python多方式操作elasticsearch介绍
1. requests模块操作ES
requests 是一个 Python HTTP 库,它简化了发送 HTTP 请求和处理响应的过程。通过 requests 模块,开发人员可以轻松地与 Web 服务进行通信,包括获取网页内容、执行 API 请求等。requests 提供了简洁而直观的 API,使得发送 GET、POST、PUT、DELETE 等类型的请求变得容易。它支持各种认证方式、持久连接、会话管理、文件上传等功能,同时提供了丰富的响应处理方法,包括 JSON 解析、内容解码、状态码检查等。由于其简单易用的特点,requests 成为了 Python 社区中最受欢迎的 HTTP 库之一,被广泛应用于网络爬虫、Web 开发和数据采集等场景。
- 使用requests库操作ElasticSearch的基本方法
1.创建/更新文档:使用PUT方法
2.获取文档:使用GET方法
3.删除文档:使用DELETE方法
4.搜索文档:使用GET方法,并在URL中添加搜索参数
pip install requests
import requestses_url = 'http://wangting_host:9200'#### 通过接口简单获取API信息
res = requests.get(f'{es_url}/_cat/nodes')
print(res.text)"""
Output:
192.170.0.181 28 92 0 0.00 0.01 0.05 cdfhilmrstw - ops03
192.170.0.150 43 98 0 0.01 0.04 0.05 cdfhilmrstw - ops01
192.170.0.13 24 87 0 0.01 0.02 0.05 cdfhilmrstw * ops02
"""#### 创建/更新文档方法 (存在更新,不存在创建)
def create_or_update_doc(index_name, doc_id, document):url = f'{es_url}/{index_name}/_doc/{doc_id}'response = requests.put(url, json=document)print(response.json())# 调用方法实现功能(调用通常使用main函数,这里直接使用)
# 调用创建
index_name = 'test0329'
doc_id = '1'
document = {'标题': 'Python ElasticSearch','正文': 'ElasticSearch is a great tool for full-text search.'
}create_or_update_doc(index_name, doc_id, document)
"""
Output:
{'_index': 'test0329', '_id': '1', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 0, '_primary_term': 1}命令行执行效果:
GET /_cat/indices?vhealth status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open test0329 HPGaPO2xQiGNOVpozZ5wSg 1 1 1 0 11.3kb 5.6kb
"""#### 获取文档方法
def get_doc(index_name, doc_id):url = f'{es_url}/{index_name}/_doc/{doc_id}'response = requests.get(url)print(response.json())get_doc(index_name, doc_id)
"""
Output:
{'_index': 'test0329', '_id': '1', '_version': 1, '_seq_no': 0, '_primary_term': 1, 'found': True, '_source': {'标题': 'Python ElasticSearch', '正文': 'ElasticSearch is a great tool for full-text search.'}}
"""#### 搜索文档方法
def search_doc(index_name, query):url = f'{es_url}/{index_name}/_search'response = requests.get(url, params=query)print(response.json())query = {'q': 'Python'}
search_doc(index_name, query)"""
Output:
{'took': 9, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 1, 'relation': 'eq'}, 'max_score': 0.2876821, 'hits': [{'_index': 'test0329', '_id': '1', '_score': 0.2876821, '_source': {'标题': 'Python ElasticSearch', '正文': 'ElasticSearch is a great tool for full-text search.'}}]}}
""" #### 删除文档方法
def delete_doc(index_name, doc_id):url = f'{es_url}/{index_name}/_doc/{doc_id}'response = requests.delete(url)print(response.json())# 调用删除
delete_doc(index_name, doc_id)"""
再次使用get_doc获取方法验证
get_doc(index_name, doc_id)
Output:
{'_index': 'test0329', '_id': '1', 'found': False}
"""
2. elasticsearch模块操作ES
elasticsearch 是 Python 中用于与 Elasticsearch 进行交互的官方库,它提供了一种方便的方式来执行各种操作,包括索引、搜索、删除文档等。这个库封装了与 Elasticsearch REST API 的交互细节,使得开发人员能够更轻松地与 Elasticsearch 集群进行通信。
使用 elasticsearch 库,您可以轻松地连接到 Elasticsearch 集群,并执行各种操作。
-
连接到 Elasticsearch 集群:使用
Elasticsearch类连接到 Elasticsearch 集群,可以指定多个节点,并支持 HTTP Basic 认证和其他连接参数。 -
索引文档:使用
index方法可以将文档索引到 Elasticsearch 中,您可以指定索引名称、文档类型、文档 ID 和文档内容。 -
获取文档:使用
get方法可以根据索引名称、文档类型和文档 ID 获取特定文档的内容。 -
搜索文档:使用
search方法可以执行搜索操作,您可以指定查询条件、排序规则、分页参数等。 -
删除文档:使用
delete方法可以根据索引名称、文档类型和文档 ID 删除特定文档。 -
批量操作:
elasticsearch库支持批量索引、更新和删除文档,可以显著提高性能。 -
异常处理:
elasticsearch库提供了对 Elasticsearch 返回的各种错误和异常的处理机制,使得开发人员能够更好地处理异常情况。 -
灵活性:
elasticsearch库允许您以不同的方式指定查询条件、索引文档和执行其他操作,以满足各种需求。
pip install elasticsearch
2-1. elasticsearch模块基本用法
from elasticsearch import Elasticsearchdef create_index(client, index_name):if not client.indices.exists(index=index_name):result = client.indices.create(index=index_name)print(f'< def create_index >: Index[{index_name}] created successfully! {result}')else:print(f'< def create_index >: Index[{index_name}] already exists!')def delete_index(client, index_name):if client.indices.exists(index=index_name):result = client.indices.delete(index=index_name)print(f'< def delete_index >: Index[{index_name}] {result}')def insert_data(client, index_name, document_id, data):if client.indices.exists(index=index_name):result = client.index(index=index_name, id=document_id, body=data)print(f'< def insert_data >: Index[{index_name}] {result}')else:print(f'< def insert_data >: Index[{index_name}] is not exists')def query_data(client, index_name, query):if client.indices.exists(index=index_name):result = client.search(index=index_name, body=query)clean_data = dict(result)['hits']['hits'][0]['_source']for key, value in clean_data.items():print(f"{key}:{value}")else:print("index is not exists")def delete_data(client, index_name, document_id):result = client.delete(index=index_name, id=document_id)print(f'< def delete_data >: {result}')def main():es_url = "http://wangting_host:9200"client = Elasticsearch(es_url)index_name = "user_login"document_id = "1"data = {"username": "wangting_666","password": "12345678","phone": "13813812345"}query = {'query': {'match_all': {}}}create_index(client, index_name)insert_data(client, index_name, document_id, data)query_data(client, index_name, query)delete_data(client, index_name, document_id)delete_index(client, index_name)if __name__ == "__main__":main()##### 控制台输出 #####
### create_index
< def create_index >: Index[user_login] already exists!### insert_data
< def insert_data >: Index[user_login] {'_index': 'user_login', '_id': '1', '_version': 2, 'result': 'updated', '_shards': {'total': 2, 'successful': 2, 'failed': 0}, '_seq_no': 1, '_primary_term': 1}### query_data
username:wangting_666
password:12345678
phone:13813812345### delete_data
< def delete_data >: {'_index': 'user_login', '_id': '1', '_version': 3, 'result': 'deleted', '_shards': {'total': 2, 'successful': 2, 'failed': 0}, '_seq_no': 2, '_primary_term': 1}### delete_index
< def delete_index >: Index[user_login] {'acknowledged': True}
2-2. elasticsearch模块业务使用方式
- 生产环境使用demo
README.md :
项目描述:
本项目demo是一个使用 Python 编写的示例代码,演示了如何使用 ElasticSearch 的官方 Python 客户端库 elasticsearch 进行索引管理和文档操作。项目主要包括创建索引、定义映射、插入文档、更新文档、查询文档和删除文档等功能,并且利用 Python 内置的 logging 模块实现了日志记录功能,将运行时的信息输出到指定的日志文件中。功能概述:1. 初始化 ES 连接:根据配置文件中的信息初始化 ElasticSearch 连接。
2. 创建索引:如果指定的索引不存在,则创建新的索引;如果索引已存在,则忽略。
3. 删除索引:如果指定的索引存在,则删除该索引。
4. 定义映射:为指定索引定义文档的映射。
5. 插入文档:向指定索引中插入新的文档。
6. 更新文档:更新指定索引中的文档。
7. 查询文档:在指定索引中搜索文档。
8. 删除文档:从指定索引中删除文档。日志记录:
项目使用 logging 模块记录运行时的信息,包括索引的创建、映射的定义、文档的插入、更新、查询和删除等操作,将日志信息输出到项目根目录下的 log 目录中的 elasticsearch_dsl.log 文件中,方便开发者查看和调试。使用说明:1. 在配置文件 config.ini 中配置 ElasticSearch 的主机地址。
2. 运行 ElasticSearch_prd.py 文件,即可执行项目中的示例代码,演示 ElasticSearch 的索引管理和文档操作功能。该项目提供了一个简单而完整的示例,可供开发者学习和参考,帮助理解如何使用 elasticsearch-dsl 库进行 ElasticSearch 的操作。目录结构
ElasticSearch/
│
├── conf/ # 配置文件目录
│ └── config.ini # ElasticSearch 配置文件
│
├── log/ # 日志文件目录
│ └── elasticsearch_dsl.log # 日志文件
│
├── ElasticSearch_prd.py # 项目主文件
│
└── README.md # 项目说明文件配置文件:
config.ini[elasticsearch]
host = http://wangting_host:9200
ElasticSearch_prd.py 完整代码:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# @Project :ElasticSearch
# @File :ElasticSearch-dsl.py
# @Time :2024/3/30 20:24
# @Author :wangting_666import os
import logging
import configparser
from elasticsearch import Elasticsearch# 设置日志格式和级别
log_dir = "./log"
if not os.path.exists(log_dir):os.makedirs(log_dir)logging.basicConfig(level=logging.INFO,format="%(asctime)s [%(levelname)s] %(message)s",handlers=[logging.FileHandler(os.path.join(log_dir, "elasticsearch_dsl.log")),logging.StreamHandler()]
)# 读取ES配置
config = configparser.ConfigParser()
config.read('./conf/config.ini')
es_host = config.get('elasticsearch', 'host')# 初始化ES连接
def init_es_client(host):return Elasticsearch(hosts=[host])# 创建索引方法
def create_index(es, index_name):"""创建索引,如果索引已存在则忽略"""if not es.indices.exists(index=index_name):es.indices.create(index=index_name)logging.info(f"Index '{index_name}' created successfully")else:logging.info(f"Index '{index_name}' already exists")# 删除索引方法
def delete_index(es, index_name):if es.indices.exists(index=index_name):es.indices.delete(index=index_name)logging.info(f"Index '{index_name}' deleted successfully")# 定义映射方法
def define_mapping(es, index_name, mapping):"""为索引定义映射"""es.indices.create(index=index_name, body=mapping, ignore=400)logging.info(f"Mapping for index '{index_name}' defined successfully")# 插入文档
def insert_document(es, index_name, doc_id=None, document=None):"""插入文档到指定索引"""es.index(index=index_name, id=doc_id, body=document)logging.info(f"Document inserted into index '{index_name}' with ID '{doc_id}'")# 更新文档
def update_document(es, index_name, doc_id=None, updated_doc=None):"""更新指定ID的文档"""es.update(index=index_name, id=doc_id, body={"doc": updated_doc})logging.info(f"Document with ID '{doc_id}' in index '{index_name}' updated successfully")# 查询文档
def search_documents(es, index_name, query):"""在指定索引中搜索文档"""result = es.search(index=index_name, body=query)logging.info(f"Search result for index '{index_name}': {result}")return result# 删除文档
def delete_document(es, index_name, doc_id=None):"""删除指定ID的文档"""es.delete(index=index_name, id=doc_id)logging.info(f"Document with ID '{doc_id}' deleted from index '{index_name}'")def main():es = init_es_client(es_host)index_name = "wangting_666"create_index(es, index_name)mapping = {"mappings": {"properties": {"name": {"type": "text"},"age": {"type": "integer"},"email": {"type": "keyword"}}}}define_mapping(es, index_name, mapping)doc = {"name": "小米su7","age": 18,"email": "wang@xiaomi.com"}insert_document(es, index_name, doc_id="1", document=doc)update_document(es, index_name, doc_id="1", updated_doc={"age": 66})query = {'query': {'match_all': {}}}search_documents(es, index_name, query)delete_document(es, index_name, doc_id="1")delete_index(es, index_name)if __name__ == "__main__":main()
代码运行日志内容示例:
elasticsearch_dsl.log
2024-03-30 20:08:41,718 [INFO] HEAD http://wangting_host:9200/wangting_666 [status:404 duration:0.098s]
2024-03-30 20:08:41,857 [INFO] PUT http://wangting_host:9200/wangting_666 [status:200 duration:0.140s]
2024-03-30 20:08:41,857 [INFO] Index 'wangting_666' created successfully
2024-03-30 20:08:41,947 [INFO] PUT http://wangting_host:9200/wangting_666 [status:400 duration:0.063s]
2024-03-30 20:08:41,947 [INFO] Mapping for index 'wangting_666' defined successfully
2024-03-30 20:08:42,014 [INFO] PUT http://wangting_host:9200/wangting_666/_doc/1 [status:201 duration:0.066s]
2024-03-30 20:08:42,014 [INFO] Document inserted into index 'wangting_666' with ID '1'
2024-03-30 20:08:42,059 [INFO] POST http://wangting_host:9200/wangting_666/_update/1 [status:200 duration:0.044s]
2024-03-30 20:08:42,059 [INFO] Document with ID '1' in index 'wangting_666' updated successfully
2024-03-30 20:08:42,097 [INFO] POST http://wangting_host:9200/wangting_666/_search [status:200 duration:0.038s]
2024-03-30 20:08:42,097 [INFO] Search result for index 'wangting_666': {'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 0, 'relation': 'eq'}, 'max_score': None, 'hits': []}}
2024-03-30 20:08:42,162 [INFO] DELETE http://wangting_host:9200/wangting_666/_doc/1 [status:200 duration:0.064s]
2024-03-30 20:08:42,162 [INFO] Document with ID '1' deleted from index 'wangting_666'
2024-03-30 20:08:42,215 [INFO] HEAD http://wangting_host:9200/wangting_666 [status:200 duration:0.053s]
2024-03-30 20:08:42,283 [INFO] DELETE http://wangting_host:9200/wangting_666 [status:200 duration:0.068s]
2024-03-30 20:08:42,284 [INFO] Index 'wangting_666' deleted successfully
验证执行过程是否有问题,可以先不执行delete相关方法
执行代码后,在kibana上查询数据验证
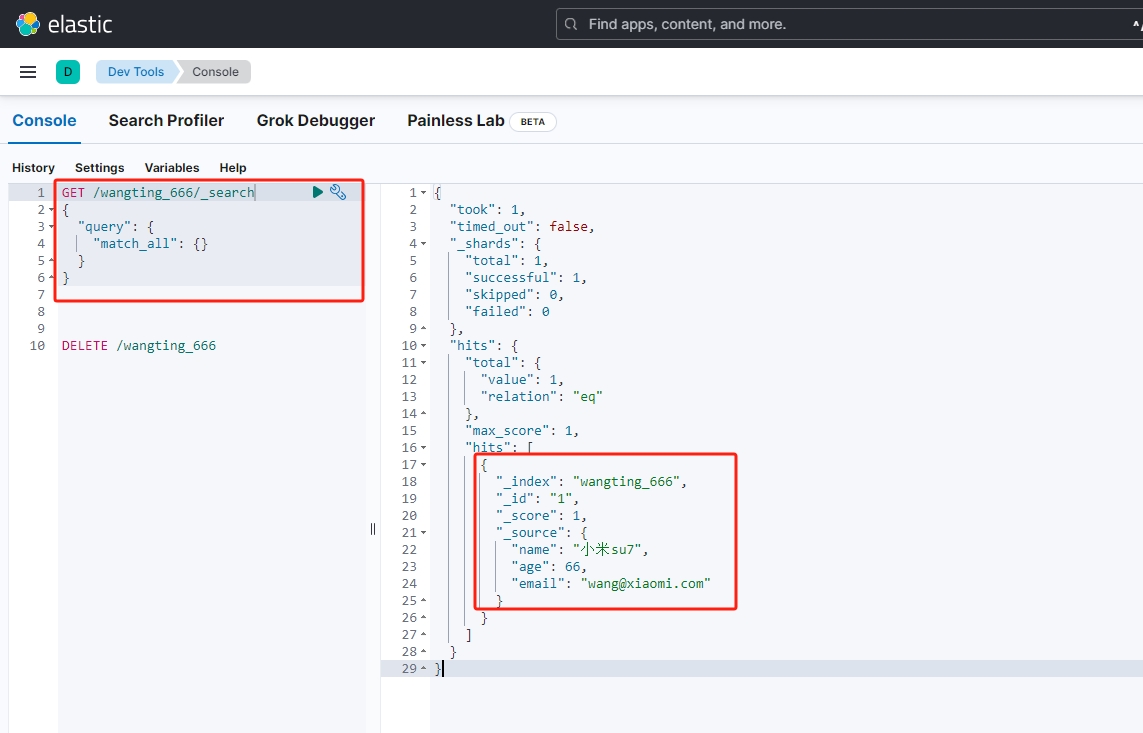
3. elasticsearch-dsl模块使用
3-1. 什么是 elasticsearch-dsl?
Elasticsearch DSL(Domain Specific Language 领域特定语言)是 Elasticsearch 官方提供的一个 Python 客户端库,它允许开发者以一种更加 Pythonic 和直观的方式与 Elasticsearch 进行交互和查询。DSL 不是一种编程语言,而是一种专门针对某一领域(如 Elasticsearch 查询语言)设计的语言。在 Elasticsearch 中,DSL 用于构建复杂的搜索查询、聚合操作和过滤条件。
Elasticsearch DSL 提供了一个面向对象的接口,使得开发者可以使用 Python 中的类和方法来构建 Elasticsearch 查询,而不必直接编写 JSON 查询体。这种方式使得代码更加清晰易懂,并且可以利用 Python 的强大功能来构建动态查询。通过 Elasticsearch DSL,开发者可以以更加高效和灵活的方式构建 Elasticsearch 查询,同时还能够利用 Python 生态系统中丰富的工具和库来处理查询结果。
Elasticsearch DSL 使得 Python 开发者简化了与 Elasticsearch 的交互过程,并提供了更加直观和易于理解的接口。
3-2. elasticsearch-dsl特点
- 简化了与 Elasticsearch 的交互过程,使得代码更加易于理解和维护。
- 提供了一种更加直观的方式来构建查询和聚合操作,无需直接操作 JSON。
- 支持类型检查和自动完成,减少了错误的可能性。
- 可以更加灵活地构建动态查询,根据不同的条件生成不同的查询语句。
3-3. elasticsearch-dsl 的基本构件
在 elasticsearch-dsl 中,主要的构件包括:
- 查询(Queries)
- 过滤器(Filters)
- 聚合(Aggregations)
- 排序(Sorting)
- 分页(Pagination)
3-4. elasticsearch-dsl使用
elasticsearch-dsl模块功能非常多,常见功能如表
| 方法 | 功能 | 代码示例 |
|---|---|---|
Search(index) | 创建一个搜索请求对象 | s = Search(index='my_index') |
query(...) | 设置查询条件 | s = s.query('match', title='python') |
filter(...) | 设置过滤条件 | s = s.filter('term', category='programming') |
sort(...) | 设置排序条件 | s = s.sort('title') |
source(...) | 设置返回字段 | s = s.source(['title', 'category']) |
highlight(...) | 设置高亮显示字段 | s = s.highlight('title') |
aggs.bucket(...) | 添加一个聚合桶 | s.aggs.bucket('by_category', 'terms', field='category') |
aggs.metric(...) | 添加一个聚合指标 | s.aggs.metric('avg_age', 'avg', field='age') |
execute() | 执行搜索请求 | response = s.execute() |
response.hits.total.value | 获取搜索结果的总数 | total_hits = response.hits.total.value |
response.hits.hits | 获取搜索结果的文档列表 | hits = response.hits.hits |
response.aggregations | 获取聚合结果 | aggs_result = response.aggregations |
Q('query_string', query=...) | 创建一个查询字符串查询 | q = Q('query_string', query='python') |
A('terms', field=...) | 创建一个术语聚合 | a = A('terms', field='category') |
Index(name) | 创建一个索引对象 | index = Index('my_index') |
index.create() | 创建索引 | index.create() |
index.delete() | 删除索引 | index.delete() |
3-4-1. 匹配查询(Match Query)
匹配查询用于查找包含指定文本的文档。
from elasticsearch import Elasticsearch
from elasticsearch_dsl import Search, Q# 创建 Elasticsearch 客户端
client = Elasticsearch(['http://wangting_host:9200'])# 创建一个 Search 对象
s = Search(using=client, index='storyline_base')# 匹配查询
s1 = s.query(Q('match', raw_text='碧桂园'))# 执行查询
response = s.execute()# 处理查询结果
for hit in response:print(hit.raw_text)# Output:
"""
标题:碧桂园简介(碧桂园简介)
标题:碧桂园(2007.HK)跌超4%,报1.56港元,碧桂园6月销售额创新低|碧桂园
标题:碧桂园被冻结3.8亿存款|碧桂园
标题:碧桂园杨惠妍:碧桂园不是家族企业
标题:碧桂园投资版图盘点 碧桂园
标题:碧桂园天誉(碧桂园简介)
标题:碧桂园近期转让多家公司股权|碧桂园
标题:中国平安(601318.SH):有关碧桂园的报道完全与事实不符 公司未持有碧桂园的股份|碧桂园
标题:森鹰窗业:公司正在履行合同中无碧桂园相关项目,也不存在碧桂园相关项目应收账款|碧桂园
标题:碧桂园新开楼盘排名(碧桂园山河城)
"""
3-4-2. 多字段匹配查询(Multi-match Query)
多字段匹配查询用于在多个字段中查找包含指定文本的文档。
from elasticsearch import Elasticsearch
from elasticsearch_dsl import Search, Q# 创建 Elasticsearch 客户端
client = Elasticsearch(['http://wangting_host:9200'])# 创建一个 Search 对象
s = Search(using=client, index='storyline_base')# 多字段匹配查询
s = s.query(Q('match', raw_text='碧桂园') & Q('match', news_id='66432104581263876650'))# 执行查询
response = s.execute()# 处理查询结果
for hit in response:print(hit.doc_id, hit.news_id, hit.pubtime, hit.raw_text)# Output:
"""
f46b1be478ff3bb94f9b1b8f4d6283ce 66432104581263876650 2023-07-28 09:54:56 标题:港股房地产股多数走强,碧桂园涨近4%
1d06a2c58f536028da3de03db66d540b 66432104581263876650 2023-07-28 09:54:56 摘要:香港股市中的大多数房地产股票表现强劲
"""
3-4-3. 范围查询(Range Query)
范围查询用于查找字段值在指定范围内的文档。
from elasticsearch import Elasticsearch
from elasticsearch_dsl import Search, Q# 创建 Elasticsearch 客户端
client = Elasticsearch(['http://wangting_host:9200'])# 创建一个 Search 对象
s = Search(using=client, index='storyline_base')# 添加范围查询
s = s.query(Q('range', news_id={'gte': 2073620092894144610, 'lte': 2073620092894144630}))# 执行查询
response = s.execute()# 处理查询结果
for hit in response:print(hit.news_id, hit.raw_text)# Output:
"""
2073620092894144620 标题:华为杨超斌:持续创新引领数字时代
2073620092894144623 摘要:华为公司高级副总裁杨超斌在2023年巴塞罗那世界移动通信大会上发表主题演讲,强调5G技术的发展推动社会进入智能世界。
"""
3-4-4. 通配符查询(Wildcard Query)
通配符查询用于查找符合指定模式的文档。
from elasticsearch import Elasticsearch
from elasticsearch_dsl import Search, Q# 创建 Elasticsearch 客户端
client = Elasticsearch(['http://wangting_host:9200'])# 创建一个 Search 对象
s = Search(using=client, index='storyline_base')# 通配符查询
s = s.query(Q('wildcard', doc_id='3dd7e3*'))# 执行查询
response = s.execute()# 处理查询结果
for hit in response:print(hit.doc_id, hit.raw_text)# Output:
"""
3dd7e3e90822340543f8a265ae564f9d 标题:华为杨超斌:持续创新引领数字时代
"""
4. Elasticsearch服务python日常巡检监控
es_check.py脚本内容
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import requests
from elasticsearch import Elasticsearch
import datetime
import os
import logging# 设置日志格式和级别
log_dir = "./log"
if not os.path.exists(log_dir):os.makedirs(log_dir)logging.basicConfig(level=logging.INFO,format="%(asctime)s [%(levelname)s] %(message)s",handlers=[logging.FileHandler(os.path.join(log_dir, "es_check.log")),logging.StreamHandler()]
)# Elasticsearch配置信息
es_host = 'http://wangting_host:9200'
es = Elasticsearch(es_host)# 函数:检查 Elasticsearch 集群是否可访问
def check_elasticsearch_availability():try:response = requests.get(es_host)if response.status_code == 200:logging.info(f'es {es_host} 健康,可以访问')else:logging.error(f'es {es_host} 不可访问! Status code:{response.status_code}')except requests.ConnectionError:logging.error("连接错误。es无法正常连接")# 获取集群健康状态
def check_cluster_health():health = es.cluster.health()logging.info(f"集群整体健康状态: {health['status']}")# 函数:检查节点信息
def check_node_info():try:response = requests.get(f'{es_host}/_nodes')if response.status_code == 200:nodes_info = response.json()nodes_count = len(nodes_info['nodes'])logging.info("es集群节点 node 个数: %d", nodes_count)else:logging.error("获取集群节点信息数据失败: %d", response.status_code)except requests.ConnectionError:logging.error("连接错误。es无法正常连接")# 获取所有索引的状态
def check_index_status():indices = es.indices.stats()['indices']for index_name, index_stats in indices.items():status = index_stats['status']logging.info(f"索引 {index_name} 状态: {status}")# 监控搜索性能
def monitor_search_performance():query = {'query': {'match_all': {}}}start_time = datetime.datetime.now()result = es.search(index='wangting_666', body=query)end_time = datetime.datetime.now()response_time = (end_time - start_time).total_seconds()logging.info(f"搜索查询性能 - 响应时间: {response_time} 秒, 搜索请求数量: {result['hits']['total']['value']}")# 监控索引性能
def monitor_indexing_performance():doc = {"name": "小米su7","age": 18,"email": "wang@xiaomi.com"}start_time = datetime.datetime.now()es.index(index='wangting_666', id="1", body=doc)end_time = datetime.datetime.now()response_time = (end_time - start_time).total_seconds()logging.info(f"索引性能 - 响应时间: {response_time} 秒")# 执行巡检任务
def run_daily_check():logging.info(f"开始每日巡检: {datetime.datetime.now()}...\n")check_elasticsearch_availability()logging.info("\n")check_node_info()logging.info("\n")check_cluster_health()logging.info("\n")check_index_status()logging.info("\n")monitor_search_performance()logging.info("\n")monitor_indexing_performance()logging.info("\n每日巡检完成.")# 主函数
if __name__ == "__main__":run_daily_check()
日志输出:
2024-03-30 15:11:26,799 [INFO] 开始每日巡检: 2024-03-30 15:11:26.799645...2024-03-30 15:11:26,934 [INFO] es http://wangting_host:9200 健康,可以访问
2024-03-30 15:11:26,934 [INFO] 2024-03-30 15:11:27,197 [INFO] es集群节点 node 个数: 3
2024-03-30 15:11:27,197 [INFO] 2024-03-30 15:11:27,450 [INFO] GET http://wangting_host:9200/_cluster/health [status:200 duration:0.254s]
2024-03-30 15:11:27,451 [INFO] 集群整体健康状态: green
2024-03-30 15:11:27,451 [INFO] 2024-03-30 15:11:27,696 [INFO] GET http://wangting_host:9200/_stats [status:200 duration:0.245s]
2024-03-30 15:11:27,696 [INFO] 索引 event_keystore 状态: open
2024-03-30 15:11:27,697 [INFO] 索引 knowledge_keystore 状态: open
2024-03-30 15:11:27,697 [INFO] 索引 test0330 状态: open
2024-03-30 15:11:27,697 [INFO] 索引 product_keystore 状态: open
2024-03-30 15:11:27,697 [INFO] 索引 storyline_base 状态: open
2024-03-30 15:11:27,697 [INFO] 索引 storyline_demo 状态: open
2024-03-30 15:11:27,697 [INFO] 索引 wangting_666 状态: open
2024-03-30 15:11:27,697 [INFO] 2024-03-30 15:11:27,876 [INFO] POST http://wangting_host:9200/wangting_666/_search [status:200 duration:0.179s]
2024-03-30 15:11:27,876 [INFO] 搜索查询性能 - 响应时间: 0.178881 秒, 搜索请求数量: 1
2024-03-30 15:11:27,876 [INFO] 2024-03-30 15:11:28,002 [INFO] PUT http://wangting_host:9200/wangting_666/_doc/1 [status:200 duration:0.126s]
2024-03-30 15:11:28,003 [INFO] 索引性能 - 响应时间: 0.127108 秒
2024-03-30 15:11:28,003 [INFO]
每日巡检完成.
5. Python同步MySQL数据至ElasticSearch
MySQL样例数据准备:
create database wow;DROP TABLE IF EXISTS `wow_info`;
CREATE TABLE `wow_info` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '角色id',`role` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '角色简称',`role_cn` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '角色类型',`role_pinyin` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '角色拼音',`zhuangbei` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '装备类型',`tianfu` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '天赋类型',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 14 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;INSERT INTO `wow_info` VALUES (1, 'fs', '法师', 'fashi', '布甲', '冰法|火法|奥法');
INSERT INTO `wow_info` VALUES (2, 'ms', '牧师', 'mushi', '布甲', '神牧|戒律|暗牧');
INSERT INTO `wow_info` VALUES (3, 'ss', '术士', 'shushi', '布甲', '毁灭|痛苦|恶魔');
INSERT INTO `wow_info` VALUES (4, 'dz', '盗贼', 'daozei', '皮甲', '狂徒|刺杀|敏锐');
INSERT INTO `wow_info` VALUES (5, 'ws', '武僧', 'wuseng', '皮甲', '酒仙|踏风|织雾');
INSERT INTO `wow_info` VALUES (6, 'xd', '德鲁伊', 'xiaode', '皮甲', '恢复|平衡|野性|守护');
INSERT INTO `wow_info` VALUES (7, 'dh', '恶魔猎手', 'emolieshou', '皮甲', '复仇|浩劫');
INSERT INTO `wow_info` VALUES (8, 'lr', '猎人', 'lieren', '锁甲', '兽王|生存|射击');
INSERT INTO `wow_info` VALUES (9, 'sm', '萨满', 'saman', '锁甲', '恢复|增强|元素');
INSERT INTO `wow_info` VALUES (10, 'long', '龙人', 'longren', '锁甲', '湮灭|恩护|增辉');
INSERT INTO `wow_info` VALUES (11, 'dk', '死亡骑士', 'siwangqishi', '板甲', '鲜血|冰霜|邪恶');
INSERT INTO `wow_info` VALUES (12, 'zs', '战士', 'zhanshi', '板甲', '武器|狂暴|防护');
INSERT INTO `wow_info` VALUES (13, 'sq', '圣骑士', 'shengqi', '板甲', '神圣|防护|惩戒');
python同步脚本MySQL_to_ElasticSearch.py
#!/usr/bin/env python3
# -*- coding:utf-8 -*-import pymysql
from elasticsearch import Elasticsearch# 连接到 MySQL 数据库
conn = pymysql.connect(host='192.168.1.1', user='root', password='123456', database='wow')
cursor = conn.cursor()# 连接到 Elasticsearch
es = Elasticsearch(['http://wangting_host:9200'])# 创建 Elasticsearch 索引
es.indices.create(index='es_wow_info', ignore=400)# 查询 MySQL 数据表
cursor.execute('SELECT id, role,role_cn,role_pinyin,zhuangbei,tianfu FROM wow_info')
wow_info_data = cursor.fetchall()# 将数据同步到 Elasticsearch
for data in wow_info_data:doc = {'role': data[1],'role_cn': data[2],'role_pinyin': data[3],'zhuangbei': data[4],'tianfu': data[5]}es.index(index='es_wow_info', id=data[0], body=doc)# 关闭连接
conn.close()
验证结果:

6. Python同步Hive数据至ElasticSearch
Hive样例数据准备:
CREATE TABLE products (id INT,name STRING,price FLOAT,description STRING
);INSERT INTO products VALUES
(1, 'Product 1', 19.99, 'Description for Product 1'),
(2, 'Product 2', 29.99, 'Description for Product 2'),
(3, 'Product 3', 39.99, 'Description for Product 3');
python同步脚本Hive_to_ElasticSearch.py
from pyhive import hive
from elasticsearch import Elasticsearch
import pandas as pd
from datetime import datetime# 连接到 Hive 数据库
conn = hive.Connection(host='192.168.3.1', port=10000)
cursor = conn.cursor()# 连接到 Elasticsearch
es = Elasticsearch(['http://wangting_host:9200'])# 查询 Hive 数据表
cursor.execute('SELECT * FROM products')
data = cursor.fetchall()# 将查询结果转换为 Pandas DataFrame
columns = [desc[0] for desc in cursor.description]
df = pd.DataFrame(data, columns=columns)# 将数据转换为 Elasticsearch 所需的格式
docs = []
for index, row in df.iterrows():doc = {'id': row['id'],'name': row['name'],'price': float(row['price']),'description': row['description'],'@timestamp': datetime.now().isoformat()}docs.append(doc)# 将数据同步到 Elasticsearch
for doc in docs:es.index(index='es_products_index', body=doc)# 关闭连接
cursor.close()
conn.close()
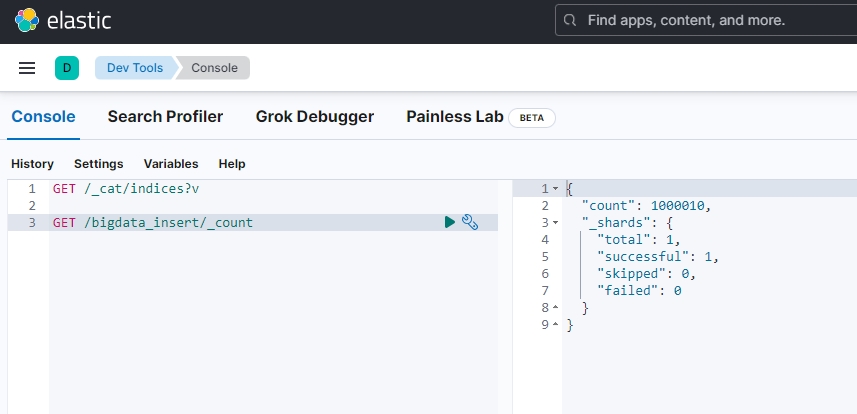
7. ElasticSearch大量数据写入实现
Bigdata2ES.py脚本内容:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-import time
from elasticsearch import Elasticsearch
from elasticsearch import helperses = Elasticsearch(['http://wangting_host:9200'])def timer(func):def wrapper(*args, **kwargs):start = time.time()res = func(*args, **kwargs)print('共耗时约 {:.2f} 秒'.format(time.time() - start))return resreturn wrapperdef create_data():""" 写入数据 """for line in range(10):es.index(index='bigdata_insert', body={'title': line})@timer
def gen():action = ({"_index": "bigdata_insert","_source": {"title": i}} for i in range(1000000))helpers.bulk(es, action)if __name__ == '__main__':# create_data()gen()"""
Output:
共耗时约 215.88 秒
"""




--完全背包拓展题目)


加密U盘)
)





以及什么是字符集,模版)



最新)
