事务的隔离性由锁机制实现,事务的原子性、一致性和持久性由redo日志和undo日志实现。
一、redo日志
1.1、为什么需要redo日志
一方面,由于数据从内存写回磁盘需要一定的时间,假如在事务提交后,还没有写回磁盘,数据库就宕机的话,那么这段数据就无法恢复了。
另一方面,为了维持事务的持久性。对于一个已经提交的事务,即使提交后系统崩溃,也要保证这个事务对数据库中所做的更改也不能丢失。
保证持久性的方法:
-
在事务提交完成前把该事务所修改的所有页面都刷新到磁盘,虽然方法
简单,但是修改量与刷新磁盘的工作量严重不成正比,仅仅为了修改一个字节的数据可能就要刷新一页的数据在磁盘上。并且由于页面可能并不相邻,使用到的随机IO刷新较慢。 -
另一种解决思路是把修改的东西记录一下。比如记录在第0号表的10号页面的偏移量为100处的值更新为2。
redo日志就采用了WAL技术(Write-Ahead Logging),这种技术的思想是先写日志、再写磁盘,日志写入成功就算提交成功。当发生宕机时,就可以通过redo日志来恢复。
1.2、redo日志的好处
好处
- 1、redo日志降低了磁盘刷新频率
- 2、redo日志占用的空间非常小
特点
- redo日志顺序写入磁盘
- 事务执行过程中,redo日志不断记录。
1.3、redo组成
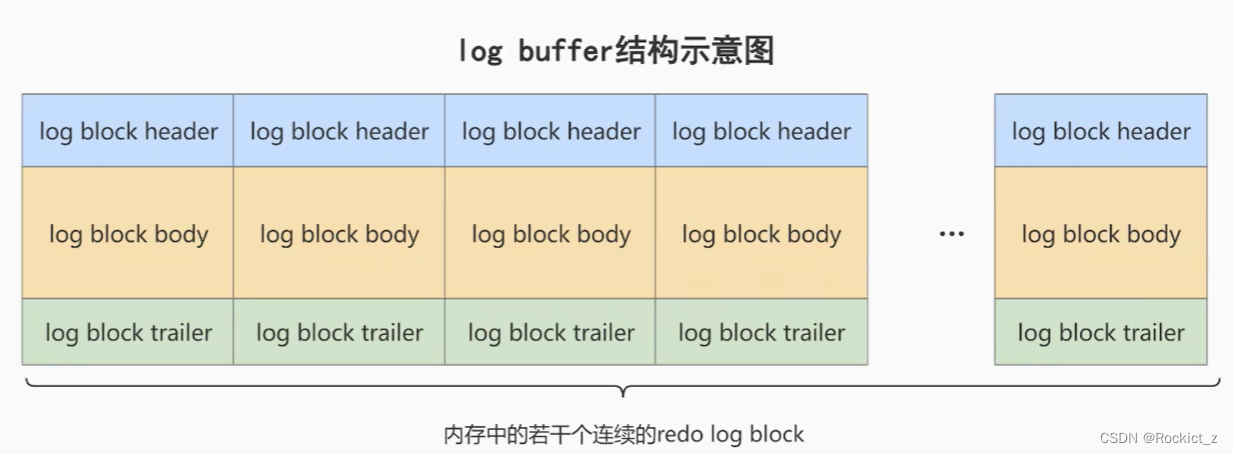
重做日志的缓冲
在数据库服务器启动时向系统申请了一大片称为redo log buffer的连续空间。这片空间被划分为若干个redo log block。
1.4、redo更新流程
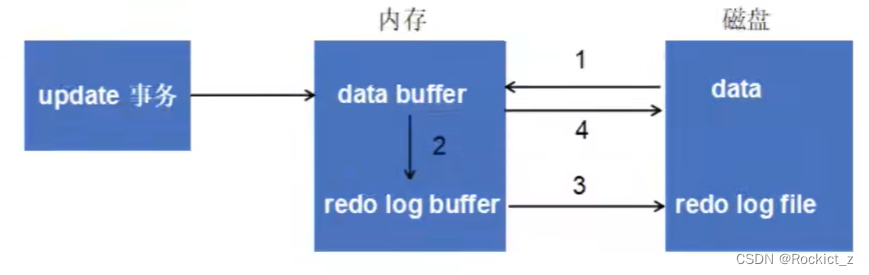
1、将数据从磁盘读到内存中
2、生成redo日志并写入redo log buffer
3、当事务commit后,将redo log buffer中的内容刷新到redo log file中。
4、定期将内存中修改的数据刷新到磁盘中。
1.5、redo log刷盘策略
1.6、redo log file
日志文件组
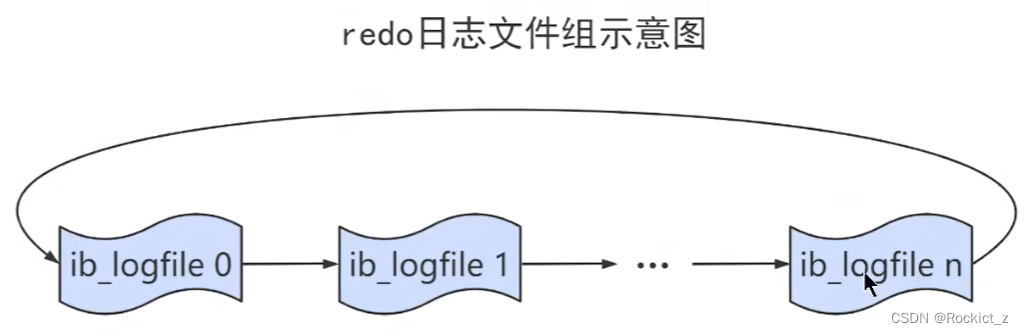
总共的redo日志文件大小为innode_log_file_size * innode_log_files_in_ group 。采用这种循环的方式向redo日志文件组中写入数据,会导致后写入的数据覆盖掉前面的数据。
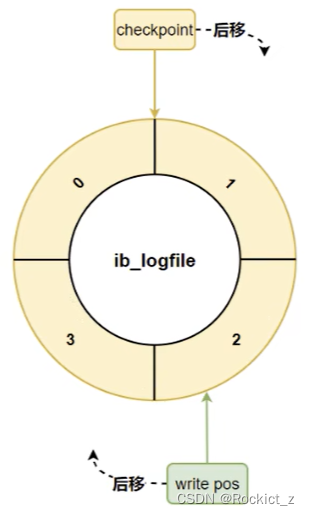
check point
这个日志文件组有两个重要的属性:
write pos是当前位置,一边写一边后移checkpoint是当前要擦除的位置,也是后移。
结构类似于循环队列:
二、undo日志
redo日志保证了事务的持久性,undo日志保证了事务的原子性
2.1、undo日志的理解
每当我们对一条记录进行改动时,都需要把回滚的东西记录下来。比如:
- 对于每个INSERT,InnoDB引擎就会完成一个DELETE
- 对于每个DELETE,InnoDB引擎就会完成一个INSERT
- 对于每个UPDATE,InnoDB引擎就会完成一个相反的UPDATE
这些为了回滚而记录的内容称为回滚日志(undo log)。此外,undo log也会产生redo log来保证持久性。
2.2、undo日志作用
- 回滚数据
undo日志只是将数据库逻辑的恢复,但是数据在物理磁盘上的存储可能不太一样。 - MVCC
多版本并发控制
2.3、undo存储结构
2.3.1、回滚段与undo页
回滚段:InnoDB对undo log的管理采用段的方式
undo页:每个回滚段记录了1024个undo log segment,在每个undo log segment中进行undo页的申请。
undo页的重用:如果为每个事务分配一个页(一页默认16K),且每秒处理1000个事务,那么每秒就需要16K*1000=16M的空间,运行时间长了就会导致磁盘空间的浪费。
重用表示多个事务共用一页,如果事务提交后,则不会立即删除undo页,而是被挂到链表中,对其已使用空间进行判断。
- 已使用空间大于等于
3/4,回收 - 已使用空间小于
3/4,继续被重用。
2.3.2、回滚段与事务
- 每个事务只会使用一个回滚段,一个回滚段在同一时刻可能会服务于多个事务
- 在事务开始时,会制定一个回滚段,在事务进行中发生数据修改,原始数据会复制到回滚段。
- 在回滚段中,事务会不断填充盘区,不够用时请求下一盘区,盘区用完覆盖初始盘区。
- 回滚段存在于undo表空间,数据库中可以存在多个undo表空间,但同一时刻只能使用一个undo表空间。
补充:purge线程
作用:
- 清理undo页
- 对页里的数据行打标签从而进行假删除。

——Rancher部署Nginx(单机版))




![[蓝桥杯 2019 省 B] 特别数的和](http://pic.xiahunao.cn/[蓝桥杯 2019 省 B] 特别数的和)

)

)



)


)

