本期作者

背景
Matroska是一种开放标准、功能强大的多媒体封装格式,可容纳多种不同类型的视频、音频及字幕流,其常见的文件扩展名为.mkv、.mka等。与应用广泛的MP4相比,Matroska更加灵活开放,可以同时容纳多个字幕,甚至可以包含章节、标签等信息,成为了许多用户的偏爱。B站Web投稿页上传的所有视频中,封装格式为Matroska的视频占比超过2%,是除MP4以外占比最高的格式。
Web投稿页作为稿件生产的第一个环节,在获取到用户上传的视频后会根据视频内容为用户投稿提供辅助,其中包含:
-
获取视频元信息,为快速转码提供预分析,缩短转码等待时间,同时为页面其他功能提供视频的基本数据。
-
获取视频抽帧画面,对视频画面进行计算,根据计算结果进行AI智能推荐及自动填写,如封面推荐、分区推荐等,为用户填写稿件信息提供辅助。
而这些内容的实现,都基于对视频文件的解析,其中又包含了解封装和解码两个部分。
通用方案
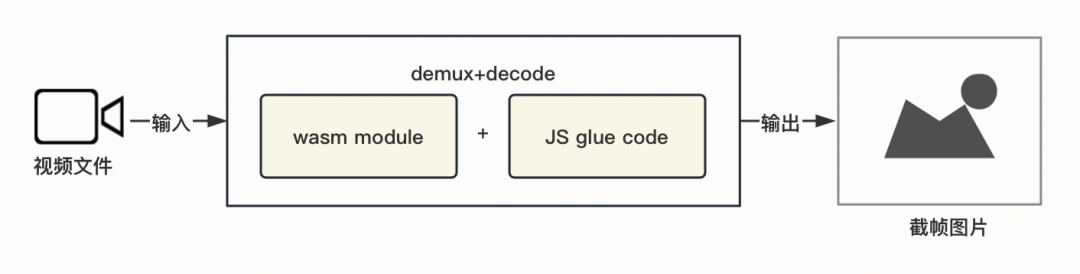
此前,Web投稿页的实现方案为使用Emscripten将FFmpeg编译为WebAssembly后在Web平台运行,借助FFmpeg的音视频处理能力来进行解封装和解码。这种方案的优点是支持的视频格式齐全,可以解析几乎所有视频格式,但其缺点也很明确——解析速度慢,无法使用硬件加速,性能不佳,内存消耗大,甚至可能导致页面崩溃。
升级方案
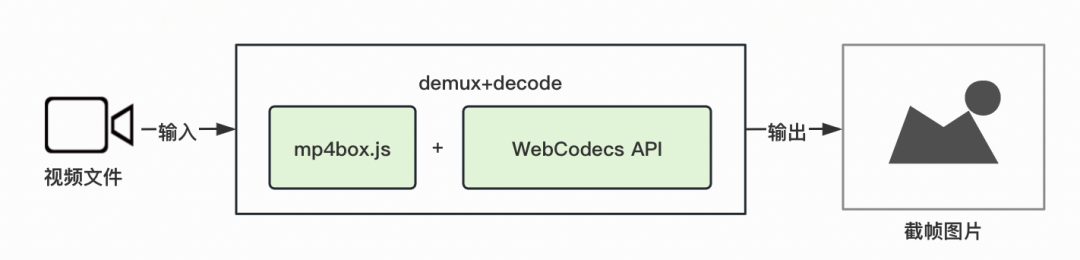
针对MP4格式视频的解析,Web投稿页已经实现了方案升级,改为使用mp4box(https://www.npmjs.com/package/mp4box)进行解封装,然后结合WebCodecs API进行解码,方案升级后获取视频信息和视频画面效率提高了70%。Matroska格式是除MP4以外占比最高的格式,在Web投稿始终占据着一席之地,对其解析方案进行改造升级势在必行。使用WebCodecs API进行解码实现起来并不复杂,已有诸多成熟的实践,需要着重解决的问题就是如何对Matroska视频进行高效解封装。
技术调研
Matroska简介
Matroska是一种多媒体封装格式,是EBML在多媒体领域的应用。EBML是一种八位位组对齐的二进制格式,由一系列Elements(元素)组成,各个Element可顺序排列,可层层嵌套,能够灵活地表示和存储各种数据。而EBML中的所存储的具体数据内容,随着EBML文件类型的不同而不同,由文件类型所定义的EBML Schema来确定(详见附录1)。Matroska继承了EBML的层级化结构,在EBML基础上定义了一套独特的Schema模式,以实现其强大的功能和特性(详见附录2)。
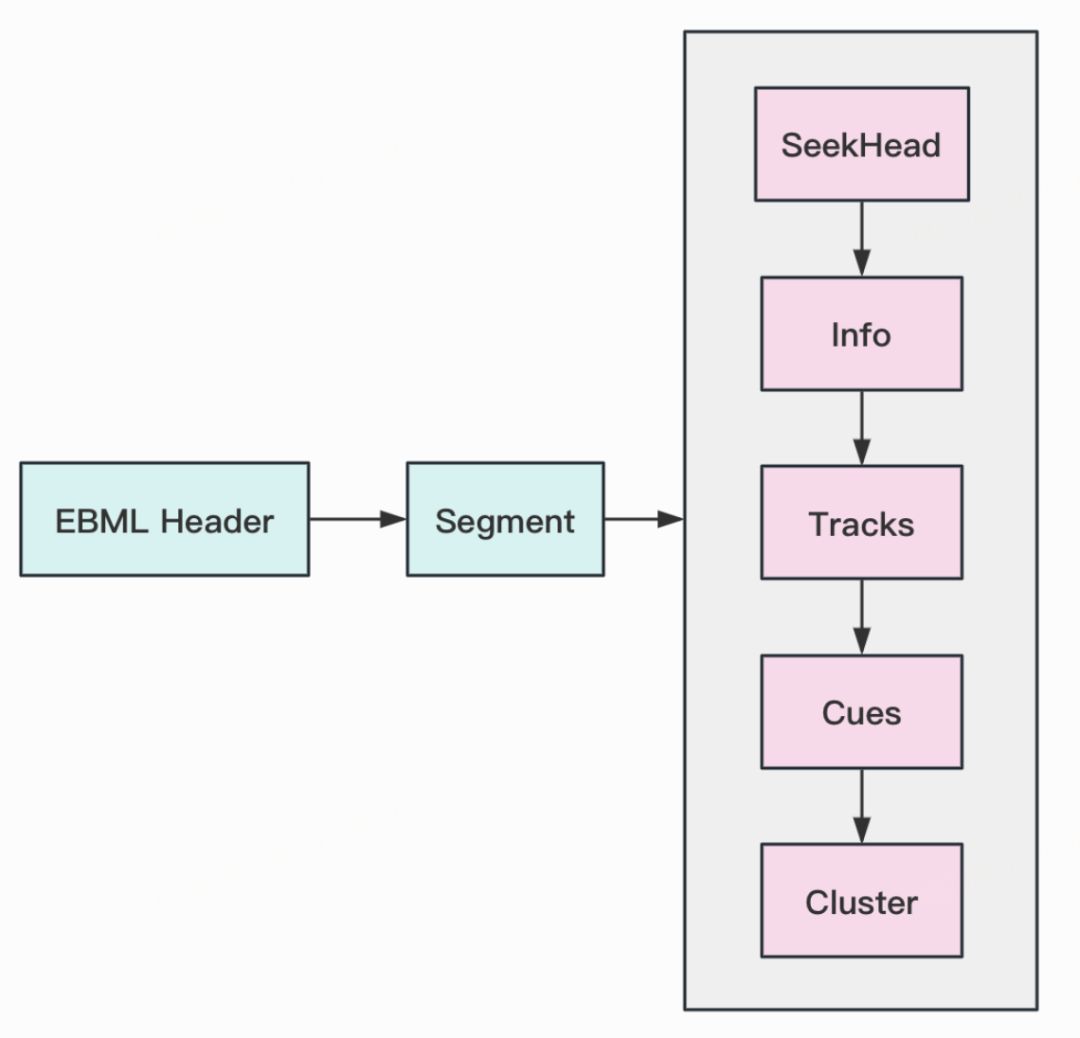
从宏观结构上看,Matroska文件仅由两个主要的Element组成:EBML Header和 Segment,而Segment中又存储着8个可能的Element,称为Top Element。其中, SeekHead对Matroska解析非常重要,其内部包含了其他Top Element的位置索引,可用于方便快速搜索需要的信息:比如从Info、Tracks中获取视频的元信息,从Cues、Cluster获取具体的视频数据(详见附录3)。

从微观组成上看,无论是EBML Header、Segment还是SeekHead等等,Matroska中的每个Element都是标准的EBML Element,有着确定的解析方式。
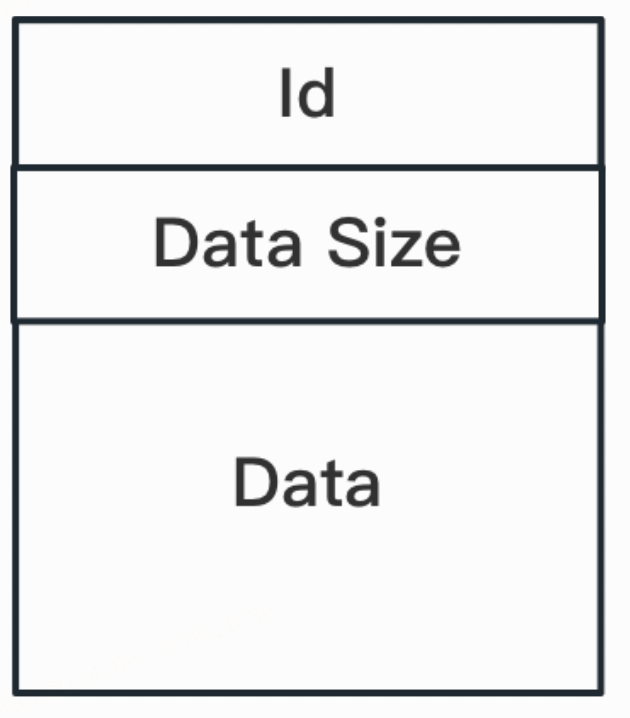
由此,遵循Matroska特定的EBML Schema结构,按照EBML Element的组成和编码方式进行逐个解析,即可对整个Matroska文件的内容进行读取。
相关开源项目
在MDN文档的WebCodecs API部分可以看到,文档中提及了一些对视频进行解封装的开源项目,对于MP4格式的文件,可以使用mp4box来进行解封装,对于WebM文件,则可以使用jswebm(https://www.npmjs.com/package/jswebm)。
WebM是一种基于Matroska的多媒体封装格式,其规范与Matroska规范基本一致,只是对视频编码和音频编码作出了一些限制(见附录4)。jswebm在解析过程中对文件的音视频编码进行了判定,如果不符合则抛出错误。如果将这部分判定功能进行忽略,jswebm是可以同时解析Matroska、WebM文件的。
jswebm使用起来非常简单,相关代码如下:
const demuxer = new JsWebm();
demuxer.queueData(buffer);
while (!demuxer.eof) {demuxer.demux();
}
console.log(demuxer);
console.log(`total video packets : ${demuxer.videoPackets.length}`);
console.log(`total audio packets : ${demuxer.audioPackets.length}`);而细读源码,可以发现其工作方式非常简单明了,就是顺序暴力读取:
1.文件读取层面:
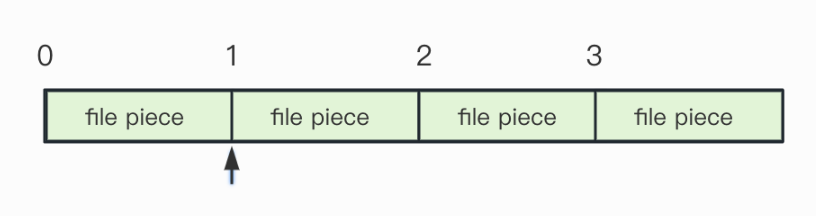
-
将整个文件的ArrayBuffer传入,SDK支持将文件一次性完整传入,也可进行切片顺序传入,按照传入的方式将文件内容按顺序存储在列表中;
-
对存好的ArrayBuffer列表从头分片读取,分片大小和数量与传入时一致;
-
内容解析过程中如果当前分片已用尽,则继续读取下一个分片,直到完成整个文件的解析。
2.内容解析层面:
-
首先读取EBML Header中的内容,然后获取到Segment部分,按照各个Top Element在Segment部分中的实际存储顺序,用递归的方式顺序解析
-
根据Element Id的不同,对各个Element Data采用不同的解析方式,并对解析结果进行存储
初步使用下来,从功能上来讲,我们想要的信息jswebm最终的确都能获取到,但想要在生产环境进行使用,有几个关键的问题不可忽略:
-
jswebm的文件读取方式决定了它内存占用极大,相当于整个视频文件都要读取到内存中,且浏览器对转换为ArrayBuffer的文件大小有限制,对于较大的视频文件,转换会直接失败
-
只能对整个文件进行完整解析,而实际使用时并不需要整个文件的完整信息,效率低
-
API不完善,没有提供诸如获取视频元信息、获取某个时间点的视频帧数据等常用方法,需要根据解析后吐出的结果来进行二次复杂运算
-
错误处理比较粗糙,视频文件有异常时解析过程无法正常抛出错误
因此,直接使用jswebm来对视频进行解析并不可行,无法满足Web投稿的实际需要。
方案实现
方案设计
Web投稿页对视频的解析需要在较短的时间内完成,这样才能确保计算结果能够及时曝光给用户,能够给用户投稿提供有效的帮助。这个过程中,内存的占用是非常重要的指标,如果内存占用过大,引发页面崩溃,则会打断投稿流程。实际生产环境使用时,有以下诉求:
-
内存占用不能过大,需要进行有效控制,不能随着视频文件大小的增大而线性增大
-
提高解析效率,缩短解析时间
-
提供API单独获取视频元信息
-
提供API获取某个时间点的视频帧数据,后续可结合WebCodecs API进行解码
因此,需要设计更加灵活、更加高效的工作流,打造更高性能、更实用的Matroska解封装SDK。
针对Web投稿页的实际诉求,主要进行以下设计:
1.数据读取层面:

-
直接传入文件的引用地址,不需要预先转换为ArrayBuffer
-
从头开始读取文件,对当前读取位置进行记录,根据传入的分片大小配置及当前位置,动态获取当前位置的ArrayBuffer分片
-
除了可以从头顺序读取文件外,还允许从给定的文件位置开始读取,记录读取位置并获取分片
-
内容解析过程中如果当前分片已用尽,则更新当前读取位置,重新获取新的分片,直到完成整个文件的解析
2.内容解析层面:
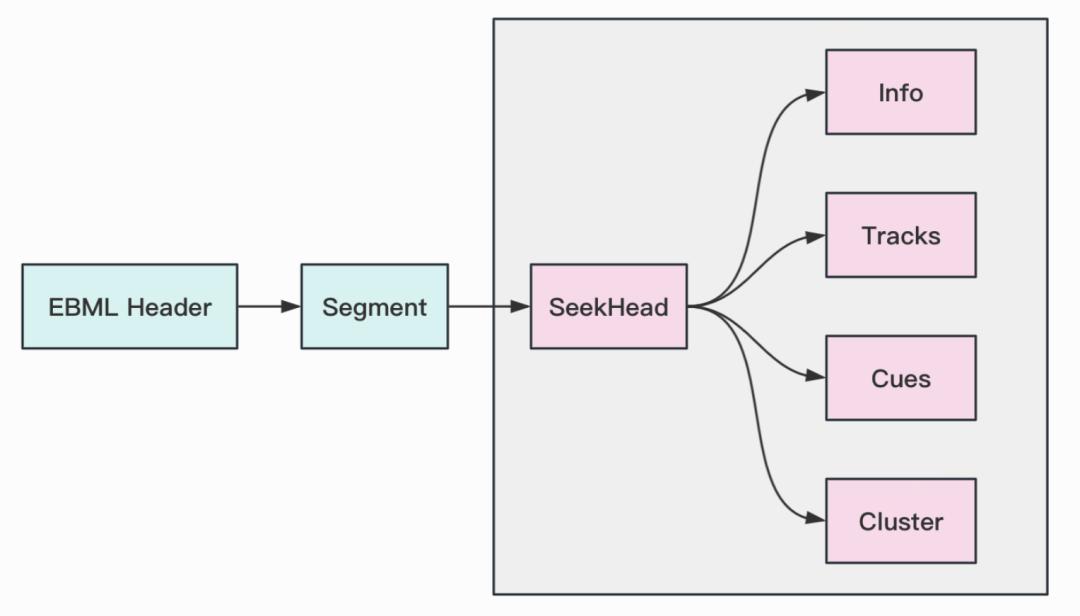
-
读取EBML Header中的内容,获取Segment部分,优先解析Segment中SeekHead的内容,记录各个Top Element在文件中的的实际位置
-
提供API,允许直接获取视频元信息或视频帧数据。根据所调用API的不同,去解析文件的不同部分:
-
如果需要获取视频元信息,则根据SeekHead中记录的位置,直接去解析Tracks和Info部分
-
如果需要获取视频帧数据,则根据SeekHead中记录的位置,直接去解析Cues和Cluster部分
-
根据Element Id的不同,对各个Element Data采用不同的读取方式,并对解析结果进行存储
-
定义解析过程中的通用错误类型,补充异常场景的错误抛出
根据Web投稿的实际应用需求,实现三个功能模块,分别进行文件预处理、视频基础信息获取、视频帧数据获取。各个模块之间存在一定的依赖关系,会对前置模块的运行结果进行校验。例如,获取视频基础信息时会使用到文件的索引信息,因此会预先检查文件是否完成了预处理工作。

每个功能模块内部又包含着一些子功能,来对视频文件进行不同的处理和分析:
1、文件预处理
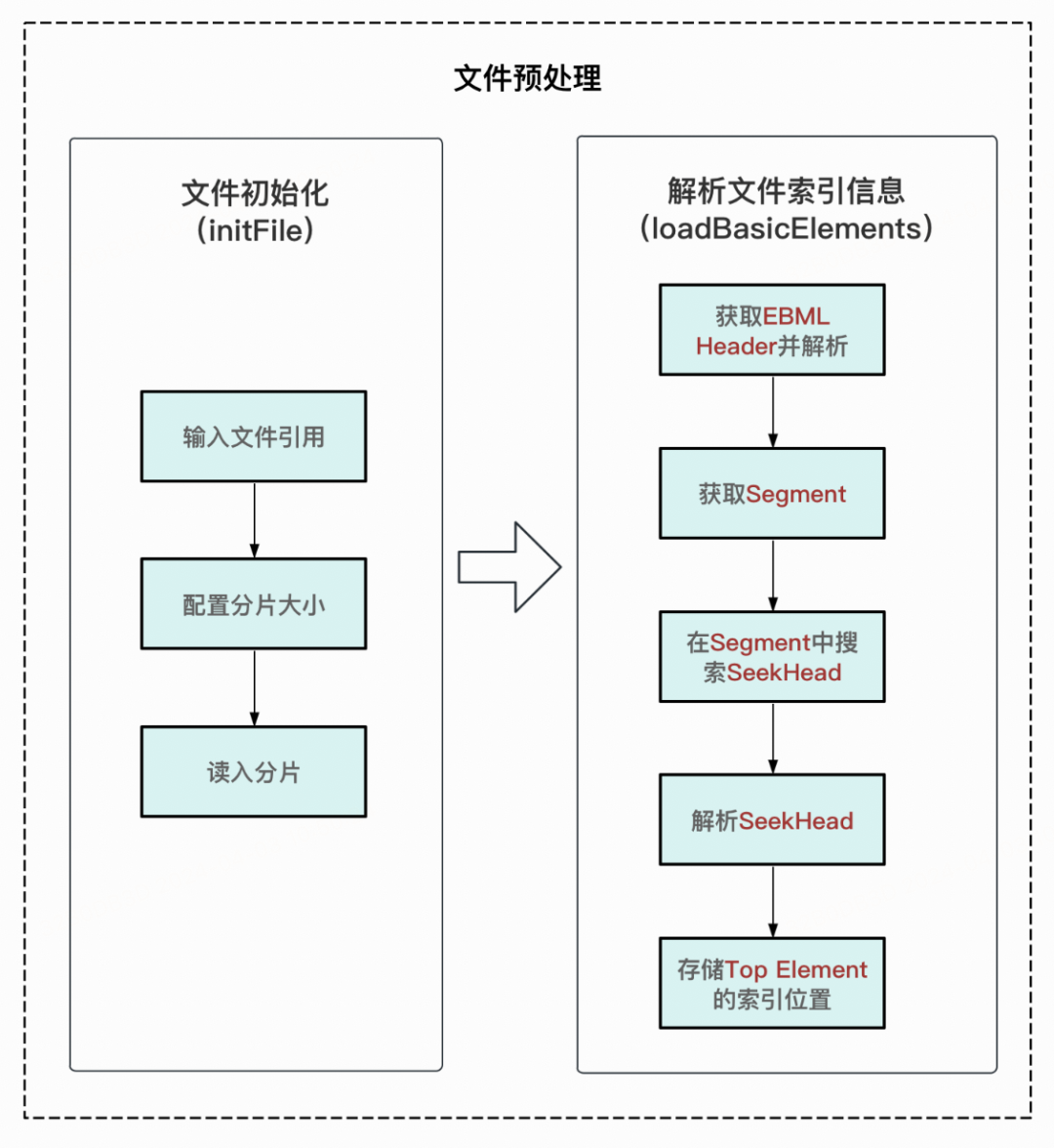
-
文件初始化:用于接收文件,按照传入的参数设置文件读取时的每个分片大小。分片大小可以根据实际需要来进行合理设置,当设置的分片大小过大时,文件分片会占据较大的内存,当设置的分片大小过小时,会频繁触发文件分片的动态获取,对解析耗时产生影响。
-
解析文件索引信息:获取文件的Segment元素,优先搜索Segment中的SeekHead元素,对SeekHead中的内容进行解析读取,获取Segment中各个Top Element的索引位置并进行存储。
2、视频基础信息获取
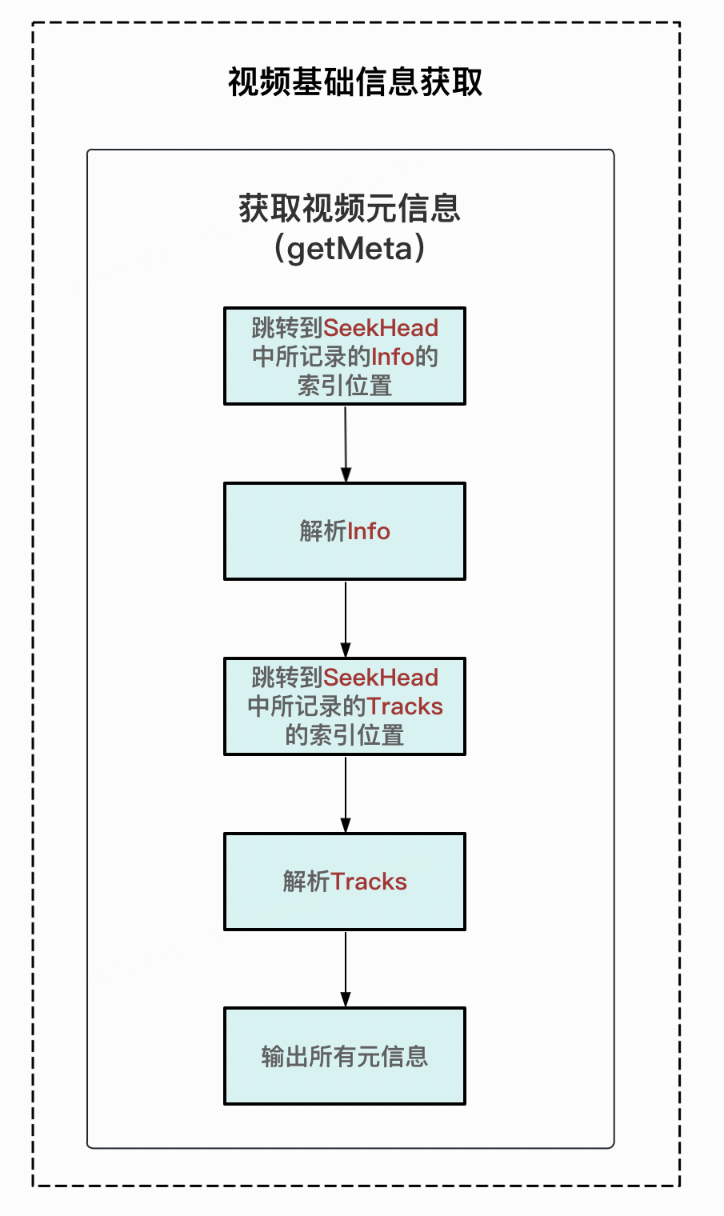
-
获取视频元信息:根据SeekHead中所记录的Tracks和Info的位置,对两者进行解析,获取视频宽、高、视频编码、音频编码等信息。
3、视频帧数据获取
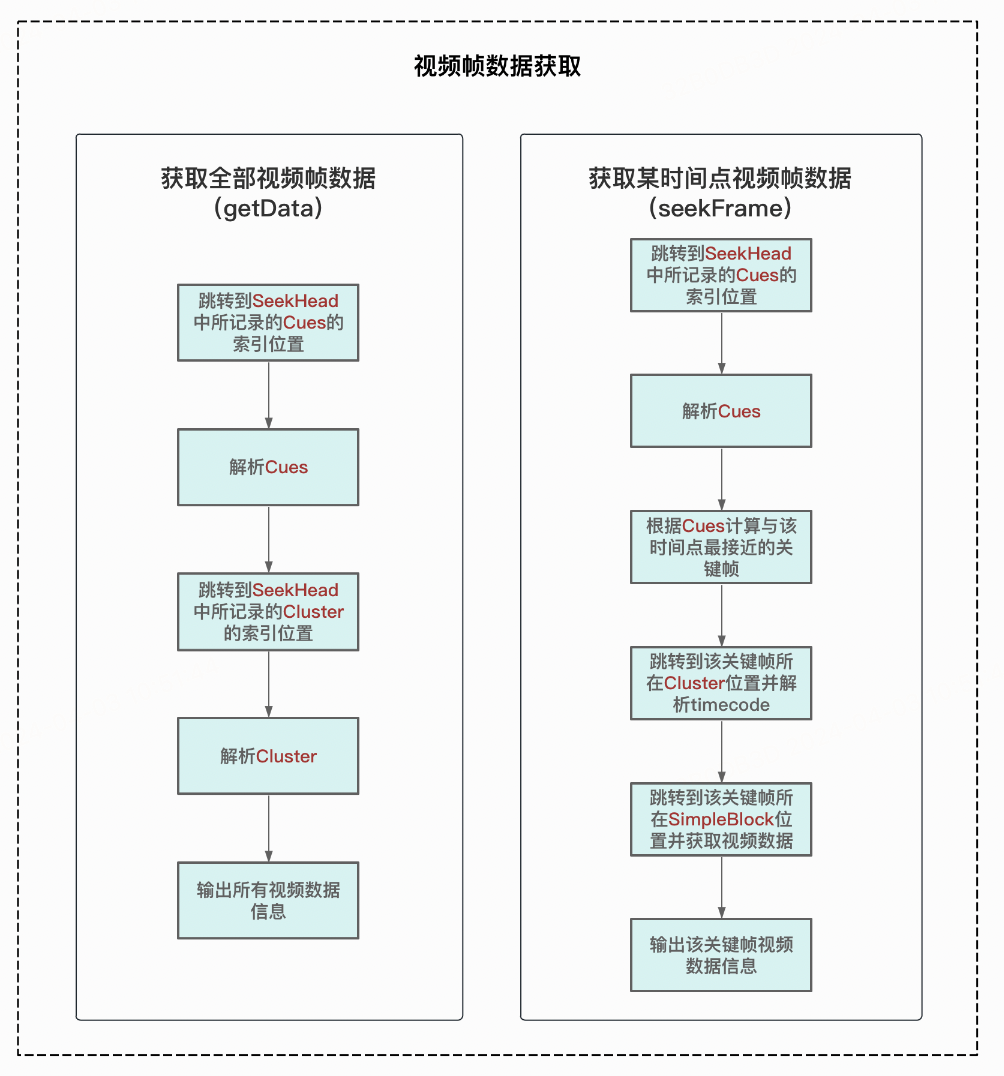
-
获取全部视频帧数据:根据SeekHead中所记录的Cues和Cluster的位置,对两者进行解析,获取视频所有帧数据及是否是关键帧等信息。
-
获取某时间点视频帧数据:根据SeekHead中所记录的Cues的位置,对其进行解析,计算与所需时间点最接近的关键帧存储位置和时间索引,根据关键帧存储位置对视频帧数据进行解析和输出。
新的方案中,SDK的工作方式和代码逻辑改变很大,因此需要另起炉灶,创建新的SDK——mkv-demuxer(https://www.npmjs.com/package/mkv-demuxer)。
mkv-demuxer重点解决了内存问题,优化了解析过程中的异常处理,并提供了几个有用的API,基本满足了Web投稿页的应用需求。
使用方式
mkv-demuxer的使用非常简单,首先创建一个解封装器实例,将文件进行传入,配置解析时的分片大小,然后根据实际需要调取相应的API即可。
import MkvDemuxer from 'mkv-demuxer'
const demuxer = new MkvDemuxer()
const filePieceSize = 1 * 1024 * 1024
await demuxer.initFile(file, filePieceSize)
const meta = await demuxer.getMeta()
const data = await demuxer.getData()
const frame = await demuxer.seekFrame(10)其中,getMeta可以获取视频文件基本的容器信息以及视频轨道、音频轨道的编码信息,返回的内容的格式为:
{info: {duration: 10000,muxingApp: "Lavf58.47.100",...},video: {codecID: "V_VP9",width: 1280,height: 720,...},audio: {codecID: "A_OPUS",channels: 2,rate: 48000,...},
}getData可以获取到视频轨、音频轨的所有数据packet信息,包含每个packet在文件中的位置、所在时间戳。同时,cues中存储了视频所有关键帧的时间戳和相对位置信息,可与其他信息结合,得到关键帧在文件中具体位置。getData所返回内容的格式为:
{cues: [{cueTime: 50,cueTrackPositions: {cueClusterPosition: 660,cueRelativePosition: 2539,cueTrack: 1,},},...],videoPackets: [{end: 3311,isKeyframe: true,keyframeTimestamp: 0.05,size: 51,start: 3260,timestamp: 0.05,},...],audioPackets: [{end: 1998,size: 1273,start: 725,timestamp: 0.001,},...],
};seekFrame可以根据给定的时间戳返回最接近该时间戳的关键帧数据信息,所返回的内容为:
{end: 3311,isKeyframe: true,keyframeTimestamp: 0.05,size: 51,start: 3260,timestamp: 0.05,
};性能表现
对于改造前后两个SDK的性能表现,可以抽取不同的视频进行测试,验证改造效果。经过多次测试和对比,发现改造后内存占用大大减小,不再受到视频本身体积的影响,能够平稳保持在较低水平;解析视频速度大大提高,基本都能在一秒内完成。尤其对于高分辨率、大体积的视频文件,使用两个SDK进行解析时性能表现差异极大,优化效果最为明显。
以一个4K视频为例,其基本信息如下:
| 属性名 | 值 |
| 视频大小 | 1.61G |
| 视频编码 | VP9 |
| 分辨率 | 3840x2160 |
| 码率 | 10023 kb/s |
对改造前后的内存占用变化及解析视频时间进行记录,可以得到如下结果:
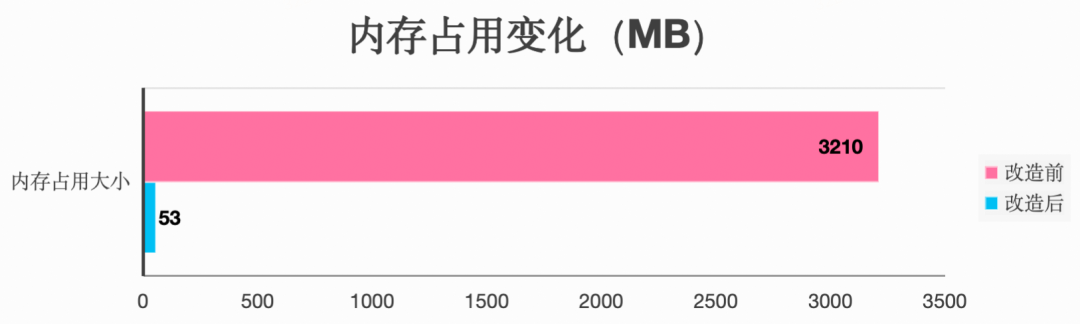
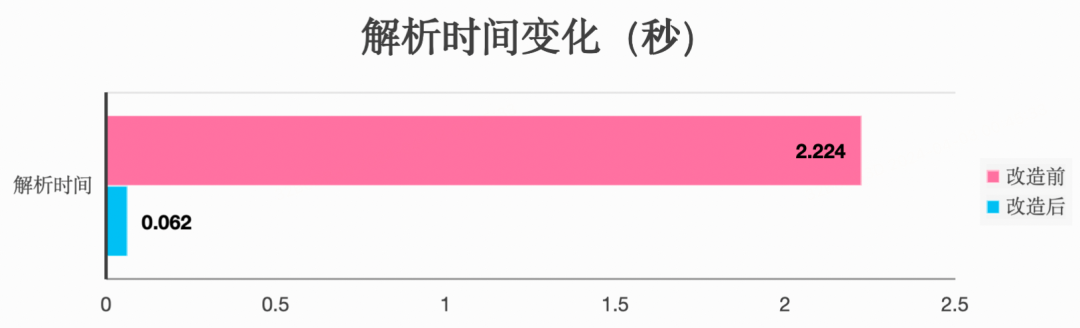
改造后内存占用减少了98.34%,解析视频时间减少97.21%。改造后的mkv-demuxer性能表现良好,可以在生产环境进行使用。
Web投稿实际应用
Web投稿页在获取到用户上传的视频后会分别获取视频元信息和视频抽帧画面,用以计算推荐封面和推荐分区,推荐结果获取的速度对用户体验有着直接的影响。
-
推荐封面的获取:从视频中截取至多30张低清截帧画面,对低清图片进行AI打分,基于打分结果排序重新截取10张高清截帧画面,作为推荐封面

-
推荐分区的获取:从视频中均匀截取10张截帧画面,对截帧画面进行打包,上传压缩包,等待AI计算,将计算结果作为推荐分区

将Matroska视频的截帧方案进行升级,使用mkv-demuxer完成解封装,调用WebCodecs API对视频帧数据进行高性能解码,再结合WebGL以更快的速度绘制截帧画面,当用户投递Matroska视频时,获取到推荐封面和推荐分区的速度会变快。当视频无法解析或浏览器不支持WebCodecs API时,则会自动降级为旧方案,因此成功率不会受到影响。
数据结果
将升级方案与通用的FFmpeg+WebAssembly方案进行对比,可以得到如下结果:
-
视频画面截帧过程耗时缩短在80%以上,视频分辨率越高效果越明显
-
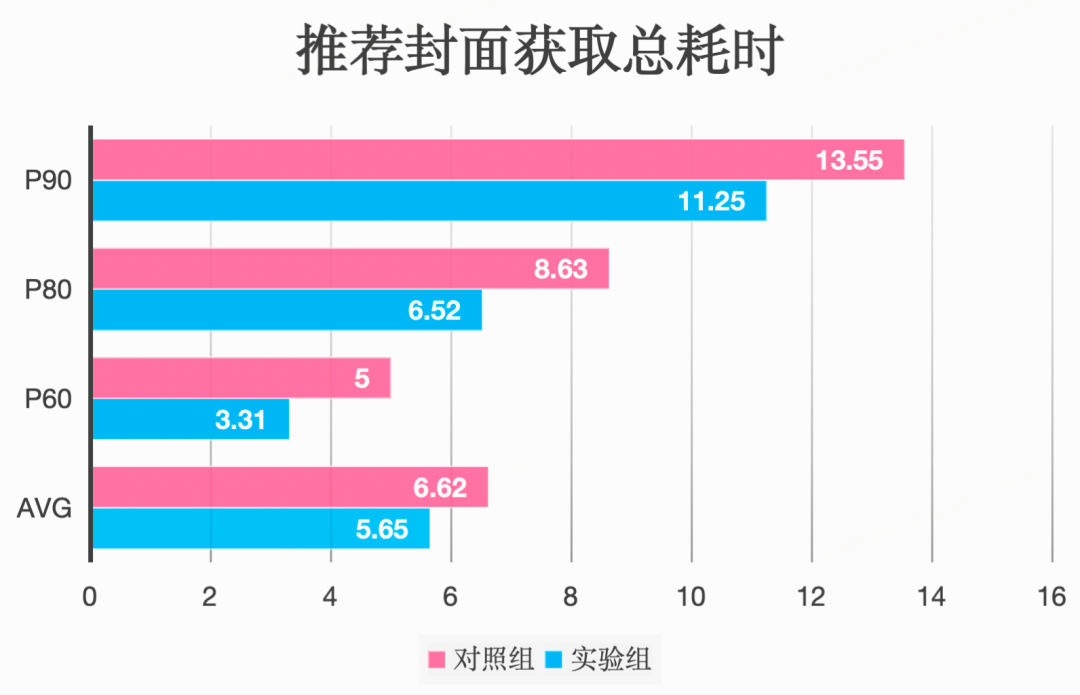
推荐封面获取总耗时减少2.29s,缩短了16.93%
-
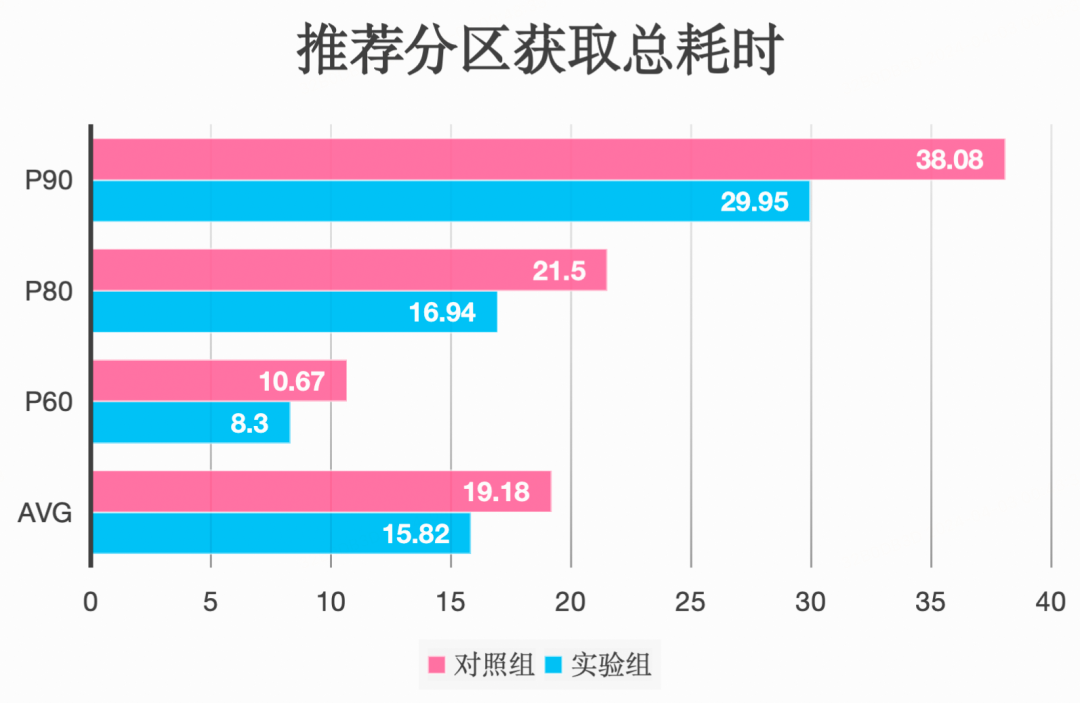
推荐分区获取总耗时减少8.13s,缩短了21.36%
具体数据如下:
推荐封面获取总耗时:
推荐分区获取总耗时:
由于推荐封面总流程和推荐分区获取总流程中除了画面截帧还包含了许多其他步骤,且受限于WebCodecs API的兼容性,实验组用户中很大比例的用户最终使用的还是旧版降级方案,因此与本地进行的截帧性能测试数据相比,耗时减少的效果得到了一定的稀释。但整体来说,新的方案对用户投稿体验的改善是比较可观的,且随着未来WebCodecs在Web平台的逐渐兼容,优化效果会越加明显。
后续规划
基于Web投稿页的实际运作需求以及mkv-demuxer现有的解析能力,可以规划如下优化策略:
一、针对Web投稿页上的Matroska视频,可以利用mkv-demuxer的解封装能力,优化视频边传边转流程。在这一过程中,mkv-demuxer能够更加快速地获取视频帧数据,并进行逐帧遍历,精确计算视频的比特率、大小等关键数据。将这些信息更早地同步至视频云,可以加速视频转码的整体流程,提升用户体验。
二、进一步提升mkv-demuxer的解析能力,完善对Matroska格式的全面支持。通过增加对Tag、Attachments等内容的解析能力,兼容对EBML Stream的解析,可以更全面地解析Matroska文件,提取更多有用的信息。
相关资料
EBML相关:
-
https://datatracker.ietf.org/doc/html/rfc8794
-
https://docs.racket-lang.org/ebml/index.html
Matroska相关:https://www.matroska.org/index.html
WebM相关:
-
https://www.webmproject.org/
-
https://cloudinary.com/guides/video-fomats/webm-format-what-you-should-know
工具推荐:
-
Hex Fiend
-
MKVToolNix
项目地址及npm包:
-
github仓库:https://github.com/SuperYanjun/mkv-demuxer
-
npm包:https://www.npmjs.com/package/mkv-demuxer
附录
1. EBML的结构:

EBML文件仅由两个部分组成:EBML header和 EBML body。EBML必须以EBML header开头,用以声明如文件类型、编写/读取EBML所需版本等重要信息,提供对EBML body处理方式的声明。而EBML body中的内容,随着EBML文件类型的不同而不同,又包含很多其他的EBML Element。
2. Matroska基于EBML的限制:
Matroska本身是基于EBML的,只是在通用的EBML基础上制定了Matroska独特的EBML Schema,同时做出了一些规定和限制:
-
EBML Header中的DocType值必须是matroska,EBMLMaxIDLength必须是4,EBMLMaxSizeLength必须为1~8
-
至少包含一个EBML Document,更复杂的Matroska可包含多个EBML Document,形成EBML Stream
-
每个EBML Document必须以EBML Header开始,随后跟着一个Segment
-
存在8个可能的顶级Top Element
3. Matroska的Top Element:
Matroska不同的Top Element,存储了文件的不同内容:
-
SeekHead:包含了其他Top Element的位置索引,由于Matroska对8个Top Element的位置顺序没有进行规定,如果没有位置索引,想要寻找其中某个元素则需要对整个文件进行搜索。
-
Info:包含了Segment内容的整体信息,如标题、时长等。
-
Tracks:包含了每个轨道的信息,如轨道类型、分辨率、采样率、编码等。
-
Chapters:包含了所有章节内容,有了章节划分便可以在视频中进行跳转。
-
Cluster:包含了每个轨道的具体数据内容,每个Cluster中包含了至少一个SimpleBlock或BlockGroup元素,存储了视频具体的数据信息;每个Cluster都包含一个时间戳,用于表明该Cluster中第一个元素的播放开始时间,这种组织形式有利于对视频数据进行查找和进行错误恢复。
-
Cues:用于播放时进行时间索引,每个Cues元素都包含至少一个CuePoint元素,用于存储该索引下BlockGroup或SimpleBlock的位置。
-
Attachments:用于为Matroska文件增加附件,如图片、字体、网页等。
Tags:包含了对文件的描述数据和额外信息,如歌手、流派、评论、导演等。
4. WebM与Matroska的区别:
WebM由Google推出,目标是构建一个开放的、免费的视频格式。WebM在互联网中使用非常方便,因为它通常压缩率高,体积较小,使得共享和传输媒体内容变得更加容易,也节省了存储空间。WebM是基于Matroska多媒体容器格式进行开发的,所不同的是,WebM对视频编码和音频编码作出了一定限制,并且定义了新的DocType的值:
-
视频编码必须是VP8或VP9
-
音频编码必须是Vorbis或Opus
-
EBML Header中的DocType必须是webm





)

Java八股——Redis)



)

)




)
