引言
在【Redis教程0x03】中,我们介绍了Redis中常用的5种基础数据类型,我们再来回顾一下它们的使用场景:
- String:存储对象、url、计数、分布式锁;
- List:消息队列;
- Hash:存储对象、购物车;
- Set:统计点赞、共同关注、抽奖;
- Zset:排行榜、电话排序;
回顾完毕,那么本篇博客我们将详细介绍一下Redis中的四种高级数据类型:BitMap、HyperLogLog、GEO、Stream。
高级数据类型
位图BitMap
BitMap是一串连续的二进制数组(0和1),可以通过偏移量offset定位元素。BitMap通过最小单位bit进行0|1的设置,表示某个元素的值或者状态。
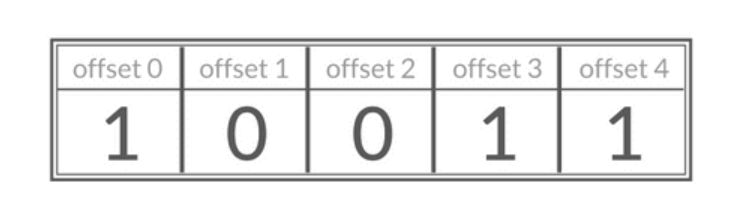
内部实现
BitMap本身是用String类型作为底层数据结构实现的一种统计二进制值状态的数据类型。之前我们说过String是二进制安全的,最大长度512MB,所以BitMap的最多位数为2^32。
常用操作
位图的基本操作:
# 设置offset位置的值,其中value只能是 0 和 1
SETBIT key offset value# 获取offset位置的值
GETBIT key offset# 获取指定范围内值为 1 的个数
# start 和 end 以字节为单位
BITCOUNT key start end
位图的运算操作:
# BitMap间的运算
# operations 位移操作符,枚举值
# AND 与运算 &
# OR 或运算 |
# XOR 异或 ^
# NOT 取反 ~
# result 计算的结果,会存储在该key中
# key1 … keyn 参与运算的key,可以有多个,空格分割,not运算只能一个key
# 当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0。返回值是保存到 destkey 的字符串的长度(以字节byte为单位),和输入 key 中最长的字符串长度相等。
BITOP [operations] [result] [key1] [keyn…]# 返回指定key中第一次出现指定value(0/1)的位置
BITPOS [key] [value]
应用场景
BitMap由于使用比特位统计,所以十分节省空间。
- 签到统计
每个用户一天的签到用1个bit位就能表示,一个月只要31个bit就好。假如统计ID 108的用户在2024年3月16号的签到情况:
设置签到:
SETBIT uid:sign:108:202403 15 1
检查签到:
GETBIT uid:sign:108:202403 15
统计签到数:
BITCOUNT uid:sign:108:202403
获取首次打卡的时间:
# 返回指定key中首次值为1的offset
BITPOS uid:sign:108:202403 1
- 判断用户登录态
只需要一个 key = login_status 表示存储用户登陆状态集合数据, 将用户 ID 作为 offset,在线就设置为 1,下线设置 0。通过 GETBIT判断对应的用户是否在线。 5000 万用户只需要 6 MB 的空间。
# 用户10055上线了
SETBIT login_status 10055 1# 检查用户是否登录
GETBIT login_status 10055# 用户10055下线了
SETBIT login_status 10055 0
- 连续签到用户总数
如果统计出连续7天都打卡的用户总数呢?
把每天的日期作为 Bitmap 的 key,userId 作为 offset,若是打卡则将 offset 位置的 bit 设置成 1。key 对应的集合的每个 bit 位的数据则是一个用户在该日期的打卡记录。一共有 7 个这样的 Bitmap,如果我们能对这 7 个 Bitmap 的对应的 bit 位做 『与』运算。同样的 UserID offset 都是一样的,当一个 userID 在 7 个 Bitmap 对应对应的 offset 位置的 bit = 1 就说明该用户 7 天连续打卡。结果保存到一个新 Bitmap 中,我们再通过 BITCOUNT 统计 bit = 1 的个数便得到了连续打卡 7 天的用户总数了。
Redis 提供了 BITOP operation destkey key [key …]这个指令用于对一个或者多个 key 的 Bitmap 进行位元操作。
operation 可以是 and、OR、NOT、XOR。当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0 。空的 key 也被看作是包含 0 的字符串序列。假设要统计 3 天连续打卡的用户数,则是将三个 bitmap 进行 AND 操作,并将结果保存到 destmap 中,接着对 destmap 执行 BITCOUNT 统计,如下命令:
# 与操作
BITOP AND destmap bitmap:01 bitmap:02 bitmap:03
# 统计 bit 位 = 1 的个数
BITCOUNT destmap
即使一天产生一个亿的数据,Bitmap 占用的内存也不大,大约占 12 MB 的内存(10^8/8/1024/1024),7 天的 Bitmap 的内存开销约为 84 MB。同时我们最好给 Bitmap 设置过期时间,让 Redis 删除过期的打卡数据,节省内存。
基数统计HyperLogLog
介绍
Redis HyperLogLog是Redis 2.8.9新增的数据类型,是一种用于基数统计的数据集合类型,基数统计就是指统计一个集合中不重复的元素个数。但要注意的是,HyperLogLog的统计规则是基于概览完成的,误算率为0.81%。
简单来说,HyperLogLog就是提供不精确的去重计数。
HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的内存空间总是固定的、并且是很小的。只需要 12k 的空间就能存储接近**2^64**个不同元素。和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。
内部实现
HyperLogLog 是一种有名的基数计数概率算法 ,基于 LogLog Counting(LLC)优化改进得来,并不是 Redis 特有的,Redis 只是实现了这个算法并提供了一些开箱即用的 API。具体的算法原理就不多赘述了,纯数学问题,比较烧脑。
当然,Redis对HyperLogLog也做了些优化,采用两种方式计数:
- 稀疏矩阵:计数较少时,占用空间很小;
- 稠密矩阵:计数达到某个阈值,占用12KB的空间;
常用命令
HyperLogLog的常用命令较少:
# 添加指定元素到 HyperLogLog 中
PFADD key element [element ...]# 返回给定 HyperLogLog 的基数估算值。
PFCOUNT key [key ...]# 将多个 HyperLogLog 合并为一个 HyperLogLog
PFMERGE destkey sourcekey [sourcekey ...]
应用场景
- 百万计网页UV计数
HyperLogLog 优势在于只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。所以,非常适合统计百万级以上的网页 UV 的场景。
在统计 UV 时,可以用 PFADD 命令(用于向 HyperLogLog 中添加新元素)把访问页面的每个用户都添加到 HyperLogLog 中。
PFADD page1:uv user1 user2 user3 user4 user5
接下来,就可以用 PFCOUNT 命令直接获得 page1 的 UV 值了,这个命令的作用就是返回 HyperLogLog 的统计结果。
PFCOUNT page1:uv
有一点需要注意一下,HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型。
地理位置GEO
介绍
GEO(地理空间索引,Geospatial index)主要用于存储地理位置信息,基于 Sorted Set 实现。通过 GEO 我们可以轻松实现两个位置距离的计算、获取指定位置附近的元素等功能。在日常生活中,我们越来越依赖搜索“附近的餐馆”、在打车软件上叫车,这些都离不开基于位置信息服务(Location-Based Service,LBS)的应用。LBS 应用访问的数据是和人或物关联的一组经纬度信息,而且要能查询相邻的经纬度范围,GEO 就非常适合应用在 LBS 服务的场景中。
内部实现
GEO 本身并没有设计新的底层数据结构,而是直接使用了 Sorted Set 集合类型。
GEO 类型使用 GeoHash 编码方法实现了经纬度到 Sorted Set 中元素权重分数的转换,这其中的两个关键机制就是「对二维地图做区间划分」和「对区间进行编码」。一组经纬度落在某个区间后,就用区间的编码值来表示,并把编码值作为 Sorted Set 元素的权重分数。
这样一来,我们就可以把经纬度保存到 Sorted Set 中,利用 Sorted Set 提供的“按权重进行有序范围查找”的特性,实现 LBS 服务中频繁使用的“搜索附近”的需求。
常用命令
# 存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。
GEOADD key longitude latitude member [longitude latitude member ...]# 从给定的 key 里返回所有指定名称(member)的位置(经度和纬度),不存在的返回 nil。
GEOPOS key member [member ...]# 返回两个给定位置之间的距离。
GEODIST key member1 member2 [m|km|ft|mi]# 根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
给个例子:
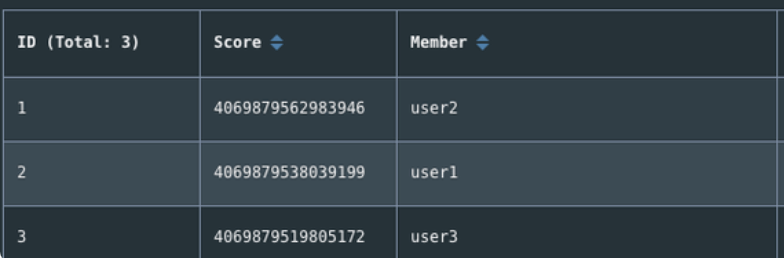
> GEOADD personLocation 116.33 39.89 user1 116.34 39.90 user2 116.35 39.88 user3
3
> GEOPOS personLocation user1
116.3299986720085144
39.89000061669732844
> GEODIST personLocation user1 user2 km
1.4018
通过可是工具查看,可以发现底层实现就是Zset,GEO 中存储的地理位置信息的经纬度数据通过 GeoHash 算法转换成了一个整数,这个整数作为 Sorted Set 的 score(权重参数)使用。
应用场景
- 滴滴打车
这里以滴滴叫车的场景为例,介绍下具体如何使用 GEO 命令:GEOADD 和 GEORADIUS 这两个命令。
假设车辆 ID 是 33,经纬度位置是(116.034579,39.030452),我们可以用一个 GEO 集合保存所有车辆的经纬度,集合 key 是 cars:locations。
执行下面的这个命令,就可以把 ID 号为 33 的车辆的当前经纬度位置存入 GEO 集合中:
GEOADD cars:locations 116.034579 39.030452 33
当用户想要寻找自己附近的网约车时,LBS 应用就可以使用 GEORADIUS 命令。例如,LBS 应用执行下面的命令时,Redis 会根据输入的用户的经纬度信息(116.054579,39.030452 ),查找以这个经纬度为中心的 5 公里内的车辆信息,并返回给 LBS 应用。
GEORADIUS cars:locations 116.054579 39.030452 5 km ASC COUNT 10
消息队列Stream
介绍
Stream 是 Redis 5.0 版本新增加的数据类型,Redis 专门为消息队列设计的数据类型。在 Redis 5.0 Stream 没出来之前,消息队列的实现方式都有着各自的缺陷,例如:
- 发布订阅模式,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息的缺陷;
- List 实现消息队列的方式不能重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一 ID。
基于以上问题,Redis 5.0 便推出了 Stream 类型也是此版本最重要的功能,用于完美地实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持 ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠。
常用命令
Stream 消息队列操作命令:
- XADD:插入消息,保证有序,可以自动生成全局唯一 ID;
- XLEN :查询消息长度;
- XREAD:用于读取消息,可以按 ID 读取数据;
- XDEL : 根据消息 ID 删除消息;
- DEL :删除整个 Stream;
- XRANGE :读取区间消息
- XREADGROUP:按消费组形式读取消息;
- XPENDING 和 XACK:
- XPENDING 命令可以用来查询每个消费组内所有消费者「已读取、但尚未确认」的消息;
- XACK 命令用于向消息队列确认消息处理已完成;
应用场景
消息队列
生产者通过 XADD 命令插入一条消息:
# * 表示让 Redis 为插入的数据自动生成一个全局唯一的 ID
# 往名称为 mymq 的消息队列中插入一条消息,消息的键是 name,值是 iq50
> XADD mymq * name iq50
"1654254953808-0"
插入成功后会返回全局唯一的 ID:“1654254953808-0”。消息的全局唯一 ID 由两部分组成:
- 第一部分“1654254953808”是数据插入时,以毫秒为单位计算的当前服务器时间;
- 第二部分表示插入消息在当前毫秒内的消息序号,这是从 0 开始编号的。例如,“1654254953808-0”就表示在“1654254953808”毫秒内的第 1 条消息。
消费者通过 XREAD 命令从消息队列中读取消息时,可以指定一个消息 ID,并从这个消息 ID 的下一条消息开始进行读取(注意是输入消息 ID 的下一条信息开始读取,不是查询输入ID的消息)。
# 从 ID 号为 1654254953807-0 的消息开始,读取后续的所有消息(示例中一共 1 条)。
> XREAD STREAMS mymq 1654254953807-0
1) 1) "mymq"2) 1) 1) "1654254953808-0"2) 1) "name"2) "iq50"
如果想要实现阻塞读(当没有数据时,阻塞住),可以调用 XRAED 时设定 BLOCK 配置项,实现类似于 BRPOP 的阻塞读取操作。
比如,下面这命令,设置了 BLOCK 10000 的配置项,10000 的单位是毫秒,表明 XREAD 在读取最新消息时,如果没有消息到来,XREAD 将阻塞 10000 毫秒(即 10 秒),然后再返回。
# 命令最后的“$”符号表示读取最新的消息
> XREAD BLOCK 10000 STREAMS mymq $
(nil)
(10.00s)
Stream 的基础方法,使用 xadd 存入消息和 xread 循环阻塞读取消息的方式可以实现简易版的消息队列,交互流程如下图所示:

OK,上面的这些操作List也能支持,接下来看看Stream独有的功能。
Stream 可以以使用 XGROUP 创建消费组,创建消费组之后,Stream 可以使用 XREADGROUP 命令让消费组内的消费者读取消息。
创建两个消费组,这两个消费组消费的消息队列是 mymq,都指定从第一条消息开始读取:
# 创建一个名为 group1 的消费组,0-0 表示从第一条消息开始读取。
> XGROUP CREATE mymq group1 0-0
OK
# 创建一个名为 group2 的消费组,0-0 表示从第一条消息开始读取。
> XGROUP CREATE mymq group2 0-0
OK
消费组 group1 内的消费者 consumer1 从 mymq 消息队列中读取所有消息的命令如下:
# 命令最后的参数“>”,表示从第一条尚未被消费的消息开始读取。
> XREADGROUP GROUP group1 consumer1 STREAMS mymq >
1) 1) "mymq"2) 1) 1) "1654254953808-0"2) 1) "name"2) "iq50"
消息队列中的消息一旦被消费组里的一个消费者读取了,就不能再被该消费组内的其他消费者读取了,即同一个消费组里的消费者不能消费同一条消息。
比如说,我们执行完刚才的 XREADGROUP 命令后,再执行一次同样的命令,此时读到的就是空值了:
> XREADGROUP GROUP group1 consumer1 STREAMS mymq >
(nil)
但是,不同消费组的消费者可以消费同一条消息(但是有前提条件,创建消息组的时候,不同消费组指定了相同位置开始读取消息)。
比如说,刚才 group1 消费组里的 consumer1 消费者消费了一条 id 为 1654254953808-0 的消息,现在用 group2 消费组里的 consumer1 消费者消费消息:
> XREADGROUP GROUP group2 consumer1 STREAMS mymq >
1) 1) "mymq"2) 1) 1) "1654254953808-0"2) 1) "name"2) "iq50"
因为我创建两组的消费组都是从第一条消息开始读取,所以可以看到第二组的消费者依然可以消费 id 为 1654254953808-0 的这一条消息。因此,不同的消费组的消费者可以消费同一条消息。
使用消费组的目的是让组内的多个消费者共同分担读取消息,所以,我们通常会让每个消费者读取部分消息,从而实现消息读取负载在多个消费者间是均衡分布的。
Question:基于 Stream 实现的消息队列,如何保证消费者在发生故障或宕机再次重启后,仍然可以读取未处理完的消息?
Streams 会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息,直到消费者使用 XACK 命令通知 Streams“消息已经处理完成”。消费确认增加了消息的可靠性,一般在业务处理完成之后,需要执行 XACK 命令确认消息已经被消费完成,整个流程的执行如下图所示:

如果消费者没有成功处理消息,它就不会给 Streams 发送 XACK 命令,消息仍然会留存。此时,消费者可以在重启后,用 XPENDING 命令查看已读取、但尚未确认处理完成的消息。
让我们小结一下:
- 消息保序:XADD/XREAD
- 阻塞读取:XREAD block
- 重复消息处理:Stream 在使用 XADD 命令,会自动生成全局唯一 ID;
- 消息可靠性:内部使用 PENDING List 自动保存消息,使用 XPENDING 命令查看消费组已经读取但是未被确认的消息,消费者使用 XACK 确认消息;
- 支持消费组形式消费数据
对比专业的MQ
Question:Redis 基于 Stream 消息队列与专业的消息队列有哪些差距?
一个专业的消息队列,必须要做到两大块:
- 消息不丢。
- 消息可堆积。
- Redis Stream消息会丢失吗?
使用一个消息队列,其实就分为三大块:生产者、队列中间件、消费者,所以要保证消息就是保证三个环节都不能丢失数据。
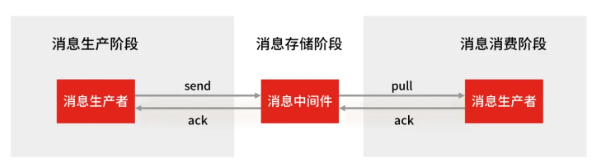
Redis 在消息中间件会不会丢消息?会,Redis 在以下 2 个场景下,都会导致数据丢失:
- AOF 持久化配置为每秒写盘,但这个写盘过程是异步的,Redis 宕机时会存在数据丢失的可能
- 主从复制也是异步的,主从切换时,也存在丢失数据的可能。
Redis 在队列中间件环节无法保证消息不丢。像 RabbitMQ 或 Kafka 这类专业的队列中间件,在使用时是部署一个集群,生产者在发布消息时,队列中间件通常会写「多个节点」,也就是有多个副本,这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失。
- Redis Stream消息可堆积吗?
Redis 的数据都存储在内存中,这就意味着一旦发生消息积压,则会导致 Redis 的内存持续增长,如果超过机器内存上限,就会面临被 OOM 的风险。
所以 Redis 的 Stream 提供了可以指定队列最大长度的功能,就是为了避免这种情况发生。当指定队列最大长度时,队列长度超过上限后,旧消息会被删除,只保留固定长度的新消息。这么来看,Stream 在消息积压时,如果指定了最大长度,还是有可能丢失消息的。
但 Kafka、RabbitMQ 专业的消息队列它们的数据都是存储在磁盘上,当消息积压时,无非就是多占用一些磁盘空间。
综上,把 Redis 当作队列来使用时,会面临的 2 个问题:
- Redis 本身可能会丢数据;
- 面对消息挤压,内存资源会紧张;
所以,能不能将 Redis 作为消息队列来使用,关键看你的业务场景:
- 如果你的业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的。
- 如果你的业务有海量消息,消息积压的概率比较大,并且不能接受数据丢失,那么还是用专业的消息队列中间件吧。
总结
本篇博客详细介绍了Redis的四种高级数据类型,后面我们会对Redis进行更多讨论,敬请期待。













:当今最大品牌背后的沉默劳动力)


)
)
(4)(数组)(万字详解版))
![[C++] 类型转换操作符(static_cast、dynamic_cast、const_cast、reinterpret_cast)](http://pic.xiahunao.cn/[C++] 类型转换操作符(static_cast、dynamic_cast、const_cast、reinterpret_cast))