概述
Redis集群,即Redis Cluster,是Redis 3.0开始引入的分布式存储方案。实际使用中集群一般由多个节点(Node)组成,Redis的数据分布在这些节点中。集群中的节点分为主节点和从节点:只有主节点负责读写请求和集群信息的维护;从节点只进行主节点数据和状态信息的复制。
集群的作用,可以归纳为两点:
1、数据分区:数据分区(或称数据分片)是集群最核心的功能。
集群将数据分散到多个节点,一方面突破了Redis单机内存大小的限制,存储容量大大增加;另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
Redis单机内存大小受限问题,在介绍持久化和主从复制时都有提及;例如,如果单机内存太大,bgsave和bgrewriteaof的fork操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出……。
2、高可用:集群支持主从复制和主节点的自动故障转移(与哨兵类似);当任一节点发生故障时,集群仍然可以对外提供服务。
本文内容基于Redis 6.0.6。
集群的搭建
环境说明
测试条件有限,这一部分我们将搭建一个简单的集群:共3个节点,3主3从共6个redis实例。规划如下:
| 主机名称 | IP地址 | redis版本和角色说明 |
|---|---|---|
| k8s-m1 | 192.168.2.140:6379 | redis 6.0.6(主) |
| k8s-m2 | 192.168.2.141:6379 | redis 6.0.6(主) |
| k8s-m3 | 192.168.2.142:6379 | redis 6.0.6(主) |
| k8s-m1 | 192.168.2.140:6380 | redis 6.0.6(从) |
| k8s-m2 | 192.168.2.141:6380 | redis 6.0.6(从) |
| k8s-m3 | 192.168.2.142:6380 | redis 6.0.6(从) |
集群的搭建有两种方式:(1)手动执行Redis命令,一步步完成搭建;(2)使用Ruby脚本搭建。二者搭建的原理是一样的,只是Ruby脚本将Redis命令进行了打包封装;在实际应用中推荐使用脚本方式,简单快捷不容易出错。下面分别介绍这两种方式。
通过Redis命令搭建集群
集群的搭建可以分为四步:
- 启动节点:将节点以集群模式启动,此时节点是独立的,并没有建立联系;
- 节点握手:让独立的节点连成一个网络;
- 分配槽:将16384个槽分配给主节点;
- 指定主从关系:为从节点指定主节点。
实际上,前三步完成后集群便可以对外提供服务;但指定从节点后,如果主节点出现问题会发生转移,集群才能够提供真正高可用的服务。
(1)启动节点
集群节点的启动仍然是使用redis-server命令,但需要使用集群模式启动。下面是其中一个节点上两个redis的配置文件(只列出了节点正常工作关键配置,其他配置(如开启AOF)可以参照单机节点进行):
[root@k8s-m1 redis]# cat redis-6379.conf
port 6379
cluster-enabled yes
cluster-config-file "node1-6379.conf"
logfile "log1-6379.log"
dbfilename "dump-1-6379.rdb"
daemonize yes[root@k8s-m1 redis]# cat redis-6380.conf
port 6380
cluster-enabled yes
cluster-config-file "node1-6380.conf"
logfile "log1-6380.log"
dbfilename "dump-1-6380.rdb"
daemonize yes
其中的cluster-enabled和cluster-config-file是与集群相关的配置。
cluster-enabled yes:Redis实例可以分为单机模式(standalone)和集群模式(cluster);cluster-enabled yes可以启动集群模式。在单机模式下启动的Redis实例,如果执行info server命令,可以发现redis_mode一项为standalone;集群模式下的节点,其redis_mode为cluster,如下所示:
127.0.0.1:6379> INFO server
# Server
redis_version:6.0.6
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:52f32f077b8711d9
redis_mode:cluster
os:Linux 3.10.0-957.el7.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:9.3.1
process_id:26832
run_id:adc677a616cd4c4516fa4f106d610c6234aaf133
tcp_port:6379
uptime_in_seconds:495
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:338056
executable:/usr/local/redis/./src/redis-server
config_file:/usr/local/redis/redis-6379.conf
cluster-config-file:该参数指定了集群配置文件的位置。每个节点在运行过程中,会维护一份集群配置文件;每当集群信息发生变化时(如增减节点),集群内所有节点会将最新信息更新到该配置文件;当节点重启后,会重新读取该配置文件,获取集群信息,可以方便的重新加入到集群中。也就是说,当Redis节点以集群模式启动时,会首先寻找是否有集群配置文件,如果有则使用文件中的配置启动,如果没有,则初始化配置并将配置保存到文件中。集群配置文件由Redis节点维护,不需要人工修改。
编辑好配置文件后,使用redis-server命令启动redis实例,其中一个节点如下:
[root@k8s-m1 redis]# ./src/redis-server redis-6379.conf
[root@k8s-m1 redis]# ./src/redis-server redis-6380.conf
[root@k8s-m1 redis]# ps aux|grep redis
root 8510 0.0 0.0 112812 980 pts/1 S+ 16:23 0:00 grep --color=auto redis
root 26832 0.1 0.0 162360 3488 ? Ssl 16:13 0:01 ./src/redis-server *:6379 [cluster]
root 28137 0.1 0.0 162360 3228 ? Ssl 16:14 0:00 ./src/redis-server *:6380 [cluster]
如果不能正常启动可以查看相应的日志文件。节点启动以后,通过cluster nodes命令可以查看节点的情况,如下所示。
[root@k8s-m1 redis]# ./src/redis-cli -p 6379 cluster nodes
0d601f868bc3a6f8be7c5dfc0434cc2c2ccc5264 :6379@16379 myself,master - 0 0 0 connected
[root@k8s-m1 redis]# ./src/redis-cli -p 6380 cluster nodes
d95662c7a6285bcab1acae439b74f848116fc85e :6380@16380 myself,master - 0 0 0 connected
说明:其中返回值第一项表示节点id,由40个16进制字符串组成,节点id与 主从复制 一文中提到的runId不同:Redis每次启动runId都会重新创建,但是节点id只在集群初始化时创建一次,然后保存到集群配置文件中,以后节点重新启动时会直接在集群配置文件中读取。
其他节点使用相同办法启动。需要特别注意,在启动节点阶段,节点是没有主从关系的,因此从节点不需要加slaveof配置。从上面也可以看到,没有配置主从关系的情况下,所有的节点初始都是master。
节点握手
节点启动以后是相互独立的,并不知道其他节点存在;需要进行节点握手,将独立的节点组成一个网络。注意为防止在同一服务器上的实例因为服务器的原因造成两个实例同时down掉,主从节点最好交叉不在同一台服务器上。
节点握手使用cluster meet {ip} {port}命令实现,例如在k8s-m1 节点的6379实例中执行cluster meet 192.168.2.140 6380 (交叉),可以完成该节点上的6379实例和该节点上的6380 实例的握手;注意ip使用的是局域网ip而不是localhost或127.0.0.1,是为了其他机器上的节点或客户端也可以访问。此时再使用cluster nodes查看:
[root@k8s-m1 redis]# ./src/redis-cli -p 6379
127.0.0.1:6379> cluster meet 192.168.2.140 6380
OK
127.0.0.1:6379> CLUSTER NODES
d95662c7a6285bcab1acae439b74f848116fc85e 192.168.2.140:6380@16380 master - 0 1711615119100 0 connected
0d601f868bc3a6f8be7c5dfc0434cc2c2ccc5264 192.168.2.140:6379@16379 myself,master - 0 0 1 connected
127.0.0.1:6379>
同样使用cluster meet命令,可以将所有节点加入到集群,完成节点握手,如下:
127.0.0.1:6379> cluster meet 192.168.2.141 6379
OK
127.0.0.1:6379> cluster meet 192.168.2.142 6379
OK
127.0.0.1:6379> cluster meet 192.168.2.142 6380
OK
127.0.0.1:6379> cluster meet 192.168.2.141 6380
OK
127.0.0.1:6379> CLUSTER NODES
b6a15068b05cf65bb13be1975730e395f3047b2c 192.168.2.142:6380@16380 master - 0 1711615226000 5 connected
d1c9201bd11c823892ee96096026690a1f370a95 192.168.2.142:6379@16379 master - 0 1711615223470 4 connected
baa6cf562a168832e3753b277a2c0743f7dec9fa 192.168.2.141:6379@16379 master - 0 1711615225473 3 connected
aca07ffcdef6c14aa9b8de89b6e2d91ad6328033 192.168.2.141:6380@16380 master - 0 1711615226476 2 connected
0d601f868bc3a6f8be7c5dfc0434cc2c2ccc5264 192.168.2.140:6379@16379 myself,master - 0 1711615222000 1 connected
d95662c7a6285bcab1acae439b74f848116fc85e 192.168.2.140:6380@16380 master - 0 1711615225000 0 connected
127.0.0.1:6379>
执行完上述命令后,通过节点之间的通信,每个节点都可以感知到所有其他节点。每个节点上执行的情况都一样,如下k8s-m2上的实例:
[root@k8s-m2 redis]# ./src/redis-cli -p 6379
127.0.0.1:6379> CLUSTER nodes
b6a15068b05cf65bb13be1975730e395f3047b2c 192.168.2.142:6380@16380 master - 0 1711615340404 5 connected
d95662c7a6285bcab1acae439b74f848116fc85e 192.168.2.140:6380@16380 master - 0 1711615339000 0 connected
baa6cf562a168832e3753b277a2c0743f7dec9fa 192.168.2.141:6379@16379 myself,master - 0 1711615340000 3 connected
0d601f868bc3a6f8be7c5dfc0434cc2c2ccc5264 192.168.2.140:6379@16379 master - 0 1711615339402 1 connected
d1c9201bd11c823892ee96096026690a1f370a95 192.168.2.142:6379@16379 master - 0 1711615339000 4 connected
aca07ffcdef6c14aa9b8de89b6e2d91ad6328033 192.168.2.141:6380@16380 master - 0 1711615341409 2 connected
127.0.0.1:6379>
分配槽
在Redis集群中,借助槽实现数据分区,具体原理后面介绍。集群总共有16384个槽,槽是数据管理和迁移的基本单位。注意重点:当数据库中的16384个槽都分配了节点时,集群处于上线状态(ok);如果有任意一个槽没有分配节点,则集群处于下线状态(fail)。
目前所有的节点还没有组成一个真正的集群,使用cluster info命令可以查看集群状态,分配槽之前状态为fail:
127.0.0.1:6379> CLUSTER INFO
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:3
......
分配槽使用cluster addslots命令,执行下面的命令将槽(编号0-16383)全部大致均分完毕。注意这个分槽只能通过如下方。如果先通过redis-cli登录后再使用如下格式进行分槽会报(error) ERR Invalid or out of range slot
[[root@k8s-m1 redis]# ./src/redis-cli -h 192.168.2.140 -p 6379 cluster addslots {0..5461}
OK
[root@k8s-m1 redis]# ./src/redis-cli -h 192.168.2.141 -p 6379 cluster addslots {5462..10922}
OK
[root@k8s-m1 redis]# ./src/redis-cli -h 192.168.2.142 -p 6379 cluster addslots {10923..16383}
OK[root@k8s-m1 redis]# ./src/redis-cli -h 192.168.2.140 -p 6379
192.168.2.140:6379> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_ping_sent:7006
cluster_stats_messages_pong_sent:11879
cluster_stats_messages_meet_sent:1
cluster_stats_messages_mfstart_sent:5
cluster_stats_messages_sent:18891
cluster_stats_messages_ping_received:11878
cluster_stats_messages_pong_received:7006
cluster_stats_messages_meet_received:1
cluster_stats_messages_update_received:4596
cluster_stats_messages_received:23481192.168.2.140:6379> CLUSTER NODES
aca07ffcdef6c14aa9b8de89b6e2d91ad6328033 192.168.2.141:6380@16380 master - 0 1711692666000 2 connected
d1c9201bd11c823892ee96096026690a1f370a95 192.168.2.142:6379@16379 master - 0 1711692667000 4 connected 10923-16383
b6a15068b05cf65bb13be1975730e395f3047b2c 192.168.2.142:6380@16380 master - 0 1711692668771 5 connected
d95662c7a6285bcab1acae439b74f848116fc85e 192.168.2.140:6380@16380 master - 0 1711692666000 0 connected
0d601f868bc3a6f8be7c5dfc0434cc2c2ccc5264 192.168.2.140:6379@16379 myself,master - 0 1711692666000 1 connected 0-5461
baa6cf562a168832e3753b277a2c0743f7dec9fa 192.168.2.141:6379@16379 master - 0 1711692667768 3 connected 5462-10922
此时再查看集群状态,显示所有槽分配完毕,集群进入上线状态。并且所有的槽大致均分在3个不同的redis实例上。
指定主从关系
集群中指定主从关系不再使用slaveof命令,而是使用cluster replicate命令;参数是使用主节点的id。先通过查看节点id,注意我们按规划的将端口号位6380的节点指定为从节点。注意命令后面的主节点的id,并且同一对主从不在同一台服务器上
[root@k8s-m1 redis]# ./src/redis-cli -h 192.168.2.141 -p 6380 cluster replicate 0d601f868bc3a6f8be7c5dfc0434cc2c2ccc5264
OK
[root@k8s-m1 redis]# ./src/redis-cli -h 192.168.2.142 -p 6380 cluster replicate baa6cf562a168832e3753b277a2c0743f7dec9fa
OK
[root@k8s-m1 redis]# ./src/redis-cli -h 192.168.2.140 -p 6380 cluster replicate d1c9201bd11c823892ee96096026690a1f370a95
OK
此时执行cluster nodes查看各个节点的状态,可以看到主从关系已经建立,如下:
192.168.2.140:6379> CLUSTER NODES
aca07ffcdef6c14aa9b8de89b6e2d91ad6328033 192.168.2.141:6380@16380 slave 0d601f868bc3a6f8be7c5dfc0434cc2c2ccc5264 0 1711693277158 1 connected
d1c9201bd11c823892ee96096026690a1f370a95 192.168.2.142:6379@16379 master - 0 1711693276156 4 connected 10923-16383
b6a15068b05cf65bb13be1975730e395f3047b2c 192.168.2.142:6380@16380 slave baa6cf562a168832e3753b277a2c0743f7dec9fa 0 1711693275148 3 connected
d95662c7a6285bcab1acae439b74f848116fc85e 192.168.2.140:6380@16380 slave d1c9201bd11c823892ee96096026690a1f370a95 0 1711693276000 4 connected
0d601f868bc3a6f8be7c5dfc0434cc2c2ccc5264 192.168.2.140:6379@16379 myself,master - 0 1711693276000 1 connected 0-5461
baa6cf562a168832e3753b277a2c0743f7dec9fa 192.168.2.141:6379@16379 master - 0 1711693274146 3 connected 5462-10922
直接使用命令搭建集群
redis-trib 工具在 Redis 5.0 版本中被移除。在之前的版本中,redis-trib 用于管理 Redis 集群,包括创建、扩展、合并和重新分片集群等操作。然而,由于一些设计上的限制和一些性能问题,Redis 开发团队决定在 5.0 版本中停止维护和移除 redis-trib 工具。
取而代之的是 redis-cli 中的 --cluster 选项,该选项提供了一组命令,使用户能够手动执行类似 redis-trib 的操作,例如将节点添加到集群、从集群中删除节点等。通过这些命令,用户可以更加灵活地管理 Redis 集群,并且可以更好地适应复杂的使用场景。
清零环境,并重新启动6个redis实例
注意所有节点都需要进行如下操作,结合自己的实际情况
# 关闭所有已启动的redis节点,使用kill命令杀掉相应进程即可
[root@k8s-m1 redis]# ps aux|grep redis
root 16964 0.0 0.0 112812 980 pts/1 S+ 14:43 0:00 grep --color=auto redis
root 18559 0.2 0.0 165432 3500 ? Ssl 10:09 0:34 ./src/redis-server *:6379 [cluster]
root 18646 0.2 0.0 165432 3648 ? Ssl 10:09 0:34 ./src/redis-server *:6380 [cluster]
[root@k8s-m1 redis]# kill -9 18559 18646
# 删除集群相关文件,删除每个节点下的dump.rdb和nodes.conf文件
[root@k8s-m1 redis]# rm -rf dump-1-6379.rdb dump-1-6380.rdb node1-6379.conf node1-6380.conf
# 启动所有Redis节点
[root@k8s-m1 redis]# ./src/redis-server redis-6379.conf
[root@k8s-m1 redis]# ./src/redis-server redis-6380.conf
[root@k8s-m1 redis]# ps aux|grep redis
root 20520 1.0 0.0 164920 3504 ? Ssl 14:46 0:00 ./src/redis-server *:6379 [cluster]
root 20602 0.0 0.0 164920 3496 ? Ssl 14:46 0:00 ./src/redis-server *:6380 [cluster]
root 20711 0.0 0.0 112812 980 pts/1 S+ 14:46 0:00 grep --color=auto redis
创建集群
使用redis-cli 直接创建。其中:–cluster表示创建集群;后面的多个{ip:port}表示节点地址,前面三个做主节点,后面三个做从节点;–replicas=1表示每个主节点有1个从节点;
执行创建命令后,脚本会给出创建集群的计划,如下所示;计划包括哪些是主节点,哪些是从节点,以及如何分配槽。输入yes确认执行计划,脚本便开始按照计划执行,如下所示。
[root@k8s-m1 redis]# ./src/redis-cli --cluster create 192.168.2.140:6379 192.168.2.141:6379 192.168.2.142:6379 192.168.2.140:6380 192.168.2.141:6380 192.168.2.142:6380 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.2.141:6380 to 192.168.2.140:6379
Adding replica 192.168.2.142:6380 to 192.168.2.141:6379
Adding replica 192.168.2.140:6380 to 192.168.2.142:6379
M: 096312e8b2e244412e1d9aaebd4beac589d0d6be 192.168.2.140:6379slots:[0-5460] (5461 slots) master
M: bd0976ea0f464ea4b94154b07ac970f85823e269 192.168.2.141:6379slots:[5461-10922] (5462 slots) master
M: 87de6b4208f584c0baebe593a036d23cf526ec31 192.168.2.142:6379slots:[10923-16383] (5461 slots) master
S: 7a869bcd7ff391f7b120f54f32bcebb5d4f63f8f 192.168.2.140:6380replicates 87de6b4208f584c0baebe593a036d23cf526ec31
S: 774f2100c19b80cb9427a59a61af2b54ebf127bd 192.168.2.141:6380replicates 096312e8b2e244412e1d9aaebd4beac589d0d6be
S: b521b39d17fb963ad424d49a3e956001c7b5fb54 192.168.2.142:6380replicates bd0976ea0f464ea4b94154b07ac970f85823e269
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.....
>>> Performing Cluster Check (using node 192.168.2.140:6379)
M: 096312e8b2e244412e1d9aaebd4beac589d0d6be 192.168.2.140:6379slots:[0-5460] (5461 slots) master1 additional replica(s)
M: 87de6b4208f584c0baebe593a036d23cf526ec31 192.168.2.142:6379slots:[10923-16383] (5461 slots) master1 additional replica(s)
M: bd0976ea0f464ea4b94154b07ac970f85823e269 192.168.2.141:6379slots:[5461-10922] (5462 slots) master1 additional replica(s)
S: 774f2100c19b80cb9427a59a61af2b54ebf127bd 192.168.2.141:6380slots: (0 slots) slavereplicates 096312e8b2e244412e1d9aaebd4beac589d0d6be
S: b521b39d17fb963ad424d49a3e956001c7b5fb54 192.168.2.142:6380slots: (0 slots) slavereplicates bd0976ea0f464ea4b94154b07ac970f85823e269
S: 7a869bcd7ff391f7b120f54f32bcebb5d4f63f8f 192.168.2.140:6380slots: (0 slots) slavereplicates 87de6b4208f584c0baebe593a036d23cf526ec31
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
至此,集群搭建完毕。
集群方案设计
设计集群方案时,至少要考虑以下因素:
(1)高可用要求:根据故障转移的原理,至少需要3个主节点才能完成故障转移,且3个主节点不应在同一台物理机上;每个主节点至少需要1个从节点,且主从节点不应在一台物理机上;因此高可用集群至少包含6个节点。
(2)数据量和访问量:估算应用需要的数据量和总访问量(考虑业务发展,留有冗余),结合每个主节点的容量和能承受的访问量(可以通过benchmark得到较准确估计),计算需要的主节点数量。
(3)节点数量限制:Redis官方给出的节点数量限制为1000,主要是考虑节点间通信带来的消耗。在实际应用中应尽量避免大集群;如果节点数量不足以满足应用对Redis数据量和访问量的要求,可以考虑:(1)业务分割,大集群分为多个小集群;(2)减少不必要的数据;(3)调整数据过期策略等。
(4)适度冗余:Redis可以在不影响集群服务的情况下增加节点,因此节点数量适当冗余即可,不用太大。
集群的基本原理
上面介绍了集群的搭建方法和设计方案,下面将进一步深入,介绍集群的原理。集群最核心的功能是数据分区,因此首先介绍数据的分区规则;然后介绍集群实现的细节:通信机制和数据结构;最后以cluster meet(节点握手)、cluster addslots(槽分配)为例,说明节点是如何利用上述数据结构和通信机制实现集群命令的。
数据分区方案
数据分区有顺序分区、哈希分区等,其中哈希分区由于其天然的随机性,使用广泛;集群的分区方案便是哈希分区的一种。
哈希分区的基本思路是:对数据的特征值(如key)进行哈希,然后根据哈希值决定数据落在哪个节点。常见的哈希分区包括:哈希取余分区、一致性哈希分区、带虚拟节点的一致性哈希分区等。
衡量数据分区方法好坏的标准有很多,其中比较重要的两个因素是(1)数据分布是否均匀(2)增加或删减节点对数据分布的影响。由于哈希的随机性,哈希分区基本可以保证数据分布均匀;因此在比较哈希分区方案时,重点要看增减节点对数据分布的影响。
(1)哈希取余分区
哈希取余分区思路非常简单:计算key的hash值,然后对节点数量进行取余,从而决定数据映射到哪个节点上。该方案最大的问题是,当新增或删减节点时,节点数量发生变化,系统中所有的数据都需要重新计算映射关系,引发大规模数据迁移。
(2)一致性哈希分区
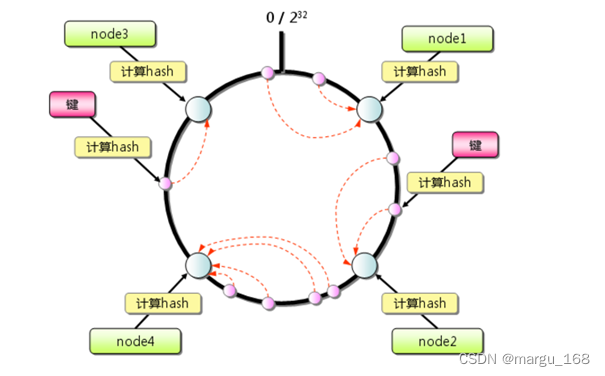
一致性哈希算法将整个哈希值空间组织成一个虚拟的圆环,如下图所示,范围为0-2^32-1;对于每个数据,根据key计算hash值,确定数据在环上的位置,然后从此位置沿环顺时针行走,找到的第一台服务器就是其应该映射到的服务器。
图片来源:https://www.cnblogs.com/lpfuture/p/5796398.html
与哈希取余分区相比,一致性哈希分区将增减节点的影响限制在相邻节点。以上图为例,如果在node1和node2之间增加node5,则只有node2中的一部分数据会迁移到node5;如果去掉node2,则原node2中的数据只会迁移到node4中,只有node4会受影响。
一致性哈希分区的主要问题在于,当节点数量较少时,增加或删减节点,对单个节点的影响可能很大,造成数据的严重不平衡。还是以上图为例,如果去掉node2,node4中的数据由总数据的1/4左右变为1/2左右,与其他节点相比负载过高。
(3)带虚拟节点的一致性哈希分区
该方案在一致性哈希分区的基础上,引入了虚拟节点的概念。Redis集群使用的便是该方案,其中的虚拟节点称为槽(slot)。槽是介于数据和实际节点之间的虚拟概念;每个实际节点包含一定数量的槽,每个槽包含哈希值在一定范围内的数据。引入槽以后,数据的映射关系由数据hash->实际节点,变成了数据hash->槽->实际节点。
在使用了槽的一致性哈希分区中,槽是数据管理和迁移的基本单位。槽解耦了数据和实际节点之间的关系,增加或删除节点对系统的影响很小。仍以上图为例,系统中有4个实际节点,假设为其分配16个槽(0-15); 槽0-3位于node1,4-7位于node2,以此类推。如果此时删除node2,只需要将槽4-7重新分配即可,例如槽4-5分配给node1,槽6分配给node3,槽7分配给node4;可以看出删除node2后,数据在其他节点的分布仍然较为均衡。
槽的数量一般远小于2^32,远大于实际节点的数量;在Redis集群中,槽的数量为16384。
下面这张图很好的总结了Redis集群将数据映射到实际节点的过程:
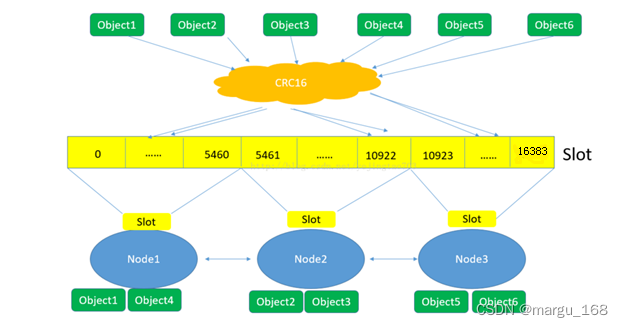
图片修改自:https://blog.csdn.net/yejingtao703/article/details/78484151
(1)Redis对数据的特征值(一般是key)计算哈希值,使用的算法是CRC16。
(2)根据哈希值,计算数据属于哪个槽。
(3)根据槽与节点的映射关系,计算数据属于哪个节点。
节点通信机制
集群要作为一个整体工作,离不开节点之间的通信。
两个端口
在哨兵系统中,节点分为数据节点和哨兵节点:前者存储数据,后者实现额外的控制功能。在集群中,没有数据节点与非数据节点之分:所有的节点都存储数据,也都参与集群状态的维护。为此,集群中的每个节点,都提供了两个TCP端口:
普通端口:如我们在前面指定的端口(6379、6380等)。普通端口主要用于为客户端提供服务(与单机节点类似);但在节点间数据迁移时也会使用。
集群端口:端口号是普通端口+10000(10000是固定值,无法改变),如6379节点的集群端口为16379。集群端口只用于节点之间的通信,如搭建集群、增减节点、故障转移等操作时节点间的通信;不要使用客户端连接集群接口。为了保证集群可以正常工作,在配置防火墙时,要同时开启普通端口和集群端口。
Gossip协议
节点间通信,按照通信协议可以分为几种类型:单对单、广播、Gossip协议等。重点是广播和Gossip的对比。
广播是指向集群内所有节点发送消息;优点是集群的收敛速度快(集群收敛是指集群内所有节点获得的集群信息是一致的),缺点是每条消息都要发送给所有节点,CPU、带宽等消耗较大。
Gossip协议的特点是:在节点数量有限的网络中,每个节点都“随机”的与部分节点通信(并不是真正的随机,而是根据特定的规则选择通信的节点),经过一番杂乱无章的通信,每个节点的状态很快会达到一致。Gossip协议的优点有负载(比广播)低、去中心化、容错性高(因为通信有冗余)等;缺点主要是集群的收敛速度慢。
消息类型
集群中的节点采用固定频率(每秒10次)的定时任务进行通信相关的工作:判断是否需要发送消息及消息类型、确定接收节点、发送消息等。如果集群状态发生了变化,如增减节点、槽状态变更,通过节点间的通信,所有节点会很快得知整个集群的状态,使集群收敛。
节点间发送的消息主要分为5种:meet消息、ping消息、pong消息、fail消息、publish消息。不同的消息类型,通信协议、发送的频率和时机、接收节点的选择等是不同的。
MEET消息:在节点握手阶段,当节点收到客户端的CLUSTER MEET命令时,会向新加入的节点发送MEET消息,请求新节点加入到当前集群;新节点收到MEET消息后会回复一个PONG消息。
PING消息:集群里每个节点每秒钟会选择部分节点发送PING消息,接收者收到消息后会回复一个PONG消息。PING消息的内容是自身节点和部分其他节点的状态信息;作用是彼此交换信息,以及检测节点是否在线。PING消息使用Gossip协议发送,接收节点的选择兼顾了收敛速度和带宽成本,具体规则如下:(1)随机找5个节点,在其中选择最久没有通信的1个节点(2)扫描节点列表,选择最近一次收到PONG消息时间大于cluster_node_timeout/2的所有节点,防止这些节点长时间未更新。
PONG消息:PONG消息封装了自身状态数据。可以分为两种:第一种是在接到MEET/PING消息后回复的PONG消息;第二种是指节点向集群广播PONG消息,这样其他节点可以获知该节点的最新信息,例如故障恢复后新的主节点会广播PONG消息。
FAIL消息:当一个主节点判断另一个主节点进入FAIL状态时,会向集群广播这一FAIL消息;接收节点会将这一FAIL消息保存起来,便于后续的判断。
PUBLISH消息:节点收到PUBLISH命令后,会先执行该命令,然后向集群广播这一消息,接收节点也会执行该PUBLISH命令。
数据结构
节点需要专门的数据结构来存储集群的状态。所谓集群的状态,是一个比较大的概念,包括:集群是否处于上线状态、集群中有哪些节点、节点是否可达、节点的主从状态、槽的分布……
节点为了存储集群状态而提供的数据结构中,最关键的是clusterNode和clusterState结构:前者记录了一个节点的状态,后者记录了集群作为一个整体的状态。
clusterNode
clusterNode结构保存了一个节点的当前状态,包括创建时间、节点id、ip和端口号等。每个节点都会用一个clusterNode结构记录自己的状态,并为集群内所有其他节点都创建一个clusterNode结构来记录节点状态。
下面列举了clusterNode的部分字段,并说明了字段的含义和作用:
typedef struct clusterNode {//节点创建时间mstime_t ctime;//节点idchar name[REDIS_CLUSTER_NAMELEN];//节点的ip和端口号char ip[REDIS_IP_STR_LEN];int port;//节点标识:整型,每个bit都代表了不同状态,如节点的主从状态、是否在线、是否在握手等int flags;//配置纪元:故障转移时起作用,类似于哨兵的配置纪元uint64_t configEpoch;//槽在该节点中的分布:占用16384/8个字节,16384个比特;每个比特对应一个槽:比特值为1,则该比特对应的槽在节点中;比特值为0,则该比特对应的槽不在节点中unsigned char slots[16384/8];//节点中槽的数量int numslots;…………} clusterNode;
除了上述字段,clusterNode还包含节点连接、主从复制、故障发现和转移需要的信息等。
clusterState
clusterState结构保存了在当前节点视角下,集群所处的状态。主要字段包括:
typedef struct clusterState {//自身节点clusterNode *myself;//配置纪元uint64_t currentEpoch;//集群状态:在线还是下线int state;//集群中至少包含一个槽的节点数量int size;//哈希表,节点名称->clusterNode节点指针dict *nodes;//槽分布信息:数组的每个元素都是一个指向clusterNode结构的指针;如果槽还没有分配给任何节点,则为NULLclusterNode *slots[16384];…………} clusterState;
除此之外,clusterState还包括故障转移、槽迁移等需要的信息。
集群命令的实现
这一部分将以cluster meet(节点握手)、cluster addslots(槽分配)为例,说明节点是如何利用上述数据结构和通信机制实现集群命令的。
cluster meet
假设要向A节点发送cluster meet命令,将B节点加入到A所在的集群,则A节点收到命令后,执行的操作如下:
-
A为B创建一个clusterNode结构,并将其添加到clusterState的nodes字典中
-
A向B发送MEET消息
-
B收到MEET消息后,会为A创建一个clusterNode结构,并将其添加到clusterState的nodes字典中
-
B回复A一个PONG消息
-
A收到B的PONG消息后,便知道B已经成功接收自己的MEET消息
-
然后,A向B返回一个PING消息
-
B收到A的PING消息后,便知道A已经成功接收自己的PONG消息,握手完成
-
之后,A通过Gossip协议将B的信息广播给集群内其他节点,其他节点也会与B握手;一段时间后,集群收敛,B成为集群内的一个普通节点
通过上述过程可以发现,集群中两个节点的握手过程与TCP类似,都是三次握手:A向B发送MEET;B向A发送PONG;A向B发送PING。
cluster addslots
集群中槽的分配信息,存储在clusterNode的slots数组和clusterState的slots数组中,两个数组的结构前面已做介绍;二者的区别在于:前者存储的是该节点中分配了哪些槽,后者存储的是集群中所有槽分别分布在哪个节点。
cluster addslots命令接收一个槽或多个槽作为参数,例如在A节点上执行cluster addslots {0…10}命令,是将编号为0-10的槽分配给A节点,具体执行过程如下:
-
遍历输入槽,检查它们是否都没有分配,如果有一个槽已分配,命令执行失败;方法是检查输入槽在clusterState.slots[]中对应的值是否为NULL。
-
遍历输入槽,将其分配给节点A;方法是修改clusterNode.slots[]中对应的比特为1,以及clusterState.slots[]中对应的指针指向A节点
-
A节点执行完成后,通过节点通信机制通知其他节点,所有节点都会知道0-10的槽分配给了A节点
客户端访问集群
在集群中,数据分布在不同的节点中,客户端通过某节点访问数据时,数据可能不在该节点中;下面介绍集群是如何处理这个问题的。
redis-cli
当节点收到redis-cli发来的命令(如set/get)时,过程如下:
(1)计算key属于哪个槽:CRC16(key) & 16383
集群提供的cluster keyslot命令也是使用上述公式实现,如:
127.0.0.1:6379> CLUSTER KEYSLOT a
(integer) 15495
127.0.0.1:6379>
(2)判断key所在的槽是否在当前节点:假设key位于第i个槽,clusterState.slots[i]则指向了槽所在的节点,如果clusterState.slots[i]==clusterState.myself,说明槽在当前节点,可以直接在当前节点执行命令;否则,说明槽不在当前节点,则查询槽所在节点的地址(clusterState.slots[i].ip/port),并将其包装到MOVED错误中返回给redis-cli。
(3)redis-cli收到MOVED错误后,根据返回的ip和port重新发送请求。
下面的例子展示了redis-cli和集群的互动过程:如上,a这个key所分配的槽是15495,应该是在192.168.2.142:6379 这个节点,如果在其他节点上操作,会返回MOVED错误(包含正确的ip和port 192.168.2.142:6379)给redis-cli,redis-cli 再(redirect)向正确的重新发起请求,如下。
[root@k8s-m1 redis]# ./src/redis-cli -c
127.0.0.1:6379> set a 1
-> Redirected to slot [15495] located at 192.168.2.142:6379
OK
192.168.2.142:6379>
上例中,redis-cli通过-c指定了集群模式,如果没有指定,redis-cli无法处理MOVED错误:
[root@k8s-m1 redis]# ./src/redis-cli -h 192.168.2.140
192.168.2.140:6379> set a 1
(error) MOVED 15495 192.168.2.142:6379
smart客户端
redis-cli这一类客户端称为Dummy(笨蛋) 客户端,因为它们在执行命令前不知道数据在哪个节点,需要借助MOVED错误重新定向。与Dummy客户端相对应的是Smart(聪明) 客户端。
Smart客户端(以Java的JedisCluster为例)的基本原理:
(1)JedisCluster初始化时,在内部维护slot->node的缓存,方法是连接任一节点,执行cluster slots命令,该命令返回如下所示:
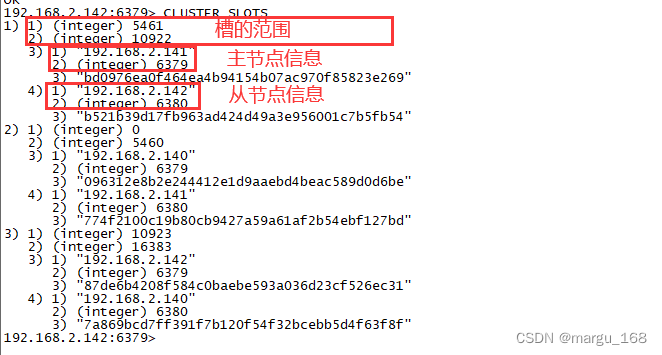
(2)此外,JedisCluster为每个节点创建连接池(即JedisPool)。
(3)当执行命令时,JedisCluster根据key->slot->node选择需要连接的节点,发送命令。如果成功,则命令执行完毕。如果执行失败,则会随机选择其他节点进行重试,并在出现MOVED错误时,使用cluster slots重新同步slot->node的映射关系。
下面代码演示了如何使用JedisCluster访问集群(未考虑资源释放、异常处理等):
public static void test() {Set<HostAndPort> nodes = new HashSet<>();nodes.add(new HostAndPort("192.168.2.140", 6379));nodes.add(new HostAndPort("192.168.2.141", 6379));nodes.add(new HostAndPort("192.168.2.142", 6379));nodes.add(new HostAndPort("192.168.2.140", 6380));nodes.add(new HostAndPort("192.168.2.141", 6380));nodes.add(new HostAndPort("192.168.2.142", 6380));JedisCluster cluster = new JedisCluster(nodes);System.out.println(cluster.get("a"));cluster.close();
}
注意事项如下:
(1)JedisCluster中已经包含所有节点的连接池,因此JedisCluster要使用单例。
(2)客户端维护了slot->node映射关系以及为每个节点创建了连接池,当节点数量较多时,应注意客户端内存资源和连接资源的消耗。
(3)Jedis较新版本针对JedisCluster做了一些性能方面的优化,如cluster slots缓存更新和锁阻塞等方面的优化,应尽量使用2.8.2及以上版本的Jedis。
实践须知
前面介绍了集群正常运行和访问的方法和原理,下面是一些重要的补充内容。
集群伸缩
实践中常常需要对集群进行伸缩,如访问量增大时的扩容操作。Redis集群可以在不影响对外服务的情况下实现伸缩;伸缩的核心是槽迁移:修改槽与节点的对应关系,实现槽(即数据)在节点之间的移动。例如,如果槽均匀分布在集群的3个节点中,此时增加一个节点,则需要从3个节点中分别拿出一部分槽给新节点,从而实现槽在4个节点中的均匀分布。
增加节点
测试环境有限,此处我在192.168.2.141这个节点上运行了两个示例,端口分别为6381和6382,其中规划6382 是6381的从节点;步骤如下:
(1)启动节点:方法参见集群搭建,我此处直接在192.168.2.141这个节点上运行了两个示例。
[root@k8s-m2 redis]# ps aux|grep redis
polkitd 9230 0.1 0.0 37188 2256 ? Ssl Mar28 7:13 redis-server *:6379
root 28852 0.2 0.0 162584 3292 ? Ssl 14:28 0:00 ./src/redis-server *:6381 [cluster]
root 28902 1.0 0.0 162584 3296 ? Ssl 14:28 0:00 ./src/redis-server *:6382 [cluster]
root 28918 0.0 0.0 112816 972 pts/1 S+ 14:28 0:00 grep --color=auto redis
root 30335 0.1 0.0 165144 3628 ? Ssl Mar29 7:48 ./src/redis-server *:6379 [cluster]
root 30423 0.1 0.0 165144 3496 ? Ssl Mar29 7:46 ./src/redis-server *:6380 [cluster]
(2)节点握手:可以使用cluster meet命令,此处直接使用redis-cli + add-node 来添加,其原理也是cluster meet,但它会先检查新节点是否已加入其它集群或者存在数据,避免加入到集群后带来混乱。注意格式前面的IP是新的实例IP+端口,后面是原来集群中的一个实例IP+端口
[root@k8s-m1 redis]# ./src/redis-cli --cluster add-node 192.168.2.141:6381 192.168.2.141:6380
(3)迁移槽:推荐使用redis-cli的reshard工具实现。reshard自动化程度很高,只需要输入redis-cli --cluster reshard ip:port (ip和port可以是集群中的任一节点),然后按照提示输入以下信息,槽迁移会自动完成:
[root@k8s-m1 redis]# ./src/redis-cli --cluster reshard 192.168.2.140:6379
待迁移的槽数量:16384个槽均分给4个节点,每个节点4096个槽,因此待迁移槽数量为4096
目标节点id:192.168.2.141:6381节点的id
源节点的id:此处直接选择的all
(4)指定主从关系:方法参见集群搭建
# 先将新的实例添加进集群
[root@k8s-m1 redis]# ./src/redis-cli --cluster add-node 192.168.2.141:6382 192.168.2.141:6380
# 登录后面添加的实例并指定它的主节点
[root@k8s-m1 redis]# ./src/redis-cli -h 192.168.2.141 -p 6382
192.168.2.141:6382> CLUSTER REPLICATE 7af7126ba36ce7dcaf7e020e8fa0f077d6f0a8ad
Ok
192.168.2.141:6382> CLUSTER NODES
7a869bcd7ff391f7b120f54f32bcebb5d4f63f8f 192.168.2.140:6380@16380 slave 87de6b4208f584c0baebe593a036d23cf526ec31 0 1711958413000 11 connected
774f2100c19b80cb9427a59a61af2b54ebf127bd 192.168.2.141:6380@16380 slave 096312e8b2e244412e1d9aaebd4beac589d0d6be 0 1711958409000 9 connected
c23a35c15e1c0d5b4417950967b156360fb9ab3d 192.168.2.141:6382@16382 myself,slave 7af7126ba36ce7dcaf7e020e8fa0f077d6f0a8ad 0 1711958411000 12 connected
87de6b4208f584c0baebe593a036d23cf526ec31 192.168.2.142:6379@16379 master - 0 1711958411193 11 connected 12288-16383
b521b39d17fb963ad424d49a3e956001c7b5fb54 192.168.2.142:6380@16380 slave bd0976ea0f464ea4b94154b07ac970f85823e269 0 1711958414205 10 connected
7af7126ba36ce7dcaf7e020e8fa0f077d6f0a8ad 192.168.2.141:6381@16381 master - 0 1711958412000 12 connected 0-1364 5461-6826 10923-12287
bd0976ea0f464ea4b94154b07ac970f85823e269 192.168.2.141:6379@16379 master - 0 1711958412000 10 connected 6827-10922
096312e8b2e244412e1d9aaebd4beac589d0d6be 192.168.2.140:6379@16379 master - 0 1711958413200 9 connected 1365-5460
减少节点
假设要下线6381/6382节点,可以分为两步:
(1)迁移槽:使用reshard将6381节点中的槽均匀迁移到之前的三个主节点。应该需要多次迁移,因为接收slots的node ID单次只能指定一个。细看一下很好理解,要输入接收和源 实例的id,确定好后输入done,然后yes执行即可。
[root@k8s-m1 redis]# ./src/redis-cli --cluster reshard 192.168.2.140:6379
>>> Performing Cluster Check (using node 192.168.2.140:6379)
M: 096312e8b2e244412e1d9aaebd4beac589d0d6be 192.168.2.140:6379slots:[0-5460] (5461 slots) master1 additional replica(s)
M: 87de6b4208f584c0baebe593a036d23cf526ec31 192.168.2.142:6379slots:[12288-16383] (4096 slots) master1 additional replica(s)
S: c23a35c15e1c0d5b4417950967b156360fb9ab3d 192.168.2.141:6382slots: (0 slots) slavereplicates 7af7126ba36ce7dcaf7e020e8fa0f077d6f0a8ad
M: bd0976ea0f464ea4b94154b07ac970f85823e269 192.168.2.141:6379slots:[6827-10922] (4096 slots) master1 additional replica(s)
S: 774f2100c19b80cb9427a59a61af2b54ebf127bd 192.168.2.141:6380slots: (0 slots) slavereplicates 096312e8b2e244412e1d9aaebd4beac589d0d6be
S: b521b39d17fb963ad424d49a3e956001c7b5fb54 192.168.2.142:6380slots: (0 slots) slavereplicates bd0976ea0f464ea4b94154b07ac970f85823e269
M: 7af7126ba36ce7dcaf7e020e8fa0f077d6f0a8ad 192.168.2.141:6381slots:[0-1365],[5461-6826],[10923-12287] (2731 slots) master1 additional replica(s)
S: 7a869bcd7ff391f7b120f54f32bcebb5d4f63f8f 192.168.2.140:6380slots: (0 slots) slavereplicates 87de6b4208f584c0baebe593a036d23cf526ec31
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1365
What is the receiving node ID? 096312e8b2e244412e1d9aaebd4beac589d0d6be
Please enter all the source node IDs.Type 'all' to use all the nodes as source nodes for the hash slots.Type 'done' once you entered all the source nodes IDs.
Source node #1: 7af7126ba36ce7dcaf7e020e8fa0f077d6f0a8ad
Source node #2: done
(2)下线节点:使用redis-cli + del-node工具;应先下线从节点再下线主节点,因为若主节点先下线,从节点会被指向其他主节点,造成不必要的全量复制。按上面将要删除的节点上的槽移除后,先确认槽移除完毕。
[root@k8s-m1 redis]# ./src/redis-cli cluster nodes
87de6b4208f584c0baebe593a036d23cf526ec31 192.168.2.142:6379@16379 master - 0 1711959268452 15 connected 6826 10923-16383
096312e8b2e244412e1d9aaebd4beac589d0d6be 192.168.2.140:6379@16379 myself,master - 0 1711959263000 13 connected 1365-6825
c23a35c15e1c0d5b4417950967b156360fb9ab3d 192.168.2.141:6382@16382 slave 87de6b4208f584c0baebe593a036d23cf526ec31 0 1711959267000 15 connected
bd0976ea0f464ea4b94154b07ac970f85823e269 192.168.2.141:6379@16379 master - 0 1711959268000 14 connected 0-1364 6827-10922
774f2100c19b80cb9427a59a61af2b54ebf127bd 192.168.2.141:6380@16380 slave 096312e8b2e244412e1d9aaebd4beac589d0d6be 0 1711959266000 13 connected
b521b39d17fb963ad424d49a3e956001c7b5fb54 192.168.2.142:6380@16380 slave bd0976ea0f464ea4b94154b07ac970f85823e269 0 1711959266445 14 connected
7af7126ba36ce7dcaf7e020e8fa0f077d6f0a8ad 192.168.2.141:6381@16381 master - 0 1711959267000 12 connected
7a869bcd7ff391f7b120f54f32bcebb5d4f63f8f 192.168.2.140:6380@16380 slave 87de6b4208f584c0baebe593a036d23cf526ec31 0 1711959267448 15 connected
然后执行删除命令。注意前面是原有集群的任意实例IP+端口,后面的是要删除的实例id。
[root@k8s-m1 redis]# ./src/redis-cli --cluster del-node 192.168.2.142:6379 c23a35c15e1c0d5b4417950967b156360fb9ab3d
>>> Removing node c23a35c15e1c0d5b4417950967b156360fb9ab3d from cluster 192.168.2.142:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.[root@k8s-m1 redis]# ./src/redis-cli --cluster del-node 192.168.2.142:6379 7af7126ba36ce7dcaf7e020e8fa0f077d6f0a8ad
>>> Removing node 7af7126ba36ce7dcaf7e020e8fa0f077d6f0a8ad from cluster 192.168.2.142:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
#检查确认集群中已经删除相应节点
[root@k8s-m1 redis]# ./src/redis-cli cluster nodes
87de6b4208f584c0baebe593a036d23cf526ec31 192.168.2.142:6379@16379 master - 0 1711959608265 15 connected 6826 10923-16383
096312e8b2e244412e1d9aaebd4beac589d0d6be 192.168.2.140:6379@16379 myself,master - 0 1711959607000 13 connected 1365-6825
bd0976ea0f464ea4b94154b07ac970f85823e269 192.168.2.141:6379@16379 master - 0 1711959606258 14 connected 0-1364 6827-10922
774f2100c19b80cb9427a59a61af2b54ebf127bd 192.168.2.141:6380@16380 slave 096312e8b2e244412e1d9aaebd4beac589d0d6be 0 1711959605256 13 connected
b521b39d17fb963ad424d49a3e956001c7b5fb54 192.168.2.142:6380@16380 slave bd0976ea0f464ea4b94154b07ac970f85823e269 0 1711959606000 14 connected
7a869bcd7ff391f7b120f54f32bcebb5d4f63f8f 192.168.2.140:6380@16380 slave 87de6b4208f584c0baebe593a036d23cf526ec31 0 1711959607261 15 connected
ASK错误
集群伸缩的核心是槽迁移。在槽迁移过程中,如果客户端向源节点发送命令,源节点执行流程如下:
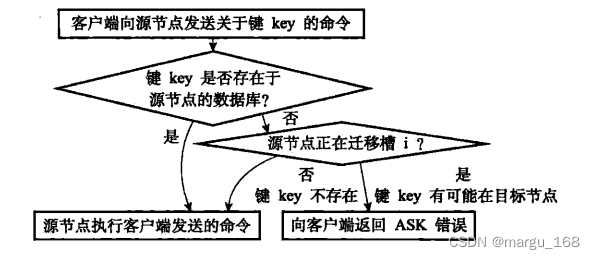
图片来源:《Redis设计与实现》
客户端收到ASK错误后,从中读取目标节点的地址信息,并向目标节点重新发送请求,就像收到MOVED错误时一样。但是二者有很大区别:ASK错误说明数据正在迁移,不知道何时迁移完成,因此重定向是临时的,SMART客户端不会刷新slots缓存;MOVED错误重定向则是(相对)永久的,SMART客户端会刷新slots缓存。
故障转移
在前面哨兵模式的文章中介绍了哨兵实现故障发现和故障转移的原理。虽然细节上有很大不同,但集群的实现与哨兵思路类似:通过定时任务发送PING消息检测其他节点状态;节点下线分为主观下线和客观下线;客观下线后选取从节点进行故障转移。
与哨兵一样,集群只实现了主节点的故障转移;而如果从节点故障时只会被下线,不会进行故障转移。因此,使用集群时,应谨慎使用读写分离技术,因为从节点故障会导致读服务不可用,可用性变差。
节点数量:在故障转移阶段,需要由主节点投票选出哪个从节点成为新的主节点;从节点选举胜出需要的票数为N/2+1;其中N为主节点数量(包括故障主节点),但故障主节点实际上不能投票。因此为了能够在故障发生时顺利选出从节点,集群中至少需要3个主节点(且部署在不同的物理机上)。
故障转移时间:从主节点故障发生到完成转移,所需要的时间主要消耗在主观下线识别、主观下线传播、选举延迟等几个环节;具体时间与参数cluster-node-timeout有关,一般来说:
故障转移时间(毫秒) ≤ 1.5 * cluster-node-timeout + 1000
cluster-node-timeout的默认值为15000ms(15s),因此故障转移时间会在20s量级。
集群的限制及应对方法
由于集群中的数据分布在不同节点中,导致一些功能受限,包括:
(1)key批量操作受限:例如mget、mset操作,只有当操作的key都位于一个槽时,才能进行。针对该问题,一种思路是在客户端记录槽与key的信息,每次针对特定槽执行mget/mset;另外一种思路是使用Hash Tag,将在下一小节介绍。
(2)keys/flushall等操作:keys/flushall等操作可以在任一节点执行,但是结果只针对当前节点,例如keys操作只返回当前节点的所有键。针对该问题,可以在客户端使用cluster nodes获取所有节点信息,并对其中的所有主节点执行keys/flushall等操作。
(3)事务/Lua脚本:集群支持事务及Lua脚本,但前提条件是所涉及的key必须在同一个节点。Hash Tag可以解决该问题。
(4)数据库:单机Redis节点可以支持16个数据库,集群模式下只支持一个,即db0。
(5)复制结构:只支持一层复制结构,不支持嵌套。
Hash Tag
Hash Tag原理是:当一个key包含 {} 的时候,不对整个key做hash,而仅对 {} 包括的字符串做hash。
Hash Tag可以让不同的key拥有相同的hash值,从而分配在同一个槽里;这样针对不同key的批量操作(mget/mset等),以及事务、Lua脚本等都可以支持。不过Hash Tag可能会带来数据分配不均的问题,这时需要:(1)调整不同节点中槽的数量,使数据分布尽量均匀;(2)避免对热点数据使用Hash Tag,导致请求分布不均。
下面是使用Hash Tag的一个例子;通过对product加Hash Tag,可以将所有产品信息放到同一个槽中,便于操作。
127.0.0.1:6379> CLUSTER KEYSLOT a1
(integer) 7785
127.0.0.1:6379> CLUSTER KEYSLOT a2
(integer) 11786
127.0.0.1:6379> CLUSTER KEYSLOT a3
(integer) 15915
127.0.0.1:6379> CLUSTER KEYSLOT {a}1
(integer) 15495
127.0.0.1:6379> CLUSTER KEYSLOT {a}2
(integer) 15495
127.0.0.1:6379> CLUSTER KEYSLOT {a}3
(integer) 15495
127.0.0.1:6379>
观察到效果了么,效果就是后面的几个key的hash值是一样的,表明它们在同一个槽中。
参数优化
cluster_node_timeout
cluster_node_timeout参数在前面已经初步介绍;它的默认值是15s,影响包括:
(1)影响PING消息接收节点的选择:值越大对延迟容忍度越高,选择的接收节点越少,可以降低带宽,但会降低收敛速度;应根据带宽情况和应用要求进行调整。
(2)影响故障转移的判定和时间:值越大,越不容易误判,但完成转移消耗时间越长;应根据网络状况和应用要求进行调整。
cluster-require-full-coverage
前面提到,只有当16384个槽全部分配完毕时,集群才能上线。这样做是为了保证集群的完整性,但同时也带来了新的问题:当主节点发生故障而故障转移尚未完成,原主节点中的槽不在任何节点中,此时会集群处于下线状态,无法响应客户端的请求。
cluster-require-full-coverage参数可以改变这一设定:如果设置为no,则当槽没有完全分配时,集群仍可以上线。参数默认值为yes,如果应用对可用性要求较高,可以修改为no,但需要自己保证槽全部分配。
redis-cli --cluster
redis-cli --cluster 提供了众多实用工具:创建集群、增减节点、槽迁移、检查完整性、数据重新平衡等;通过help命令可以查看详细信息。在实践中如果能使用redis-cli --cluster 工具则尽量使用,不但方便快捷,还可以大大降低出错概率。
补充一些有用的命令
# 后面接需要修复的节点
[root@k8s-m1 redis]# ./src/redis-cli --cluster fix 192.168.2.142:6379
#检查集群完整性
[root@k8s-m1 redis]# ./src/redis-cli --cluster check 192.168.2.142:6379
# 检查集群是否需要重新平衡
[root@k8s-m1 redis]# ./src/redis-cli --cluster rebalance 192.168.2.142:6379
# 后续慢慢补充完善
redis集群性能测试
Redis 提供了一个内置的性能测试工具,用于评估 Redis 服务器的性能。该工具名为 redis-benchmark,可以模拟多个客户端并发地向 Redis 服务器发送命令,以测量服务器的性能指标,例如每秒执行的操作数(QPS)、响应时间等。支持以下选项:
-h host:指定 Redis 服务器的主机名或 IP 地址,默认为127.0.0.1。-p port:指定 Redis 服务器的端口号,默认为6379。-c connections:指定并发连接数(客户端数量),默认为50。-n requests:指定每个客户端发送的请求数,默认为100000。-t tests:指定测试用例的名称,例如get,set。-d datasize:指定数据大小,以字节为单位,默认为2。-r range:指定数据范围,例如100-200表示数据值的范围在 100 到 200 之间。
示例:
[root@k8s-m1 redis]# ./src/redis-benchmark -h 127.0.0.1 -p 6379 -t set,lpush -n 10000 -q -c 100
SET: 44642.86 requests per second
LPUSH: 46082.95 requests per second
可以看到目前我的集群性能还是不错的。
更多关于redis的知识分享,请前往博客主页。编写过程中,难免出现差错,敬请指出




![【洛谷 P8700】[蓝桥杯 2019 国 B] 解谜游戏 题解(字符串+映射+周期性)](http://pic.xiahunao.cn/【洛谷 P8700】[蓝桥杯 2019 国 B] 解谜游戏 题解(字符串+映射+周期性))





)
|附结构图)

:2024.03.25-2024.03.31)



(1))
)
