目录
- 1. 注意力机制
- 1.1 注意力评分函数
- 1.2 多头注意力(Multi-head self-attention)
- 2. Layer norm
- 3. 模型结构
- 4. Attention在Transformer中三种形式的应用
论文:https://arxiv.org/abs/1706.03762
李沐B站视频:https://www.bilibili.com/video/BV1pu411o7BE/?spm_id_from=333.788&vd_source=21011151235423b801d3f3ae98b91e94
D2L: https://zh.d2l.ai/chapter_attention-mechanisms/index.html
知乎讲解:https://zhuanlan.zhihu.com/p/639123398
1. 注意力机制
注意力机制由三个重要组成部分:query, key, value, query和key通过注意力评分函数计算出注意力权重,用于对value进行加权平均,得到最后的输出,如下图所示:
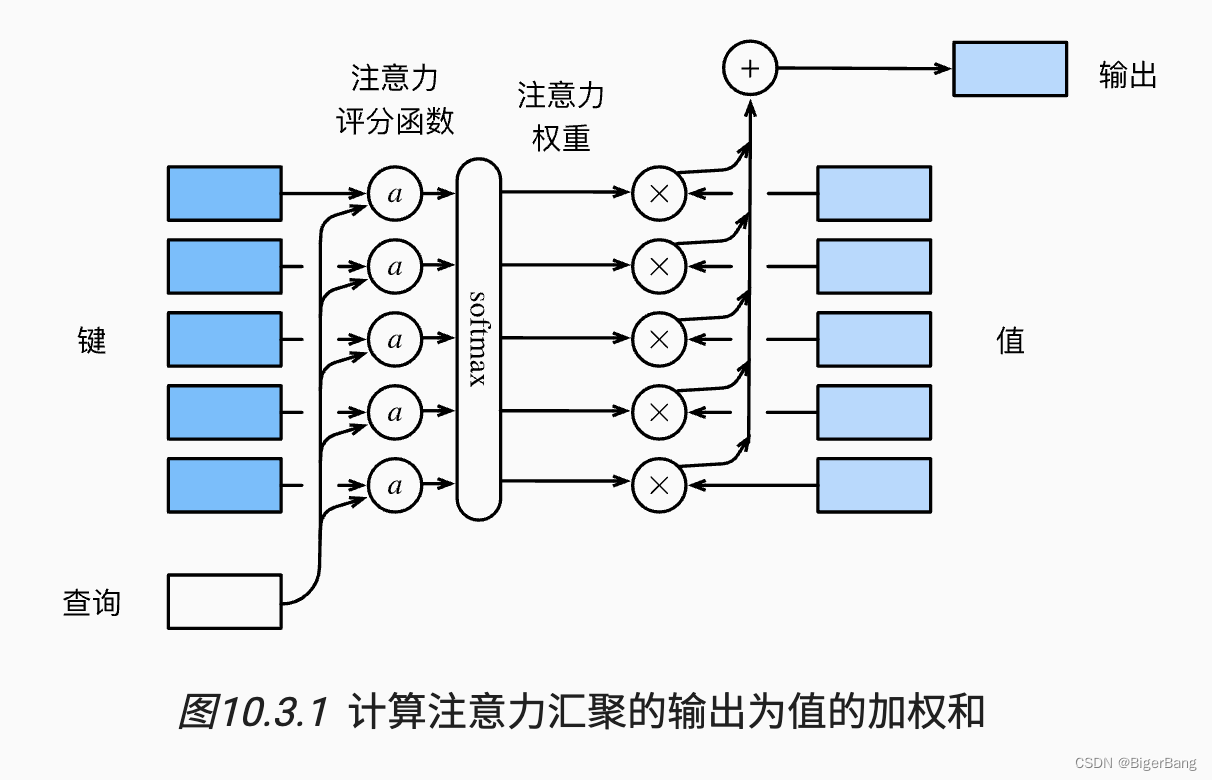
举例:
如果:
key的维度为(m, k),表示有m个key,每个key的向量维度为k;
value的维度为(m,v), 表示有m个value(key和value的个数一定相同),每个value的向量维度为v;
那么给定一个query的维度为(q), 那么通过注意力评分函数W(query, key)将得到一个维度为(m)的权重向量, 这个权重向量与value相乘,就完成了每个特征的加权求和,得到的维度为(v)。
当然也可以一个求多个query的结果,比如query是(n,q), 最后得到的结果维度就是(n, v);
1.1 注意力评分函数
常用的注意力评分函数有两种:加性注意力(Additive Attention)和 点积注意力 (Dot-Product Attention),Transformer这篇论文采用的是缩放点积注意力(Scaled Dot-Product Attention),就是在点积注意力的基础上加入一个缩放;
-
加性注意力
当查询和键是不同长度的矢量时,可以使用加性注意力作为评分函数。

先使用两个全连接层,将query和key统一到相同长度,然后将每一个query都和每一个键相加,再经过一个线性映射得到注意力权重
-
缩放点积注意力


-
为什么要缩放?
- 当dk的值比较小的时候,这两个机制的性能相差相近,当dk比较大时,加法attention比不带缩放的点积attention性能好。我们怀疑,维度dk很大时,点积结果也变得很大,那么某些向量中间的注意力分数将占绝对主导地位,将softmax函数推向具有极小梯度的区域。为了抵消这种影响,我们将点积缩小1/sqrt(dk)倍。
- 假设query和Key的所有元素都是独立的随机变量,并满足零均值和单位方差,那么两个向量点积的均值为0,方差为d(d为向量维度)。为保证点积的方差仍是1,那么就要将点积除以sqrt(d)
1.2 多头注意力(Multi-head self-attention)

-
类似于卷集中的多通道,可学习到不同模式
- 增加可学习的参数:本身缩放点积注意力是没什么参数可以学习的,就是计算点积、softmax、加权和而已。但是使用
Multi-head attention之后,投影到低维的权重矩阵W_Q, W_K, W_V是可以学习的,而且有h=8次学习机会。 - 多语义匹配:使得模型可以在不同语义空间下学到不同的的语义表示,也扩展了模型关注不同位置的能力。类似卷积中多通道的感觉。例如,“小明养了一只猫,它特别调皮可爱,他非常喜欢它”。“猫”从指代的角度看,与“它”的匹配度最高,但从属性的角度看,与“调皮”“可爱”的匹配度最高。标准的 Attention 模型无法处理这种多语义的情况。
- 注意力结果互斥:自注意力结果需要经过softmax归一化,导致自注意力结果之间是互斥的,无法同时关注多个输人。 使用多组自注意力模型产生多组不同的注意力结果,则不同组注意力模型可能关注到不同的输入,从而增强模型的表达能力。
- 增加可学习的参数:本身缩放点积注意力是没什么参数可以学习的,就是计算点积、softmax、加权和而已。但是使用
-
多头注意力对计算量没有影响
多头注意力的每个头单独通过矩阵运算进行注意力计算,也可以合并成一次矩阵运算
2. Layer norm
从下面两幅示意图可以清楚的理解Layer norm以及其和Batch norm等normalization模块的区别;
下图截取自何凯明在MIT的演讲PPT:

下图截取自沐神B站视频,蓝色是BN,黄色是LN

可以这么理解,BN是针对每个特征,对所有的样本计算均值和方差;而LN是针对每个样本,对这个样本的所有特征计算均值和方差;
如果输入的shape为(B, C, H, W),那么BN的均值和方差的维度是(1,C, 1, 1), 计算机视觉中的LN的均值和方差维度为(B, 1, 1, 1), transformer中的均值和方差维度为(B,1, H, W),instance norm的均值和方差维度为(B, 1, 1, 1), group norm 的均值和方差维度为(B, C/m, 1, 1)
-
为什么不使用batch norm?
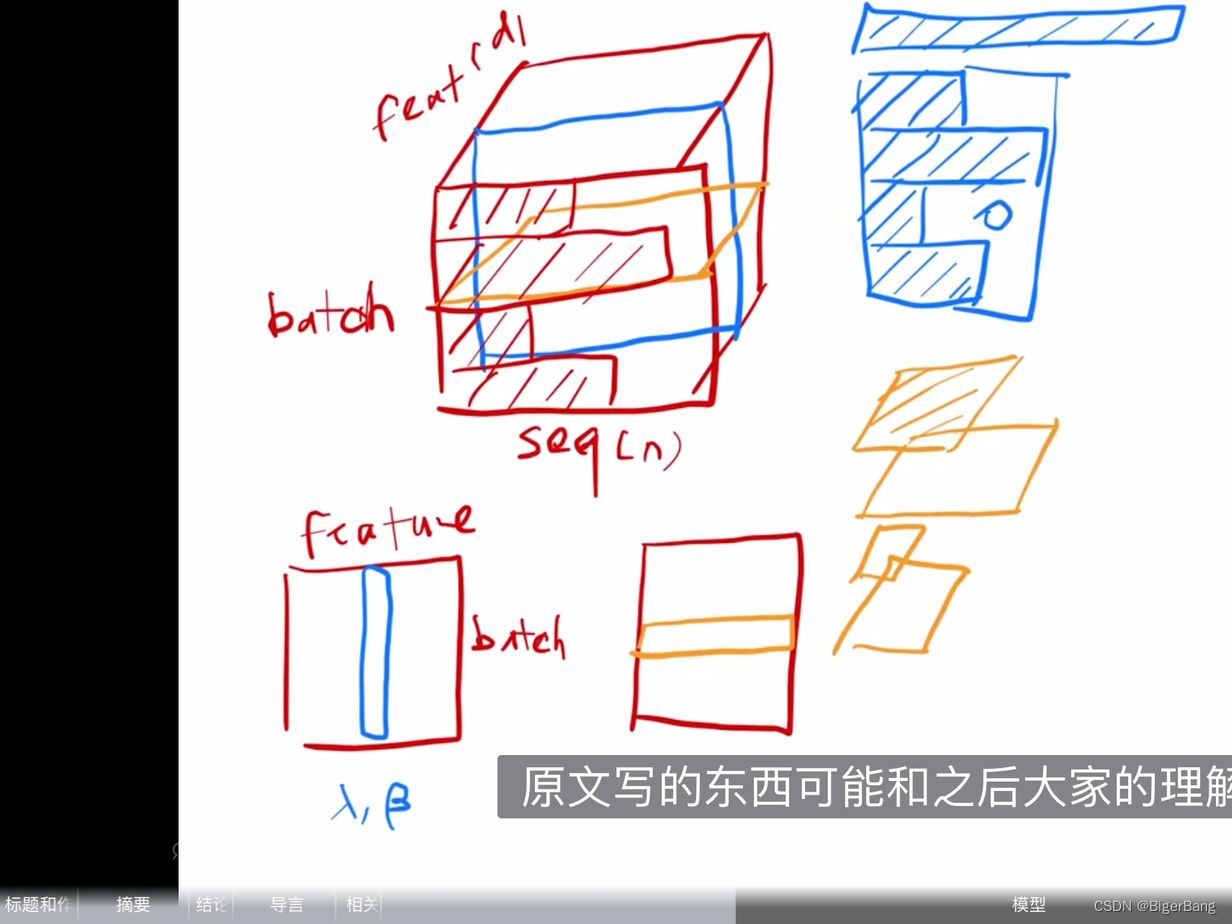
为什么这里使用LN而不是BN?
- 计算变长序列时,每个Batch中的序列长度是不同的,如上图的蓝色示意图,这样在一个batch中做均值时,变长序列后面会pad 0,这些pad部分是没有意义的,这样进行特征维度做归一化缺少实际意义。
- 序列长度变化大时,计算出来的均值和方差抖动很大。
- 预测时使用训练时记录下来的全局均值和方差。如果预测时新样本特别长,超过训练时的长度,那么之前记录的均值和方差可能会不适用,预测会出现问题。
而Layer Normalization在每个序列内部进行归一化,不存在这些问题:
- NLP任务中一个序列的所有token都是同一语义空间,进行LN归一化有实际意义
- 因为实是在每个样本内做的,序列变长时相比BN,计算的数值更稳定。
- 不需要存一个全局的均值和方差,预测样本长度不影响最终结果。
3. 模型结构
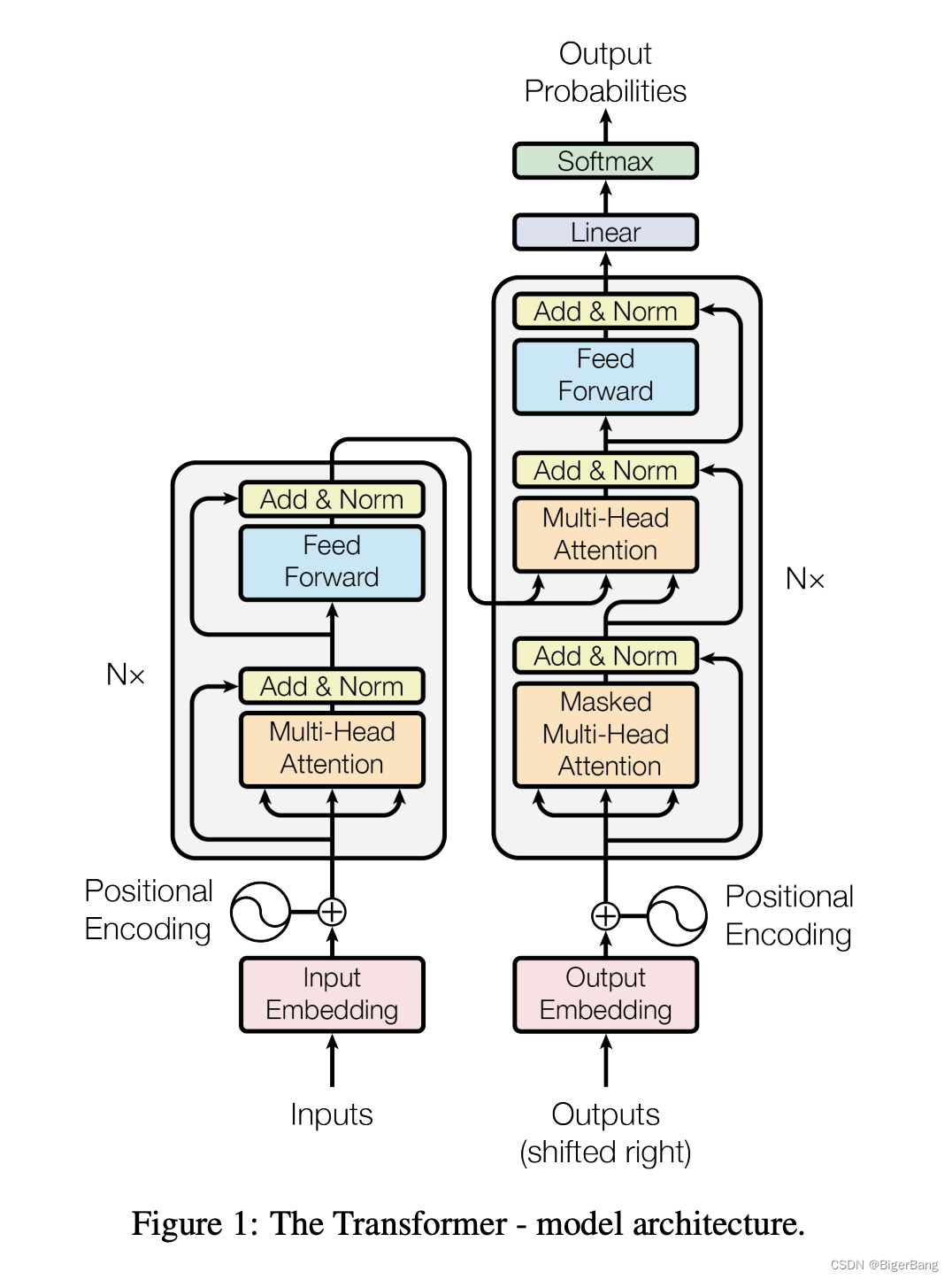
大多数的机器翻译网络都是这种encoder-decoder架构
-
Inputs 和 Outputs
本篇文章做的是机器翻译任务,比如若是完成中译英问题,inputs则是中文句子,outputs是英文翻译结果;
在翻译时采用的是auto-regressive,也就是网络在翻译当前词的时候不仅使用中文句子的信息,也会将已经翻译出来的英文单词的信息作为输入,提取其中的信息预测下一个词;
At each step the model is auto-regressive [10], consuming the previously generated symbols as additional input when generating the next.
-
Embedding
将输入和输出的token转成具有d_model维度的向量;
we use learned embeddings to convert the input
tokens and output tokens to vectors of dimension d_model. -
位置编码 Positional Encoding
Attention计算时本身是不考虑位置信息的,这样序列顺序变化结果也是一样的。所以我们必须在序列中加入关于词符相对或者绝对位置的一些信息。
为此,我们将“位置编码”添加到token embedding中。二者维度相同(例如d_model
=512),所以可以相加。有多种位置编码可以选择,例如通过学习得到的位置编码和固定的位置编码。
关于位置编码可学习:https://zh.d2l.ai/chapter_attention-mechanisms/self-attention-and-positional-encoding.html
-
编码器
编码器由N=6个相同encoder层堆栈组成。如上图中所示,每个encoder层有两个子层:
multi-head self-attentionFFNN(前馈神经网络层,Feed Forward Neural Network),其实就是MLP,为了fancy一点,就把名字起的很长。
每个子层的形式可以表达为:LayerNorm(x + Sublayer(x)),其中Sublayer(x)是当前子层的输出, 两个子层都使用残差连接(residual connection),然后进行层归一化(layer normalization)。
为了简单起见,模型中的所有子层以及嵌入层的向量维度都是d_model=512(如果输入输出维度不一样,残差连接就需要做投影,将其映射到统一维度)。(这和之前的CNN或MLP做法是不一样的,之前都会进行一些下采样)
这种各层统一维度使得模型比较简单,只有N和d_model两个参数需要调。这个也影响到后面一系列网络,比如bert和GPT等等。
-
解码器
解码器:解码器同样由 N=6个相同的decoder层堆栈组成,每个层有三个子层。
-
Masked multi-head self-attention:解码器里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法如下图所示:在 Self Attention 分数经过 Softmax 层之前,使用attention mask,屏蔽当前位置之后的那些位置。所以叫Masked multi-head self Attention。(对应masked位置使用一个很大的负数-inf,使得softmax之后其对应值为0)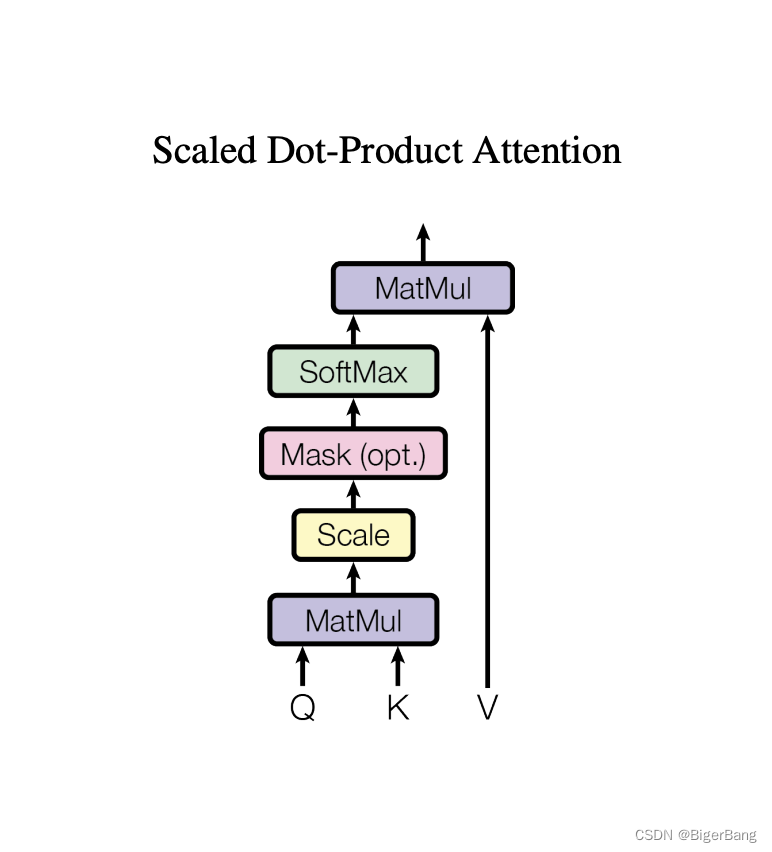
-
Encoder-Decoder Attention:也就是解码器中的第二个MHA层,这一个MHA的query是解码器的上一输出,key和 value都来自编码器输出最终向量,用来帮解码器把注意力集中中输入序列的合适位置。 -
FFNN:依然是MLP层
-
4. Attention在Transformer中三种形式的应用
multi-head self attention:标准的多头自注意力层,用在encoder的第一个多头自注意力层。所有key,value和query来自同一个地方,即encoder中前一层的输出。在这种情况下,encoder中的每个位置都可以关注到encoder上一层的所有位置。masked-self-attention:用在decoder中,序列的每个位置只允许看到当前位置之前的所有位置,这是为了保持解码器的自回归特性,防止看到未来位置的信息encoder-decoder attention:用于encoder block的第二个多头自注意力层。query来自前面的decoder层,而keys和values来自encoder的输出memory。这使得decoder中的每个位置都能关注到输入序列中的所有位置。


![[C++/Linux] Linux线程详解](http://pic.xiahunao.cn/[C++/Linux] Linux线程详解)
)




)

蓝桥杯习题)








