
- 错误3 也有可能会遇到以下错误,按照下面提示解决
Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)
如果metrics-server正常启动,没有错误,应该就是网络问题。修改metrics-server的Pod 网络模式:
hostNetwork: true
[root@server1 harbor]# docker pull kubernetesui/metrics-scraper:v1.0.6
[root@server1 harbor]# docker tag kubernetesui/metrics-scraper:v1.0.6 reg.westos.org/kubernetesui/metrics-scraper:v1.0.6
[root@server1 harbor]# docker push reg.westos.org/kubernetesui/metrics-scraper:v1.0.6
[root@server1 harbor]# docker pull kubernetesui/dashboard:v2.2.0
[root@server1 harbor]# docker tag kubernetesui/dashboard:v2.2.0 reg.westos.org/kubernetesui/dashboard:v2.2.0
[root@server1 harbor]# docker push reg.westos.org/kubernetesui/dashboard:v2.2.0[root@server2 ~]# mkdir dashboard/
[root@server2 ~]# cd dashboard/
[root@server2 dashboard]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.2.0/aio/deploy/recommended.yaml
[root@server2 dashboard]# kubectl apply -f recommended.yaml注意两个镜像名称
[root@server2 dashboard]# kubectl -n kubernetes-dashboard describe sa kubernetes-dashboard
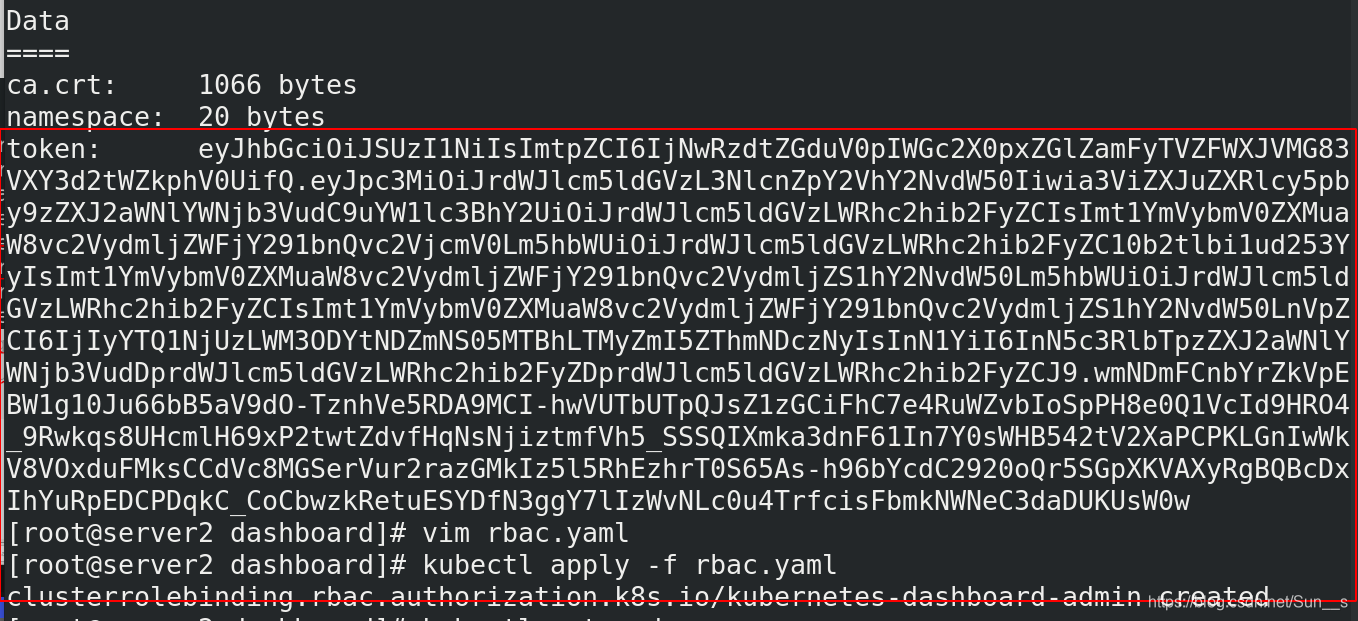
[root@server2 dashboard]# kubectl describe secrets kubernetes-dashboard-token-nwnwc -n kubernetes-dashboard
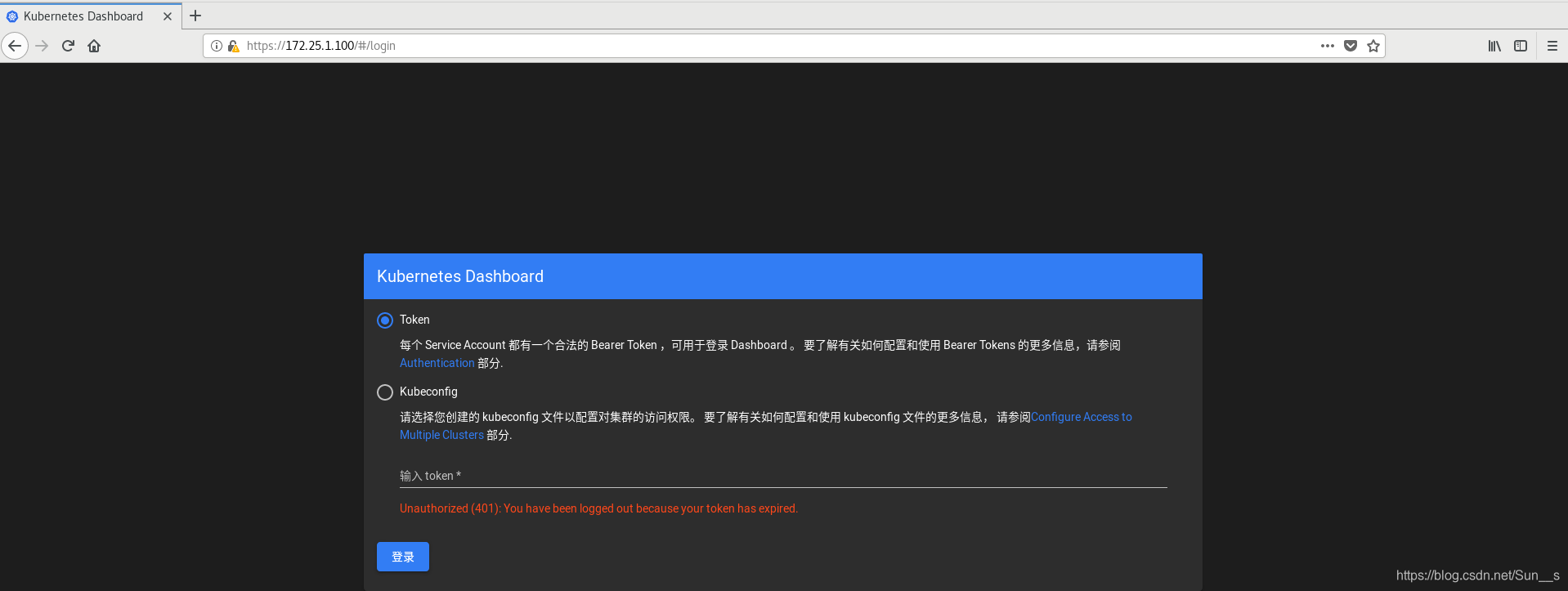
将上面的token输入网址就可以进入
HPA
官网:https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
HPA伸缩过程:
收集HPA控制下所有Pod最近的cpu使用情况(CPU utilization)
对比在扩容条件里记录的cpu限额(CPUUtilization)
调整实例数(必须要满足不超过最大/最小实例数)
每隔30s做一次自动扩容的判断
CPU utilization的计算方法是用cpu usage(最近一分钟的平均值,通过metrics可以直接获取到)除以cpu request(这里cpu request就是我们在创建容器时制定的cpu使用核心数)得到一个平均值,这个平均值可以理解为:平均每个Pod CPU核心的使用占比。
HPA进行伸缩算法:
计算公式:TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target)ceil()表示取大于或等于某数的最近一个整数每次扩容后冷却3分钟才能再次进行扩容,而缩容则要等5分钟后。
当前Pod Cpu使用率与目标使用率接近时,不会触发扩容或缩容:
触发条件:avg(CurrentPodsConsumption) / Target >1.1 或 <0.9
[root@server2 ~]# mkdir hpa/
[root@server2 ~]# cd hpa/
[root@server2 hpa]# vim hpa.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: php-apache
spec:selector:matchLabels:run: php-apachereplicas: 1template:metadata:labels:run: php-apachespec:containers:- name: php-apacheimage: hpa-exampleports:- containerPort: 80resources:limits:cpu: 500mrequests:cpu: 200m---apiVersion: v1
kind: Service
metadata:name: php-apachelabels:run: php-apache
spec:ports:- port: 80selector:run: php-apache[root@server2 hpa]# kubectl apply -f hpa.yaml
[root@server2 hpa]# kubectl describe svc php-apache
[root@server2 hpa]# curl 10.108.66.200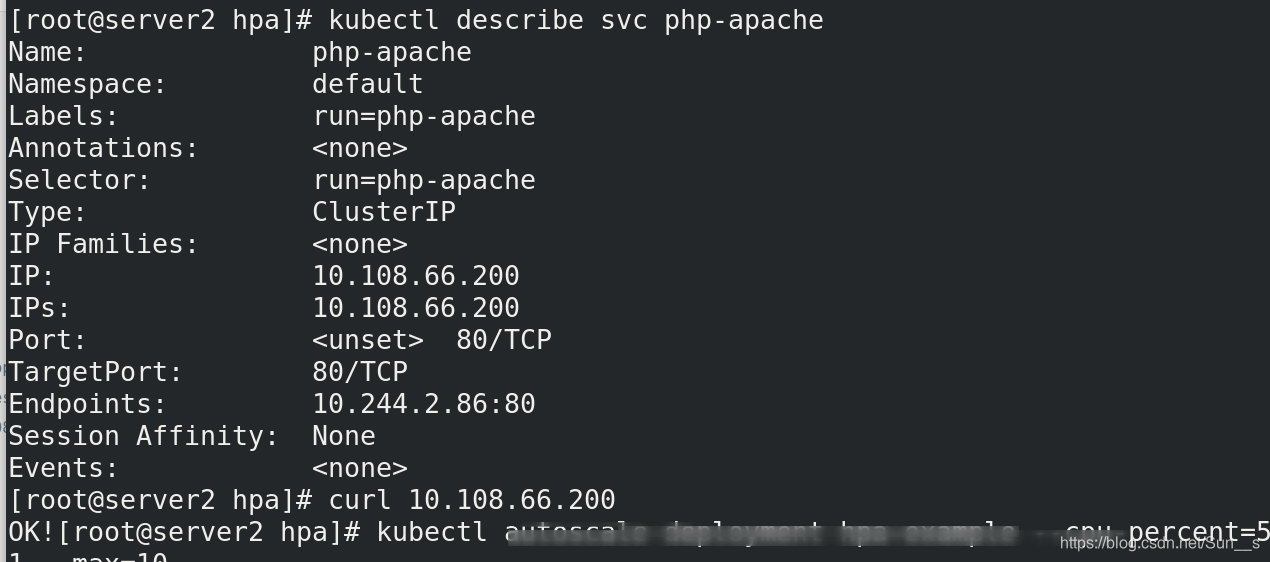
[root@server2 hpa]# kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
[root@server2 hpa]# kubectl get hpa
[root@server2 hpa]# kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"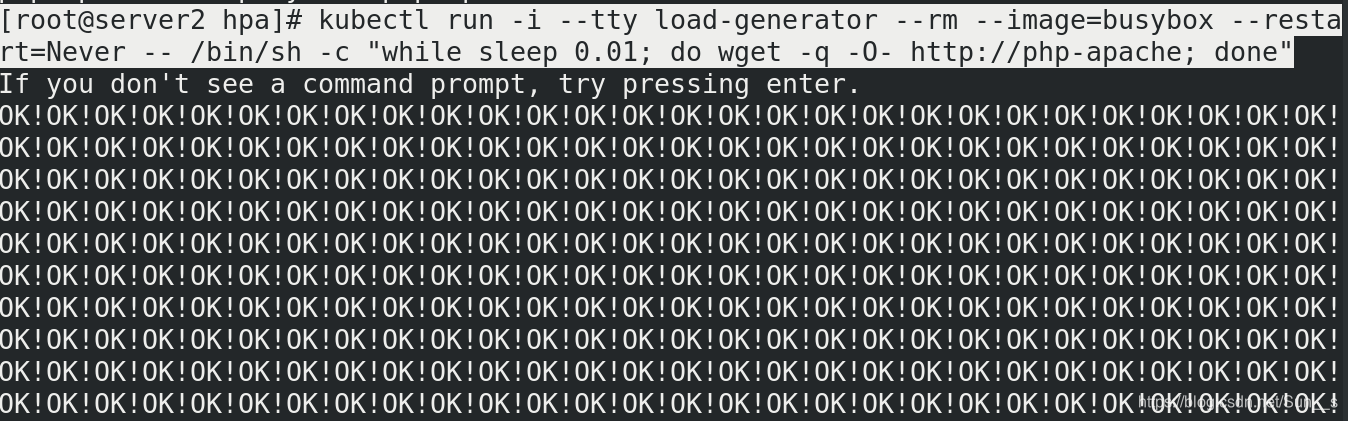
[root@server2 hpa]# vim hpa-v2.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:maxReplicas: 10minReplicas: 1scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apachemetrics:- type: Resourceresource:name: cputarget:averageUtilization: 60type: Utilization- type: Resourceresource:name: memorytarget:averageValue: 50Mitype: AverageValue[root@server2 hpa]# kubectl apply -f hpa-v2.yaml
[root@server2 hpa]# kubectl get hpa
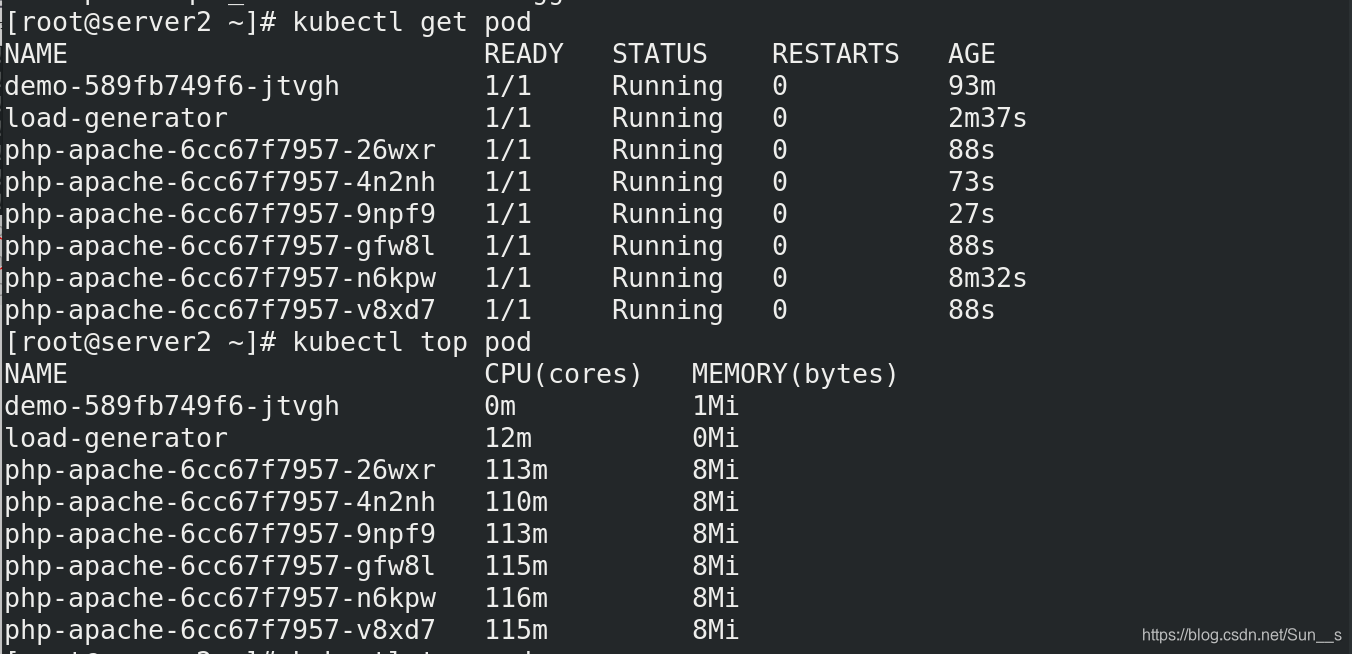
[root@server2 hpa]# kubectl get pod

Hpa会根据Pod的CPU使用率动态调节Pod的数量。
HELM
Helm是Kubernetes 应用的包管理工具,主要用来管理 Charts,类似Linux系统的yum。
Helm Chart 是用来封装 Kubernetes 原生应用程序的一系列 YAML 文件。可以在你部署应用的时候自定义应用程序的一些 Metadata,以便于应用程序的分发。
对于应用发布者而言,可以通过 Helm 打包应用、管理应用依赖关系、管理应用版本并发布应用到软件仓库。
对于使用者而言,使用 Helm 后不用需要编写复杂的应用部署文件,可以以简单的方式在 Kubernetes 上查找、安装、升级、回滚、卸载应用程序。
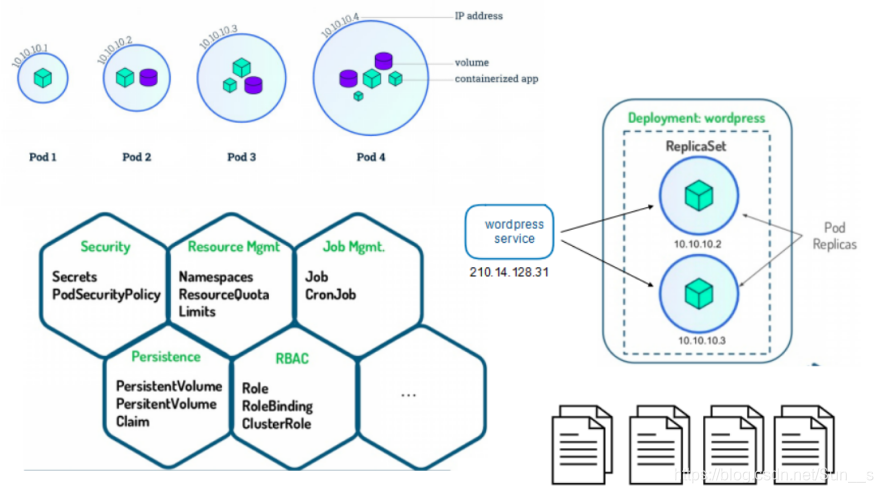
Helm V3 与 V2 最大的区别在于去掉了tiller:
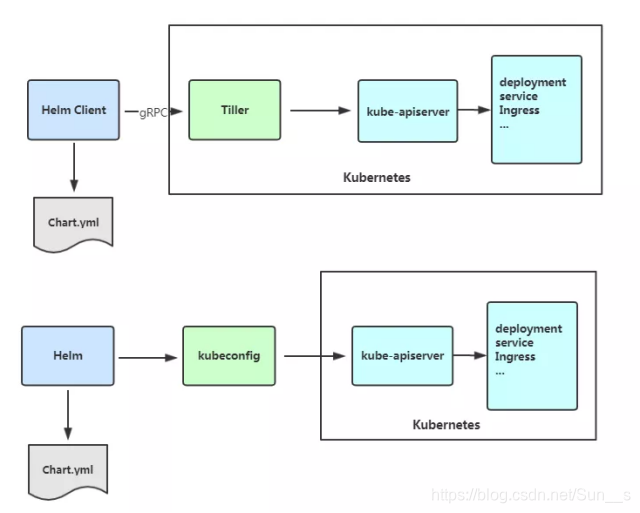
Helm当前最新版本 v3.1.0 官网:https://helm.sh/docs/intro/
Helm安装:
[root@server2 ~]# mkdir helm
[root@server2 ~]# cd helm/
get helm-v3.4.1-linux-amd64.tar.gz
[root@server2 helm]# tar zxf helm-v3.4.1-linux-amd64.tar.gz
[root@server2 helm]# cd linux-amd64/
[root@server2 linux-amd64]# cp helm /usr/local/bin/
[root@server2 linux-amd64]# helm env[root@server2 ~]# helm repo add dandydev https://dandydeveloper.github.io/charts
[root@server2 helm]# helm pull dandydev/redis-ha
[root@server2 helm]# tar axf redis-ha-4.12.9.tgz
[root@server2 helm]# cd redis-ha/
[root@server2 redis-ha]# vim values.yaml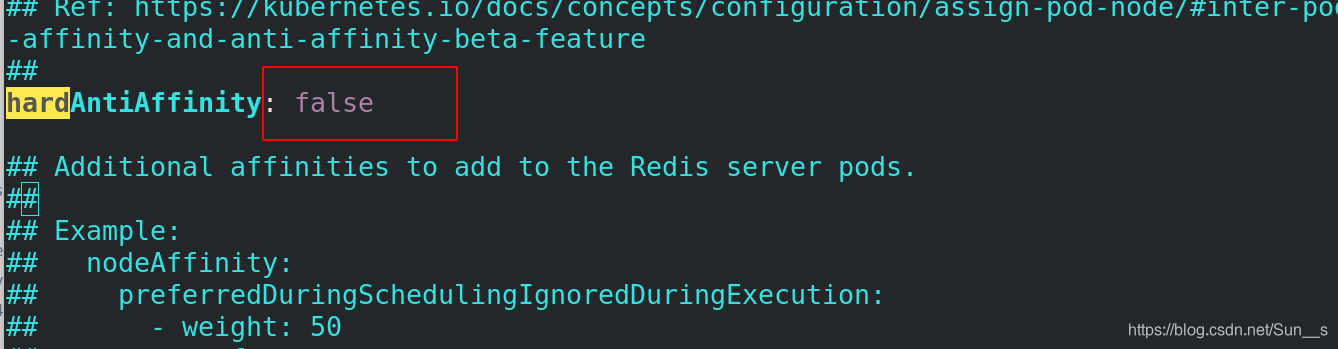
本地仓库里需要的镜像
[root@server1 harbor]# docker pull redis:6.0.7-alpine
[root@server1 harbor]# docker tag redis:6.0.7-alpine reg.westos.org/library/redis:6.0.7-alpine
[root@server1 harbor]# docker push reg.westos.org/library/redis:6.0.7-alpine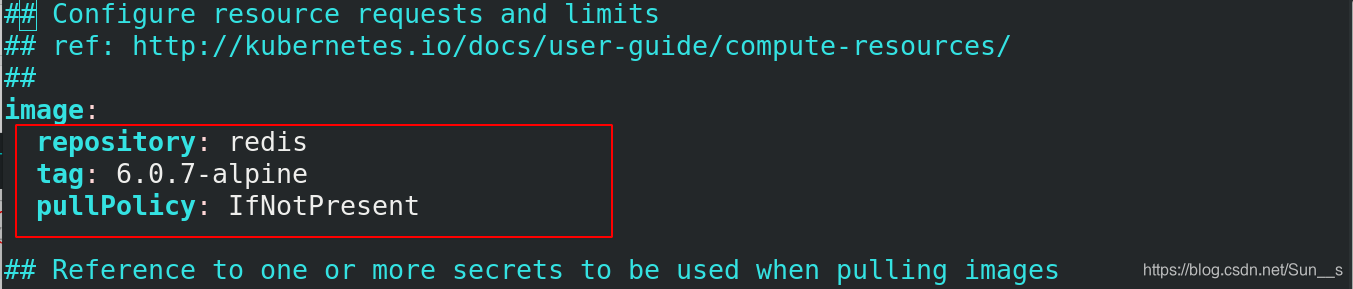
将存储位置指向默认分配
[root@server2 redis-ha]# kubectl patch storageclass managed-nfs-storage -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
[root@server2 redis-ha]# helm install redis-ha .
[root@server2 redis-ha]# kubectl get pod -w会慢慢运行起来,等待全部运行起来即可

[root@server2 redis-ha]# kubectl exec -it redis-ha-server-0 sh -n default
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
Defaulting container name to redis.
Use 'kubectl describe pod/redis-ha-server-0 -n default' to see all of the containers in this pod.
/data $ redis-cli
127.0.0.1:6379> info这里我们看到master是0
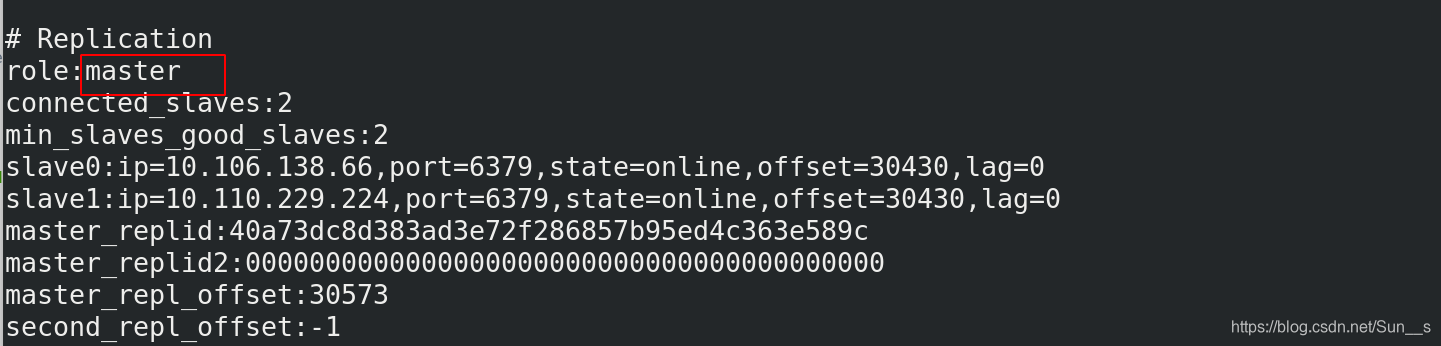
当我们把0的pod删除之后,再次登陆一个查看master会调度到哪一个
[root@server2 redis-ha]# kubectl delete pod redis-ha-server-0
[root@server2 redis-ha]# kubectl exec -it redis-ha-server-1 sh -n default
/data $ redis-cli
127.0.0.1:6379> info这时我们看到现在1已经成为了master
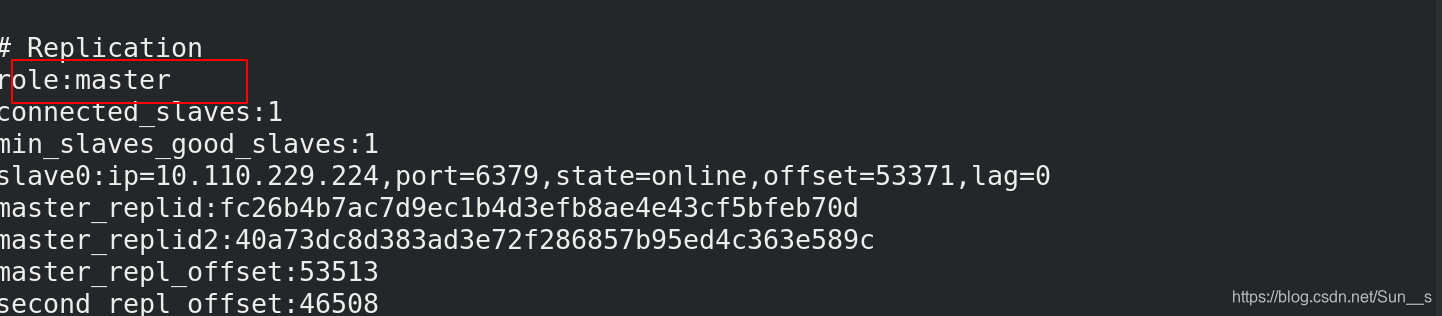
手动创建
[root@server2 ~]# cd helm/
[root@server2 helm]# helm create mychart
[root@server2 helm]# tree mychart/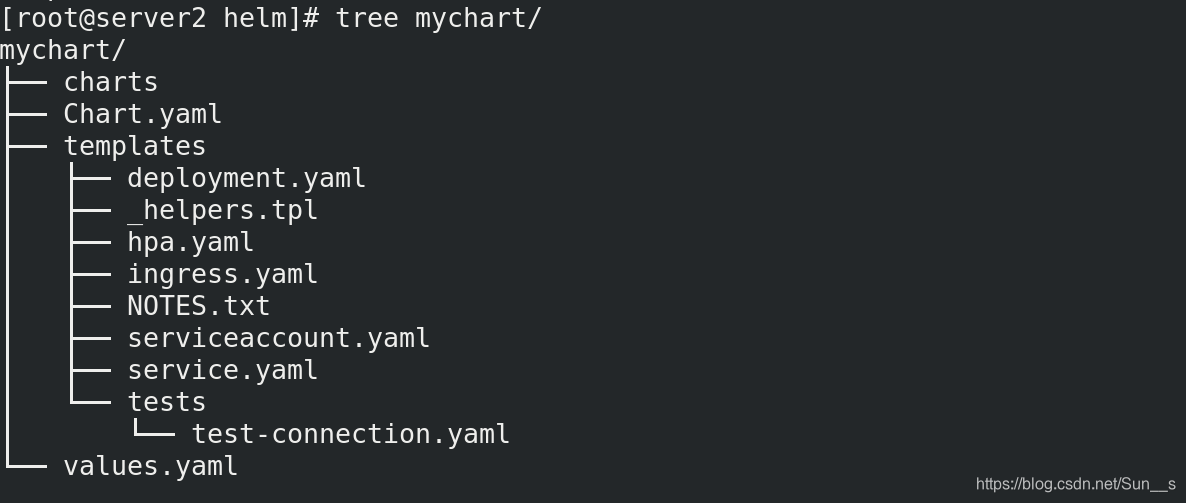
[root@server2 helm]# cd mychart/
[root@server2 mychart]# vim Chart.yaml
[root@server2 mychart]# vim values.yaml检测是否有错误
[root@server2 mychart]# cd ..
[root@server2 helm]# helm lint mychart/
将应用打包
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)

WkCA6DFB-1712501552801)]
[外链图片转存中…(img-4KpVf68S-1712501552801)]
[外链图片转存中…(img-i5jvowTS-1712501552801)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)
[外链图片转存中…(img-mTJcHlLR-1712501552801)]











领域类图-作战推演)







