什么是RAG
检索增强生成(Retrieval Augmented Generation,简称RAG)为大型语言模型(LLMs)提供了从某些数据源检索到的信息,以此作为生成答案的基础。简而言之,RAG是搜索+LLM提示的结合,即在有搜索算法找到的信息作为上下文的情况下,让模型回答提出的查询。查询和检索到的上下文都被注入到发送给LLM的提示中。
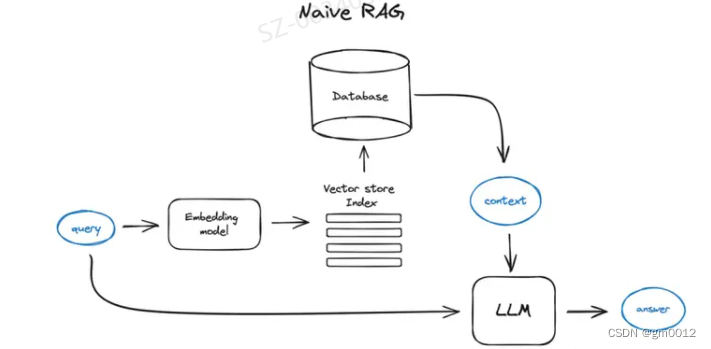
原理流程
将文本分割成块,然后使用基于Transformer decoder的模型将这些块嵌入到向量中,将所有这些向量放入一个索引中,最后为LLM创建一个提示,告诉模型在我们在搜索步骤中找到的上下文中回答用户的查询。
在运行时,我们使用相同的编码器模型将用户的查询向量化,然后对索引执行这个查询向量的搜索,找到前k个结果,从我们的数据库中检索相应的文本块,并将它们作为上下文输入到LLM的提示中。
切分和向量化
首先,我们想创建一个向量索引,代表我们文档的内容,然后在运行时搜索这些向量与查询向量之间最小的余弦距离,对应于最接近的语义含义。
切分:Transformer模型有固定的输入序列长度,即使输入上下文窗口很大,一个句子或几个句子的向量也比几页文本的平均向量更好地代表它们的语义含义(也取决于模型,但通常如此),所以要切分你的数据——将初始文档切分为某个大小的块,不会丢失它们的含义(将文本切分为句子或段落,而不是将单个句子切成两部分)。有各种文本分割器实现能够完成这项任务。
块的大小是一个需要考虑的参数——它取决于你使用的嵌入模型及其在令牌上的容量,标准的Transformer编码器模型如基于BERT的句子转换器最多接受512个令牌,OpenAI ada-002能够处理更长的序列,如8191个令牌,但这里的折中是为LLM提供足够的上下文进行推理与执行搜索的足够具体的文本嵌入。最近的一项研究[3]说明了块大小选择的考虑因素。在LlamaIndex中,这是通过NodeParser类来覆盖的,它提供了一些高级选项,如定义自己的文本分割器、元数据、节点/块关系等。
向量化:下一步是选择一个模型来嵌入切割后的块——有很多选择,例如像bge-large或E5嵌入系列这样的搜索优化模型
向量存储索引:RAG管道的关键部分是搜索索引,它存储了我们在上一步中获得的向量化内容。最简单的实现使用平面索引——在查询向量和所有块向量之间进行暴力距离计算
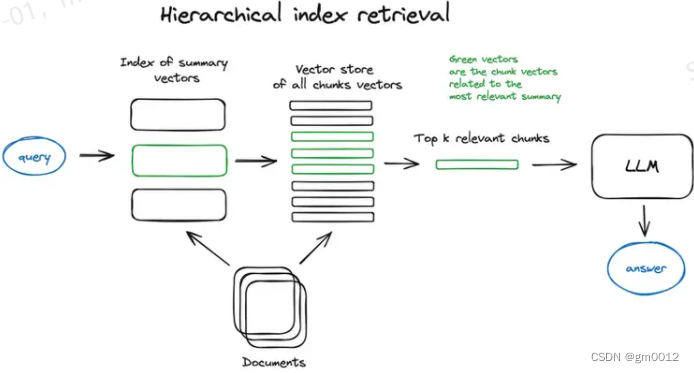
分层索引:如果您需要从许多文档中检索信息,您需要能够有效地在其中搜索,找到相关信息,并将其综合为带有来源引用的单一答案。在大型数据库中做到这一点的有效方法是创建两个索引——一个由摘要组成,另一个由文档块组成,并分两步进行搜索,首先通过摘要筛选出相关文档,然后仅在这个相关组内搜索。
上下文丰富化:上下文丰富化是检索更小的块以提高搜索质量,但添加周围上下文让LLM进行推理。通常有两种做法——通过在检索到的较小块周围的句子扩展上下文,或者将文档递归地分割成包含较小子块的多个较大的父块。
句子窗口检索:在这个方案中,文档中的每个句子都分别嵌入,这提供了极高的查询与上下文余弦距离搜索的准确性。为了在找到最相关的单个句子后更好地推理所发现的上下文,我们通过在检索到的句子前后扩展k个句子的上下文窗口,然后将这个扩展的上下文发送给LLM

自动合并检索器(又称父文档检索器):这里的想法与句子窗口检索非常相似——搜索更精细的信息片段,然后在将这些上下文提供给LLM进行推理之前扩展上下文窗口。文档被分割成较小的子块,这些子块引用较大的父块。
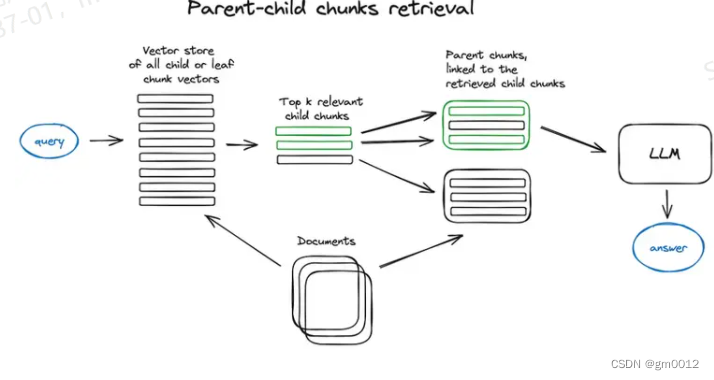
在这种方法中,首先在更细粒度的子块上进行搜索,找到与查询最相关的块。然后,系统会自动将这些子块与它们所属的更大的父块结合起来。这样做的目的是在回答查询时为LLM提供更丰富的上下文。例如,如果一个子块是一段或一小节,父块可能是整个章节或文档的一大部分。这种方法既保留了检索精度(因为是在更小的块上搜索),同时也通过提供更广泛的上下文来增强LLM的推理能力。

)








23-54)


策略下的Prompt)
)




