sealed class StudentStatus { object NotEnrolled : StudentStatus() class Active(val courseId: String) : StudentStatus() object Graduated : StudentStatus()
}
StudentStatus 密封类可以有若干个(有数目限制的)子类。不过,要继承 StudentStatus密封类,这些子类必须和它定义在同一个文件里。定义密封类而不是枚举类允许你定义多个
StudentStatus 子类。然后,如果要使用 when 表达式判断学生状态,编译器同样会检查所有属性是否都得到了处理。由于 NotEnrolled、Active 和 Graduated 都是 StudentStatus 子类,
控制它们更加灵活了。不需要课程 ID 的学生状态子类用一个单例就能搞定,所以定义时用了 object 关键字。定义 Active 子类用了 class 关键字,因为不同的学生会选不同的课,所以需要多个实例对应。
when 表达式里用上新定义的密封类后,通过智能类型转换,从 Active 子类里读取 courseId比以前更灵活了。
fun main(args: Array<String>) { val student = Student(StudentStatus.Active("Kotlin101")) studentMessage(student.status)
}
fun studentMessage(status: StudentStatus): String { return when (status) { is StudentStatus.NotEnrolled -> "Please choose a course!" is StudentStatus.Active -> "You are enrolled in: ${status.courseId}" is StudentStatus.Graduated -> "Congratulations!" }
}
(8)运算符重载
Java 不支持运算符重载。Java 语言设计者认为运算符重载会增加代码的复杂性和难以理解性,因此在 Java 中没有提供这个特性。如果您需要实现类似的功能,可以考虑使用方法重载或其他设计模式来达到相同的效果。
但是Kotlin支持运算符重载。
data class NumberClass(val x: Int, val y: Int){// 重载运算符,使用 operator 关键字operator fun plus(other: NumberClass): NumberClass{return NumberClass(x + other.x, y + other.y)}
}
列出了一些常见运算符,你可以根据需要重载它们。

(9)接口和抽象类
Kotlin 规定所有的接口属性和函数实现都要使用 override 关键字。
另一方面,接口中定义的函数并不需要使用 open 关键字修饰。这是因为添加到接口中的属性和函数默认就是 open 的,它们生来就是要对外开放的。
要定义一个抽象类,你需要在类定义之前加上 abstract 关键字。除了具体的函数实现,抽象类也可以包含抽象函数——只有定义,没有函数实现。
接口里不能定义构造函数。其次,一个类只能继承一个抽象类,但可以实现多个接口。日常开发时,对于如何使用它们,有个不错的经验法则:在你需要一组公共对象行为或属性时,如果继承行不通,就用接口。另一方面,如果继承可行,但你又不需要父类太具
体,那就用抽象类。(如果还想实例化父类,那就只能用一般类。
10、泛型
List 集合支持泛型(generic),所以它能存放任何类型。泛型系统允许函数和其他类型接受你或编译器当前无法预知的类型,大大提高了代码的复用率。
(1)泛型类
泛型类的构造函数可以接受任何类型。
class Test<T>(item: T){private val name: T = item
}
(2)泛型函数
泛型参数也可以用于函数。
class Test<T>(item: T){private val name: T = itemfun getItem():T{return name}
}
(3)多泛型参数
泛型函数或泛型类也可以有多个泛型参数。
这里,新 fetch 函数多了一个泛型参数 R。R 是英文单词 return 的缩写形式,表示这个泛型参数将用作 fetch 函数的返回类型。定义时,这个 R 泛型参数要放在尖括号里,置于函数名之前:fun fetch。fetch 返回的是一个 R?,即一个可空的 R 类型。
此外,由于函数类型声明(T) -> R,lootModFunction 函数能接受 T 类型的值参,返回一个 R 类型的结果值。
class Test<T>(item: T){var open = falseprivate val loot: T = itemfun <R> fetch(lootModFunction: (T) -> R): R?{return lootModFunction(loot).takeIf { open }}
}
既然 R 类型取决于匿名函数的返回结果,那么 lambda 表达式返回什么,fetch 函数就返回和它一样的类型值。
(4)泛型约束
给 LootBox 的泛型参数添加一个约束,只允许 Loot 类的子类用于 LootBox。
open class Loot(val name: String){}
// 添加泛型约束
class LootBox <T: Loot>(item: T){var open = falseprivate val loot: T = itemfun <R> fetch(lootModFunction: (T) -> R): R?{return lootModFunction(loot).takeIf { open }}
}
(5) vararg 关键字与 get 函数
使用一个 vararg关键字,就能让它接受多个值参。
有了这个 vararg 关键字,初始化 LootBox 泛型类时,就能把它的 item 变量看作元素数组,而非单个元素了。LootBox 的构造函数也就可以接受多个 item 值参了。
class LootBox <T: Loot>(vararg item: T){var open = falseprivate val loot: T = item[0] // 会将item看作数组fun <R> fetch(lootModFunction: (T) -> R): R?{return lootModFunction(loot).takeIf { open }}
}
根据需要,泛型参数可以扮演两种角色:生产者(producer)或消费者(consumer)。生产者角色就意味着泛型参数可读而不可写;消费者角色则相反,可写而不可读。
在Kotlin中,in和out关键字与泛型类型的协变和逆变有关。这些关键字用于指定泛型类型参数的变异性,从而增加代码的灵活性和安全性。
-
out: 当你想要确保类型参数只被用来从泛型类中读取数据时,可以使用
out。这意味着你可以将子类型对象的集合安全地赋值给父类型对象的集合。这被称为协变。例如,Producer<out T>意味着Producer<Derived>可以被当作Producer<Base>的子类来使用。 -
in: 相反地,当你想要确保类型参数只被用来向泛型类中写入数据时,可以使用
in。这意味着你可以将父类型对象的集合安全地赋值给子类型对象的集合。这被称为逆变。例如,Consumer<in T>意味着Consumer<Base>可以被当作Consumer<Derived>的超类来使用。
这些关键字对于创建类型安全的API非常重要,因为它们允许你定义哪些操作是安全的,从而防止在运行时出现类型错误。
例如,如果你有一个List<out Animal>,你可以安全地将其赋值给List<out Cat>,因为你只从列表中读取数据,而不会向其中添加数据。但是,你不能将List<in Cat>赋值给List<in Animal>,因为这将允许向List<in Animal>中添加任何类型的动物,这可能导致类型不匹配的问题。
(6)reified 关键字
有时候,你可能想知道某个泛型参数具体是什么类型。reified 关键字能帮你检查泛型参数类型。
通常情况下,Kotlin 不允许对泛型参数 T 做类型检查,因为泛型参数类型会被类型擦除(type erasure)。也就是说,T 的类型信息在运行时是不可知的。Java 也有这样的规则。
与 Java 不同,Kotlin 提供了 reified 关键字,它允许你在运行时保留类型信息。
有了 reified 关键字,不需要反射(reflection)我们也能检查泛型参数的类型了。反射是指在运行时了解一个属性或函数的名称或类型,是个开销很大的操作。
这个功能只能与inline函数一起使用,因为inline函数的代码在编译时会被内联到调用处,从而使得泛型参数的实际类型在运行时可知。
inline fun <reified T> myGenericFun(){val item: String = "hello"if (item is T){println("${T::class.simpleName}")}
}
在这个例子中,myGenericFun函数是一个内联函数,它有一个reified泛型参数T。在函数体内,我们可以使用T::class来获取T的实际类型,这在普通的泛型函数中是做不到的,因为泛型信息在运行时会被擦除。
当你调用myGenericFun()时,编译器会将myGenericFun函数的代码内联到调用处,并将T替换为String,这样就可以在运行时知道T的实际类型是String。
使用reified关键字可以让你编写更加灵活和强大的泛型函数,特别是在需要根据泛型参数类型进行特定操作时。
11、扩展
扩展可以在不直接修改类定义的情况下增加类功能。扩展可以用于自定义类,比如 List、String,以及 Kotlin 标准库里的其他类。
和继承类似,扩展也能共享类行为。在你无法接触某个类定义,或者某个类没有使用 open修饰符,导致你无法继承它时,扩展就是增加类功能的最好选择。
(1)定义扩展函数
定义扩展函数和定义一般函数差不多,但有一点大不一样:除了函数定义,你还需要指定接受功能扩展的接收者类型(receiver type)。
// 为String类添加一个扩展函数,用于移除字符串的首尾字符
// String就是接收者类型
fun String.removeFirstAndLast(): String{
// this 代指接收者实例return this.substring(1, this.length-1)
}fun main() {"hello world".removeFirstAndLast()
}
(2)应用场景
场景一:为现有类添加辅助函数
假设你经常需要为List类型的集合检查是否为空或仅包含一个元素。你可以为List添加一个扩展函数来简化这个操作:
fun <T> List<T>.isNullOrEmptyOrSingle(): Boolean {return this == null || this.size <= 1
}// 使用示例
val myList = listOf("Kotlin")
println(myList.isNullOrEmptyOrSingle()) // 输出 true
场景二:为现有类添加格式化输出
如果你想要为Date类添加一个自定义的格式化输出方法,可以使用扩展函数来实现:
import java.text.SimpleDateFormat
import java.util.Datefun Date.formatAsYearMonthDay(): String {val formatter = SimpleDateFormat("yyyy-MM-dd")return formatter.format(this)
}// 使用示例
val currentDate = Date()
println(currentDate.formatAsYearMonthDay()) // 输出当前日期的年-月-日格式
场景三:为现有类添加计算属性
你可以为String类添加一个计算属性来获取字符串的单词数量:
val String.wordCount: Intget() = this.split("\\s+".toRegex()).size// 使用示例
val myString = "Hello Kotlin World"
println(myString.wordCount) // 输出 3
场景四:为接口添加通用实现
如果有一个接口,你希望为所有实现该接口的类提供一个通用的方法实现,可以使用扩展函数:
interface Printer {fun print()
}fun Printer.printWithPrefix(prefix: String) {println(prefix)print()
}// 使用示例
class ConsolePrinter : Printer {override fun print() {println("Printing from ConsolePrinter")}
}val printer = ConsolePrinter()
printer.printWithPrefix("Start: ") // 输出 "Start: " 然后输出 "Printing from ConsolePrinter"
这些场景展示了扩展函数如何在不同的情况下增强现有类的功能。扩展函数的优势在于它们的灵活性和能力,使得你可以轻松地为任何类添加新的功能,而无需修改原始类定义。这对于处理不能修改的第三方库类尤其有用。扩展函数也是一种优雅的方式,用于将功能逻辑与类定义分离,使得代码更加模块化和可维护。
12、函数式编程
函数式编程范式主要依赖于**高阶函数(以函数为参数或返回函数)**返回的数据。这些高阶函数专用于处理各种集合,可方便地联合多个同类函数构建链式操作以创建复杂的计算行为。
一个函数式应用通常由三大类函数构成:变换(transform)、过滤(filter)和合并(combine)。
每类函数都针对集合数据类型设计,目标是产生一个最终结果。函数式编程用到的函数生来都是可组合的,也就是说,你可以组合多个简单函数来构建复杂的计算行为。
(1)变换
变换是函数式编程的第一大类函数。变换函数会遍历集合内容,用一个以值参形式传入的变换器函数变换每一个元素,然后返回包含已修改元素的集合给链上的其他函数。
最常用的两个变换函数是 map 和 flatMap。
map 变换函数会遍历接收者集合,让变换器函数作用于集合里的各个元素。返回结果是包含已修改元素的集合,会作为链上下一个函数的输入。flatMap函数操作一个集合的集合,将其中多个集合中的元素合并后返回一个包含所有元素的单一集合。
函数式编程的特点是组合多个函数以链式调用的形式操作数据。
原始集合没有被修改。map 变换函数和你定义的变换器函数做完事情后,返回的是一个新集合。
fun test01(){val list = listOf("java", "kotlin", "android")// 返回一个新的集合val newList = list.map { item ->// 首字母大写item.replaceFirstChar { it.uppercaseChar() }}newList.forEach{println(it)}
}
(2)过滤
过滤是函数式编程的第二大类函数。过滤函数接受一个 predicate 函数,用它按给定条件检查接收者集合里的元素并给出 true 或 false 的判定。如果 predicate 函数返回 true,受检元素就会添加到过滤函数返回的新集合里。如果 predicate 函数返回 false,那么受检元素就被移出新集合。
fun test02(){val list = listOf("java", "kotlin", "android")val filter = list.filter { it.length >= 5 }filter.forEach{println(it)}
}
(3)合并
合并是函数式编程的第三大类函数。合并函数能将不同的集合合并成一个新集合(这和接收者是包含集合的集合的 flatMap 函数不同)。
zip函数可以合并2个集合
fun test03(){val employees = listOf("Denny", "Claudette", "Peter")val shirtSize = listOf("large", "x-large", "medium")// zip 函数返回的是一个包含键值对的新集合val employeeShirtSizes = employees.zip(shirtSize).toMap()println(employeeShirtSizes["Denny"])
}
另一个可以用来合并值的合并类函数是 fold。这个合并函数接受一个初始累加器值,随后会根据匿名函数(针对集合元素调用)的结果更新。在下面这个例子里,fold 函数会遍历集合元素,将每个元素值乘以 3 后累加起来。
fun test04(){val sum = listOf(1, 2, 3, 4).fold(0){cnt, num ->cnt + num*3}println(sum)
}
使用函数式编程的优点:
(1) 累加变量(如 employeeShirtSizes)都是隐式定义的,所以可以少用状态变量。
(2) 函数运算结果会自动赋值给累加变量,降低了代码出错的机会。
(3) 执行新任务的函数很容易添加到函数调用链上,因为它们都兼容 Iterable类型。
(4)序列
List、Set 以及 Map 集合类型。这几个集合类型统称为及早集合(eager collection)。这些集合的任何一个实例在创建后,它要包含的元素都会被加入并允许你访问。
对应及早集合,Kotlin 还有另外一类集合:惰性集合(lazy collection)。你见识过惰性初始化(类属性的初始化延后至首次被访问时)。类似于类的惰性初始化,惰性集合类型的性能表现优异——尤其是用于包含大量元素的集合时——因为集合元素是按需产生的。
Kotlin 有个内置惰性集合类型叫序列(Sequence)。序列不会索引排序它的内容,也不记录元素数目。事实上,在使用一个序列时,序列里的值可能有无限多,因为某个数据源能产生无限多个元素。
针对某个序列,你可能会定义一个只要序列有新值产生就被调用一下的函数,这样的函数叫迭代器函数(iterator function)。要定义一个序列和它的迭代器,你可以使用 Kotlin 的序列构造函数 generateSequence。generateSequence 函数接受一个初始种子值作为序列的起步值。在用generateSequence 定义的序列上调用一个函数时,generateSequence 函数会调用你指定的迭代器函数,决定下一个要产生的值。
例子:从 3(种子值)起步,generateSequence 会以加 1 递增的方式,一次产生一个新值。然后,it 会使用 isPrime 扩展函数过滤掉非素数。一直这样找下去,直到产生1000 个素数。既然无法知道待查数有多少,那么比较理想的方式就是,一次产生一个新值用于检查,直到 take 函数得到满足为止。
fun Int.isPrime(): Boolean{(2..(sqrt(this.toDouble()).toInt())).map {if (this % it == 0)return false}return true
}
fun test05(){val sequence = generateSequence(3) { value -> value + 1 }.filter { it.isPrime() }.take(1000)sequence.forEach { println(it) }
}
一般来讲,你操作的集合都比较小,集合里的元素应该不超过 1000 个。如果确实如此,那就没必要纠结用序列还是 List,因为数据量不大的情况下,这两个集合类型的性能差异几乎可以忽略——大概是纳秒级。但对于包含几十万甚至上百万元素的大集合,不同集合的性能差异就太大了。遇到这种情况时,你可以像这样把 List 转换为性能好的序列。
fun test06(){val toList = (0..100000000).toList()val asSequence = toList.asSequence()
}
(5)测试代码执行性能
如果想知道代码执行性能,你可以使用 Kotlin 的measureNanoTime 和 measureTimeInMillis
这两个函数来测量代码执行速度。这两个函数都支持 lambda 表达式值参,能估算置入 lambda 表达式里的代码的执行时间。measureNanoTime 函数返回的是纳秒时间,measureTimeInMillis函数返回的是毫秒时间。
fun Int.isPrime(): Boolean{(2..(sqrt(this.toDouble()).toInt())).map {if (this % it == 0)return false}return true
}
fun sequenceMethod(){val sequence = generateSequence(2) { value -> value + 1 }.filter { it.isPrime() }.take(1000)
}
fun listMethod(){val list = (1..7926).toList().filter { it.isPrime() }.take(1000)
}
fun test07(){val sequenceTime = measureNanoTime { sequenceMethod() }val listTime = measureNanoTime { listMethod() }println("$sequenceTime, $listTime")
}
(6)Arrow.kt
使用 Arrow.kt 这样的库,Kotlin 也能享用到许多 Haskell 里才有的函数式编程特性。
例如,Arrow.kt 库里有个叫 Either 的类型,对应的就是 Haskell 里的 Maybe 类型。使用Either,无须抛出异常和使用 try/catch 逻辑,你也能妥善处理某个会出错的操作。
假设有个函数的作用是把用户输入的一个字符串转换为一个 Int。如果用户输入的是数字,则直接转为 Int 值。但如果是无效输入,则提示有错误并处理之。
使用 Either,代码可以这样写:
导入依赖库
implementation("io.arrow-kt:arrow-core:1.2.4")
fun parse(s: String): Either<NumberFormatException, Int> =if (s.matches(Regex("-?[0-9]+"))) {Either.Right(s.toInt())} else {Either.Left(NumberFormatException("$s is not a valid integer."))}fun main() {val x = parse("123")val value = when(x) {is Either.Left -> when (x.value) {is NumberFormatException -> "Not a number!"else -> "Unknown error"}is Either.Right -> "Number that was parsed: ${x.value}"}println(value)
}
13、Kotlin和Java互操作
Kotlin 可以编译成 Java 字节码。这意味着 Kotlin 支持和 Java 互操作,也就是说,Kotlin 代码可以 Java 代码一起工作,一起执行特定任务。
毫不夸张地说,这应该是 Kotlin 编程语言最重要的特性。与 Java 的无缝式互操作性表明,Kotlin 文件可以和 Java 文件共存于同一项目。无论是从 Kotlin 里调用 Java 方法,还是反过来,都不是问题。当然,在 Kotlin 里使用现有的 Java 库,包括 Android 框架库也没有任何问题。
使用@Nullable 注解表明某个方法可能返回 null。你也可以使用@NotNull 来表明某个值永远不会为 null。
14、协程
Kotlin 协程支持异步处理任务,或干脆把任务放在应用后台处理。这样,用户无须等待即可继续使用应用,让任务自己在后台继续运行直至完成。
Kotlin 协程的资源利用效率更高。相比 Java 等其他编程语言使用的线程(稍后会介绍),Kotlin协程要更加易用。使用线程需要编写复杂的代码来处理线程之间的信息传递,还会受性能问题的折磨,因为线程很容易被阻塞。
的 Deferred 就像一个对未来结果的约定:不发出请求就不会有数据返回。
class NewCharacterActivity : AppCompatActivity() { ... override fun onCreate(savedInstanceState: Bundle?) { ... generateButton.setOnClickListener { launch(UI) { characterData = fetchCharacterData().await()displayCharacterData() } } displayCharacterData() } ...
}
首先,你调用 launch 函数创建了一个新协程。你安排的任务会立即在这个新协程里开始执行。launch 函数的值参是 UI,它指定协程的上下文环境(即 lambda 表达式里的任务要在哪里执行)为 Android 的 UI 线程。
Android 禁止在主线程上访问网络。协程上下文的默认值参是 CommonPool。它是一个用来执行协程的后台线程池,同时也是 async 函数默认使用的值参,所以调用 await函数时,Web API 调用请求是使用线程池而不是主线程来执行的。
- 用来调用 Web API 和更新 UI 的 async 和 launch 函数又叫作协程创建函数。
- launch 创建的协程会立即执行指定任务——这里指的是调用 fetchCharacterData 和更新 UI。
- async 协程创建函数人工作方式和 launch 不同,因为它创建的协程的返回值类型是 Deferred,表示任务还没有完成,会在未来某个时间完成。
- 一个执行挂起函数的线程还能用来执行其他协程。挂起函数都带 suspend 关键字。以下是 await 函数的函数签名:public suspend fun await(): T





 ----------线性回归算法(梯度下降+正则化))













