langchain框架目前以python或javascript包的形式提供,具体来说是TypeScript。
假如你想从你自己的数据、你自己的文件中具体了解一些情况,它可以是一本书,一个pdf文件,一个包含专有信息的数据库。Langchain允许你将GPT-4这样的大型语言模型与你自己的数据源连接起来。

把你像让你的语言模型参考的文件,先切成小块,再把这些小块存储再一个矢量数据库中。这些块被存储为嵌入,意味着它们是文本的矢量表示。
用户提出了一个初始问题,然后这个问题被发送到语言模型,该问题的向量表示被用来在向量数据库(叫矢量数据库也可以)中做相似性搜索(Similarity Search )。
现在,语言模型同时拥有初始问题和来自矢量数据库的相关信息(Question+Relevant Info),因此能够提供一个答案或采取一个行动(action)。
LangChain有助于建立遵循这样一个管道的应用程序,而这些应用都是有数据意识的,我们可以在一个矢量存储中引用我们自己的数据,而且它们是代理性的。
其实可以将大语言模型连接到现有的公司数据,如客户数据、营销数据等。
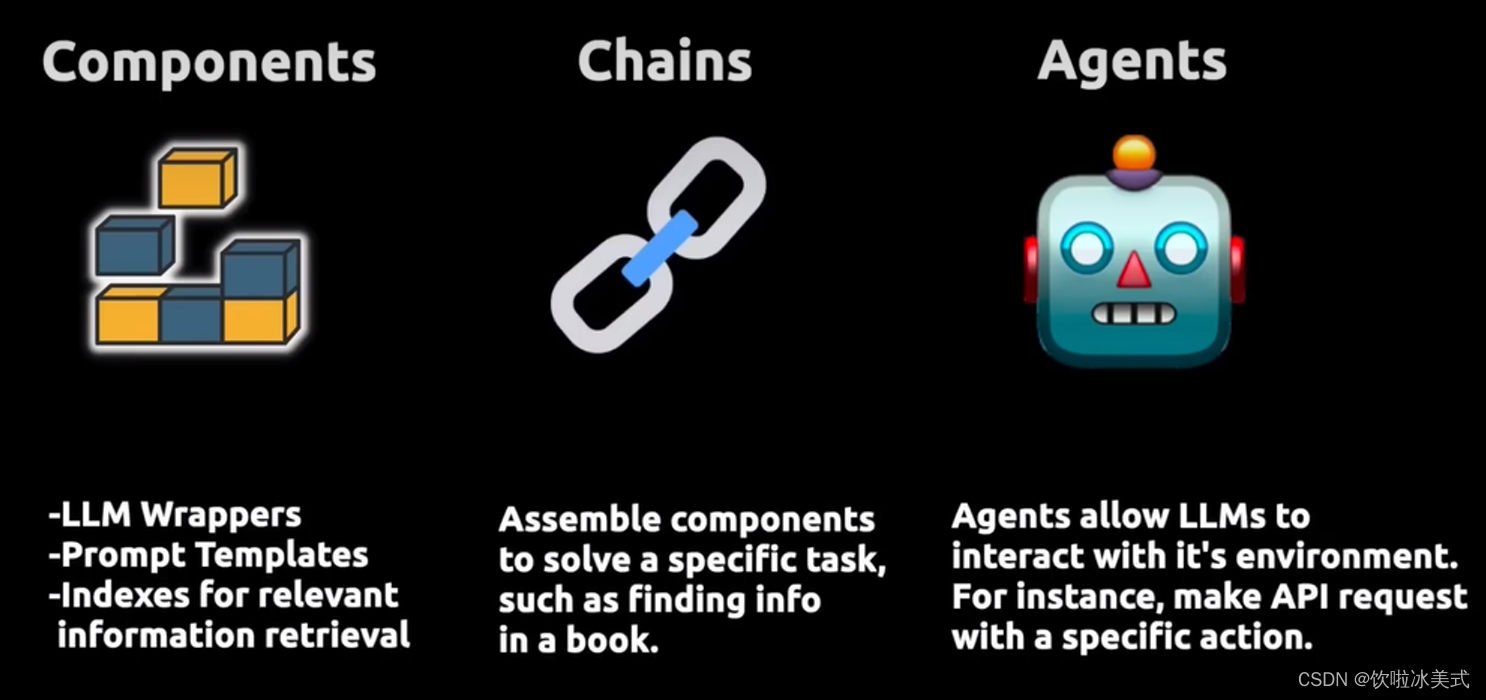
因此,LangChain的主要价值主张可以分为三个主要概念。
我们有LLM包装器,允许我们连接到大语言模型,如GPT-4或HuggingFace的模型。提示模板(prompt)使我们不必对文本进行硬编码,而文本是LLM的输入。然后我们有了索引(index),允许我们为LLm提供相关信息。
该链允许我们将多个组件组合在一起,以解决一个特定的任务,并建立一个完整的LLM应用程序。
最后我们还有允许LLM与外部API互动的代理。
详细步骤
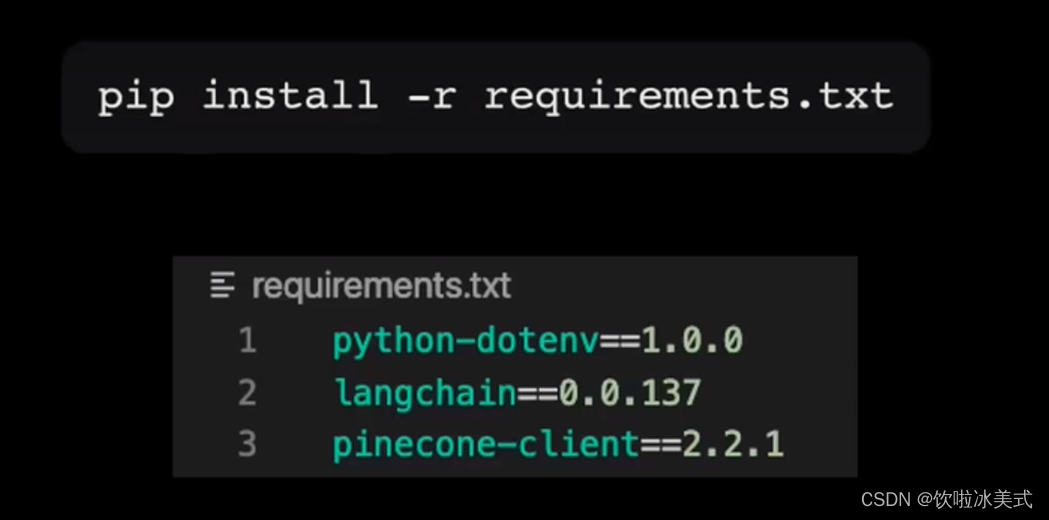
我们要做的第一件事是,我们用管道安装三个库。
Pinecone是我们要使用的矢量商店

新建后缀为.env的环境文件,内容为pinecone(矢量存储)和openai的KPI密钥和pinecone的环境。
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())# 输出为True则为成功find_dotenv()函数用于查找环境变量文件。它会在当前工作目录及其父目录中查找名为.env的文件,然后返回找到的第一个文件的路径。.env文件通常包含了各种环境变量的定义。load_dotenv()函数用于加载环境变量文件中的变量到当前环境中,以供Python程序使用。
ok,接着咱一步步来,在同一个py文件里
from langchain.schema import (AIMessage,HumanMessage,SystemMessage
)
from langchain.chat_models import ChatOpenAIchat = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.3)
messages = [SystemMessage(content="You are an expert data scientist"),HumanMessage(content="Write a Python script that trains a neural network on simulated data")
]response = chat(messages)
print(response.content, end="\n")为了通过LangChain与聊天模型互动,导入一个由三部分组成的schema。一个人工智能信息,一个人类信息和一个系统信息。
系统信息是在使用模型时用来配置系统的。人类信息是用户信息。
要使用聊天模型,要将系统信息和人类信息结合在一个列表list中,然后将其作为聊天模型的输入。这里我们使用GPT3.5 Turbo
输出结果为:
Sure! Here's an example of a Python script that trains a neural network on simulated data using the Keras library:```python
import numpy as np
from keras.models import Sequential
from keras.layers import Dense# Generate simulated data
np.random.seed(0)
X = np.random.rand(100, 2)
y = np.random.randint(2, size=100)# Define the neural network model
model = Sequential()
model.add(Dense(10, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))# Compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])# Train the model
model.fit(X, y, epochs=10, batch_size=10)# Evaluate the model
loss, accuracy = model.evaluate(X, y)
print(f"Loss: {loss}, Accuracy: {accuracy}")
```In this script, we first generate simulated data using `np.random.rand()` and `np.random.randint()`. The input data `X` is a 2-dimensional array of random numbers between 0 and 1, and the target labels `y` are binary values (0 or 1).We then define a neural network model using the `Sequential` class from Keras. The model consists of two dense layers, with 10 neurons in the first layer and 1 neuron in the output layer. The activation function for the first layer is ReLU, and the output layer uses a sigmoid activation function.Next, we compile the model using the binary cross-entropy loss function and the Adam optimizer. We also specify that we want to track the accuracy metric during training.We then train the model using the `fit()` method, passing in the input data `X` and target labels `y`. We set the number of epochs to 10 and the batch size to 10.After training, we evaluate the model using the `evaluate()` method, passing in the same input data `X` and target labels `y`. The method returns the loss and accuracy of the model on the provided data, which we print to the console.Prompts模板
# 采取一段文本,将用户的输入注入到该文本中,然后用用户的输入格式化提示,并将其反馈给语言模型
from langchain import PromptTemplate
template = """
You are an expert data scientist with an expertise in building deep learning models.
Explain the concept of {concept} in a couple of lines
"""prompt = PromptTemplate(input_variables=["concept"],template=template,
)llm(prompt.format(concept="autoencoder"))输出结果为:
'\nAutoencoders are a type of neural network used for unsupervised learning. They are used to learn efficient representations of input data by learning to compress and reconstruct the input data. They consist of an encoder which compresses the input data into a latent representation, and a decoder which reconstructs the input data from the latent representation.'链Chains
一个链需要一个语言模型和一个Prompts模板,并将它们组合成一个界面,接受用户的输入,并从语言模型中输出一个答案。类似于复合函数,内部函数是Prompts模板,外部函数是语言模型。
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)# 只明确输入变量跑chain
print(chain.run("autoencoder"))输出结果为:
An autoencoder is a type of artificial neural network used to learn a low-dimensional representation of data (called an "encoding") from the input data. It is a type of unsupervised learning technique that can be used to perform dimensionality reduction, feature extraction, and anomaly detection.【顺序链】
# 建立一个顺序链,即一个链返回一个输出,然后第二个链将第一个链的输出作为输入
from langchain.chains import SimpleSequentialChain
second_prompt = PromptTemplate(input_variables=["ml_concept"],template="Turn the concept description of {ml_concept} and explain it to me like I'm five in 500 words",
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)# 只明确第一个chain的输入变量跑chain
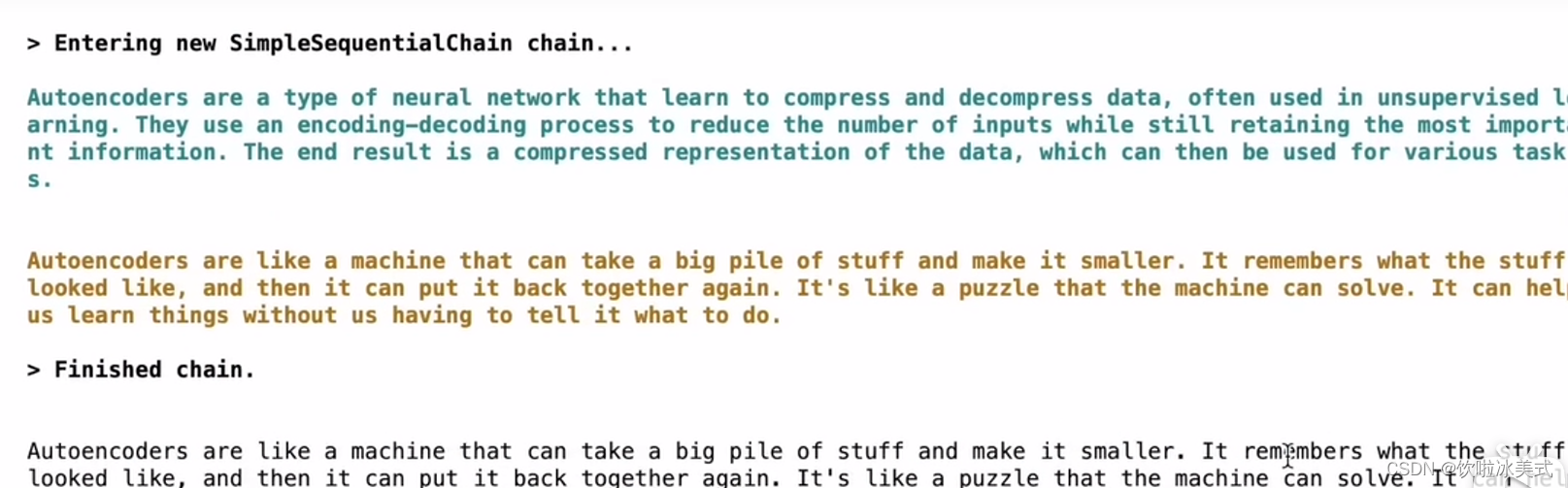
explanation = overall_chain.run("autoencoder")
print(explanation)输出结果为:
嵌入和矢量存储Embeddings and VectorStores
现在我们要把上述explanation文本拆成几块,然后储存到Pinecone的一个矢量存储中:
刚好Langchain有一个文本拆分工具可以做到这点
from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=100,chunk_overlap=0,
)
texts = text_splitter.create_documents([explanation])
print(texts)#print(texts[0].page_content)输出结果为:
[Document(page_content='Autoencoders are a type of artificial intelligence, sometimes called “neural networks”. They are', metadata={}),Document(page_content='like computers that can learn.', metadata={}),Document(page_content='An autoencoder has two parts: an encoder and a decoder. The encoder takes in data (like a picture or', metadata={}),Document(page_content='a sentence) and compresses it. It makes the data much smaller and simpler. The decoder takes the', metadata={}),Document(page_content='data and recreates it back to its original form.', metadata={}),Document(page_content='For example, let’s say you have a picture of a cat. The encoder would take this picture and make it', metadata={}),Document(page_content='much smaller and simpler. Then the decoder would take this small and simple version and recreate the', metadata={}),Document(page_content='original picture of the cat.', metadata={}),Document(page_content='Autoencoders can be used for many things. They can be used to learn interesting features from data,', metadata={}),Document(page_content='reduce the size of data, and find errors in data.', metadata={}),Document(page_content='For example, if you give an autoencoder a picture of a cat, it can learn what a cat looks like and', metadata={}),Document(page_content='it can quickly recognize a cat in a different picture. It can also reduce the size of the picture,', metadata={}),Document(page_content='making it easier to store and faster to share. Finally, it can find errors in pictures, like if the', metadata={})]然后接下来要做的就是把它编程一个嵌入,这知识这个文本的一个矢量表示。而且我们可以使用OpenAI的嵌入模型Ada。
有了Openai的模型,我们就可以对刚刚从文档的各块中提取的原始文本调用嵌入查询
from langchain.embeddings import OpenAIEmbeddingsembeddings = OpenAIEmbeddings(model_name="ada")
query_result = embeddings.embed_query(texts[0].page_content)
print(query_result)输出结果为一个embedding向量。把文件的各块内容拿出来,在Pinecone中存储向量表示:

接下来,我们将导入Pinecone Python客户端,我们将从Langchain矢量商店导入Pinecone。
我们使用钥匙和环境文件中的环境启动Pinecone客户端。
我们采取嵌入模型,采取一个索引名称,我们把这些嵌入块加载到Pinecone。而一旦我们将矢量存储在Pinecone中,我们就可以对存储的数据提出问题。
然后我们就可以在Pinecone中进行相似性搜索,以获得答案或提取所有相关的块状物
import os
import pinecone
from langchain.vectorstores import Pinecone
from tqdm.autonotebook import tqdm# 初始化Pinecone
pinecone.init(api_key=os.getenv("PINECONE_API_KEY"),environment=os.getenv("PINECONE_ENV")
)# 若index不存在,则先新建index,再用from_documents进行存储;若index已存在,则用from_existing_index进行存储
index_name = "langchain-quickstart"
if index_name not in pinecone.list_indexes():pinecone.create_index(name=index_name,metric="cosine",dimension=1024)search = Pinecone.from_documents(texts, embeddings, index_name=index_name)
else:search = Pinecone.from_existing_index(index_name, embeddings)query = "What is magical at autoencoder?"
result = search.similarity_search(query)
result我们前往pinecone就可以看到索引在这里
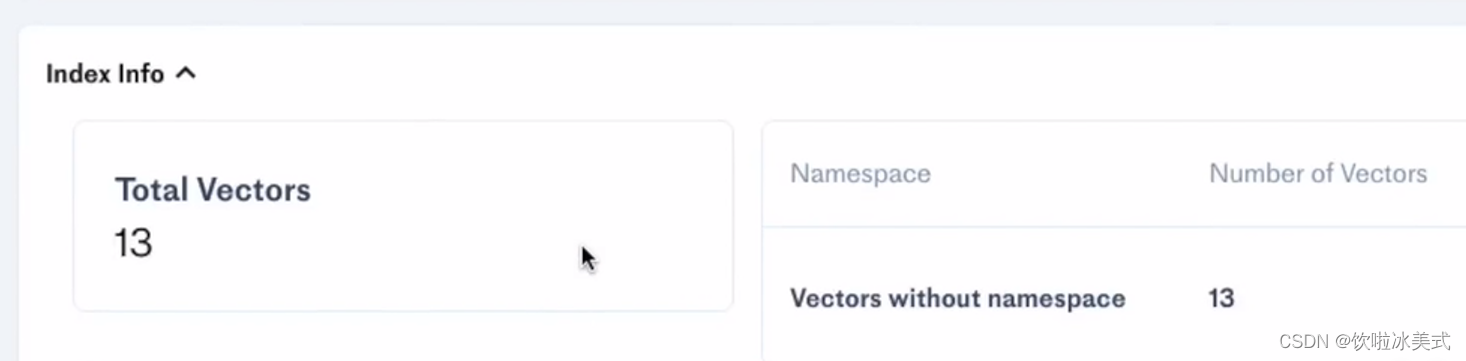
检查索引信息,我们在向量库中共有13个向量
Agents(代理执行者)
简单说吧,就是大语言模型做不到的事情,让别的模型做,比如代码生成,图像生成等。
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
from langchain.python import PythonREPL
from langchain.llms.openai import OpenAIagent_executor = create_python_agent(llm=OpenAI(temperature=0, max_tokens=1000),tool=PythonREPLTool(),verbose=True
)agent_executor.run("Find the roots (zeros) if the quadratic function 3 * x**2 + 2*x -1")输出结果为:
> Entering new AgentExecutor chain...I need to solve a quadratic equation
Action: Python REPL
Action Input: import numpy as np
Observation:
Thought: I can use the numpy function to solve the equation
Action: Python REPL
Action Input: np.roots([3,2,-1])
Observation:
Thought: I now know the final answer
Final Answer: (-1.0, 0.3333333333333333)> Finished chain.代码示例:
# 导入LLM包装器
from langchain import OpenAI, ConversationChain
from langchain.agents import initialize_agent
from langchain.agents import load_tools
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplatellm = OpenAI(model_name="text-davinci-003", temperature=0.9) // 这些都是OpenAI的参数
text = "What would be a good company name for a company that makes colorful socks?"
print(llm(text))
// 以上就是打印调用OpenAI接口的返回值,相当于接口的封装,实现的代码可以看看github.com/hwchase17/langchain/llms/openai.py的OpenAIChat代码运行结果:
Cozy Colours Socks.Prompt Templates:管理LLMs的Prompts,就像我们需要管理变量或者模板一样。
prompt = PromptTemplate(input_variables=["product"],template="What is a good name for a company that makes {product}?",
)
// 以上是两个参数,一个输入变量,一个模板字符串,实现的代码可以看看github.com/hwchase17/langchain/prompts
// PromptTemplate实际是基于StringPromptTemplate,可以支持字符串类型的模板,也可以支持文件类型的模板代码运行结果:
What is a good name for a company that makes colorful socks?Chains:将LLMs和prompts结合起来,前面提到提供了OpenAI的封装和你需要问的字符串模板,就可以执行获得返回了。
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt) // 通过LLM的llm变量,Prompt Templates的prompt生成LLMChain
chain.run("colorful socks") // 实际这里就变成了实际问题:What is a good name for a company that makes colorful socks?Agents:基于用户输入动态地调用chains,LangChain可以将问题拆分为几个步骤,然后每个步骤可以根据提供个Agents做相关的事情。
# 导入一些tools,比如llm-math
# llm-math是langchain里面的能做数学计算的模块
tools = load_tools(["llm-math"], llm=llm)
# 初始化tools,models 和使用的agent
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
text = "12 raised to the 3 power and result raised to 2 power?"
print("input text: ", text)
agent.run(text)代码运行结果(拆分为两部分):
> Entering new AgentExecutor chain...I need to use the calculator for this
Action: Calculator
Action Input: 12^3
Observation: Answer: 1728
Thought: I need to then raise the previous result to the second power
Action: Calculator
Action Input: 1728^2
Observation: Answer: 2985984Thought: I now know the final answer
Final Answer: 2985984
> Finished chain.Memory:就是提供对话的上下文存储,可以使用Langchain的ConversationChain,在LLM交互中记录交互的历史状态,并基于历史状态修正模型预测。
# ConversationChain用法
llm = OpenAI(temperature=0)
# 将verbose设置为True,以便我们可以看到提示
conversation = ConversationChain(llm=llm, verbose=True)
print("input text: conversation")
conversation.predict(input="Hi there!")
conversation.predict(input="I'm doing well! Just having a conversation with an AI.")通过多轮运行以后,就会出现:
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:Human: Hi there!
AI: Hi there! It's nice to meet you. How can I help you today?
Human: I'm doing well! Just having a conversation with an AI.
AI: That's great! It's always nice to have a conversation with someone new. What would you like to talk about?

)
![Vue element-plus 导航栏 [el-menu]](http://pic.xiahunao.cn/Vue element-plus 导航栏 [el-menu])


)
】)










)
函数)