一、开源AI大语言模型
目前开源的AI大语言模型(LLM)已经非常的多了,以下是收集的一些LLM:

LLaMA
LLaMA(Large Language Model Meta AI):LLaMA是由MetaAI的Facebook人工智能实验室(FAIR)发布的开放使用的预训练语言模型。它在2022年11月到2023年2月之间训练。LLaMA的工作原理类似于其他大型语言模型,它将一连串的单词作为输入,并预测下一个单词,以递归地生成文本。
2023-06-26日上传至github,目前51.3k star
Gemma
Gemma 是由 Google AI 开发的一系列轻量级、最先进的开源模型,基于用于创建 Google Gemini 模型的研究和技术。Gemma 模型具有出色的语言理解和生成能力。它分为两个规模:2B 和 7B 参数。每个规模都包含基础(预训练)和指令微调版本。Gemma 模型可以在各种类型的消费级硬件上运行,甚至无需量化,且上下文长度可达 8K 个标记。
2024-02-13日上传至github,目前5.1k star
Grok
Grok是一个智能学习系统,通过分析大量数据来获取知识并理解复杂的概念。它利用先进的机器学习算法和深度神经网络,可以处理文本、图像和声音等多种类型的数据。
2024-03-17日上传至github,目前45.6k star。短短几天,这成绩可以说是“狂飙”了
DBRX
DBRX是由Databricks的Mosaic Research团队开发的通用大型语言模型(LLM),旨在为每家企业提供数据智能,让组织能够理解和利用其独特数据来构建自己的人工智能系统。相比现有的开源模型,DBRX在语言理解、编程、数学和逻辑等方面表现更优秀,能够击败多个已建立的开源模型。
2024-02-13日上传至github,目前1.1k star。最近发布的说是可以替代GPT4。
Qwen
Qwen模型是一种基于深度学习的自然语言处理模型,利用大规模语料库进行训练,具有强大的语义理解和文本生成能力。它适用于多种场景,如智能客服、文本摘要、机器翻译等。
2023-08-03日上传至github,目前10.2k star,由阿里云发布。
ChatGLM
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。
2023-03-13日上传至github,目前38.8k star,由清华大学支持
二、LLaMA本地安装
Ollama 是一个开源框架,专门设计用于在本地运行大型语言模型。它将模型权重、配置和数据捆绑到一个包中,优化了设置和配置细节,包括 GPU 使用情况,从而简化了在本地运行大型模型的过程. Ollama 可以让用户通过简单的安装指令,在本地运行开源大型语言模型. 安装和使用 Ollama 非常方便,你可以直接在官网下载安装包,或者在 Linux 上使用命令行安装。一旦安装完成,你就可以使用一行命令来运行模型,例如运行中文微调过的 Llama2-Chinese 7B 模型,只需执行以下命令:ollama run llama2-chinese。
step1:下载Ollama
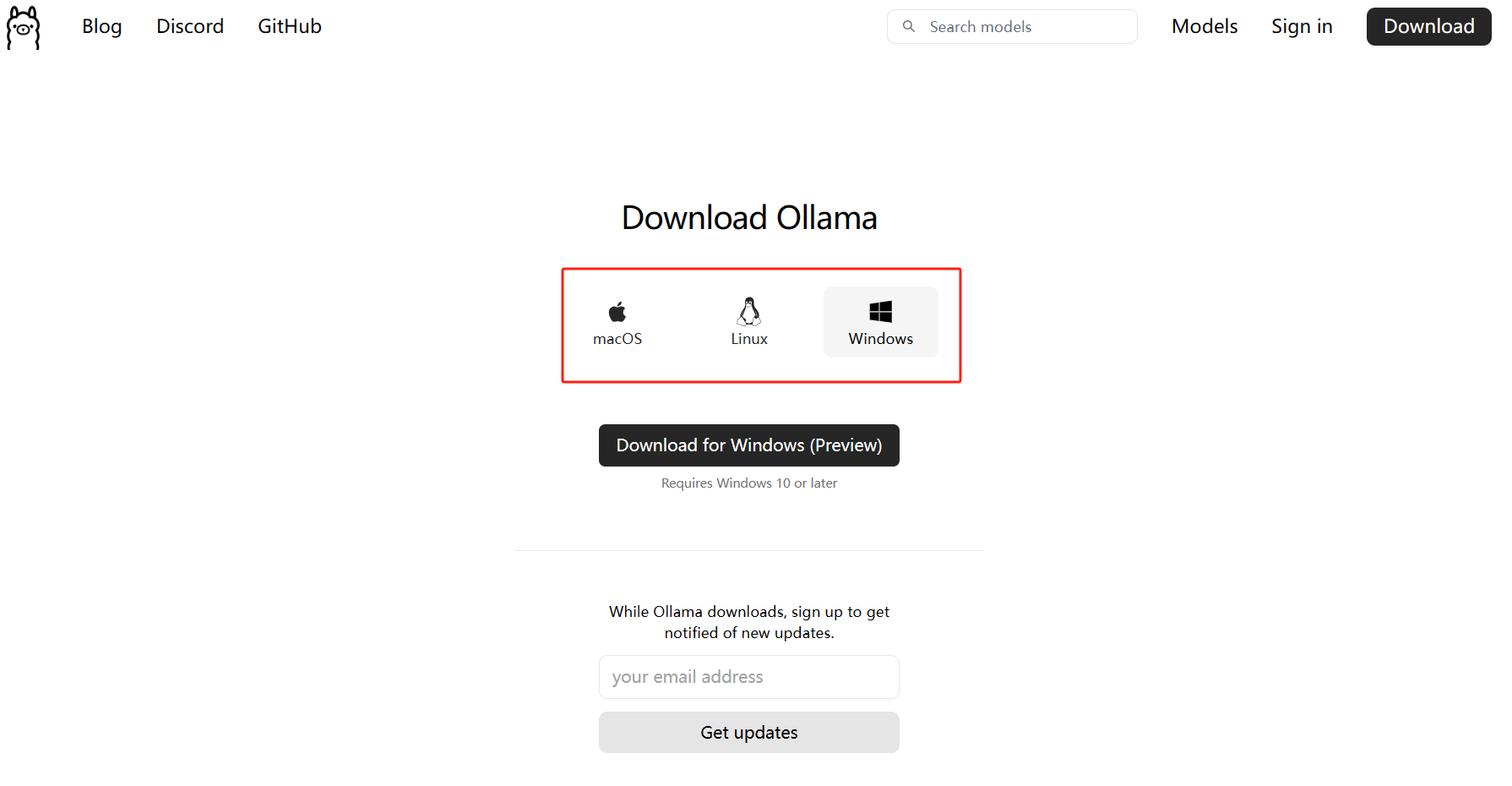
step2:安装Ollama
双击安装OllamaSetup.exe,安装完成后在电脑状态栏会多一个羊驼的图标
step3:安装模型
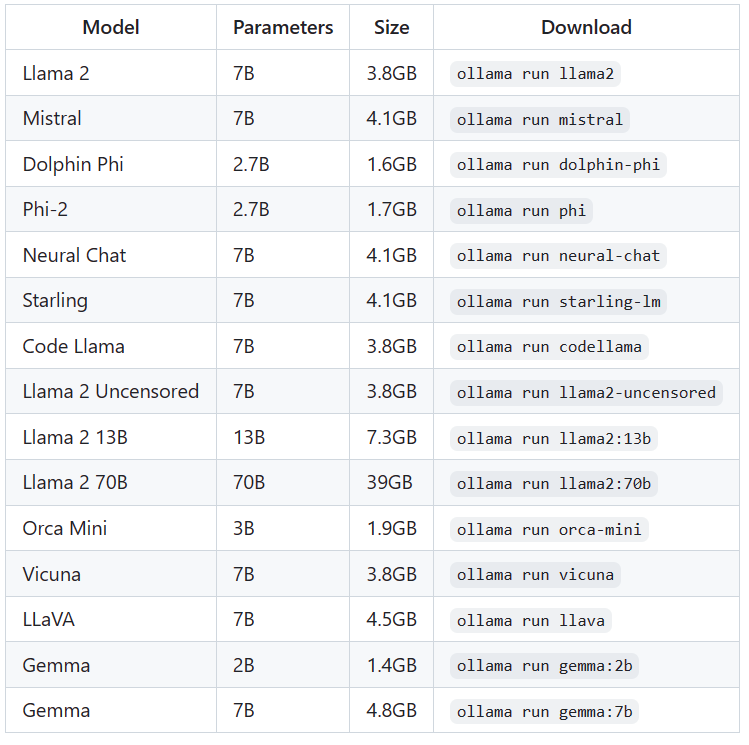
github.com/ollama/ollama
选择你需要的模型,然后在windows上打开一个cmd,执行,比如:
ollama run gemma:2b接下就是会下载相应的模型,这里比较大,要花不少时间
step4:使用
>>> hi who are you比如打开windows命令窗口:

这就是离线版本AI了....
不过执行起来的确占用大量的CPU,CPU直接狂飙到100%.....内存占用的不是很大....
普通电脑已经可以部署开源AI产品,但并不适用于所有类型的AI应用或任务。在选择部署AI产品及模型时,需要考虑到具体的应用需求和硬件性能要求。
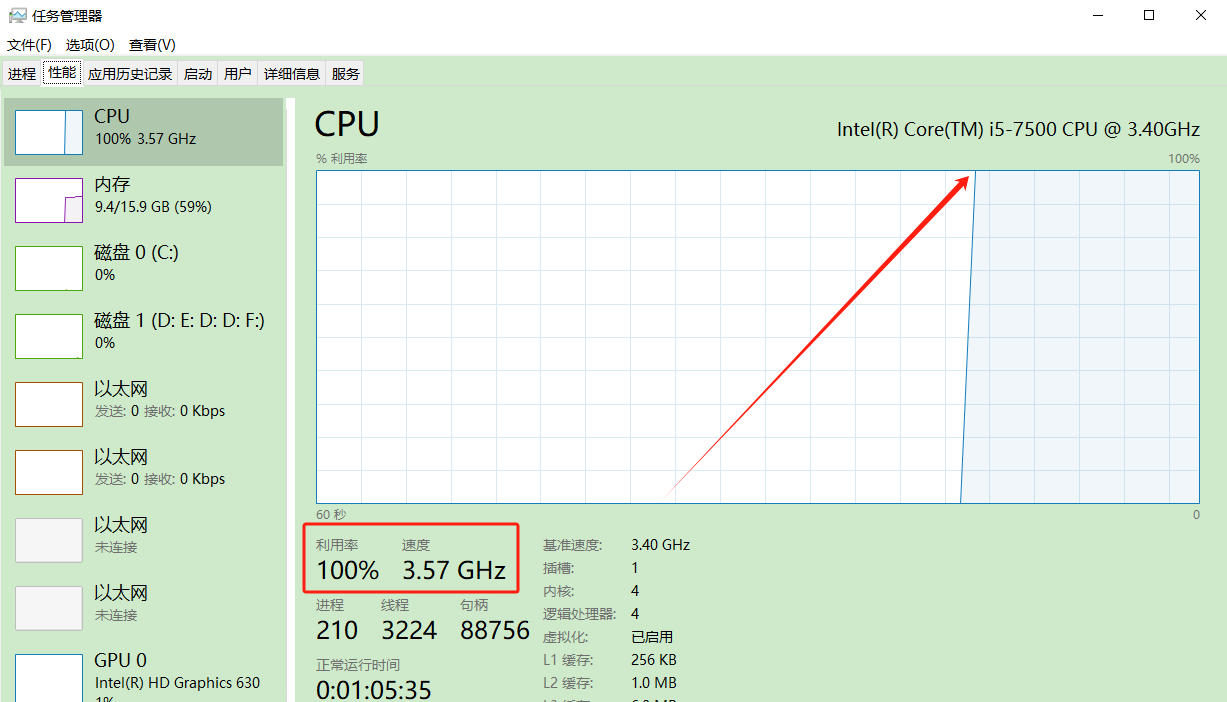
比如这里的模型参数越大,对机器的要求就越高
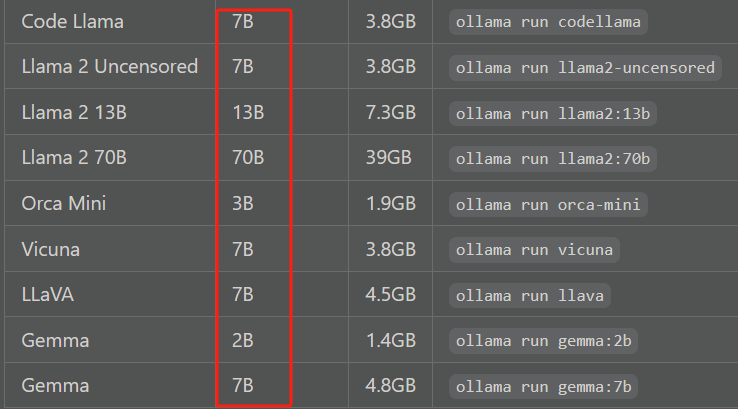
注意:您应该至少有8 GB的RAM可用于运行7B型号,16 GB用于运行13B型号,32 GB用于运行33B型号。
至于CPU的要求,切切的说是GPU的要求,在国外的一个硬件网站上有列举出:

详细的可以在这里看:
hardware-corner.net/guides/computer-to-run-llama-ai-model
后续会有相关文章介绍ollama的使用及微调大语言模型。




)


)











