1.代码看现象引入
#include<stdio.h>#include<unistd.h>#include<string.h> #include<stdlib.h>int val=100;int main (){ printf("i am father,pid:%d,ppid:%d,val:%d,&val:%p\n",getpid(),getppid(),val,&val);size_t id=fork();if(id==0){int cnt=0;while(1){printf("i am child,pid:%d,ppid:%d,val:%d,&val:%p\n",getpid(),getppid(),val,&val);cnt++;sleep(1);if(cnt==5) {val=300;}}}else { while(1){ printf("i am father,pid:%d,ppid:%d,val:%d,&val:%p\n",getpid(),getppid(),val,&val);sleep(1);}} } 代码解释:定义一个全局变量,然后创建子进程,让子进程在5秒开始修改这个值,观察子进程和父进程这个全局变量是否一样
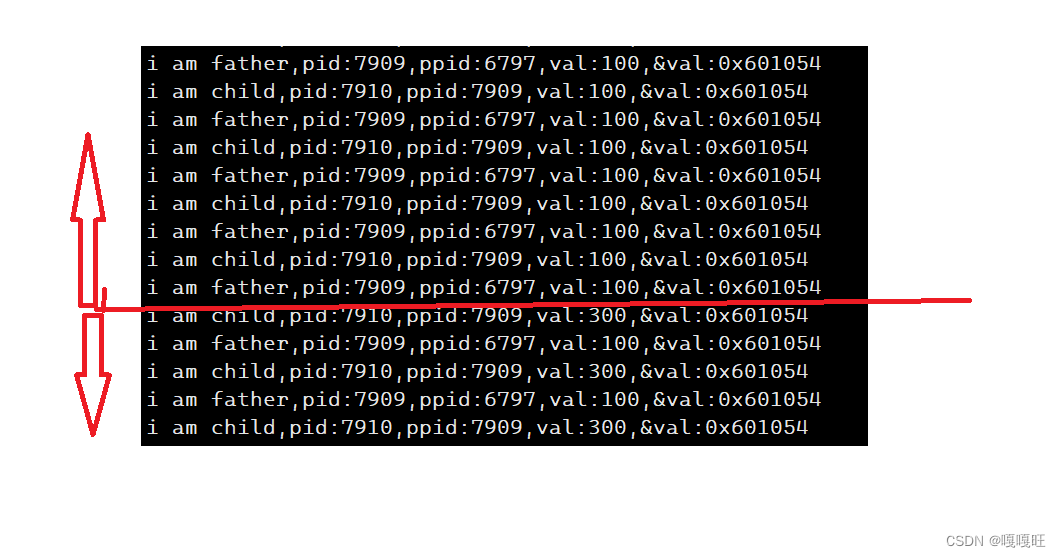
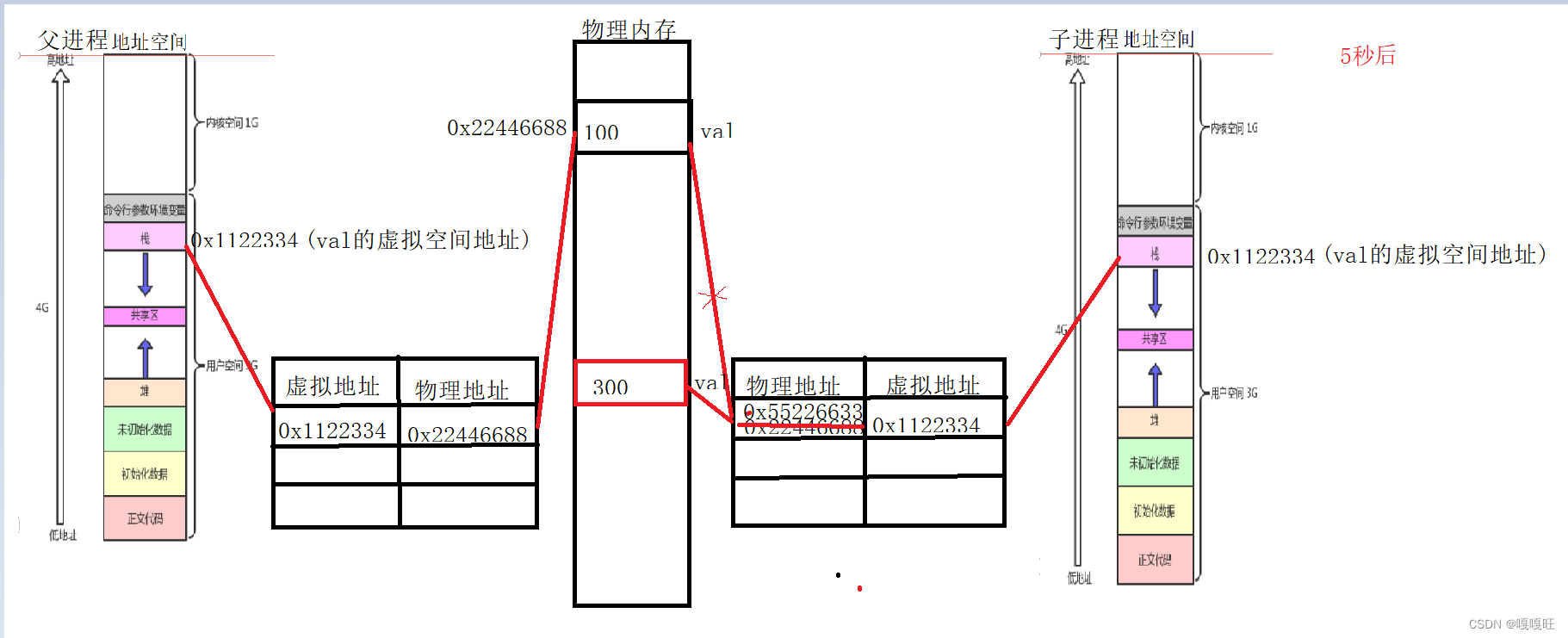
我们发现val变量子进程和父进程的值不一样,这个我们可以理解,因为进程的独立性,导致父进程和子进程的val不一样,但是为什么val两个的地址还是一样的
解释:这里的地址并非物理地址,同一个物理地址只可能出现一个值,这里的地址其实是进程的地址空间,也叫做虚拟地址。
2.虚拟空间的理解
当我们有进程执行的时候,会将代码和数据从磁盘加载到物理内存中去,操作系统会对这个进程创建一个进程task_struct来描述这个进程,而这个对应进程的pcb中存在的是这个进程的地址空间的地址,这里的地址空间就是我们之前学过的包括命令行参数和环境变量的虚拟地址,栈的虚拟地址,堆的虚拟地址,以及初始化数据的虚拟地址,以及正文代码的虚拟地址,而这些虚拟地址怎么找到该变量的实际地址也就是物理地址呢??这里就要提到一个叫页表的东西,页表将变量的虚拟地址和物理内存的实际地址对应上了,下面画图带大家理解一下
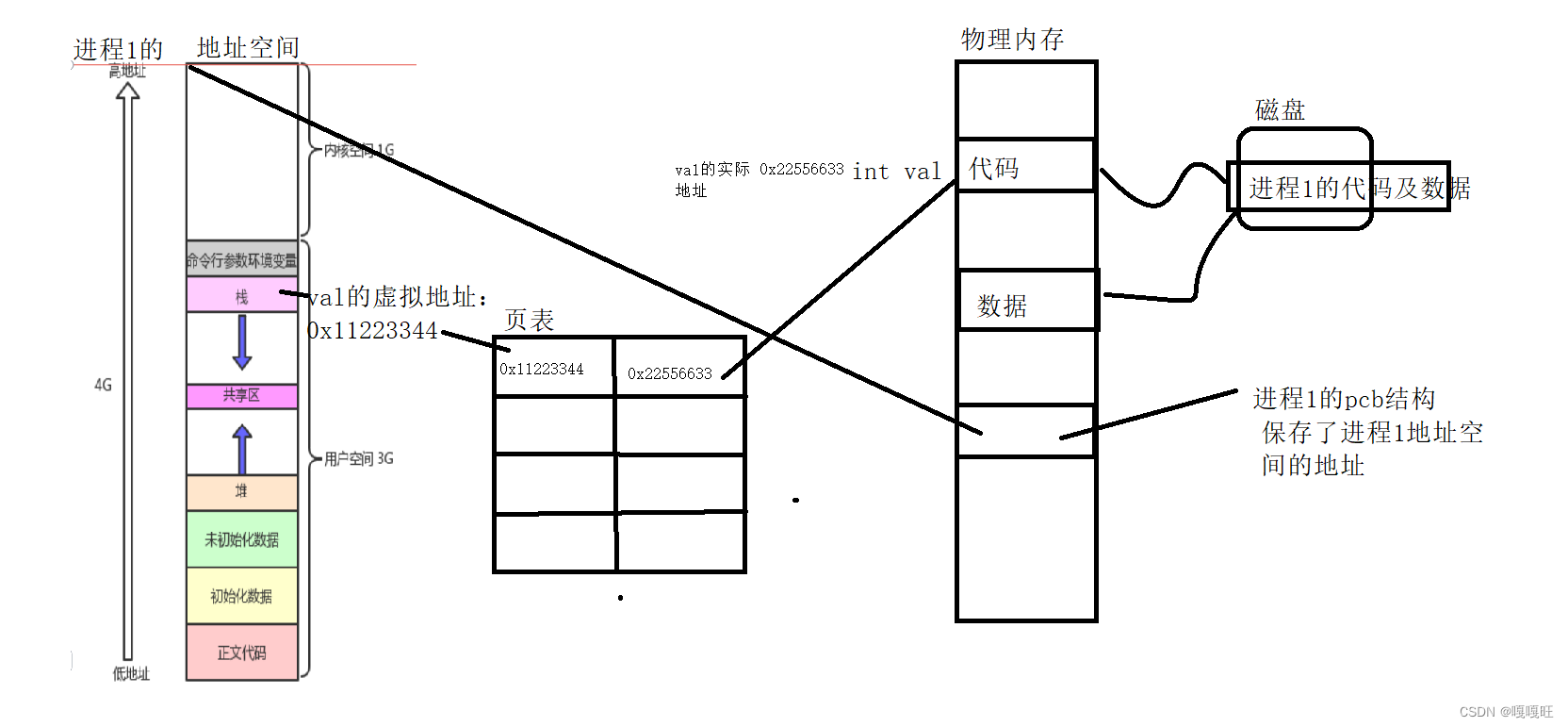
而对于地址空间,到底是什么东西呢??要想理解这个地址空间,我们可以先来理解一下什么是划分区域。
当我们有一个长100cm的桌子,你和你·同桌要划分三八线,你两一人50cm,然后过了几天,然后你和你同桌商量将你的地盘多加20,然后你就有70cm长,然后他只有30cm,实现了区域的调整。
那如何通过计算机语言来实现呢?
我们可以先定义一个结构体,来确定一个人的边界
struct area
{
int start;
int end;}
struct area destop
{struct area left;struct area right;
}
struct area destop res;
res.left.start=0;
res.left.end=50;
res.right.start=50;
res.right.start=100;
//如果要变化
res.left.end+=20;
res.right.start-=20;实际上地址空间本质就是一个结构体对象,里面存了好多虚拟地址的范围,给大家看一下linux里面的地址空间的结构
struct mm_struct
{unsigned long start_code; // 代码段的开始地址unsigned long end_code; // 代码段的结束地址unsigned long start_data; // 数据的首地址unsigned long end_data; // 数据的尾地址unsigned long start_brk; // 堆的首地址unsigned long brk; // 堆的尾地址unsigned long start_stack; // 进程栈的首地址//...
};假如我要在堆区申请空间,由于堆是向上生长,所以他申请的空间时,会让start_brk–
腾出要申请空间的大小
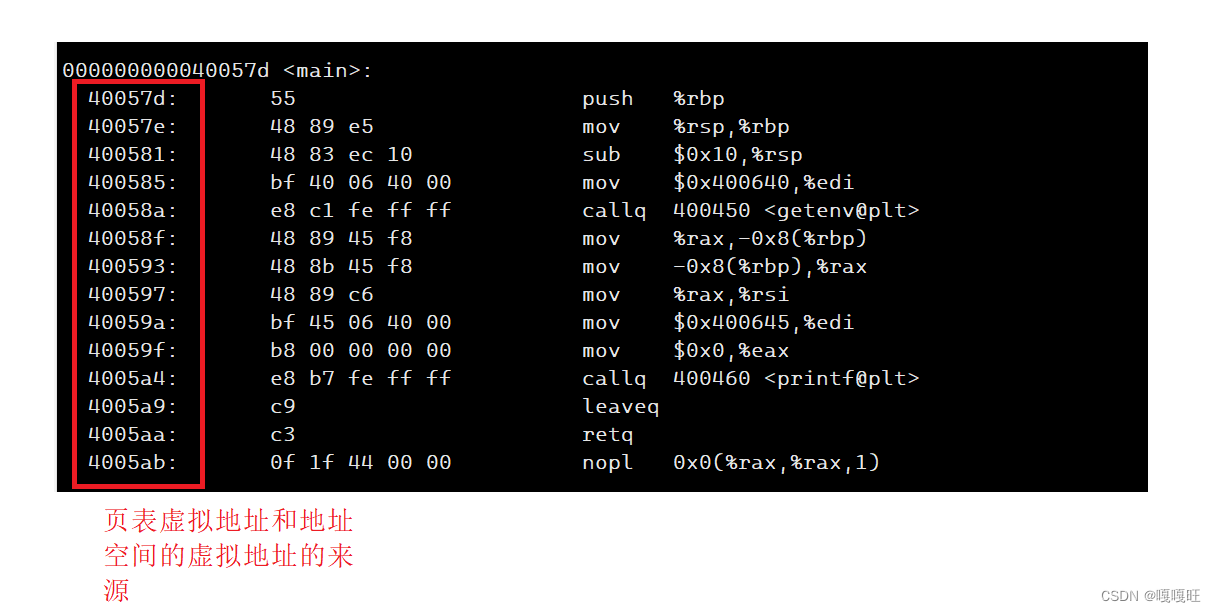
地址空间上的虚拟地址和页表上的地址信息是从哪里来的呢??
实际上页表上的地址和地址空间的地址来自于程序
我们可以通过下面的指令查看反汇编
objdump -S 可执行程序的名称
3.接着利用现有的虚拟空间的理解来解释上面的代码父子进程全局变量的虚拟地址为啥相同
父进程创建子进程时,会继承父进程的基本所有数据,当然不包括pid,ppid以及其他的.比方说拷贝父进程地地址空间,以及父进程的页表,下面画图来理解一下
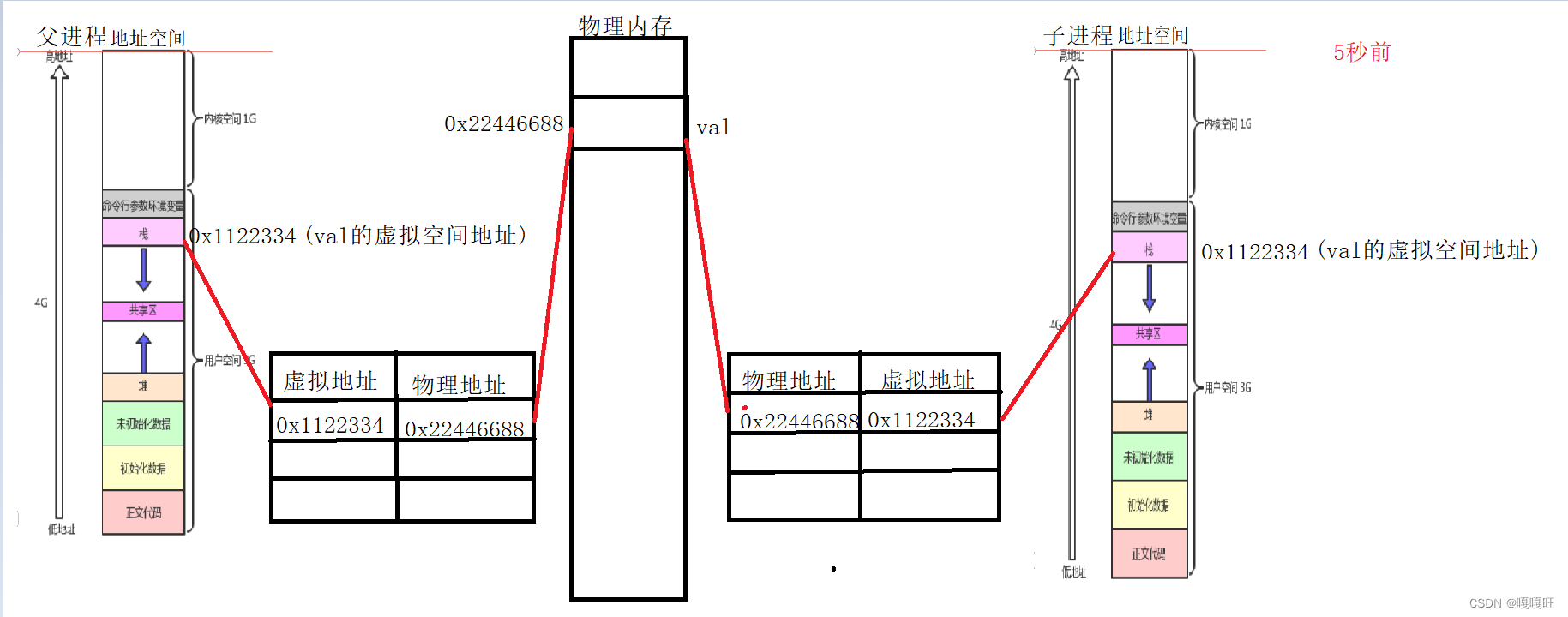
这种拷贝在c++中我们学过叫浅拷贝,我们之前为了防止这种浅拷贝在析构的时候析构多次出现错误,我们引入了一个概念叫引用计数,当计数值大于1时说明该空间被多个虚拟地址共享,我们当引用计数为1时在析构,就解决了了当时的问题,而子进程要进行修改这个变量的时候,操作系统就会使用写时拷贝,给子进程的val在创建一个物理空间,该物理空间里的val值就是子进程修改之后的val,而子进程和父进程的val的虚拟地址一样,但是物理地址不一样,发生了写时拷贝,只有在子进程要修改的时候才进行写时拷贝,通过调整拷贝的时间顺序,达到有效节省空间的目的
#include<stdio.h>#include<unistd.h>#include<string.h> #include<stdlib.h>int main(){size_t id=fork();if(id==0){printf("i am child id:%d,&id:%p\n",id,&id);}else{printf("i am father id:%d,&id:%p\n",id,&id);}}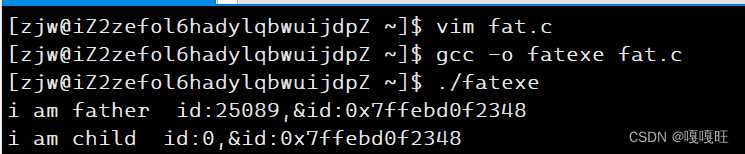
这里我们就懂这段代码了吧
4.为什么要有地址空间
原因1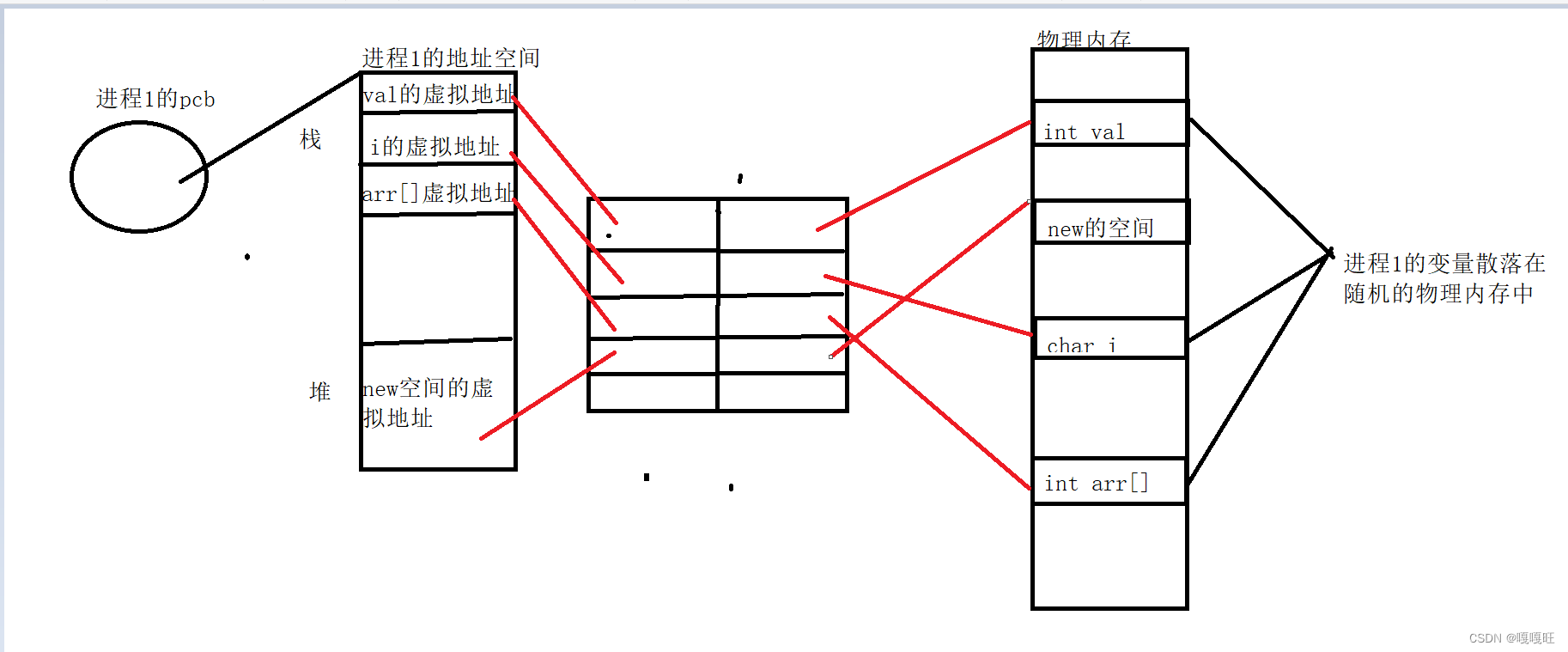
根据图我们可以知道进程1的变量会随机的散落在物理内存中,如果我们将同一类型的变量划分在同一个区域里面会显得特别规整,所以我们引入了地址空间,让无序变成有序,让进程以统一的视角看待物理内存以及自己运行的区域
原因2
当我们实际的某一块物理内存中没有数据,我们在页表里面访问虚拟地址没有对应的物理内存,就会进行拦截非法请求,对物理内存进行保护。
原因3
进程管理模块和内存管理模块进行解耦
5.进一步理解页表和写时拷贝
CR3寄存器:

MMU是一种硬件设备,也称为内存管理单元,它位于计算机系统的中央处理器(CPU)和内存之间。MMU负责处理程序发出的内存访问请求,并将逻辑地址转换为物理地址,实现对内存的管理和保护
这里会让CR3寄存器保存对应进程的页表的起始地址,然后MMU会将地址空间里面的虚拟地址转化为物理地址,填到相应页表中,实现了地址的对应关系
页表不单单只是存虚拟空间和物理空间的地址
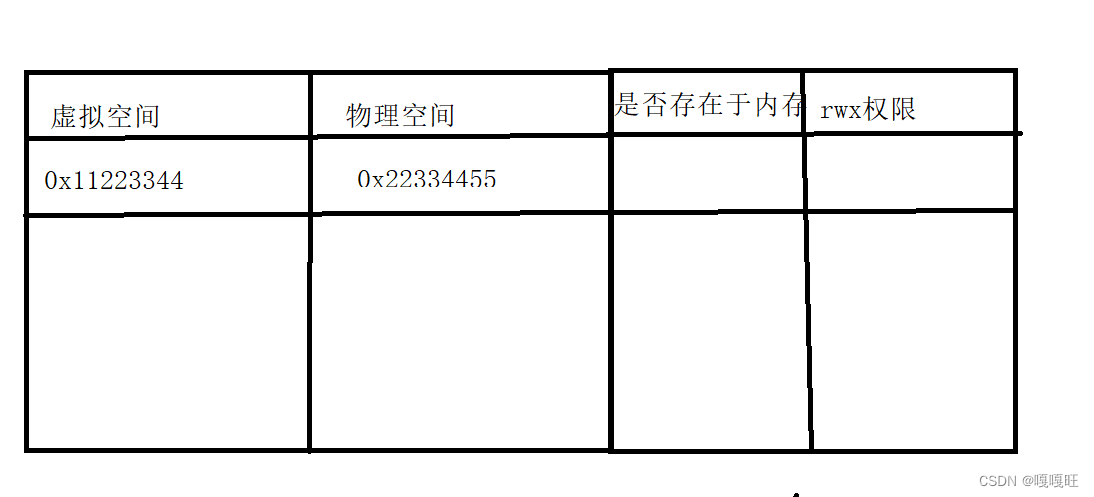
当运行一个进程时,会将他的代码和数据加载进物理内存,我们在上篇文章中提到过,如果内存不足的时候,操作系统会将
长时间不执行的进程的代码和数据挂起,将代码和数据移动到硬盘的swap区,此时在对应页表的是否存在于内存中就可以标记为0。
#include<iostream>
using namespace std;
int main()
{const char* ptr = "hello world"; *ptr="hello";printf("%s", ptr);}
针对上面的代码为什么不行,因为*ptr是在常量区的,对应页表里面的wrx权限里面是没有写权限的,所以不能被修改。
然后我们再次理解第三个问题时,子进程和父进程
当子进程拷贝了父进程的地址空间和页表时,然后val值对应的页表那一栏,wrx权限修改成r(只读)
当子进程要修改时
操作系统会做一下判断,操作系统识别到错误
1.是不是在物理内存里(发生缺页中断)
2.是不是数据需要写时拷贝(发生写时拷贝)
3.如果不是才进行异常处理
6.linux是如何调度的?
我们之前讲优先级默认值为80,然后Nice可以调整优先级,Nice的范围是-20到19
也就说明优先级是60-99的,就是40个优先级
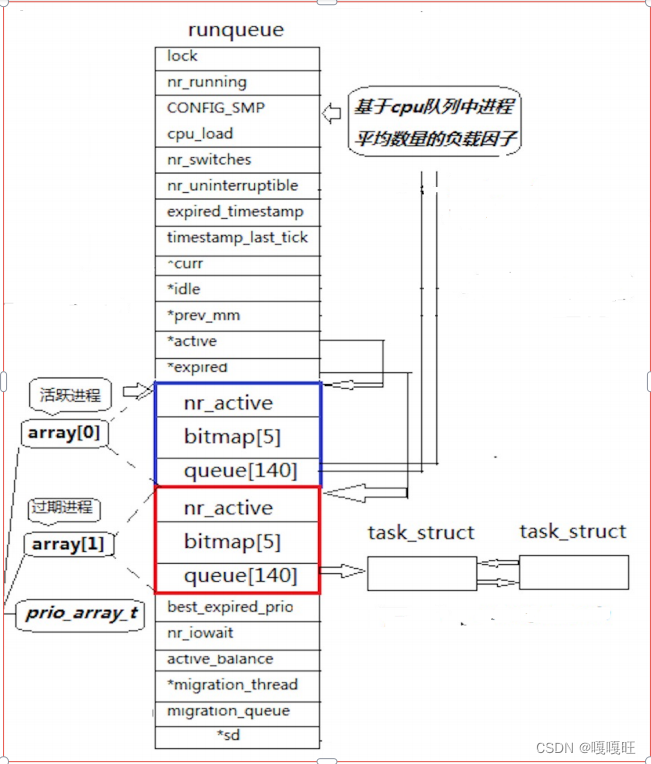
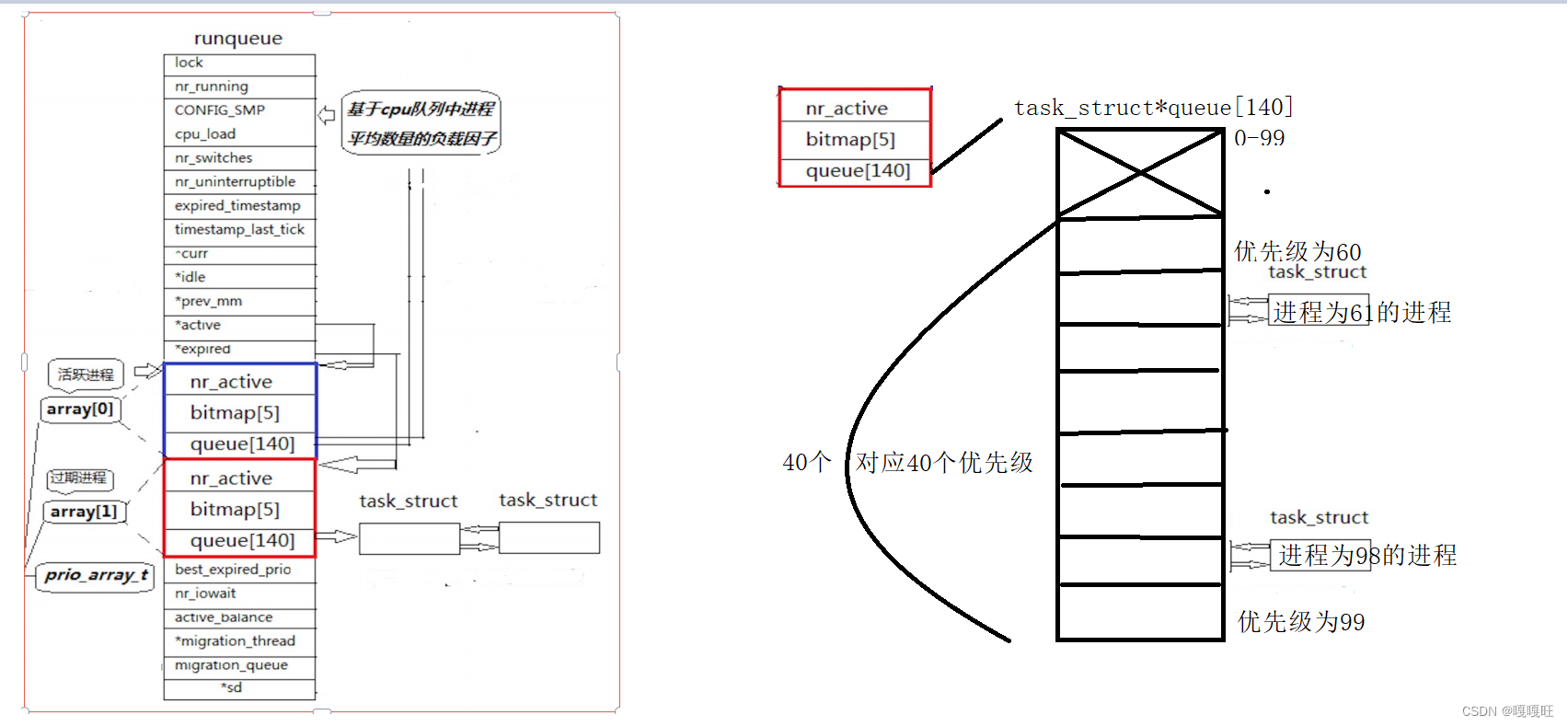
queue是一个指针数组,每一个指针数组里面存放的是对应优先级的进程pcb结构的地址,前100个不用,后面40个正好对应40个优先级,当运行一个进程时,就将这个进程的pcb结构连接在对应优先级的后面,之前说过各个pcb结构是通过双向链表连接起来。前面的pcb结构存放了后面pcb结构的地址,如果要找出哪个优先级对应的指针数组有pcb结构,难道要挨着遍历吗,这里有一个 long bitmap[5]数组
long 是四个字节,一个可以存放32个比特位,32*5=160
bitmap[0]:00000000 00000000 00000000 00000000 //前32个不用
bitmap[1]:00000000 00000000 00000000 00000000 //前64个不用
bitmap[2]:00000000 00000000 00000000 00000000 //前96个不用
bitmap[3]:0000 //前100个不用 0000 00000000 00000000 00000000
bitmap[4]:00000000 00000000 00000000 00000000然后剩下的40个如果对应优先级上有进程的pcb结构话,就置1,没有就置0,
上面还有一个活跃进程和一个过期进程array[0],array[1]
活跃进程只出不进,过期进程只进不出。
活跃进程里面的进程pcb,如果代码片到了的话,就会将对应的pcb结构放到过期进程中去,如果进程被挂起,也会放到过期进程里面去,然后活跃进程完成他里面的所有进程后,就会交换array[0],array[1]的地址也就是过期进程变成了活跃进程,活跃进程变成了过期进程,而新的进程被加载到内存,是被放到就绪队列中去,我感觉活跃队列是正在运行的队列,而另一个过期队列就是就绪队列,他好像要交换一下,过期队列就成了活跃队列,也就是运行队列。
swap(&array[0],&array[1]);
改变后的指针指向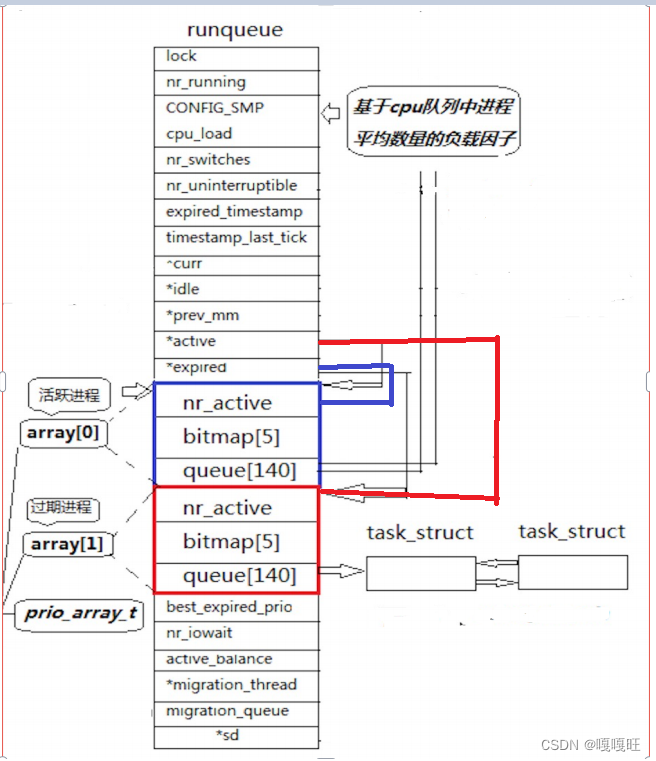
本来是
*active=&array[0];
*expired=&array[1];
改变后是
*active=&array[1];
*expired=&array[0];
我们就可以通过O(1)的时间复杂度来确定哪个优先级上有pcb结构








)






![[Linux初阶]which-find-grep-wc-管道符命令](http://pic.xiahunao.cn/[Linux初阶]which-find-grep-wc-管道符命令)



