提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 1.物化视图
- 什么是物化视图?
- 1.1 普通视图
- ==1.2 物化视图==
- 1.3 优缺点
- 1.4 基本语法
- 1.5 在生产环境中创建物化视图
- 1.6 AggregatingMergeTree 表引擎
- 3.1 概念
- 3.2 AggregatingMergeTree 建表语句
- 3.3 搭配使用 案例
- 物化视图--- 案例1
- 1.原始数据表
- 物化视图---方式1:
- 物化视图---方式2:
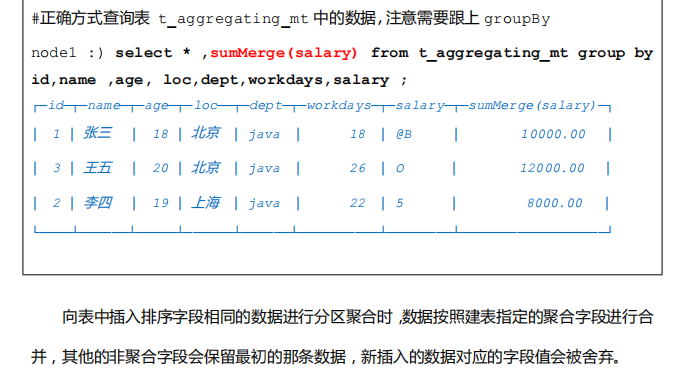
- 为什么查询物化视图 还要GROUP BY +sum ?
- ==在使用 MV 的聚合引擎时,也需要按照聚合查询 配合 GROUP BY 来写sql,因为聚合时机不可控==
- 物化视图---方式3:
- 物化视图--- 案例2
- 1.原始数据表----以Wikistat的10亿行数据集为例:
- 2.创建物化视图
- 3.填充数据
- 4.测试查询 物化视图
- 为什么查询物化视图 还要GROUP BY +sum ?
- ==在使用 MV 的聚合引擎时,也需要按照聚合查询 配合 GROUP BY 来写sql,因为聚合时机不可控==
- 5.更新物化视图中的数据
- ==在使用 MV 的聚合引擎时,也需要按照聚合查询 配合 GROUP BY 来写sql,因为聚合时机不可控==
- 6.使用物化视图加速聚合(AggregatingMergeTree引擎)
- ==在使用 MV 的聚合引擎时,也需要按照聚合查询 配合 GROUP BY 来写sql,因为聚合时机不可控==
- 7.验证和过滤数据
- 8.数据路由到表格
- 9.数据转换
- 10.物化视图和JOIN操作
- ClickHouse博客; [https://blog.csdn.net/ClickHouseDB?type=blog](https://blog.csdn.net/ClickHouseDB?type=blog)
1.物化视图
ClickHouse 中视图分为普通视图和物化视图,两者区别如图所示

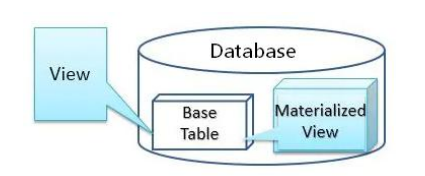
什么是物化视图?
- 物化视图是一种特殊的触发器,当数据被插入时,它将数据上执行 SELECT 查询的结果存储为到一个目标表中:
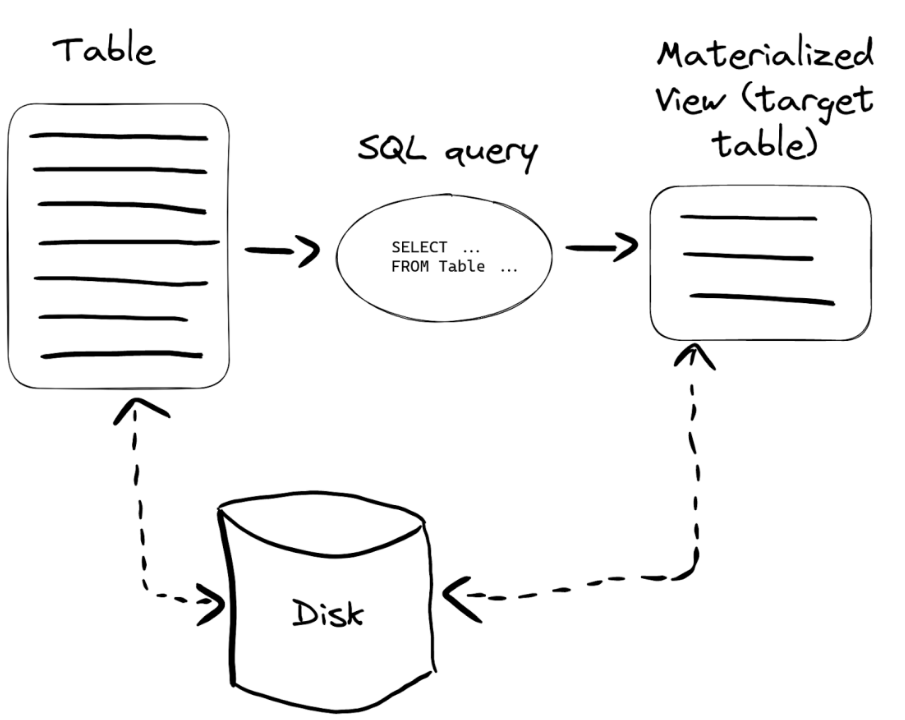
1.1 普通视图
- 普通视图不存储数据,它只是一层 select 查询映射,类似于表的别名或者同义词,能简化查询,对原有表的查询性能没有增强的作用,具体性能依赖视图定义的语句,
- 当从视图中查询时,视图只是替换了映射的查询语句。普通视图当基表删除后不可用。

1.2 物化视图
- 物化视图是查询结果集的一份持久化存储,所以它与普通视图完全不同,而非常趋近于表。”查询结果集”的范围很宽泛,可以是基础表中部分数据的一份简单拷贝,也可以是多 表 join 之后产生的结果或其子集,或者原始数据的聚合指标等等。
- 物化视图创建好之后,若源表被写入新数据则物化视图也会同步更新,POPULATE 关键字决定了物化视图的更新策略,若有 POPULATE 则在创建视图的过程会将源表已经存在的 数据一并导入,类似于 create table … as,若无 POPULATE则物化视图在创建之后 没有数据,只会在创建只有同步之后写入源表的数据,clickhouse 官方并不推荐使用 populated,因为在创建物化视图的过程中同时写入的数据不能被插入物化视图。
- 物化视图是种特殊的数据表,创建时需要指定引擎,可以用 show tables 查看。另外,物化视图不支持 alter 操作。
- 产生物化视图的过程就叫做“物化”(materialization),广义地讲,物化视图是 数据库中的预计算逻辑+显式缓存,典型的空间换时间思路,所以用得好的话,它可以避免 对基础表的频繁查询并复用结果,从而显著提升查询的性能。

1.3 优缺点
优点:查询速度快
缺点:写入过程中消耗较多机器资源,比如带宽占满,存储增加等。本质是一个流式数据的使用场景,是累加式的技术,所以要用历史数据做去重、去核的分析操作不太好用。
1.4 基本语法
创建一个隐藏的目标表来保存视图数据,表名默认是.inner.物化视图名。如果加了TO表名,将保存到显式的表。
create [materialized] view [if not exists] [db.]table_name [to [db.]name]
[engine = engine] [populate]
as select ...限制条件:
- 必须指定物化视图的engine用于数据存储(要么是物化视图,要么是指定的显式表)
- to [db.]table的时候,不得使用populate
- 查询语句可以包含子句:distinct, group by, order by, limit …
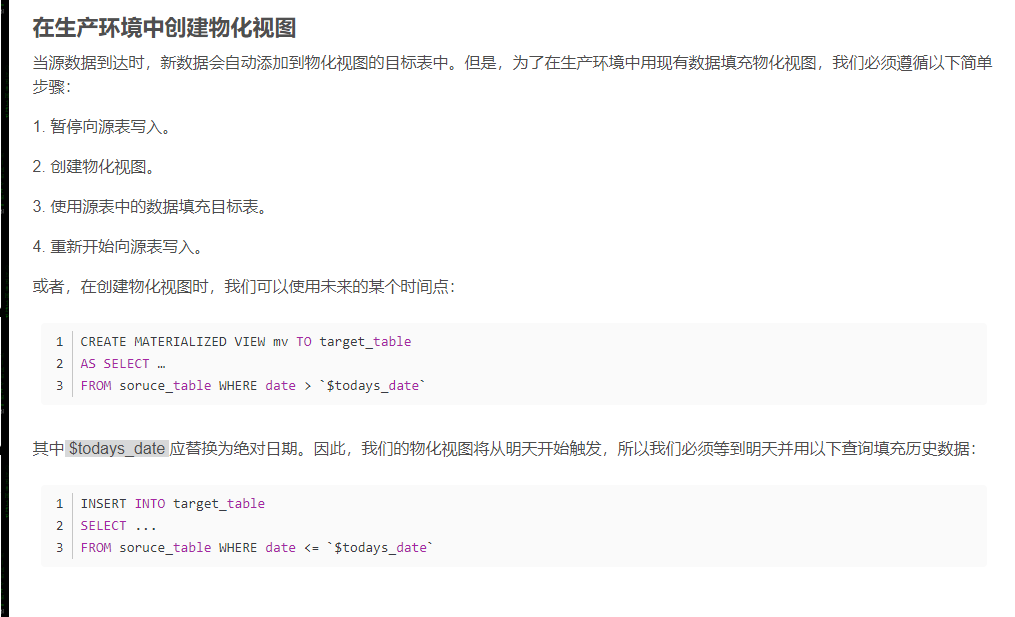
1.5 在生产环境中创建物化视图
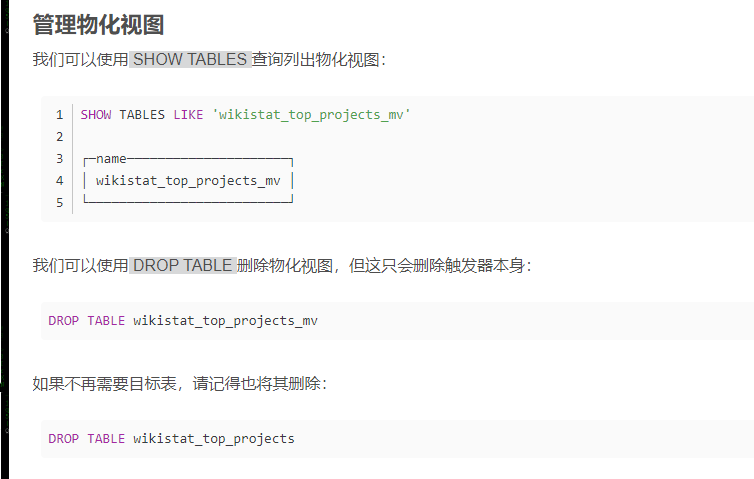
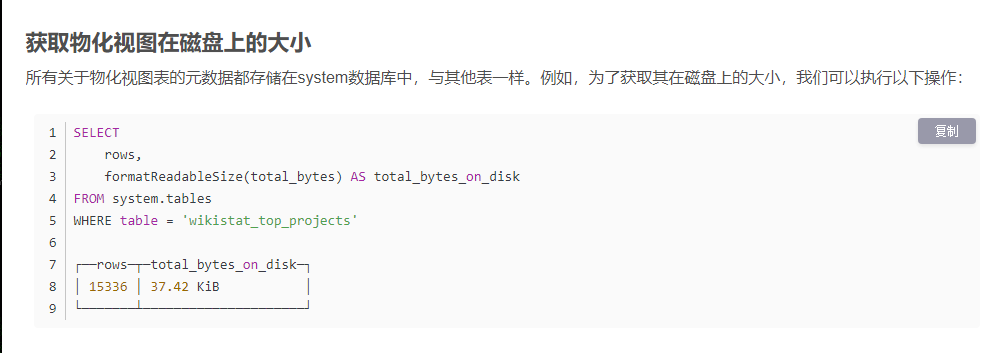
1.6 AggregatingMergeTree 表引擎

3.1 概念
- 该表引擎继承自 MergeTree,可以使用 AggregatingMergeTree表来做增量数据统计聚合。如果要按一组规则来合并减少行数,则使AggregatingMergeTree 是合适的。AggregatingMergeTree 是通过预先定义的聚合函数计算数据并通过二进制的格式存入表内。
- 与 SummingMergeTree 的区别在于:SummingMergeTree 对非主键列进行 sum 聚 合,而 AggregatingMergeTree 则可以指定各种聚合函数。对某些字段需要进行聚合时, 需要在创建表字段时指定成 AggregateFunction 类型
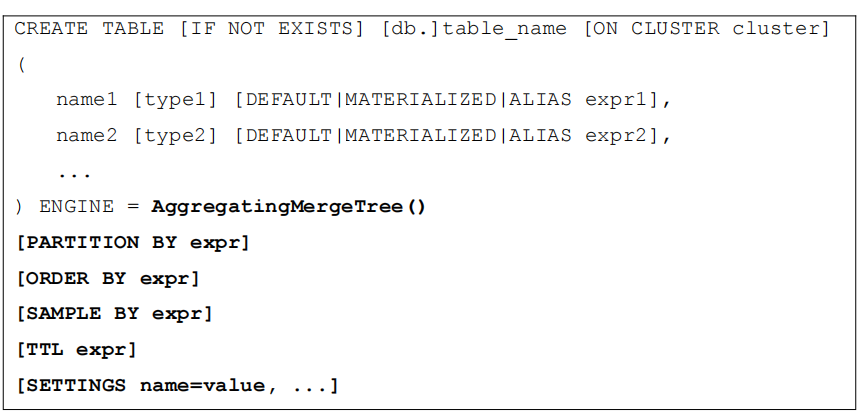
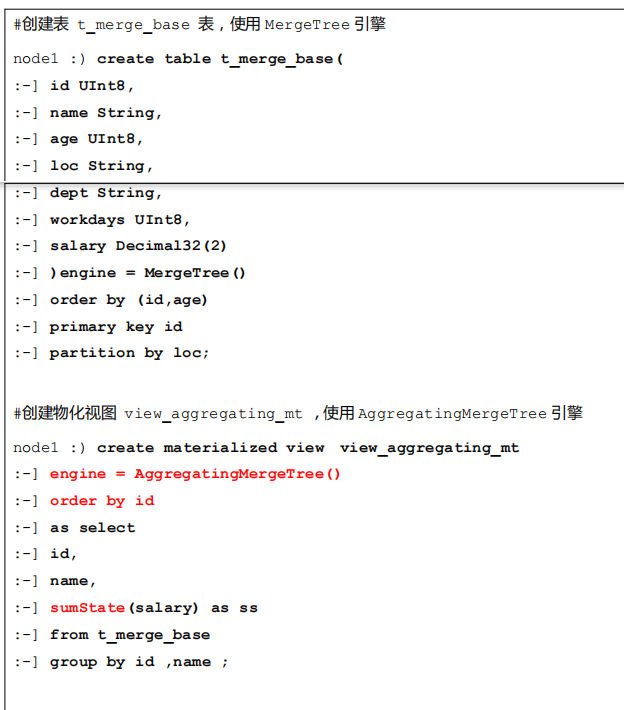
3.2 AggregatingMergeTree 建表语句

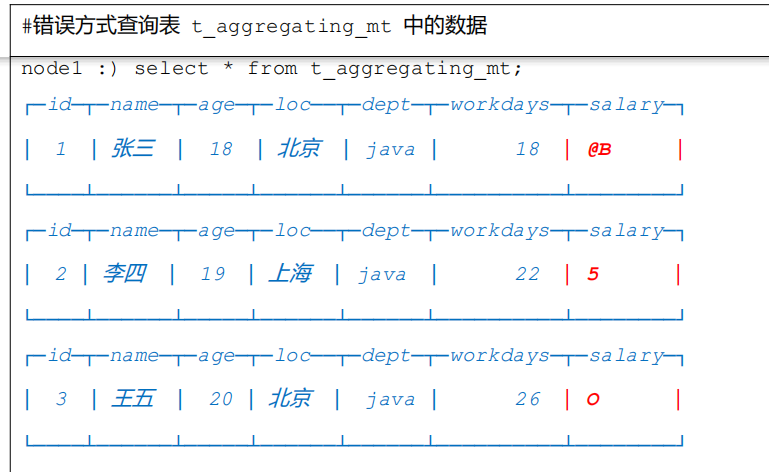
3.3 搭配使用 案例
- 以上方式使用 AggregatingMergeTree 表引擎比较不方便,更多情况下,我们将AggregatingMergeTree 作为物化视图的表引擎与 MergeeTree 搭配使用。
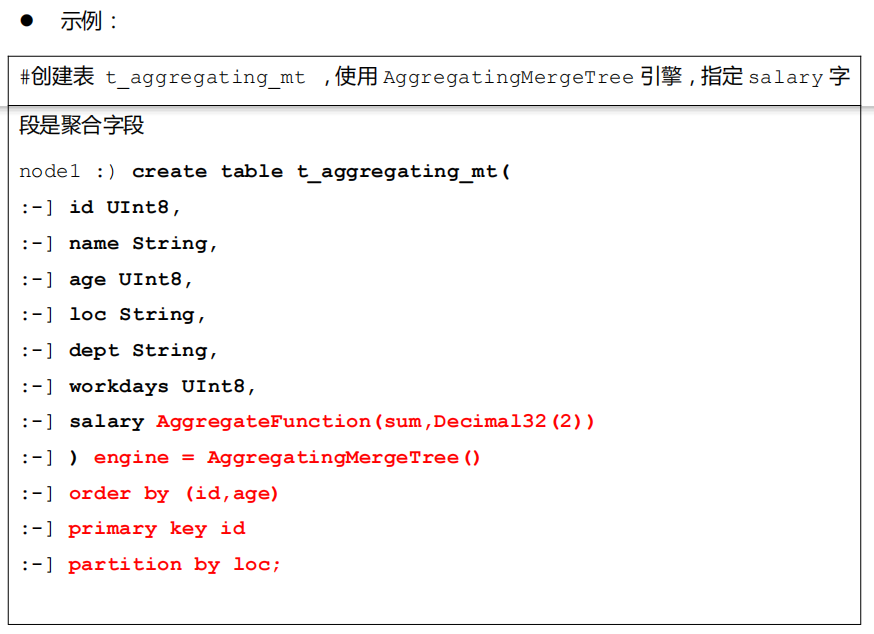
示例:


物化视图— 案例1
1.原始数据表
-- 建表
CREATE TABLE test.tb_mtview_counter (create_time DateTime DEFAULT now(),device UInt32,value Float32
)
ENGINE=MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY (device, create_time);- 插入数据
-- 插入数据
INSERT INTO test.tb_mtview_counter
SELECTtoDateTime('2015-01-01 00:00:00') + toInt64(number/10) AS create_time,(number % 10) + 1 AS device,(device * 3) + (number/10000) + (rand() % 53) * 0.1 AS value
FROM system.numbers LIMIT 100000;-- 查询源表
SELECTtoStartOfMonth(create_time) as day,device,count(*) as count,sum(value) as sum,max(value) as max,min(value) as min,avg(value) as avg
from test.tb_mtview_counter
GROUP BY device, day
ORDER BY day, device;- 数据表查询结果如下:
┌────────day─┬─device─┬─count─┬────────────────sum─┬─────max─┬─────min─┬────────────────avg─┐
│ 2015-01-01 │ 1 │ 10000 │ 106363.50000333786 │ 18.096 │ 3.021 │ 10.636350000333787 │
│ 2015-01-01 │ 2 │ 10000 │ 136010.90005207062 │ 21.1011 │ 6.1701 │ 13.601090005207062 │
│ 2015-01-01 │ 3 │ 10000 │ 166312.0000295639 │ 24.1942 │ 9.0022 │ 16.63120000295639 │
│ 2015-01-01 │ 4 │ 10000 │ 195977.00000858307 │ 27.1783 │ 12.0003 │ 19.597700000858307 │
│ 2015-01-01 │ 5 │ 10000 │ 226182.19993972778 │ 30.1824 │ 15.0284 │ 22.61821999397278 │
│ 2015-01-01 │ 6 │ 10000 │ 256159.19996261597 │ 33.0795 │ 18.0295 │ 25.615919996261596 │
│ 2015-01-01 │ 7 │ 10000 │ 286113.2000026703 │ 36.1976 │ 21.1016 │ 28.61132000026703 │
│ 2015-01-01 │ 8 │ 10000 │ 315845.9000492096 │ 39.0887 │ 24.1237 │ 31.58459000492096 │
│ 2015-01-01 │ 9 │ 10000 │ 345891.30003738403 │ 42.0428 │ 27.0048 │ 34.589130003738404 │
│ 2015-01-01 │ 10 │ 10000 │ 376212.0999965668 │ 45.0789 │ 30.0009 │ 37.62120999965668 │
└────────────┴────────┴───────┴────────────────────┴─────────┴─────────┴────────────────────┘物化视图—方式1:
-- 创建物化视图 -- 没有to table时必须有engine
CREATE MATERIALIZED VIEW test.tb_mtview_counter_daily_mv
ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(day) ORDER BY (device, day)
AS SELECTtoStartOfMonth(create_time) as day,device,count(*) as count,sum(value) as sum,max(value) as max,min(value) as min,avg(value) as avg
FROM test.tb_mtview_counter
WHERE create_time >= toDate('2016-01-01 00:00:00')
GROUP BY device, day
ORDER BY device, day;- 查询物化视图
-- 查询物化视图
SELECTdevice, day, count, sum, max, min, avg
FROM test.tb_mtview_counter_daily_mv;
查询结果,物化视图中此时没有数据,为何?这是因为未使用 populate 关键字,该关键字并不推荐使用。
思考:为什么建表要加条件 WHERE create_time >= toDate(‘2016-01-01 00:00:00’) ?
在后续的测试中发现其实不加也没有问题,猜测加过滤条件是为了确保建表时数据无法被导入,从而确保数据不会出错。
- 向源表插入数据
-- 源表插入数据
INSERT INTO test.tb_mtview_counter
SELECTtoDateTime('2017-01-01 00:00:00') + toInt64(number/10) AS create_time,(number % 10) + 1 AS device,(device * 3) + (number/10000) + (rand() % 53) * 0.1 AS value
FROM system.numbers LIMIT 100000;-- 查询物化视图
SELECTdevice, day, count, sum, max, min, avg
FROM test.tb_mtview_counter_daily_mv;- 结果如下:
┌─device─┬────────day─┬─count─┬────────────────sum─┬─────max─┬─────min─┬────────────────avg─┐
│ 1 │ 2017-01-01 │ 10000 │ 106250.90001893044 │ 18.153 │ 3.122 │ 10.625090001893044 │
│ 2 │ 2017-01-01 │ 10000 │ 135986.09993600845 │ 21.1851 │ 6.1051 │ 13.598609993600846 │
│ 3 │ 2017-01-01 │ 10000 │ 165927.19995212555 │ 24.1862 │ 9.2032 │ 16.592719995212555 │
│ 4 │ 2017-01-01 │ 10000 │ 195965.7000246048 │ 27.1743 │ 12.0193 │ 19.59657000246048 │
│ 5 │ 2017-01-01 │ 10000 │ 226203.90004825592 │ 30.1224 │ 15.0054 │ 22.62039000482559 │
│ 6 │ 2017-01-01 │ 10000 │ 256157.8000125885 │ 33.1915 │ 18.0025 │ 25.61578000125885 │
│ 7 │ 2017-01-01 │ 10000 │ 285870.0000991821 │ 36.1576 │ 21.0036 │ 28.587000009918214 │
│ 8 │ 2017-01-01 │ 10000 │ 315986.59994506836 │ 39.1477 │ 24.0267 │ 31.598659994506836 │
│ 9 │ 2017-01-01 │ 10000 │ 346104.4998226166 │ 42.1978 │ 27.0028 │ 34.610449982261656 │
│ 10 │ 2017-01-01 │ 10000 │ 376108.5000667572 │ 45.1809 │ 30.0059 │ 37.61085000667572 │
└────────┴────────────┴───────┴────────────────────┴─────────┴─────────┴────────────────────┘- 向物化视图插入数据
-- 向物化视图插入数据
insert into test.tb_mtview_counter_daily_mv
SELECTtoStartOfMonth(create_time) as day,device,count(*) as count,sum(value) as sum,max(value) as max,min(value) as min,avg(value) as avg
from test.tb_mtview_counter where create_time < toDate('2016-01-01 00:00:00')
GROUP BY device, day
ORDER BY device, day;-- 查询物化视图
SELECTdevice, day, count, sum, max, min, avg
FROM test.tb_mtview_counter_daily_mv;- 结果如下:
┌─device─┬────────day─┬─count─┬────────────────sum─┬─────max─┬─────min─┬────────────────avg─┐
│ 1 │ 2017-01-01 │ 10000 │ 106250.90001893044 │ 18.153 │ 3.122 │ 10.625090001893044 │
│ 2 │ 2017-01-01 │ 10000 │ 135986.09993600845 │ 21.1851 │ 6.1051 │ 13.598609993600846 │
│ 3 │ 2017-01-01 │ 10000 │ 165927.19995212555 │ 24.1862 │ 9.2032 │ 16.592719995212555 │
│ 4 │ 2017-01-01 │ 10000 │ 195965.7000246048 │ 27.1743 │ 12.0193 │ 19.59657000246048 │
│ 5 │ 2017-01-01 │ 10000 │ 226203.90004825592 │ 30.1224 │ 15.0054 │ 22.62039000482559 │
│ 6 │ 2017-01-01 │ 10000 │ 256157.8000125885 │ 33.1915 │ 18.0025 │ 25.61578000125885 │
│ 7 │ 2017-01-01 │ 10000 │ 285870.0000991821 │ 36.1576 │ 21.0036 │ 28.587000009918214 │
│ 8 │ 2017-01-01 │ 10000 │ 315986.59994506836 │ 39.1477 │ 24.0267 │ 31.598659994506836 │
│ 9 │ 2017-01-01 │ 10000 │ 346104.4998226166 │ 42.1978 │ 27.0028 │ 34.610449982261656 │
│ 10 │ 2017-01-01 │ 10000 │ 376108.5000667572 │ 45.1809 │ 30.0059 │ 37.61085000667572 │
└────────┴────────────┴───────┴────────────────────┴─────────┴─────────┴────────────────────┘
┌─device─┬────────day─┬─count─┬────────────────sum─┬─────max─┬─────min─┬────────────────avg─┐
│ 1 │ 2015-01-01 │ 10000 │ 105885.80000400543 │ 18.166 │ 3.021 │ 10.588580000400544 │
│ 2 │ 2015-01-01 │ 10000 │ 136100.19999217987 │ 21.0361 │ 6.0391 │ 13.610019999217988 │
│ 3 │ 2015-01-01 │ 10000 │ 166083.29994297028 │ 24.0942 │ 9.0432 │ 16.608329994297026 │
│ 4 │ 2015-01-01 │ 10000 │ 196134.90005016327 │ 27.1783 │ 12.0363 │ 19.613490005016327 │
│ 5 │ 2015-01-01 │ 10000 │ 225946.59996700287 │ 30.1994 │ 15.1584 │ 22.594659996700287 │
│ 6 │ 2015-01-01 │ 10000 │ 256283.39991378784 │ 33.1905 │ 18.0135 │ 25.628339991378784 │
│ 7 │ 2015-01-01 │ 10000 │ 286232.70005607605 │ 35.9916 │ 21.0066 │ 28.623270005607605 │
│ 8 │ 2015-01-01 │ 10000 │ 315966.5000553131 │ 39.1537 │ 24.0577 │ 31.596650005531313 │
│ 9 │ 2015-01-01 │ 10000 │ 345799.6998100281 │ 42.1388 │ 27.0538 │ 34.579969981002805 │
│ 10 │ 2015-01-01 │ 10000 │ 375820.0998439789 │ 45.1509 │ 30.0779 │ 37.582009984397885 │
└────────┴────────────┴───────┴────────────────────┴─────────┴─────────┴────────────────────┘- 向源表插入同分区数据
- 插入一个同分区(对物化视图而言),但日期不同的数据。对比查询源表结果,与物化视图的结果有什么区别
-- 源表插入数据
INSERT INTO test.tb_mtview_counter
SELECTtoDateTime('2017-01-02 00:00:00') + toInt64(number/10) AS create_time,(number % 10) + 1 AS device,(device * 3) + (number/10000) + (rand() % 53) * 0.1 AS value
FROM system.numbers LIMIT 100000;-- 查询物化视图
SELECTdevice, day, count, sum, max, min, avg
FROM test.tb_mtview_counter_daily_mv;- 结果如下:
┌─device─┬────────day─┬─count─┬────────────────sum─┬─────max─┬─────min─┬────────────────avg─┐
│ 1 │ 2015-01-01 │ 10000 │ 105885.80000400543 │ 18.166 │ 3.021 │ 10.588580000400544 │
│ 2 │ 2015-01-01 │ 10000 │ 136100.19999217987 │ 21.0361 │ 6.0391 │ 13.610019999217988 │
│ 3 │ 2015-01-01 │ 10000 │ 166083.29994297028 │ 24.0942 │ 9.0432 │ 16.608329994297026 │
│ 4 │ 2015-01-01 │ 10000 │ 196134.90005016327 │ 27.1783 │ 12.0363 │ 19.613490005016327 │
│ 5 │ 2015-01-01 │ 10000 │ 225946.59996700287 │ 30.1994 │ 15.1584 │ 22.594659996700287 │
│ 6 │ 2015-01-01 │ 10000 │ 256283.39991378784 │ 33.1905 │ 18.0135 │ 25.628339991378784 │
│ 7 │ 2015-01-01 │ 10000 │ 286232.70005607605 │ 35.9916 │ 21.0066 │ 28.623270005607605 │
│ 8 │ 2015-01-01 │ 10000 │ 315966.5000553131 │ 39.1537 │ 24.0577 │ 31.596650005531313 │
│ 9 │ 2015-01-01 │ 10000 │ 345799.6998100281 │ 42.1388 │ 27.0538 │ 34.579969981002805 │
│ 10 │ 2015-01-01 │ 10000 │ 375820.0998439789 │ 45.1509 │ 30.0779 │ 37.582009984397885 │
└────────┴────────────┴───────┴────────────────────┴─────────┴─────────┴────────────────────┘
┌─device─┬────────day─┬─count─┬────────────────sum─┬─────max─┬─────min─┬────────────────avg─┐
│ 1 │ 2017-01-01 │ 10000 │ 106250.90001893044 │ 18.153 │ 3.122 │ 10.625090001893044 │
│ 2 │ 2017-01-01 │ 10000 │ 135986.09993600845 │ 21.1851 │ 6.1051 │ 13.598609993600846 │
│ 3 │ 2017-01-01 │ 10000 │ 165927.19995212555 │ 24.1862 │ 9.2032 │ 16.592719995212555 │
│ 4 │ 2017-01-01 │ 10000 │ 195965.7000246048 │ 27.1743 │ 12.0193 │ 19.59657000246048 │
│ 5 │ 2017-01-01 │ 10000 │ 226203.90004825592 │ 30.1224 │ 15.0054 │ 22.62039000482559 │
│ 6 │ 2017-01-01 │ 10000 │ 256157.8000125885 │ 33.1915 │ 18.0025 │ 25.61578000125885 │
│ 7 │ 2017-01-01 │ 10000 │ 285870.0000991821 │ 36.1576 │ 21.0036 │ 28.587000009918214 │
│ 8 │ 2017-01-01 │ 10000 │ 315986.59994506836 │ 39.1477 │ 24.0267 │ 31.598659994506836 │
│ 9 │ 2017-01-01 │ 10000 │ 346104.4998226166 │ 42.1978 │ 27.0028 │ 34.610449982261656 │
│ 10 │ 2017-01-01 │ 10000 │ 376108.5000667572 │ 45.1809 │ 30.0059 │ 37.61085000667572 │
└────────┴────────────┴───────┴────────────────────┴─────────┴─────────┴────────────────────┘
┌─device─┬────────day─┬─count─┬────────────────sum─┬─────max─┬─────min─┬────────────────avg─┐
│ 1 │ 2017-01-01 │ 10000 │ 106321.70000195503 │ 18.196 │ 3.007 │ 10.632170000195503 │
│ 2 │ 2017-01-01 │ 10000 │ 135868.9999809265 │ 21.1501 │ 6.0041 │ 13.586899998092651 │
│ 3 │ 2017-01-01 │ 10000 │ 165784.19991016388 │ 24.1572 │ 9.0552 │ 16.57841999101639 │
│ 4 │ 2017-01-01 │ 10000 │ 196065.50004196167 │ 27.1883 │ 12.0763 │ 19.606550004196166 │
│ 5 │ 2017-01-01 │ 10000 │ 225919.39997386932 │ 30.1374 │ 15.0284 │ 22.591939997386934 │
│ 6 │ 2017-01-01 │ 10000 │ 256105.40001869202 │ 33.1865 │ 18.0855 │ 25.6105400018692 │
│ 7 │ 2017-01-01 │ 10000 │ 286283.80012512207 │ 36.1986 │ 21.0996 │ 28.628380012512206 │
│ 8 │ 2017-01-01 │ 10000 │ 316006.7000656128 │ 39.1217 │ 24.0167 │ 31.60067000656128 │
│ 9 │ 2017-01-01 │ 10000 │ 345796.399974823 │ 42.1778 │ 27.0268 │ 34.5796399974823 │
│ 10 │ 2017-01-01 │ 10000 │ 376074.8998966217 │ 45.1629 │ 30.0649 │ 37.60748998966217 │
└────────┴────────────┴───────┴────────────────────┴─────────┴─────────┴────────────────────┘数据暂时未合并,可以执行 optimize 来手动进行合并(就算不手动执行,未来某个时刻也会自动合并)。
optimize table test.tb_mtview_counter_daily_mv final;
- 合并后查询结果:
┌─device─┬────────day─┬─count─┬────────────────sum─┬─────max─┬─────min─┬────────────────avg─┐
│ 1 │ 2015-01-01 │ 10000 │ 105885.80000400543 │ 18.166 │ 3.021 │ 10.588580000400544 │
│ 2 │ 2015-01-01 │ 10000 │ 136100.19999217987 │ 21.0361 │ 6.0391 │ 13.610019999217988 │
│ 3 │ 2015-01-01 │ 10000 │ 166083.29994297028 │ 24.0942 │ 9.0432 │ 16.608329994297026 │
│ 4 │ 2015-01-01 │ 10000 │ 196134.90005016327 │ 27.1783 │ 12.0363 │ 19.613490005016327 │
│ 5 │ 2015-01-01 │ 10000 │ 225946.59996700287 │ 30.1994 │ 15.1584 │ 22.594659996700287 │
│ 6 │ 2015-01-01 │ 10000 │ 256283.39991378784 │ 33.1905 │ 18.0135 │ 25.628339991378784 │
│ 7 │ 2015-01-01 │ 10000 │ 286232.70005607605 │ 35.9916 │ 21.0066 │ 28.623270005607605 │
│ 8 │ 2015-01-01 │ 10000 │ 315966.5000553131 │ 39.1537 │ 24.0577 │ 31.596650005531313 │
│ 9 │ 2015-01-01 │ 10000 │ 345799.6998100281 │ 42.1388 │ 27.0538 │ 34.579969981002805 │
│ 10 │ 2015-01-01 │ 10000 │ 375820.0998439789 │ 45.1509 │ 30.0779 │ 37.582009984397885 │
└────────┴────────────┴───────┴────────────────────┴─────────┴─────────┴────────────────────┘
┌─device─┬────────day─┬─count─┬────────────────sum─┬───────max─┬───────min─┬────────────────avg─┐
│ 1 │ 2017-01-01 │ 20000 │ 212572.60002088547 │ 36.349 │ 6.1289997 │ 21.257260002088547 │
│ 2 │ 2017-01-01 │ 20000 │ 271855.09991693497 │ 42.3352 │ 12.1092 │ 27.185509991693497 │
│ 3 │ 2017-01-01 │ 20000 │ 331711.3998622894 │ 48.3434 │ 18.2584 │ 33.171139986228944 │
│ 4 │ 2017-01-01 │ 20000 │ 392031.20006656647 │ 54.3626 │ 24.0956 │ 39.20312000665665 │
│ 5 │ 2017-01-01 │ 20000 │ 452123.30002212524 │ 60.2598 │ 30.0338 │ 45.212330002212525 │
│ 6 │ 2017-01-01 │ 20000 │ 512263.2000312805 │ 66.378006 │ 36.088 │ 51.22632000312805 │
│ 7 │ 2017-01-01 │ 20000 │ 572153.8002243042 │ 72.3562 │ 42.1032 │ 57.21538002243042 │
│ 8 │ 2017-01-01 │ 20000 │ 631993.3000106812 │ 78.2694 │ 48.0434 │ 63.19933000106812 │
│ 9 │ 2017-01-01 │ 20000 │ 691900.8997974396 │ 84.375595 │ 54.029602 │ 69.19008997974396 │
│ 10 │ 2017-01-01 │ 20000 │ 752183.3999633789 │ 90.343796 │ 60.0708 │ 75.21833999633789 │
└────────┴────────────┴───────┴────────────────────┴───────────┴───────────┴────────────────────┘从结果可以看到,分区数据执行了合并,而且合并是依据order by字段进行的,除了device和day以外的字段全部自动求和了,这个就是SummingMergeTree的特性。
物化视图—方式2:
在前一种物化视图中,我们看到,SummingMergeTree()对常规的除了求和以外的聚合函数支持并不好,在本例中,我们采用 聚合函数名称加-State后缀 的函数形式来获取聚合值,通过例子来了解具体是怎么一回事。
官网介绍:以-State后缀的函数总是返回AggregateFunction类型的数据的中间状态。对于SELECT而言AggregateFunction类型总是以特定的二进制形式展现在所有的输出格式中。
参考:https://clickhouse.com/docs/zh/sql-reference/data-types/aggregatefunction
-- 没有to table时必须有engine
CREATE MATERIALIZED VIEW test.tb_mtview_counter_daily_mv2
ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(day) ORDER BY (device, day)
AS SELECTtoStartOfMonth(create_time) as day,device,count(*) as count,sum(value) as sum,maxState(value) AS max_value_state,minState(value) AS min_value_state,avgState(value) AS avg_value_state
FROM test.tb_mtview_counter
WHERE create_time >= toDate('2016-01-01 00:00:00')
GROUP BY device, day
ORDER BY device, day;- 源表新增数据
INSERT INTO test.tb_mtview_counter
SELECTtoDateTime('2016-01-01 00:00:00') + toInt64(number/10) AS create_time,(number % 10) + 1 AS device,(device * 3) + (number/10000) + (rand() % 53) * 0.1 AS value
FROM system.numbers LIMIT 100000;-- 查询源表
SELECTtoStartOfMonth(create_time) as day,device,count(*) as count,sum(value) as sum,max(value) as max,min(value) as min,avg(value) as avg
from test.tb_mtview_counter
GROUP BY device, day
ORDER BY day, device;-- 查询物化视图
SELECTday, device, sum(count) AS count,sum(sum) as sum, maxMerge(max_value_state) AS max,minMerge(min_value_state) AS min,avgMerge(avg_value_state) AS avg
FROM test.tb_mtview_counter_daily_mv2
GROUP BY device, day
ORDER BY day, device;-- 显示当前数据库所有表
show tables from test;- 二者结果均为:
┌────────day─┬─device─┬─count─┬────────────────sum─┬─────max─┬─────min─┬────────────────avg─┐
│ 2016-01-01 │ 1 │ 10000 │ 105755.79999136925 │ 18.11 │ 3.004 │ 10.575579999136925 │
│ 2016-01-01 │ 2 │ 10000 │ 136052.39994812012 │ 21.1971 │ 6.0411 │ 13.605239994812012 │
│ 2016-01-01 │ 3 │ 10000 │ 165888.80001831055 │ 24.1952 │ 9.0012 │ 16.588880001831054 │
│ 2016-01-01 │ 4 │ 10000 │ 196001.40008163452 │ 27.1563 │ 12.0223 │ 19.600140008163454 │
│ 2016-01-01 │ 5 │ 10000 │ 225971.79990959167 │ 30.0924 │ 15.0074 │ 22.597179990959166 │
│ 2016-01-01 │ 6 │ 10000 │ 256052.80004692078 │ 33.1685 │ 18.0755 │ 25.605280004692077 │
│ 2016-01-01 │ 7 │ 10000 │ 286267.600069046 │ 36.1666 │ 21.0096 │ 28.6267600069046 │
│ 2016-01-01 │ 8 │ 10000 │ 315901.2999572754 │ 39.1117 │ 24.0547 │ 31.59012999572754 │
│ 2016-01-01 │ 9 │ 10000 │ 345774.49993896484 │ 42.1678 │ 27.1348 │ 34.57744999389649 │
│ 2016-01-01 │ 10 │ 10000 │ 375901.99990463257 │ 45.1459 │ 30.0009 │ 37.590199990463255 │
└────────────┴────────┴───────┴────────────────────┴─────────┴─────────┴────────────────────┘为什么查询物化视图 还要GROUP BY +sum ?
- 由于SummingMergeTree引擎是异步的(这节省了资源并减少了对查询处理的影响),所以某些值可能尚未被计算,我们仍然需要在此使用 GROUP BY 。
在使用 MV 的聚合引擎时,也需要按照聚合查询 配合 GROUP BY 来写sql,因为聚合时机不可控
物化视图—方式3:
- 一般需要先建一张表
- 再采用使用to db.table方法,将物化视图的实体表指定为特定名称的表。
-- 先建一张表
CREATE TABLE test.tb_mtview_counter_daily (day Date,device UInt32,count UInt64,sum Float64,max_value_state AggregateFunction(max, Float32),min_value_state AggregateFunction(min, Float32),avg_value_state AggregateFunction(avg, Float32)
)
ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(day)
ORDER BY (device, day);-- 将物化视图的实体表指定为特定名称的表
CREATE MATERIALIZED VIEW test.tb_mtview_counter_daily_mv3
TO test.tb_mtview_counter_daily
AS SELECTtoStartOfMonth(create_time) as day,device,count(*) as count,sum(value) as sum,maxState(value) AS max_value_state,minState(value) AS min_value_state,avgState(value) AS avg_value_state
FROM test.tb_mtview_counter
WHERE create_time >= toDate('2019-01-01 00:00:00')
GROUP BY device, day
ORDER BY device, day;- 向源表导入数据
INSERT INTO test.tb_mtview_counter
SELECTtoDateTime('2020-01-01 00:00:00') + toInt64(number/10) AS create_time,(number % 10) + 1 AS device,(device * 3) + (number/10000) + (rand() % 53) * 0.1 AS value
FROM system.numbers LIMIT 10000;-- 查询物化视图实体表
SELECTdevice, day, sum(count) AS count,sum(sum) as sum, maxMerge(max_value_state) AS max,minMerge(min_value_state) AS min,avgMerge(avg_value_state) AS avg
FROM test.tb_mtview_counter_daily
GROUP BY device, day
ORDER BY day, device;-- 查询物化视图
SELECTdevice, day, sum(count) AS count,sum(sum) as sum, maxMerge(max_value_state) AS max,minMerge(min_value_state) AS min,avgMerge(avg_value_state) AS avg
FROM test.tb_mtview_counter_daily_mv3
GROUP BY device, day
ORDER BY day, device;结果二者查询的结果一致:
┌─device─┬────────day─┬─count─┬────────────────sum─┬─────max─┬─────min─┬────────────────avg─┐
│ 1 │ 2020-01-01 │ 1000 │ 6121.699999332428 │ 9.165 │ 3.111 │ 6.121699999332428 │
│ 2 │ 2020-01-01 │ 1000 │ 9138.199996948242 │ 12.1741 │ 6.0041 │ 9.138199996948241 │
│ 3 │ 2020-01-01 │ 1000 │ 12132.700001716614 │ 15.1862 │ 9.0142 │ 12.132700001716614 │
│ 4 │ 2020-01-01 │ 1000 │ 15055.100002288818 │ 18.1763 │ 12.0163 │ 15.055100002288818 │
│ 5 │ 2020-01-01 │ 1000 │ 18032.100012779236 │ 21.1454 │ 15.0524 │ 18.032100012779235 │
│ 6 │ 2020-01-01 │ 1000 │ 21153.600038528442 │ 24.1725 │ 18.1265 │ 21.15360003852844 │
│ 7 │ 2020-01-01 │ 1000 │ 24141.300004959106 │ 27.1236 │ 21.1196 │ 24.141300004959106 │
│ 8 │ 2020-01-01 │ 1000 │ 27071.199975967407 │ 30.1157 │ 24.0987 │ 27.071199975967406 │
│ 9 │ 2020-01-01 │ 1000 │ 30123.699993133545 │ 33.1418 │ 27.0528 │ 30.123699993133545 │
│ 10 │ 2020-01-01 │ 1000 │ 33096.899978637695 │ 36.0949 │ 30.0509 │ 33.096899978637694 │
└────────┴────────────┴───────┴────────────────────┴─────────┴─────────┴────────────────────┘
物化视图— 案例2
1.原始数据表----以Wikistat的10亿行数据集为例:
CREATE TABLE wikistat
(`time` DateTime CODEC(Delta(4), ZSTD(1)),`project` LowCardinality(String),`subproject` LowCardinality(String),`path` String,`hits` UInt64
)
ENGINE = MergeTree
ORDER BY (path, time);Ok.INSERT INTO wikistat SELECT *
FROM s3('https://ClickHouse-public-datasets.s3.amazonaws.com/wikistat/partitioned/wikistat*.native.zst') LIMIT 1e9
- 假设我们经常查询某个日期最受欢迎的项目:
SELECTproject,sum(hits) AS h
FROM wikistat
WHERE date(time) = '2015-05-01'
GROUP BY project
ORDER BY h DESC
LIMIT 10
- 这个查询在测试实例上需要15秒来完成:
┌─project─┬────────h─┐
│ en │ 34521803 │
│ es │ 4491590 │
│ de │ 4490097 │
│ fr │ 3390573 │
│ it │ 2015989 │
│ ja │ 1379148 │
│ pt │ 1259443 │
│ tr │ 1254182 │
│ zh │ 988780 │
│ pl │ 985607 │
└─────────┴──────────┘10 rows in set. Elapsed: 14.869 sec. Processed 972.80 million rows, 10.53 GB (65.43 million rows/s., 708.05 MB/s.)
2.创建物化视图
CREATE TABLE wikistat_top_projects
(`date` Date,`project` LowCardinality(String),`hits` UInt32
)
ENGINE = SummingMergeTree
ORDER BY (date, project);Ok.CREATE MATERIALIZED VIEW wikistat_top_projects_mv TO wikistat_top_projects AS
SELECTdate(time) AS date,project,sum(hits) AS hits
FROM wikistat
GROUP BYdate,project;
在这两个查询中:
- wikistat_top_projects 是我们要用来保存物化视图的表的名称,
- wikistat_top_projects_mv 是物化视图本身(触发器)的名称,
- 我们使用了SummingMergeTree表引擎,因为我们希望为每个date/project汇总hits值,
- AS 后面的内容是构建物化视图的查询。
我们可以创建任意数量的物化视图,但每一个新的物化视图都是额外的存储负担,因此保持总数合理,即每个表下的物化视图数目控制在10个以内。
3.填充数据
现在,我们使用与 wikistat 表相同的查询来填充物化视图的目标表:
INSERT INTO wikistat_top_projects SELECTdate(time) AS date,project,sum(hits) AS hits
FROM wikistat
GROUP BYdate,project
请注意,这只花费了ClickHouse 3ms来产生相同的结果,而原始查询则花费了15秒
4.测试查询 物化视图
由于 wikistat_top_projects 是一个表,我们可以利用ClickHouse的SQL功能进行查询:
SELECTproject,sum(hits) hits
FROM wikistat_top_projects
WHERE date = '2015-05-01'
GROUP BY project
ORDER BY hits DESC
LIMIT 10┌─project─┬─────hits─┐
│ en │ 34521803 │
│ es │ 4491590 │
│ de │ 4490097 │
│ fr │ 3390573 │
│ it │ 2015989 │
│ ja │ 1379148 │
│ pt │ 1259443 │
│ tr │ 1254182 │
│ zh │ 988780 │
│ pl │ 985607 │
└─────────┴──────────┘10 rows in set. Elapsed: 0.003 sec. Processed 8.19 thousand rows, 101.81 KB (2.83 million rows/s., 35.20 MB/s.)
请注意,这只花费了ClickHouse 3ms来产生相同的结果,而原始查询则花费了15秒
为什么查询物化视图 还要GROUP BY +sum ?
- 由于SummingMergeTree引擎是异步的(这节省了资源并减少了对查询处理的影响),所以某些值可能尚未被计算,我们仍然需要在此使用 GROUP BY 。
在使用 MV 的聚合引擎时,也需要按照聚合查询 配合 GROUP BY 来写sql,因为聚合时机不可控
5.更新物化视图中的数据
- 物化视图的最强大的特点是当向源表插入数据时,目标表中的数据会使用 SELECT 语句自动更新:
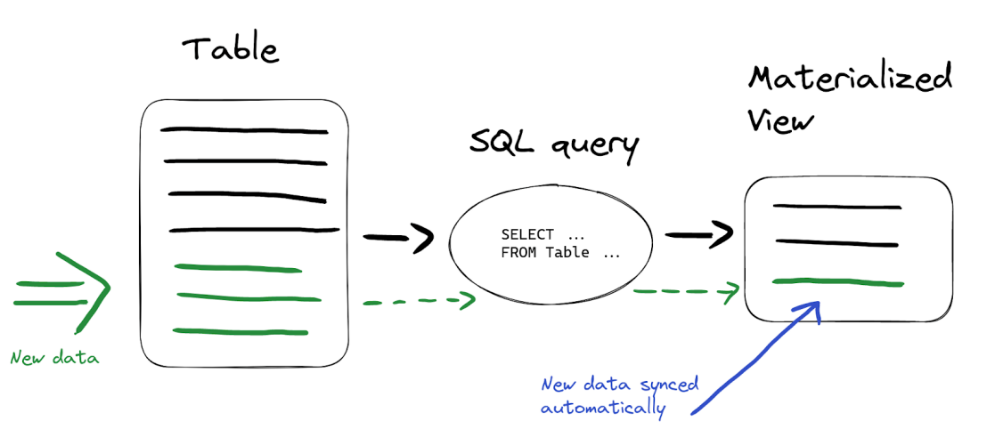
- 因此,我们不需要额外地刷新物化视图中的数据 - ClickHouse会自动完成一切操作。假设我们向 wikistat 表插入新数据:
INSERT INTO wikistat
VALUES(now(), 'test', '', '', 10),(now(), 'test', '', '', 10),(now(), 'test', '', '', 20),(now(), 'test', '', '', 30);
现在,让我们查询物化视图的目标表,以验证 hits 列是否已正确汇总。我们使用FINAL修饰符以确保SummingMergeTree引擎返回汇总的hits,而不是单个、未合并的行:
SELECT hits
FROM wikistat_top_projects
FINAL
WHERE (project = 'test') AND (date = date(now()))┌─hits─┐
│ 70 │
└──────┘1 row in set. Elapsed: 0.005 sec. Processed 7.15 thousand rows, 89.37 KB (1.37 million rows/s., 17.13 MB/s.)
- 在生产环境中,避免在大表上使用 FINAL ,并始终优先使用 sum(hits)。还请检查optimize_on_insert参数设置,该选项控制如何合并插入的数据。
在使用 MV 的聚合引擎时,也需要按照聚合查询 配合 GROUP BY 来写sql,因为聚合时机不可控
6.使用物化视图加速聚合(AggregatingMergeTree引擎)
- 如前一节所示,物化视图是一种提高查询性能的方法。对于分析查询,常见的聚合操作不仅仅是前面示例中展示的 sum() 。SummingMergeTree非常适用于计算汇总数据,但还有更高级的聚合可以使用AggregatingMergeTree引擎进行计算。
假设我们经常执行以下类型的查询:
SELECTtoDate(time) AS date,min(hits) AS min_hits_per_hour,max(hits) AS max_hits_per_hour,avg(hits) AS avg_hits_per_hour
FROM wikistat
WHERE project = 'en'
GROUP BY date
- 这为我们提供了给定项目的每日点击量的月最小值、最大值和平均值:
┌───────date─┬─min_hits_per_hour─┬─max_hits_per_hour─┬──avg_hits_per_hour─┐
│ 2015-05-01 │ 1 │ 36802 │ 4.586310181621408 │
│ 2015-05-02 │ 1 │ 23331 │ 4.241388590780171 │
│ 2015-05-03 │ 1 │ 24678 │ 4.317835245126423 │
...
└────────────┴───────────────────┴───────────────────┴────────────────────┘38 rows in set. Elapsed: 8.970 sec. Processed 994.11 million rows
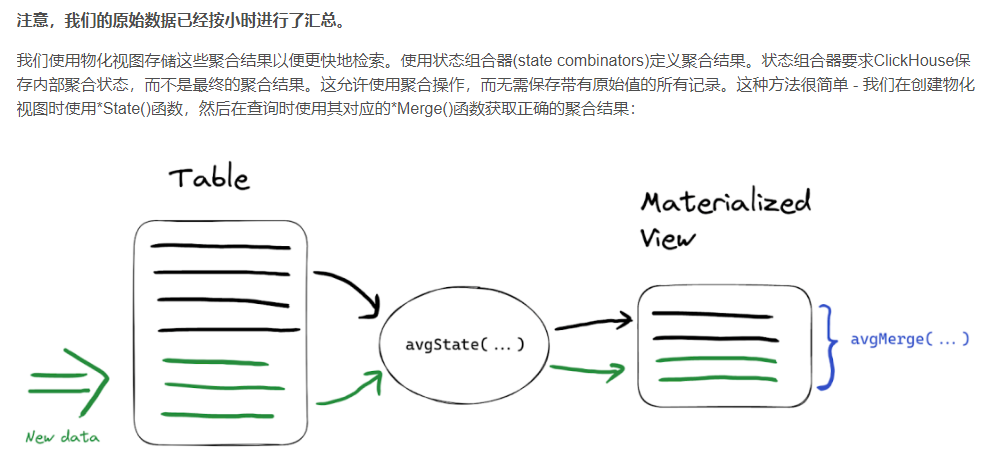
- 在我们的示例中,我们将使用 min 、 max 和 avg 状态。在新物化视图的目标表中,我们将使用AggregateFunction 类型存储聚合状态而不是值:
CREATE TABLE wikistat_daily_summary
(`project` String,`date` Date,`min_hits_per_hour` AggregateFunction(min, UInt64),`max_hits_per_hour` AggregateFunction(max, UInt64),`avg_hits_per_hour` AggregateFunction(avg, UInt64)
)
ENGINE = AggregatingMergeTree
ORDER BY (project, date);Ok.CREATE MATERIALIZED VIEW wikistat_daily_summary_mv
TO wikistat_daily_summary AS
SELECTproject,toDate(time) AS date,minState(hits) AS min_hits_per_hour,maxState(hits) AS max_hits_per_hour,avgState(hits) AS avg_hits_per_hour
FROM wikistat
GROUP BY project, date
- 现在,让我们为它填充数据:
INSERT INTO wikistat_daily_summary SELECTproject,toDate(time) AS date,minState(hits) AS min_hits_per_hour,maxState(hits) AS max_hits_per_hour,avgState(hits) AS avg_hits_per_hour
FROM wikistat
GROUP BY project, date0 rows in set. Elapsed: 33.685 sec. Processed 994.11 million rows
- 在查询时,我们使用相应的 Merge 组合器来检索值:
在使用 MV 的聚合引擎时,也需要按照聚合查询 配合 GROUP BY 来写sql,因为聚合时机不可控
SELECTdate,minMerge(min_hits_per_hour) min_hits_per_hour,maxMerge(max_hits_per_hour) max_hits_per_hour,avgMerge(avg_hits_per_hour) avg_hits_per_hour
FROM wikistat_daily_summary
WHERE project = 'en'
GROUP BY date
请注意,我们得到的结果完全相同,但速度快了数千倍:
┌───────date─┬─min_hits_per_hour─┬─max_hits_per_hour─┬──avg_hits_per_hour─┐
│ 2015-05-01 │ 1 │ 36802 │ 4.586310181621408 │
│ 2015-05-02 │ 1 │ 23331 │ 4.241388590780171 │
│ 2015-05-03 │ 1 │ 24678 │ 4.317835245126423 │
...
└────────────┴───────────────────┴───────────────────┴────────────────────┘32 rows in set. Elapsed: 0.005 sec. Processed 9.54 thousand rows, 1.14 MB (1.76 million rows/s., 209.01 MB/s.)
任何聚合函数都可以作为一个聚合物化视图的一部分与State/Merge组合器一起使用。
7.验证和过滤数据
使用物化视图的另一个流行的示例是在插入后立即处理数据。数据验证就是一个很好的例子。
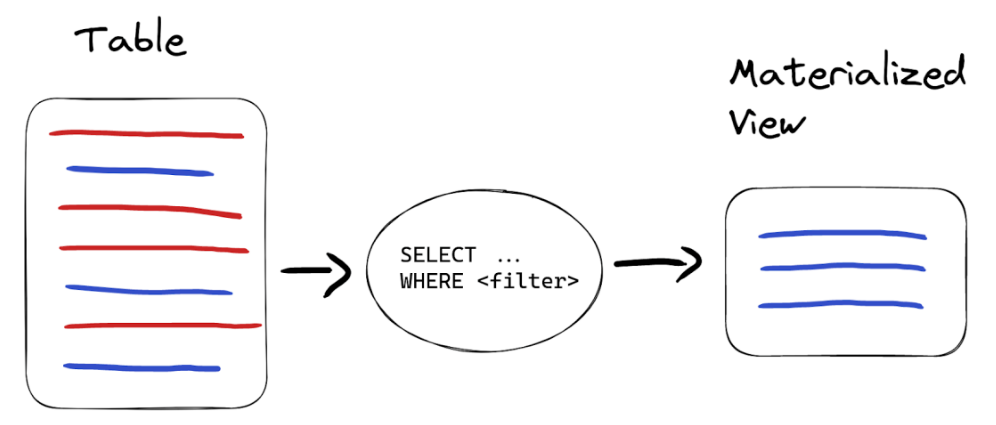
假设我们想要滤掉所有包含不需要的符号的path,再保存到结果表中。我们的表中有大约1%这样的值:
SELECT count(*)
FROM wikistat
WHERE NOT match(path, '[a-z0-9\\-]')
LIMIT 5┌──count()─┐
│ 12168918 │
└──────────┘1 row in set. Elapsed: 46.324 sec. Processed 994.11 million rows, 28.01 GB (21.46 million rows/s., 604.62 MB/s.)
为了实现验证过滤,我们需要两个表 - 一个带有所有数据的表和一个只带有干净数据的表。
- 物化视图的目标表将扮演一个只带有干净数据的最终表的角色,
- 源表将是暂时的。我们可以根据TTL从源表中删除数据,就像我们在上一节中所做的那样,或者将此表的引擎更改为Null,该引擎不存储任何数据(数据只会存储在物化视图中):
CREATE TABLE wikistat_src
(`time` DateTime,`project` LowCardinality(String),`subproject` LowCardinality(String),`path` String,`hits` UInt64
)
ENGINE = Null
现在,让我们使用数据验证查询创建一个物化视图:
CREATE TABLE wikistat_clean AS wikistat;Ok.CREATE MATERIALIZED VIEW wikistat_clean_mv TO wikistat_clean
AS SELECT *
FROM wikistat_src
WHERE match(path, '[a-z0-9\\-]')
当我们插入数据时, wikistat_src 将保持为空:
INSERT INTO wikistat_src SELECT * FROM s3('https://ClickHouse-public-datasets.s3.amazonaws.com/wikistat/partitioned/wikistat*.native.zst') LIMIT 1000

8.数据路由到表格
物化视图可以用于的另一个示例是基于某些条件将数据路由到不同的表:
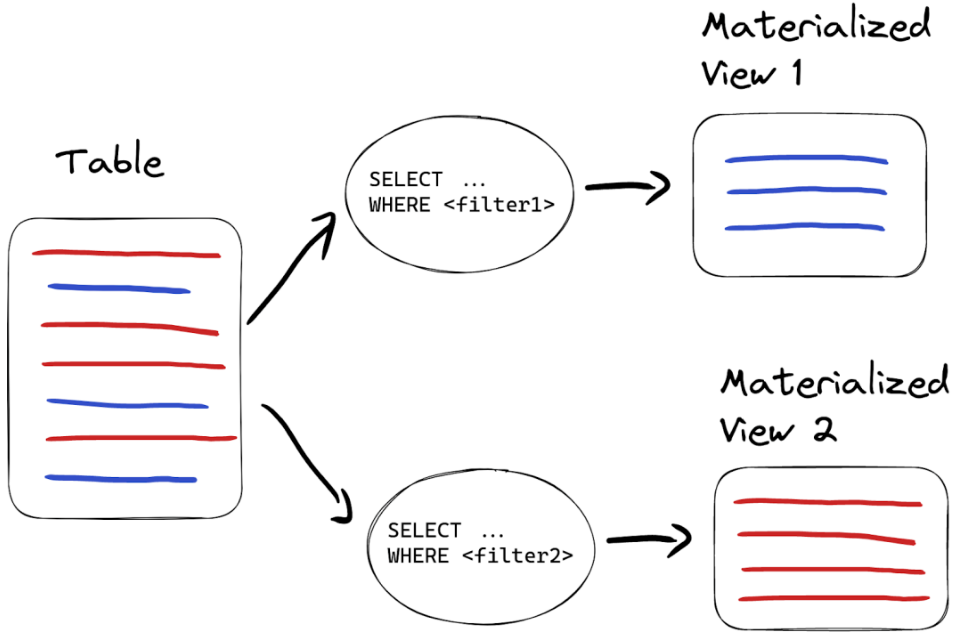
例如,我们可能希望将无效数据路由到另一个表,而不是删除它。在这种情况下,我们创建另一个物化视图,但使用不同的查询:
CREATE TABLE wikistat_invalid AS wikistat;Ok.CREATE MATERIALIZED VIEW wikistat_invalid_mv TO wikistat_invalid
AS SELECT *
FROM wikistat_src
WHERE NOT match(path, '[a-z0-9\\-]')
当我们有单个物化视图用于同一源表时,它们将按字母顺序进行处理。请记住,不要为源表创建超过几十个物化视图,因为插入性能可能会下降。
如果我们再次插入相同的数据,我们会在 wikistat_invalid 物化视图中找到942个无效的行:
SELECT count(*)
FROM wikistat_invalid┌─count()─┐
│ 942 │
└─────────┘
9.数据转换
由于物化视图基于查询的结果,所以我们可以在SQL中使用所有ClickHouse函数的功能来转换源值,以丰富和提升数据的清晰度。作为一个快速的例子,让我们将project、subproject和path列合并到一个单一的page列,并将时间分割为date和hour列:
CREATE TABLE wikistat_human
(`date` Date,`hour` UInt8,`page` String
)
ENGINE = MergeTree
ORDER BY (page, date);Ok.CREATE MATERIALIZED VIEW wikistat_human_mv TO wikistat_human
AS SELECTdate(time) AS date,toHour(time) AS hour,concat(project, if(subproject != '', '/', ''), subproject, '/', path) AS page,hits
FROM wikistat
现在, wikistat_human 将填充转换后的数据:
┌───────date─┬─hour─┬─page──────────────────────────┬─hits─┐
│ 2015-11-08 │ 8 │ en/m/Angel_Muñoz_(politician) │ 1 │
│ 2015-11-09 │ 3 │ en/m/Angel_Muñoz_(politician) │ 1 │
└────────────┴──────┴───────────────────────────────┴──────┘
10.物化视图和JOIN操作
由于物化视图是基于SQL查询的结果工作的,我们可以使用JOIN操作以及任何其他SQL功能。但是应该小心使用JOIN操作。
假设我们有一个带有页面标题的表:
CREATE TABLE wikistat_titles
(`path` String,`title` String
)
ENGINE = MergeTree
ORDER BY path
这个表中的title与path关联:
SELECT *
FROM wikistat_titles┌─path─────────┬─title────────────────┐
│ Ana_Sayfa │ Ana Sayfa - artist │
│ Bruce_Jenner │ William Bruce Jenner │
└──────────────┴──────────────────────┘
现在我们可以创建一个物化视图,从 wikistat_titles 表中通过joinpath值连接title:
CREATE TABLE wikistat_with_titles
(`time` DateTime,`path` String,`title` String,`hits` UInt64
)
ENGINE = MergeTree
ORDER BY (path, time);Ok.CREATE MATERIALIZED VIEW wikistat_with_titles_mv TO wikistat_with_titles
AS SELECT time, path, title, hits
FROM wikistat AS w
INNER JOIN wikistat_titles AS wt ON w.path = wt.path
注意,我们使用了 INNER JOIN ,所以在填充后,我们只会得到在 wikistat_titles 表中有对应值的记录:
SELECT * FROM wikistat_with_titles LIMIT 5┌────────────────time─┬─path──────┬─title──────────────┬─hits─┐
│ 2015-05-01 01:00:00 │ Ana_Sayfa │ Ana Sayfa - artist │ 5 │
│ 2015-05-01 01:00:00 │ Ana_Sayfa │ Ana Sayfa - artist │ 7 │
│ 2015-05-01 01:00:00 │ Ana_Sayfa │ Ana Sayfa - artist │ 1 │
│ 2015-05-01 01:00:00 │ Ana_Sayfa │ Ana Sayfa - artist │ 3 │
│ 2015-05-01 01:00:00 │ Ana_Sayfa │ Ana Sayfa - artist │ 653 │
└─────────────────────┴───────────┴────────────────────┴──────┘
我们在 wikistat 表中插入一个新记录,看看我们的新物化视图是如何工作的:
INSERT INTO wikistat VALUES(now(), 'en', '', 'Ana_Sayfa', 123);1 row in set. Elapsed: 1.538 sec.
注意这里的插入时间 - 1.538秒。我们可以在 wikistat_with_titles 中看到我们的新行:
SELECT *
FROM wikistat_with_titles
ORDER BY time DESC
LIMIT 3┌────────────────time─┬─path─────────┬─title────────────────┬─hits─┐
│ 2023-01-03 08:43:14 │ Ana_Sayfa │ Ana Sayfa - artist │ 123 │
│ 2015-06-30 23:00:00 │ Bruce_Jenner │ William Bruce Jenner │ 115 │
│ 2015-06-30 23:00:00 │ Bruce_Jenner │ William Bruce Jenner │ 55 │
└─────────────────────┴──────────────┴──────────────────────┴──────┘
但是,如果我们向 wikistat_titles 表添加数据会发生什么呢?:
INSERT INTO wikistat_titles
VALUES('Academy_Awards', 'Oscar academy awards');
尽管我们在 wikistat 表中有相应的值,但物化视图中不会出现任何内容:
SELECT *
FROM wikistat_with_titles
WHERE path = 'Academy_Awards'0 rows in set. Elapsed: 0.003 sec.
这是因为物化视图只在其源表接收插入时触发。它只是源表上的一个触发器,对连接表一无所知。注意,这不仅仅适用于join查询,并且在物化视图的SELECT语句中引入任何外部表时都很相关,例如使用 IN SELECT 。
在我们的情况下, wikistat 是物化视图的源表,而 wikistat_titles 是我们要连接的表:
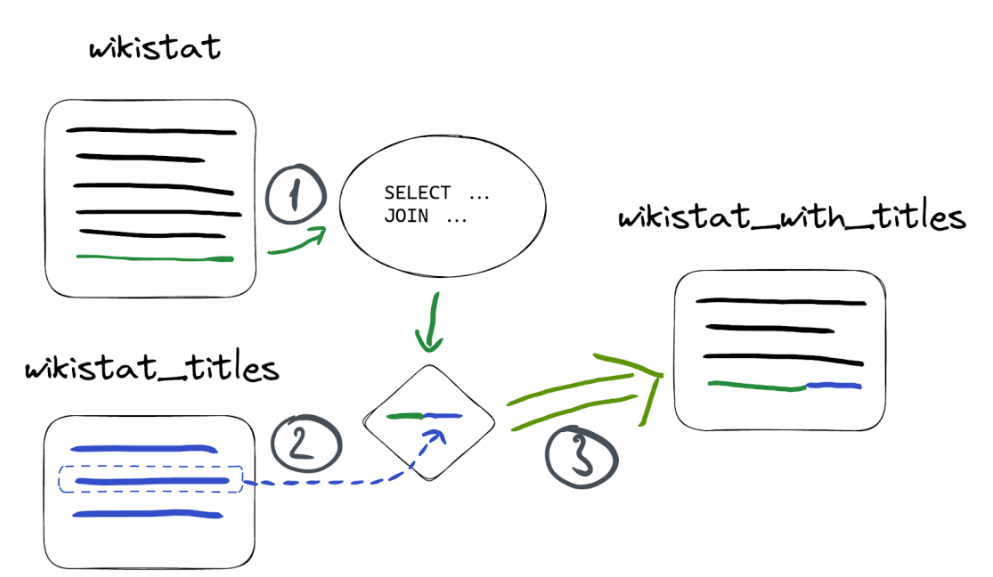

要小心,因为JOIN操作可能会在连接大表时显著降低插入性能,如上所示。考虑使用字典作为更有效的替代方法。
ClickHouse博客; https://blog.csdn.net/ClickHouseDB?type=blog




的使用)


)



打包org.omg.CosNotification找不到)


![[Python人工智能] 四十四.命名实体识别 (5)利用bert4keras构建Bert-CRF实体识别模型(实体位置)](http://pic.xiahunao.cn/[Python人工智能] 四十四.命名实体识别 (5)利用bert4keras构建Bert-CRF实体识别模型(实体位置))



)
