大家好,我是微学AI,今天给大家介绍一下深度学习实战73-基于多模态CLIP模型的实战项目,CLIP模型的架构介绍与代码实现。多模态CLIP(Contrastive Language-Image Pre-training)模型是一种深度学习模型,其核心设计理念是通过大规模的对比学习训练,实现图像与文本之间的跨模态对齐和理解。该模型的独特之处在于其能够联合处理并理解图像和文本两种不同类型的输入数据,从而在多种应用场景中展现强大的性能。
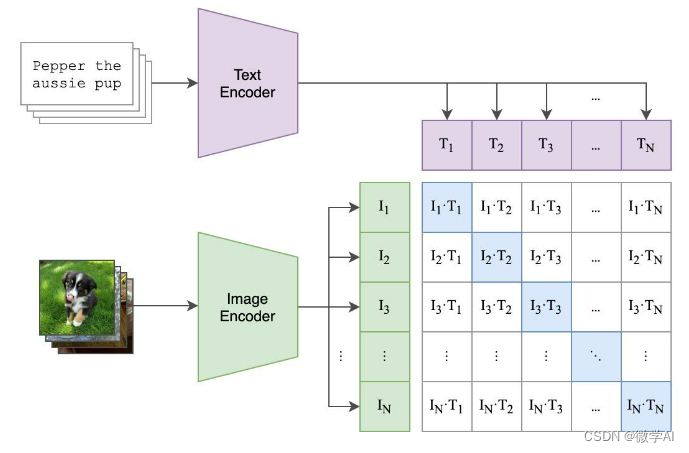
在模型结构上,CLIP由两个主要部分构成:视觉编码器和文本编码器。视觉编码器用于提取图像特征,通常采用Transformer或卷积神经网络架构;而文本编码器则负责捕获文本描述的语义信息,通常基于Transformer架构。这两个编码器分别将图像和文本映射到相同的向量空间,使得具有相似语义的图像和文本能够在该空间中距离相近。
CLIP模型广泛应用于图像检索、图像分类、图文生成、零样本学习等多种任务。例如,在零样本设置下,CLIP可以直接理解从未在训练集中见过的新类别标签,并据此进行准确的图像分类。此外,CLIP还能有效提升模型对于未见过的任务或领域的泛化能力,为跨模态AI应用开辟了新的可能性。
文章目录
- 一、应用场景介绍
- 视觉-文本检索应用
- 零样本学习场景
)














)
、精确率(Precision)、召回率(recall)和F1-Score模型评估参数)
——SBP的Bundle写操作生成)

)