在之前的文章中,我们了解我们的机器学习,了解我们spark机器学习中的MLIib算法库,知道它大概的模型,熟悉并认识它。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-机器学习(1)什么是机器学习与MLlib算法库的认识-CSDN博客文章浏览阅读3.7k次,点赞72次,收藏59次。从这一系列开始,我会带着大家一起了解我们的机器学习,了解我们spark机器学习中的MLIib算法库,知道它大概的模型,熟悉并认识它。同时,本篇文章为个人spark免费专栏的系列文章,有兴趣的可以收藏关注一下,谢谢。同时,希望我的文章能帮助到每一个正在学习的你们。也欢迎大家来我的文章下交流讨论,共同进步。https://blog.csdn.net/qq_49513817/article/details/137754753
今天的文章,我会带着大家一起了解我们的特征提取和我们的tf-idf,word2vec算法。希望大家能有所收获。
目录
一、特征提取
什么是特征提取?
特征提取与机器学习的关系
二、示例代码
tf-idf实现文档向量化(词频-逆文档频率计算)
tf-idf是什么
代码实现
word2vec(创建 K 维度的稠密向量)
word2vec是什么?
代码实现
拓展-特征提取的各种方法简单示例及优点
一、特征提取
什么是特征提取?

特征提取
特征提取(Feature Extraction)是机器学习和模式识别中的一个重要步骤,旨在从原始数据中提取出有意义的、对解决问题有帮助的信息,即特征。这些特征通常是对原始数据的简化表示,能够捕捉数据的关键属性,同时减少数据的复杂性和冗余性。
特征提取的主要目的是:
- 降维:将原始数据从高维空间映射到低维空间,使得后续的数据处理和模型训练更加高效。
- 提高模型性能:通过提取有意义的特征,可以提高机器学习模型的性能,如分类准确率、回归精度等。
- 增强模型的可解释性:通过特征提取,可以使得模型更加容易理解和解释,有助于人们理解数据的内在规律和模式。
特征提取的方法多种多样,具体取决于数据的类型和问题的性质。例如,在文本处理中,常用的特征提取方法包括词袋模型(Bag of Words)、TF-IDF(词频-逆文档频率)、n-gram模型、词嵌入(如Word2Vec、GloVe)等。在图像处理中,常用的特征提取方法包括SIFT(尺度不变特征变换)、SURF(加速鲁棒特征)、HOG(方向梯度直方图)等。
在进行特征提取时,需要注意以下几点:
- 选择有意义的特征:确保提取的特征与解决问题密切相关,避免引入无关或冗余的特征。
- 避免过拟合:避免提取过多的特征,以免导致模型过拟合。通常需要通过交叉验证等技术来评估特征提取的效果。
- 考虑计算效率:特征提取的过程应尽可能高效,避免在大数据集上花费过多的计算资源。
最后,特征提取是机器学习和模式识别中的一个关键环节,通过提取有意义的特征,可以提高模型的性能、可解释性和计算效率。
特征提取与机器学习的关系

特征提取与机器学习之间存在密切的关系。特征提取是机器学习流程中的一个关键步骤,对于模型的性能和效果具有重要影响。以下是特征提取与机器学习之间的主要关系:
-
数据预处理:在机器学习项目的开始阶段,通常需要对原始数据进行预处理。特征提取是预处理的一个重要环节,它可以将原始数据转化为机器学习算法更容易理解和利用的形式。
-
模型输入:机器学习算法通常依赖于特征作为输入。特征提取的过程就是将原始数据转化为这些特征。因此,特征提取的质量直接影响机器学习模型的性能。如果提取的特征不能很好地表示数据的内在规律和模式,那么模型的性能可能会受到限制。
-
降低维度和复杂度:原始数据可能包含大量的特征和维度,这可能导致计算复杂度高和模型过拟合的问题。特征提取可以通过选择最重要的特征或转换原始特征来降低数据的维度和复杂度,从而提高模型的效率和性能。
-
提升模型性能:合适的特征提取方法可以使机器学习模型更容易学习和识别数据的模式。通过提取与问题相关的特征,模型能够更准确地做出预测或分类,从而提升模型的性能。
-
模型解释性:特征提取有助于增强模型的解释性。通过提取有意义的特征,我们可以更好地理解模型是如何根据这些特征做出决策的,从而增加对模型工作原理的洞察力。
我们需要注意的是,特征提取是一个需要经验和技巧的过程。不同的数据集和问题可能需要不同的特征提取方法。因此,在进行特征提取时,需要根据具体的应用场景和数据特点进行选择和调整。
二、示例代码
在本篇文章中,我会提供tf-idf与word2vec两种算法的简单示例
tf-idf实现文档向量化(词频-逆文档频率计算)
tf-idf是什么
Word2Vec是用一个一层的神经网络(即CBOW)将one-hot形式的稀疏词向量映射为一个n维(n一般为几百)的稠密向量的过程。这种n维的稠密向量即为word2vec中的K维度稠密向量。相较于传统NLP的高维、稀疏的表示法(One-hot Representation),Word2Vec训练出的词向量是低维、稠密的,其语义信息更加丰富。这种表示方法使得意思相近的词在向量空间中会被映射到相近的位置。
-
TF(词频):某一给定词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
-
IDF(逆文档频率):一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。如果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。
TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关度的度量或评级。除了TF和IDF以外,还有一系列的TF-IDF变种,以及每一个变种自己的权重分数归一化方案。
代码实现
这里我们有一个名为tf-idf.txt的文本文档,我们需要将它从指定地址提取文档文件并进行我们的文档向量化。
import org.apache.spark.rdd.RDD
import org.apache.spark.SparkContext
import org.apache.spark.mllib.feature.HashingTF
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.feature.IDF
val p = sc.textFile("/opt/spark-3.2.1/P/tf-idf.txt").map(_.split (" ").toSeq)
val HashingTF = new HashingTF()
val tf = HashingTF.transform(p).cache()
val idf = new IDF().fit(tf)
val pp = idf.transform(tf)
pp.collect.foreach(print)- 首先,我导入了必要的Spark类和对象
- 然后,我读取了一个文本文件,并将每一行分割成单词序列。使用
map函数将每一行文本分割成单词,并将这些单词转换为一个序列(Seq)。 - HashingTF将单词序列转换为哈希特征向量。并计算每个单词在文档中的词频。然后使用cache()`方法缓存了结果,以便在后续的操作中重复使用,而不必重新计算。
- IDF`对象会计算每个特征的逆文档频率。
- 最后,使用IDF模型转换数据,并打印结果

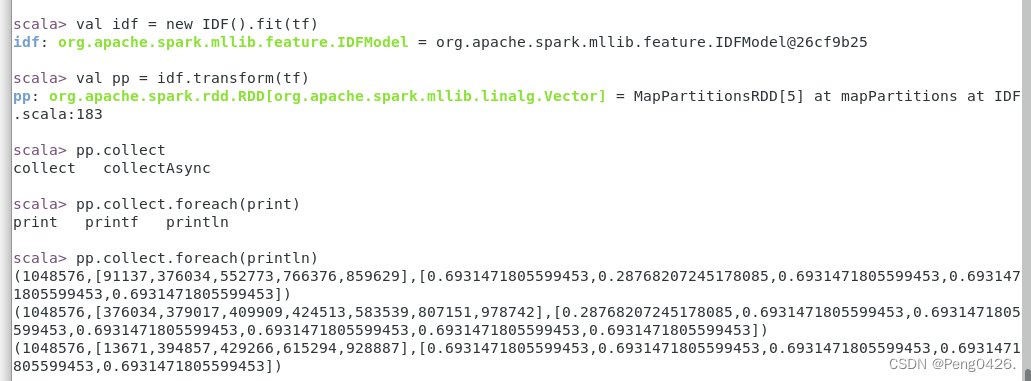
这样我们就成功实现了文档向量化
word2vec(创建 K 维度的稠密向量)
word2vec是什么?
Word2Vec 是一种用于生成词向量的深度学习模型,由 Google 的研究人员在 2013 年提出。该模型的核心思想是通过训练神经网络来学习词汇表中每个单词的分布式表示(distributed representation),通常是一个固定维度的实数向量。这些向量能够捕捉单词之间的语义和语法关系,使得语义上相近的单词在向量空间中的位置也相近。
Word2Vec 主要包含两种训练方式:Skip-gram 和 Continuous Bag of Words (CBOW)。
-
Skip-gram:给定一个中心词,Skip-gram 模型的目标是预测其上下文中的其他词。也就是说,模型通过中心词来预测其周围的词。
-
CBOW:与 Skip-gram 相反,CBOW 模型通过上下文中的词来预测中心词。模型将上下文中的词作为输入,并尝试预测中心词。
这两种方法都基于一个假设:具有相似上下文的词在语义上也是相似的。因此,通过训练模型来预测上下文或中心词,我们可以学习到每个词的向量表示,这些向量能够捕捉词之间的语义关系。
代码实现
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.SparkSession // 创建 Spark 配置和上下文
val conf = new SparkConf().setAppName("Word2VecExample").setMaster("local[*]")
val sc = new SparkContext(conf)
val spark = SparkSession.builder().appName("Word2VecExample").getOrCreate()
import spark.implicits._ // 假设你的文本数据在 "/opt/spark-3.2.1/P/word2vec.txt" 文件中
val input = sc.textFile("/opt/spark-3.2.1/P/word2vec.txt") // 将文本数据转换为 RDD[Seq[String]],其中每个 Seq[String] 代表一个文档
val sentences = input.map(_.split("\\s+").toSeq) // 设置 Word2Vec 参数
val word2Vec = new Word2Vec() .setInputCol("text") .setOutputCol("result") .setVectorSize(100) // 设置词向量的维度,例如 100 .setMinCount(5) // 设置最小词频,例如 5 .setNumIterations(1) // 设置训练迭代次数 // 使用 Word2Vec 训练模型
val model = word2Vec.fit(sentences.toDF("text")) // 查找特定词的向量
val findVectors = model.transform(sentences.toDF("text"))
val vectorForHi = findVectors.select("result").where($"text" === Seq("Hi")).first().getAs[Vector](0)
println(s"Vector for 'Hi': $vectorForHi") 这样我们就可以查找特定词的向量。
拓展-特征提取的各种方法及优点
| 算法 | 说明 | 优点 |
|---|---|---|
| TF-IDF | 在文本处理中,TF-IDF是一种统计方法,用于评估一个词对于一个文件集或一个语料库中的其中一份文件的重要程度。TF表示词频,即一个词在文档中出现的次数;IDF表示逆文档频率,即一个词在所有文档中的普遍重要性。两者相乘,就得到一个词的TF-IDF值。 | - 能够综合考虑词在文档中的出现频率和在整个语料库中的稀有性。 |
| - 适用于文本分类、信息检索等任务。 | ||
| - 能够有效地提取出文本中的关键信息。 | ||
| 主成分分析 (PCA) | 假设有一个数据集包含多个特征,PCA 可以将这些特征转换为一组新的正交特征,即主成分,这些主成分捕获了数据中的最大变化方向。 | - 降低数据维度,减少计算复杂度。 |
| - 去除噪声和冗余特征,提高模型性能。 | ||
| - 易于理解和可视化。 | ||
| 线性判别分析 (LDA) | 在分类问题中,LDA 试图找到最能区分不同类别的特征。例如,在面部识别中,LDA 可以找到最能区分不同人脸的特征。 | - 能够找到最具区分性的特征,提高分类性能。 |
| - 对数据的分布有一定的鲁棒性。 | ||
| SIFT (尺度不变特征变换) | 在图像处理中,SIFT 算法可以提取图像的关键点(如角点、边缘点等),并为每个关键点生成一个具有尺度、旋转和光照不变性的描述子。 | - 对尺度、旋转和光照变化具有不变性。 |
| - 适用于复杂场景和大量数据的处理。 | ||
| - 提取的特征具有较高的鲁棒性和独特性。 | ||
| Word2Vec | 在自然语言处理中,Word2Vec 将每个单词转换为一个固定维度的实数向量,这些向量能够捕捉单词之间的语义和上下文关系。 | - 捕捉单词的语义和上下文信息,提高文本处理任务的性能。 |
| - 适用于各种自然语言处理任务,如文本分类、情感分析等。 |