Walk These Ways: 通过行为多样性调整机器人控制以实现泛化
摘要:
通过学习得到的运动策略可以迅速适应与训练期间经历的类似环境,但在面对分布外测试环境失败时缺乏快速调整的机制。这就需要一个缓慢且迭代的奖励和环境重新设计周期来在新任务上达成良好表现。作为一种替代方案,我们提出学习一个单一策略,该策略编码了一个结构化的运动策略家族,这些策略以不同的方式解决训练任务,从而产生行为的多样性(MoB)。不同的策略具有不同的泛化能力,并且可以实时为新任务或环境选择,绕过了耗时的再训练需求。我们发布了一个快速、稳健的开源MoB运动控制器“Walk These Ways”,它能执行多样的步态,具有可变的足摆、姿态和速度,解锁多样的下游任务:蹲伏、单脚跳、高速跑步、楼梯穿越、抵抗推挤、有节奏的舞蹈等等。
视频和代码发布在:https://gmargo11.github.io/walk-these-ways/
介绍:
MoB的实用性基于这样一个假设:在限制的训练环境中成功的某些行为子集,在分布外目标环境中也会成功。为了有意义地证明这一点,我们选择了一个极端案例**:仅在平地上训练一个四足行走的单一策略,并在非平地地形和新任务上进行评估。**我们展示了人类操作者可以实时调整行为,以在多样未见地形和动力学环境中成功进行运动,包括不平坦的地面、楼梯、外部推力和限制空间(图1)。同样的调整机制可用于组合行为,以执行新任务,如有效载荷操纵和节奏舞蹈(图1)。

图1:行为的多样性(MoB)使人类能够将一个在平地上训练的单一四足策略调整为多样的未见环境。顶部行:低频步态在滑腻地面上无法快速奔跑(步态2;插图),但将其调整为高频则成功(步态1)。然而,低频和高摆动高度对于楼梯穿越是必需的(步态2;中间图片)。低摆动和宽站姿(步态3)使机器人对腿部推力具有鲁棒性,但在快速奔跑中成功的步态1失败了。因此,调整步态有助于泛化到不同的任务。底部行:我们的控制器启用的其他行为示例。
背景:
辅助奖励:仅使用任务奖励(例如,速度跟踪)学习到的运动步态未能成功转移到现实世界。为了弥补模拟到现实的差距,需要使用辅助奖励进行训练,这些奖励使机器人保持特定的接触计划、动作平滑度、能量消耗或足部间隙[1, 2, 3, 5, 6, 7],以补偿模拟与现实之间的差距。这样的辅助奖励可以被解释为泛化的偏差。例如,足部间隙使机器人在真实世界的地形更加不平或机器人在真实世界中比在模拟中更深陷时更加鲁棒[7]。如果一个代理在真实世界的任务中失败了,通常的做法是手动调整辅助奖励,以鼓励成功的真实世界行为的出现。然而,这种调整是乏味的,因为它需要重复的训练和部署迭代。此外,这种调整是特定于任务的,对于指令给代理的新任务必须重复进行。在图1的顶部行插图中说明了设计一套既促进多样化下游任务中泛化的单一辅助奖励集的难度:每一个都展示了一个情况,其中固定的辅助奖励会导致一个任务失败,尽管它对另一个任务效果良好。
带有参数化风格的运动学习:与四足机器人相关的近期工作已经通过增强参数的辅助奖励项将步态参数明确包含在任务规格中,这包括追踪接触模式[8]和目标脚部位置[9]的奖励。文献[8]在双足运动中使用了依赖于步态的奖励项来控制两只脚之间的时间偏移和摆动阶段的持续时间。文献[8]的奖励结构启发了我们的研究,但由于其指令参数的空间较小,它没有提出也不支持应用于组合任务或分布外环境。为了达到类似的效果,其他工作通过引用步态库强加了参数化的风格。文献[10, 11]生成了一个参考轨迹库,并训练了一个以目标为条件的策略来模仿它们。文献[12]展示了可以同时从一个参考轨迹库中学习一小组离散的运动风格。(AMP相关工作)
带有多样性目标的学习:一些先前的方法旨在自动学习一系列高性能且多样化的行为。质量多样性(QD)方法[13, 14, 15]通过强制执行在轨迹之间定义的新颖性目标来学习一个多样化策略库。它们通常使用进化策略来执行这种优化。QD已经展示了包括改进的优化性能和在线适应中技能复用的好处[13, 14]。另一系列工作使用无监督目标进行强化学习中的技能发现,以改善优化[16]或分布外泛化[17, 18]。无监督的多样性方法很有前景,但它们尚未扩展到真实的机器人平台,并且不产生用于指导行为的参数的实际界面。
通过步态参数的分层控制:几项研究通过调节基于模型的低级控制器的步态参数,学习了一个高级策略来完成下游任务。这种方法之前已经应用于能量最小化[19]和视觉引导的脚部放置[20, 21]。这些工作依赖于一个模型预测的低级控制器在没有步态条件学习控制器的情况下执行不同的步态。基于模型的控制与强化学习之间的权衡在先前的文献中已经讨论得很充分[3, 22]。我们的工作使得可以重新审视在高级和低级都有学习的分层方法。
方法:
为了获得行为的多样性(MoB),我们训练了一个条件策略 π ( ⋅ ∣ c t , b t ) \pi(\cdot | c_t, b_t) π(⋅∣ct,bt),该策略能够通过不同的行为参数 b t b_t bt的选择,以多种方式实现由指令 c t c_t ct指定的任务。关于如何定义 b t b_t bt的问题随之而来。我们可以使用无监督的多样性指标来学习行为,但这些行为可能不实用[4],并且不能被人类调整。为了解决这些问题,我们利用人类对有用行为参数( b t b_t bt)的直觉,这些参数对应于步态特性,如足部摆动运动、身体姿态和接触时间表[6, 7, 8, 23]。在训练过程中,代理接收任务奖励(用于速度跟踪)、固定辅助奖励(促进模拟到现实的转换和稳定运动)的组合,以及最后的增强辅助奖励(鼓励以期望的风格进行运动)。在新环境中部署时,人类操作者可以通过改变其输入 b t b_t bt 来调整策略的行为。

表1:奖励结构:任务奖励、增强辅助奖励和固定辅助奖励。
- MoB任务框架
任务规格:我们考虑全方位速度跟踪的任务。这个任务由一个三维指令向量 c t = [ v cmd x , v cmd y , ω cmd z ] c_t = [v_{\text{cmd}_x}, v_{\text{cmd}_y}, \omega_{\text{cmd}_z}] ct=[vcmdx,vcmdy,ωcmdz]指定,其中 v cmd x , v cmd y v_{\text{cmd}_x}, v_{\text{cmd}_y} vcmdx,vcmdy是身体框架x轴和y轴上的期望线性速度,而 ω cmd z \omega_{\text{cmd}_z} ωcmdz是偏航轴上的期望角速度。
行为规格:我们通过一个8维的行为参数向量 b t b_t bt来参数化任务完成的风格:
b t = [ θ cmd 1 , θ cmd 2 , θ cmd 3 , f cmd , h cmd z , φ cmd , s cmd y , h f , cmd z ] b_t = [\theta_{\text{cmd}_1}, \theta_{\text{cmd}_2}, \theta_{\text{cmd}_3}, f_{\text{cmd}}, h_{\text{cmd}_z}, \varphi_{\text{cmd}}, s_{\text{cmd}_y}, h_{f,\text{cmd}_z}] bt=[θcmd1,θcmd2,θcmd3,fcmd,hcmdz,φcmd,scmdy,hf,cmdz]
其中 θ cmd = ( θ cmd 1 , θ cmd 2 , θ cmd 3 ) \theta_{\text{cmd}} = (\theta_{\text{cmd}_1}, \theta_{\text{cmd}_2}, \theta_{\text{cmd}_3}) θcmd=(θcmd1,θcmd2,θcmd3)是脚之间的时间偏移,这些表达了包括pronging( θ cmd = ( 0.0 , 0 , 0 ) \theta_{\text{cmd}} = (0.0, 0, 0) θcmd=(0.0,0,0))、trotting( θ cmd = ( 0.5 , 0 , 0 ) \theta_{\text{cmd}} = (0.5, 0, 0) θcmd=(0.5,0,0))、bounding( θ cmd = ( 0 , 0.5 , 0 ) \theta_{\text{cmd}} = (0, 0.5, 0) θcmd=(0,0.5,0))、pacing( θ cmd = ( 0 , 0 , 0.5 ) \theta_{\text{cmd}} = (0, 0, 0.5) θcmd=(0,0,0.5))以及它们的连续插值,如galloping( θ cmd = ( 0.25 , 0 , 0 ) \theta_{\text{cmd}} = (0.25, 0, 0) θcmd=(0.25,0,0))等步态。总的来说, θ cmd \theta_{\text{cmd}} θcmd参数可以表达所有两拍四足接触模式;图2提供了一个视觉插图。 f cmd f_{\text{cmd}} fcmd是步进频率,以Hz表示。例如,指令 f cmd = 3 f_{\text{cmd}} = 3 fcmd=3Hz 将导致每只脚每秒接触地面三次。 h cmd z h_{\text{cmd}_z} hcmdz是身体高度指令; φ cmd \varphi_{\text{cmd}} φcmd是身体俯仰指令。 s cmd y s_{\text{cmd}_y} scmdy是脚步姿态宽度指令; h f , cmd z h_{f,\text{cmd}_z} hf,cmdz 是足摆高度指令。
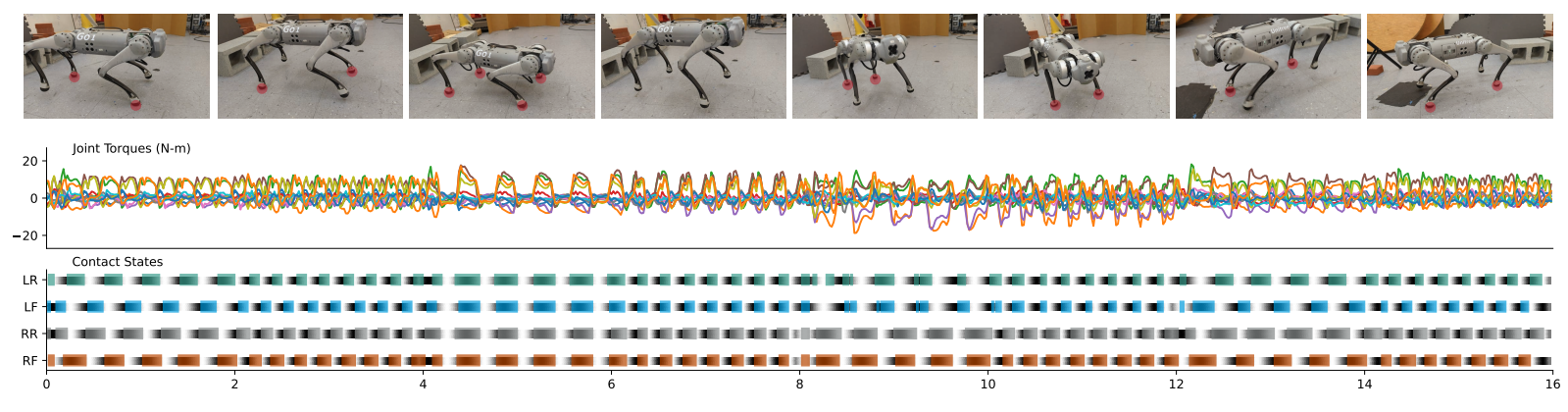
图2:一个学习到的控制器在2Hz和4Hz的交替频率下,在经典的结构化步态之间进行转换:小跑、跳跃、配步和原地蹦跳。图片展示了机器人实现每种步态的接触阶段,站立的脚以红色高亮显示。底部图表中的黑色阴影反映了每只脚的定时参考变量 t t t_t tt;彩色条形报告了脚部传感器测量到的接触状态。正如我们后来揭示的,多样化的行为可以促进新的下游能力。
奖励函数:所有奖励项都列在表1中。身体速度跟踪的任务奖励被定义为指令向量 c t c_t ct的函数。辅助奖励用于各种原因约束四足动物的运动。“固定” 辅助奖励独立于行为参数( b t b_t bt)并鼓励所有步态的稳定性和平滑性,以实现更好的模拟到现实转换。
在训练过程中,一个担忧是**机器人可能会放弃任务或在辅助目标的惩罚压倒任务奖励时选择提前终止。**为了解决这个问题,正如[7]中所做的,我们通过计算 r task exp ( c aux r aux ) r_{\text{task}} \exp (c_{\text{aux}} r_{\text{aux}}) rtaskexp(cauxraux)使总奖励成为任务奖励的正线性函数,其中 r task r_{\text{task}} rtask是(正的)任务奖励项的和, r aux r_{\text{aux}} raux是(负的)辅助奖励项的和(我们使用 c aux = 0.02 c_{\text{aux}} = 0.02 caux=0.02)。这样,代理始终因为朝任务进展而获得奖励,当满足辅助目标时获得更多,当不满足时获得较少。
对于MoB,我们将增强辅助奖励定义为行为向量 b t b_t bt的函数。我们设计这些奖励以增加在实现的行为与 b t b_t bt匹配时,并且不与任务奖励冲突。这需要一些对奖励结构的仔细设计。例如,在将站姿宽度作为行为参数实现时,一个简单的方法是奖励左右脚之间的恒定期望距离。然而,这在需要脚相对侧向运动的快速转弯任务中会惩罚机器人。为了避免这种情况,我们实现了Raibert启发式,它建议脚部的必要运动学运动,以实现特定的身体速度和接触时间表[23, 24]。Raibert启发式计算地面平面中期望的脚位置 p f , x , y , cmd foot ( s cmd y ) p_{f,x,y,\text{cmd}}^{\text{foot}}(s_{\text{cmd}_y}) pf,x,y,cmdfoot(scmdy),作为对机器人站姿宽度的调整,使其与期望的接触时间表和身体速度一致。为了定义期望的接触时间表,函数 C foot cmd ( θ cmd , t ) C_{\text{foot}}^{\text{cmd}}(\theta_{\text{cmd}}, t) Cfootcmd(θcmd,t) 根据相位和时间变量计算每只脚的期望接触状态,如[8]中所述,细节在附录中给出。
- 学习多样化运动
任务和行为采样:为了学习在行为之间优雅的在线过渡,我们在每个训练阶段重新采样所需的任务和行为。为了使机器人能够快速跑步和快速旋转,我们使用来自[3]的网格自适应课程策略对任务 c t = ( v cmd x , v cmd y , ω cmd z ) c_t = (v_{\text{cmd}_x}, v_{\text{cmd}_y}, \omega_{\text{cmd}_z}) ct=(vcmdx,vcmdy,ωcmdz)进行采样。(命令的课程策略,简单来说就是从易到难,从低速到高速)然后,我们需要采样一个目标行为 b t b_t bt。首先,我们将 ( θ cmd 1 , θ cmd 2 , θ cmd 3 ) (\theta_{\text{cmd}_1}, \theta_{\text{cmd}_2}, \theta_{\text{cmd}_3}) (θcmd1,θcmd2,θcmd3)采样为对称的四足接触模式之一(跳跃、小跑、蹦跳或配步),这些被认为是更稳定的,并且我们发现它们是多样化有用步态的足够基础。然后,其余的指令参数 ( v cmd y , f cmd , h cmd z , φ cmd , h f , cmd z , s cmd y ) (v_{\text{cmd}_y}, f_{\text{cmd}}, h_{\text{cmd}_z}, \varphi_{\text{cmd}}, h_{f,\text{cmd}_z}, s_{\text{cmd}_y}) (vcmdy,fcmd,hcmdz,φcmd,hf,cmdz,scmdy)独立且均匀地被采样。它们的范围在表6中给出。(只有重要的两个角/线速度用了课程策略,其他都是均匀采样)
策略输入:策略的输入是观测 o t − H . . . t o_{t-H...t} ot−H...t、命令 c t − H . . . t c_{t-H...t} ct−H...t、行为 b t − H . . . t b_{t-H...t} bt−H...t、之前的动作 a t − H − 1... t − 1 a_{t-H-1...t-1} at−H−1...t−1和定时参考变量 t t − H . . . t t_{t-H...t} tt−H...t的30步历史记录。观测空间 o t o_t ot包括关节位置和速度 q t , q ˙ t q_t, \dot{q}_t qt,q˙t(通过关节编码器测量)和身体框架中的重力矢量 g t g_t gt(通过加速计测量)。定时参考变量 t t = [ sin ( 2 π t F R ) , sin ( 2 π t F L ) , sin ( 2 π t R R ) , sin ( 2 π t R L ) ] t_t = [\sin(2\pi t_{FR}), \sin(2\pi t_{FL}), \sin(2\pi t_{RR}), \sin(2\pi t_{RL})] tt=[sin(2πtFR),sin(2πtFL),sin(2πtRR),sin(2πtRL)]由每只脚的偏移时间计算得出: [ t F R , t F L , t R R , t R L ] = [ t + θ cmd 2 + θ cmd 3 , t + θ cmd 1 + θ cmd 3 , t + θ cmd 1 , t + θ cmd 2 ] [t_{FR}, t_{FL}, t_{RR}, t_{RL}] = [t + \theta_{\text{cmd}_2} + \theta_{\text{cmd}_3}, t + \theta_{\text{cmd}_1} + \theta_{\text{cmd}_3}, t + \theta_{\text{cmd}_1}, t + \theta_{\text{cmd}_2}] [tFR,tFL,tRR,tRL]=[t+θcmd2+θcmd3,t+θcmd1+θcmd3,t+θcmd1,t+θcmd2],其中 t 是从 0 到 1 推进的计数器变量,每个步态周期递增,FR、FL、RR、RL 是四只脚。这种形式是从[8]改编的,用于表达四足步态。
[8] Sim-to-real learning of all common bipedal gaits via periodic reward composition
这里值得展开讲讲,步态主要由足部速度/轨迹,受力所决定,contact schedule也算是一个侧面体现,作者通过构造决定步态的关键信息以周期性奖励函数的形式进行tracking得到了步态。
实际计算将偏移时间裁剪至0到1之间:
{ t F R , t F L , t R R , t R L } = clip ( { t + θ cmd 3 , t + θ cmd 1 + θ cmd 3 , t + θ cmd 1 , t + θ cmd 2 } , 0 , 1 ) \{t_{FR}, t_{FL}, t_{RR}, t_{RL}\} = \text{clip}(\{t + \theta_{\text{cmd}_3}, t + \theta_{\text{cmd}_1} + \theta_{\text{cmd}_3}, t + \theta_{\text{cmd}_1}, t + \theta_{\text{cmd}_2}\}, 0, 1) {tFR,tFL,tRR,tRL}=clip({t+θcmd3,t+θcmd1+θcmd3,t+θcmd1,t+θcmd2},0,1)
在正弦波上采样到时间参考变量后带入:
C foot cmd ( t foot ( θ cmd , t ) ) = Φ ( t foot , σ ) × ( 1 − Φ ( t foot − 0.5 , σ ) ) + Φ ( t foot − 1 , σ ) × ( 1 − Φ ( t foot − 1.5 , σ ) ) C_{\text{foot}}^{\text{cmd}}(t_{\text{foot}}(\theta_{\text{cmd}}, t)) = \Phi(t_{\text{foot}}, \sigma) \times (1 - \Phi(t_{\text{foot}} - 0.5, \sigma)) + \Phi(t_{\text{foot}} - 1, \sigma) \times (1 - \Phi(t_{\text{foot}} - 1.5, \sigma)) Cfootcmd(tfoot(θcmd,t))=Φ(tfoot,σ)×(1−Φ(tfoot−0.5,σ))+Φ(tfoot−1,σ)×(1−Φ(tfoot−1.5,σ))
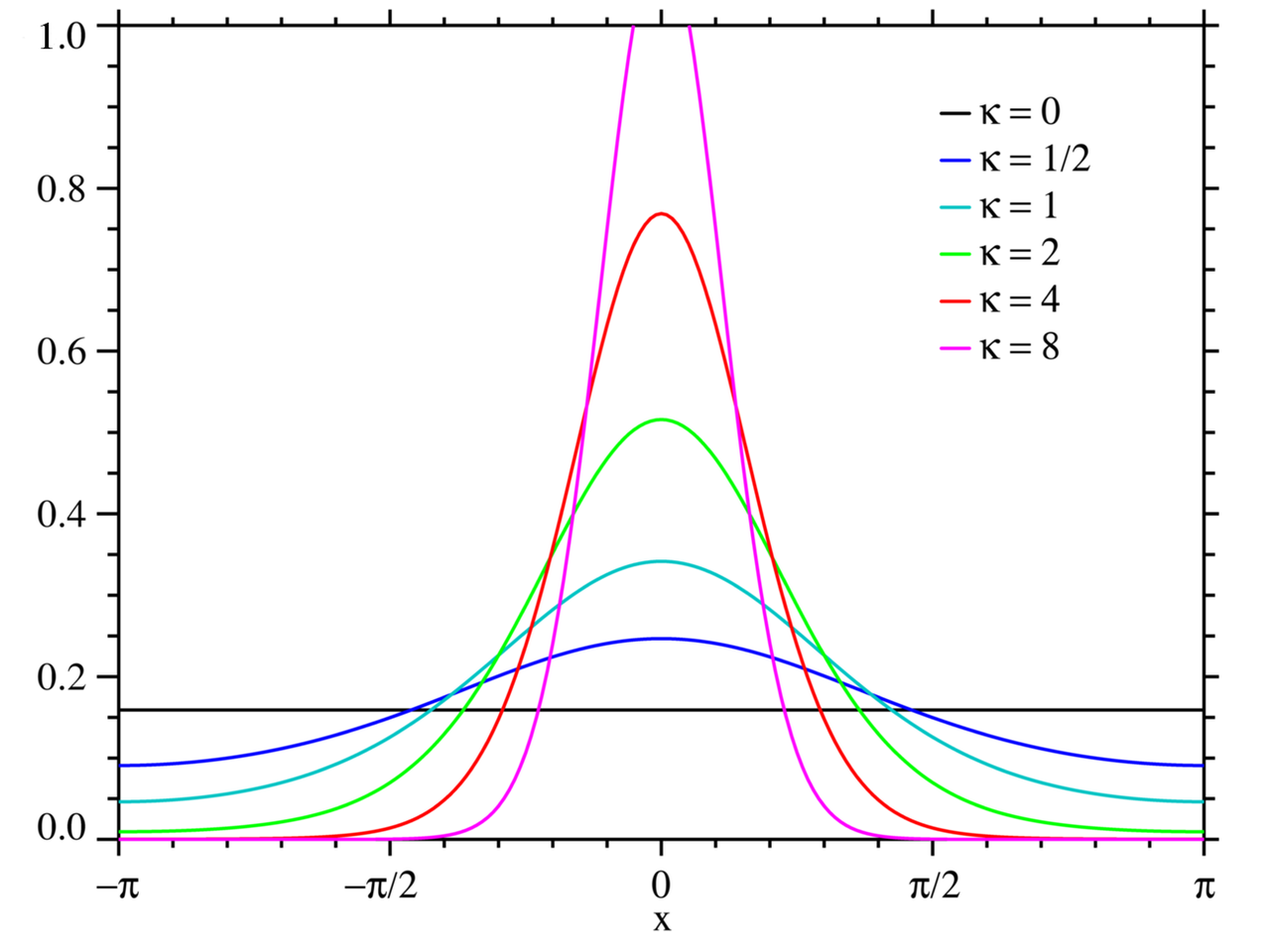
这个函数近似了Von Mises distribution,如下图,实际定义域为0到1,值域为0到1,在足部的支撑状态和摆动状态之间构建了一个平稳的过渡。(只能说构造的神!)
最后代入奖励函数中,调整足部受力和速度的目标,从而实现某种步态:
摆动相位跟踪(力):
∑ foot [ 1 − C foot cmd ( θ cmd , t ) ] exp ( − ∣ f foot ∣ 2 σ c f ) \sum_{\text{foot}} \left[1 - C_{\text{foot}}^{\text{cmd}}(\theta^{\text{cmd}}, t)\right] \exp\left(-\frac{|f^{\text{foot}}|^2}{\sigma_{cf}}\right) foot∑[1−Cfootcmd(θcmd,t)]exp(−σcf∣ffoot∣2)
支撑相位跟踪(速度):
∑ foot C foot cmd ( θ cmd , t ) exp ( − ∣ v x y foot ∣ 2 σ c v ) \sum_{\text{foot}} C_{\text{foot}}^{\text{cmd}}(\theta^{\text{cmd}}, t) \exp\left(-\frac{|v^\text{foot}_{xy}|^2}{\sigma_{cv}}\right) foot∑Cfootcmd(θcmd,t)exp(−σcv∣vxyfoot∣2)
策略架构:我们的策略主体是一个带有隐藏层大小 [512, 256, 128] 和 ELU 激活函数的 MLP。除了上述内容,策略输入还包括估计的领域参数:机器人身体的速度和地面摩擦力,这些是使用监督学习从观测历史中预测的,类似于[7]中的方式。估计器模块是一个带有隐藏层大小 [256, 128] 和 ELU 激活函数的 MLP。我们没有分析这种估计对性能的影响,但发现它对于可视化部署很有用。
动作空间:动作 a t a_t at包括十二个关节的位置目标。零动作对应于名义关节位置 q ^ \hat{q} q^。位置目标使用比例-微分控制器跟踪,其中 k p = 20 , k d = 0.5 k_p = 20, k_d = 0.5 kp=20,kd=0.5。
- 针对Sim-to-real的设计
域随机化:为了更好地实现从模拟到真实的转移,我们训练了一个对于机器人身体质量、电机强度、关节位置校准、地面摩擦力和恢复力以及重力的方向和大小范围健壮的策略。由于我们对研究分布外泛化感兴趣,我们仅在没有任何地形几何随机化的平坦地面上训练。这个选择也简化了训练。所有参数的随机化范围在附录A中。
延迟和执行器建模:直接识别不变属性避免了因不必要的域随机化而导致的过分保守行为。我们执行系统识别以减少机器人动力学中的模拟到真实差距。跟随[22]的做法,我们训练一个执行器网络来捕捉PD(比例-微分)误差和实现扭矩之间的非理想关系。另外,我们识别出我们系统中大约20毫秒的延迟,并在模拟过程中将其建模为一个恒定的动作延迟。
- 其他
模拟器和学习算法:我们在Isaac Gym模拟器[6, 25]中定义了我们的训练环境。我们使用邻近策略优化(Proximal Policy Optimization, [26])训练策略。
硬件:我们在Unitree Go1 Edu机器人[27]上将我们的控制器部署到真实世界中。一个板载的Jetson TX2 NX计算机运行我们训练好的策略。我们基于轻量级通信和封装(Lightweight Communications and Marshalling, LCM)[28]实现了一个接口,用于在我们的代码和Unitree提供的低级控制SDK之间传递传感器数据、电机指令和操纵杆状态。无论是训练还是部署,控制频率都是50Hz。
无步态baseline:为了理解MoB对性能的影响,我们将我们的控制器与基线速度跟踪控制器(“无步态baseline”)进行了比较。无步态baseline通过上述方法进行训练,但排除了所有增强辅助奖励(表1)。因此,它只学习了对训练环境的一种解决方案,其动作与行为参数 b t b_t bt无关。
实验:
- Sim-to-Real 和步态变换
我们将在模拟中学习到的控制器部署到真实世界中,并首先在与训练环境相似的平地上评估其性能。首先,我们展示了在运动学社区中众所周知的结构化步态之间生成和切换的能力。图2展示了在小跑、跳跃、蹦跳和配步之间转换时,同时在2Hz和4Hz之间交替 f cmd f_{\text{cmd}} fcmd时的扭矩和接触状态。我们发现,在模拟到真实转换后,所有步态参数都被一致跟踪(羡慕)。项目网站上的视频(i)-(iv)展示了通过单独调制 b t b_t bt中的每个参数获得的不同步态。
我们将在模拟中学习到的控制器部署到真实世界中,并首先在与训练环境相似的平地上评估其性能。首先,我们展示了如何在运动学界众所周知的结构化步态之间生成和切换。图2显示了在小跑、跳跃、蹦跳和配步之间转换时的扭矩和接触状态,同时在2Hz和4Hz之间交替 f cmd f_{\text{cmd}} fcmd。我们发现,所有步态参数在模拟到真实转换后都被一致地跟踪。项目网站上的视频(i)-(iv)展示了通过单独调制 b t b_t bt中的每个参数获得的不同步态。
- 借助MoB实现泛化
针对新任务的调整。在使用通用的运动目标进行训练后,人们可能希望调整控制器的行为,以便在原始环境中优化新的度量标准。如果学习到的某些行为子集按照新任务的度量超过了无步态策略,那么MoB将有助于这种调整。
能量效率(仿真环境中计量):我们考虑最小化机械功率消耗(J/s)的任务,该任务通过求和每个12个电机处的关节速度和扭矩的乘积来测量: ∑ i max ( τ i q ˙ i , 0 ) \sum_{i} \max(\tau_i \dot{q}_i, 0) ∑imax(τiq˙i,0)。如图3所示,多个接触时间表 θ cmd \theta_{\text{cmd}} θcmd、高度 h cmd z h_{\text{cmd}_z} hcmdz和频率 f cmd f_{\text{cmd}} fcmd的选择在这个度量中超过了无步态策略,跨所有速度消耗更少的能量。因此,调整行为参数可以有助于在原始训练环境中针对新目标(能量效率)调整性能。
似乎可以专门针对这个指标(能量效率)进行优化?
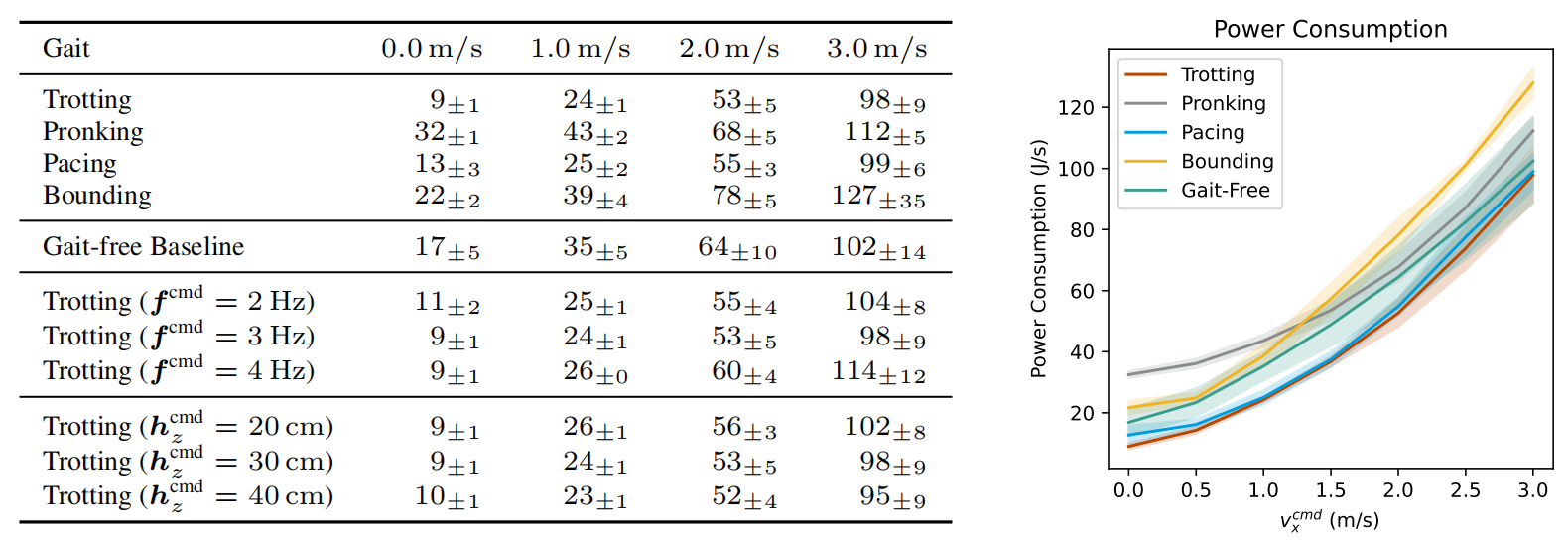
表3:行为调整使得可以在单一策略内部进行关于步态特性与性能标准之间关系的干预研究。这里,我们展示了对于常见的四足步态以及没有步态约束的基线策略,功率消耗如何随速度变化。几种结构化步态在所有速度上超过了无约束步态的效率。
更多实验详见主页视频。
结论和讨论
我们的实验表明,添加行为多样性(MoB)的好处可能会以牺牲分布内任务性能为代价,特别是限制了机器人在平地上的冲刺性能(附录中的表5)。热图揭示了我们的行为参数化对于高线性和角速度的组合是有限制的。量化和控制任务性能与奖励塑形之间的权衡是一个有趣的未来方向,对此一些先前的方法已经被提出[29]。
MoB为单个学习到的策略赋予了一个结构化且可控的多样化运动行为空间,适用于训练分布中的每个状态和任务。这提供了一组“旋钮”来调整未见测试环境中的运动技能性能。当前系统需要人类驾驶员手动调整其行为。未来,我们的系统的自主性可以通过使用来自现实世界人类演示的模仿来自动化行为选择,或者使用分层学习方法在部署期间自动自调整控制器来扩展。


)

)



)


 函数的应用)
、绘制直线(drawLine))




)

