目录
火山图
热图
箱线图
森林图
LASSO回归可视化图(套索图)
交叉验证图
PCA图
ROC曲线图
这篇文章只介绍这些图应该怎么解读,具体怎么绘制,需要什么参数,怎么处理数据,会在下一篇文章里面给出
火山图
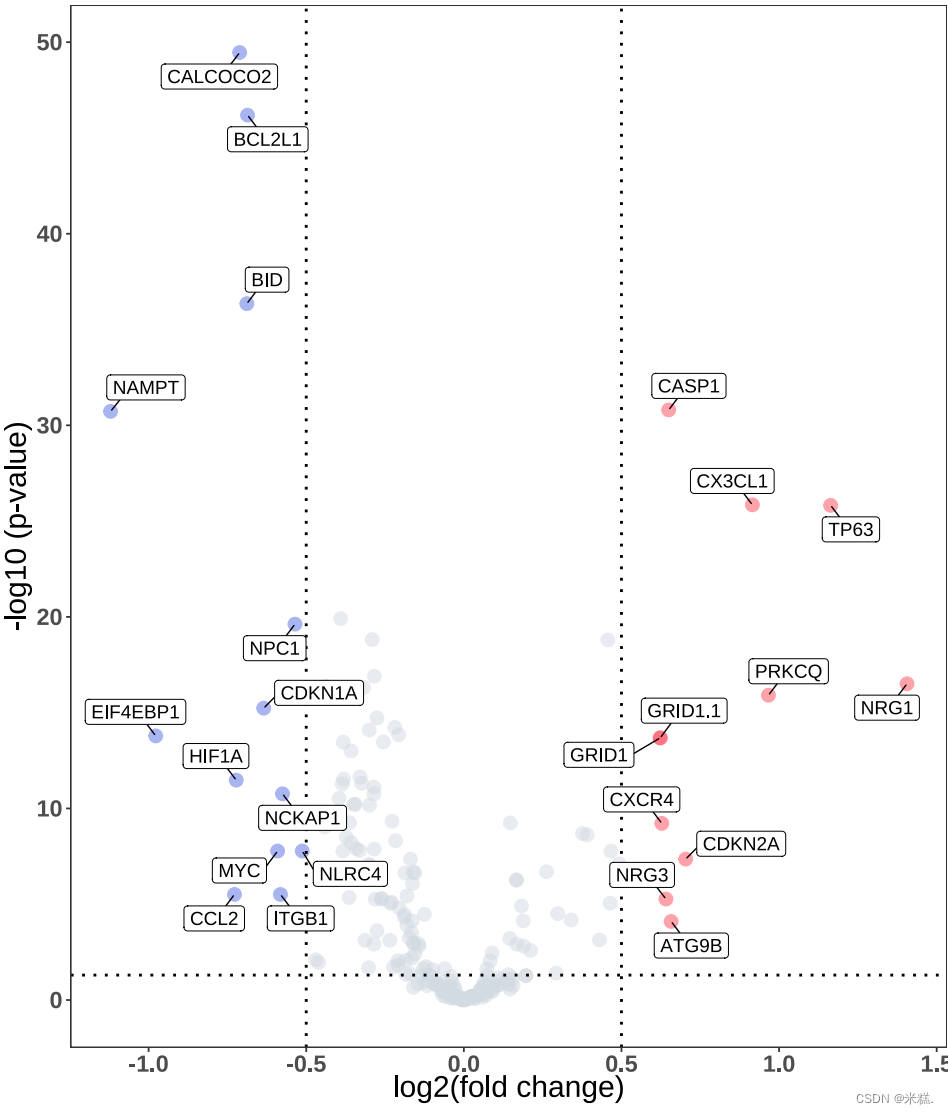
火山图横轴表示与对照组的差异倍数,纵轴表示表达水平。整个图由两条竖着的虚线和一条横着的虚线分割成六个部分,横着的虚线表示显著性水平线,在显著性水平线上面的是表达显著,下面是表达不显著。竖着的两条虚线表示差异倍数线。在差异倍数线区域的左侧表示表达量下降,右边表示表达量上升。在看火山图的时候一般看的是左上区域和右上区域。他们分别是表达量显著下降和表达量显著上升。
热图

这是一个热图,用颜色的深浅来表示基因表达量的差异
横轴代表样本,本例中分为了两组,一组是Healthy,一组是DCM
纵轴代表基因
横轴纵轴交汇处代表的就是特定基因在特定样本中的表达
可以看到上面和左面还有一些折线相互作用交错聚在一起,聚在一起的列可能表示有相似表达模式的基因,而聚在一起的行可能表示表达模式相似的样本或条件
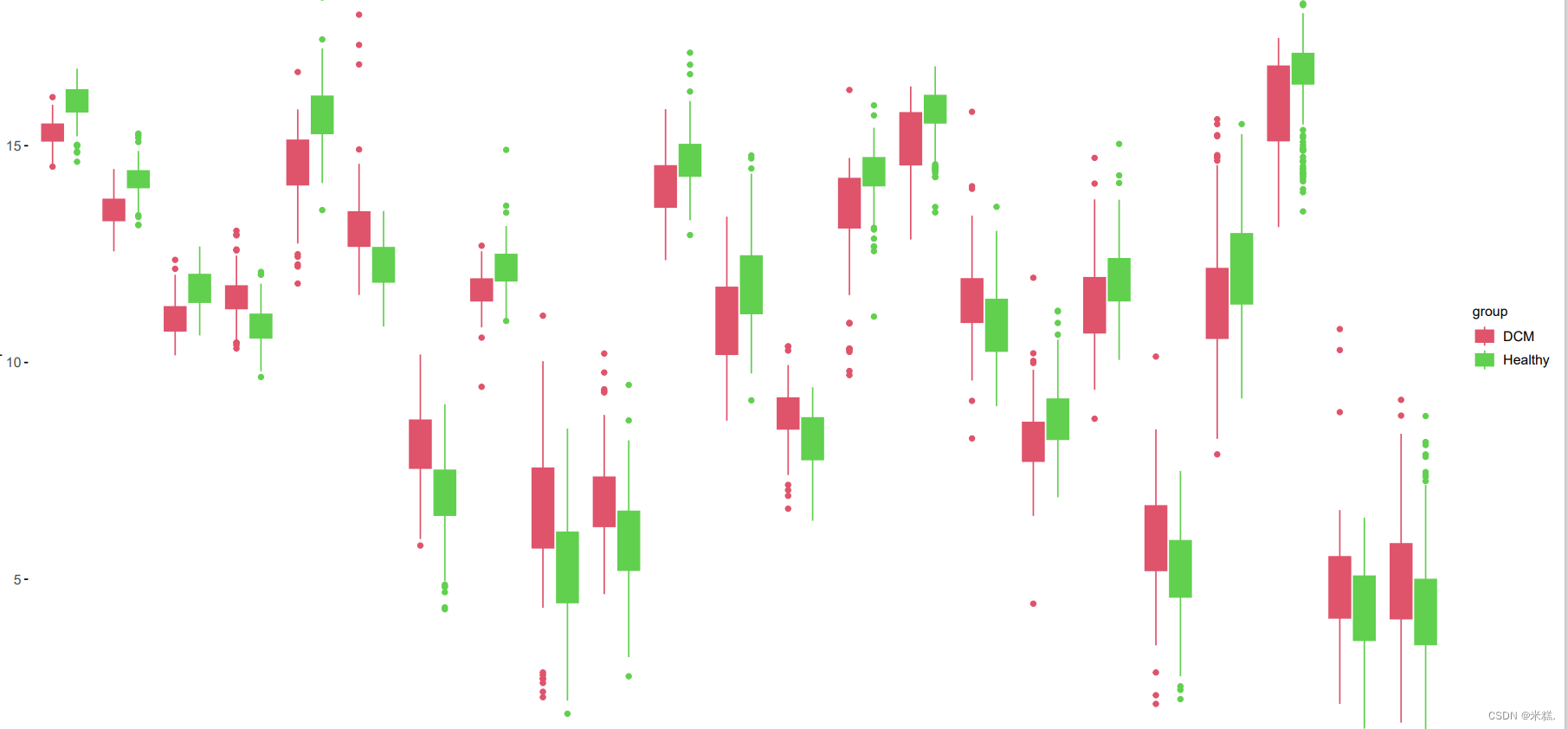
箱线图
普通箱线图的基本组成
- 箱体:箱体的上下边界分别是数据的上四分位数(Q3)和下四分位数(Q1),因此箱体包含了数据集中间的50%的数据点。箱体的长度(即IQR,四分位间距)可以用来衡量数据的散布程度。
- 中位线:箱体内部的一条线,表示数据的中位数(Q2)。
- 触须(须线):从箱体出发的两条线,延伸至数据的最大值和最小值,但不包括异常值。它们代表数据的正常范围。触须的计算方式有多种,但常见的一种是从Q1和Q3分别向外延伸1.5倍IQR(四分位间距)。
- 异常值:通常用小圆圈表示,异常值是 those 数据点,它们的值超出了触须的范围。这些点被认为是异常的或“离群”的,需要特别注意。
分组箱线图的基本组成
分组箱线图保持了箱线图的所有基本元素,包括箱体、中位线、触须和异常值,但它在横轴上为每个组或类别提供了一个单独的箱线图。这些箱线图并排排列,使得不同组之间的比较变得直接而明显。
这是一个分组箱线图
森林图

1:表示研究对象,可能是某些差异表达的基因名等等
2:是一些平行于x轴的线段,线段长短对应百分之九十五置信区间,线段左右两端的两个数值分别对应百分之九十五置信区间的两个端点值,线段越长表示95%置信区间越长,因此越不精准。
3:无效线,通常是x=0或x=1,如果2中的线段与无效线相交,则代表2中的线段没有统计学意义
5:OR叫比值比,计算方式位患病组中暴露的与不暴露的比值除上对照组中暴露的与不暴露的比值,也就是两个比值的比,因此也叫比值比
LASSO回归可视化图(套索图)
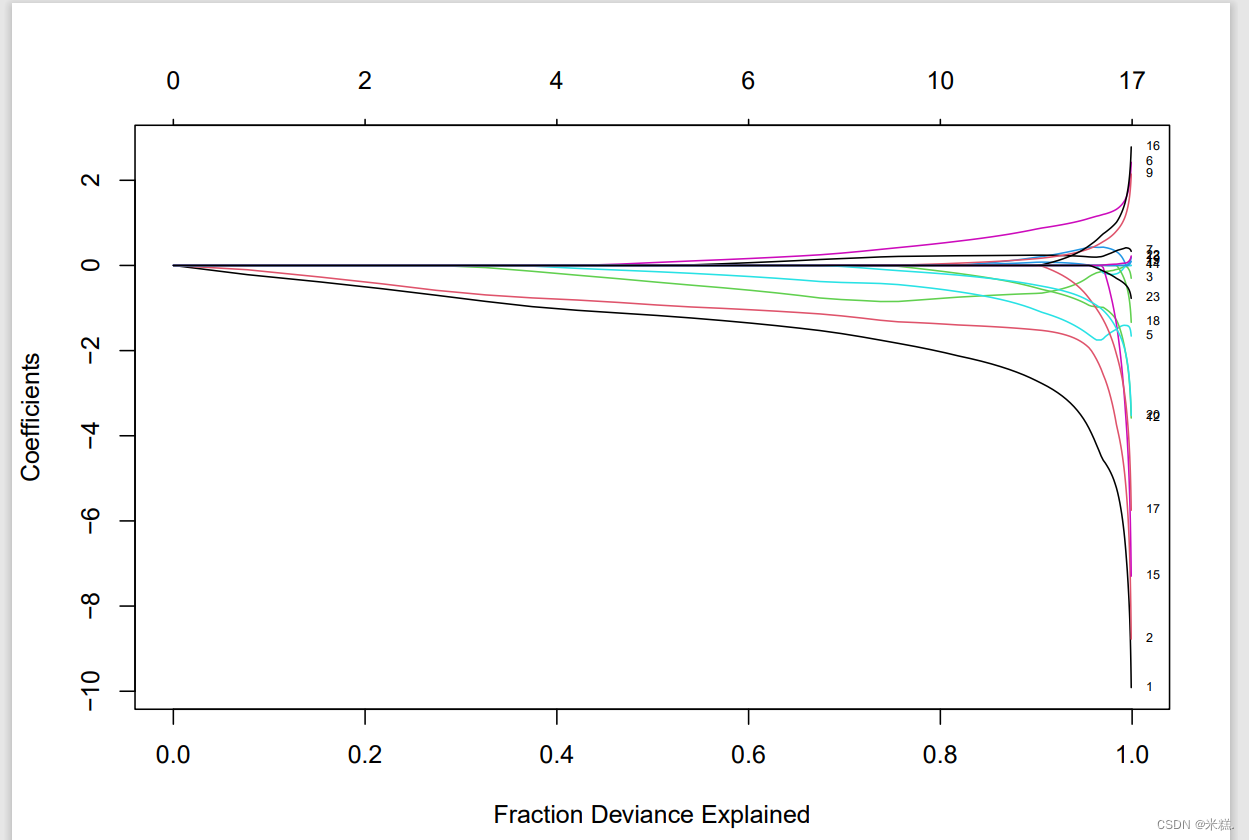
一般我们看到的套索图都是往右边收敛的,那些图的横坐标都是负的,而这个图的横坐标是正的,因此与那些图正好反着。LASSO回归是通过在多元线性回归模型中添加了一个惩罚系数,来达到简化模型的效果,图中每一条线都代表一个影响因素比如基因,让上来有非常多条线,但是随着惩罚系数的增大,他们的影响力不断减小,甚至有的已经到达了0,而随着惩罚系数不断增大,这些线最终都会收敛于0,我们以某一个惩罚系数的值位基准,剔除到达这个基准之前的那些基因,就能够简化模型了。
那么这个所谓的基准应该怎么选才合适呢?这就需要用到下面这张图了
交叉验证图
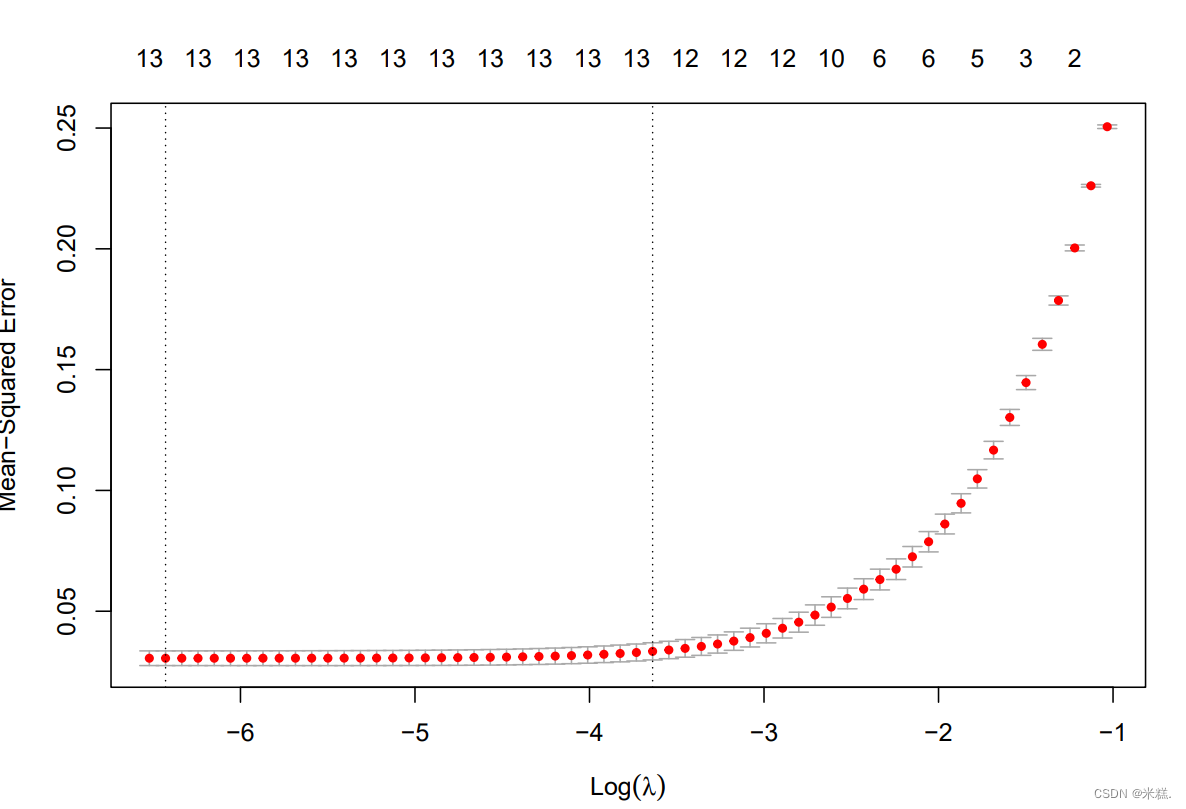
交叉验证图上面都会有两条虚线,分别是让纵坐标最小的位置和往右一个误差的位置,通常会使用均方误差作为纵坐标。
在文章中套索图和交叉验证图都是一起出现的。
PCA图
PCA:主成分分析
先来介绍一下PCA在做什么,举个极端的例子,在一个二维坐标系中有一些点,他们排成了一条直线,比如他们都是直线y=kx+b上面的点,如果要描述这些点的位置,就需要知道他们的横坐标和纵坐标,也就是需要两个维度的信息,但是既然他们都已经排成一条线了,我们如果能够旋转坐标系让他们都落在某一条坐标轴上,那么再次描述这些点的位置不就只需要一维的信息就足够了吗?这就达到了一个降维的效果。实际上PCA在做的事情与这个例子类似,是在把一个多维的信息转换成几个综合指标,从而达到降维的效果,这个综合指标是对原始指标数据的线性组合,这个综合指标被称为主成分,比如PC1,PC2等
而PCA图就是对我们降维的结果进行展示,下面是一个PCA图
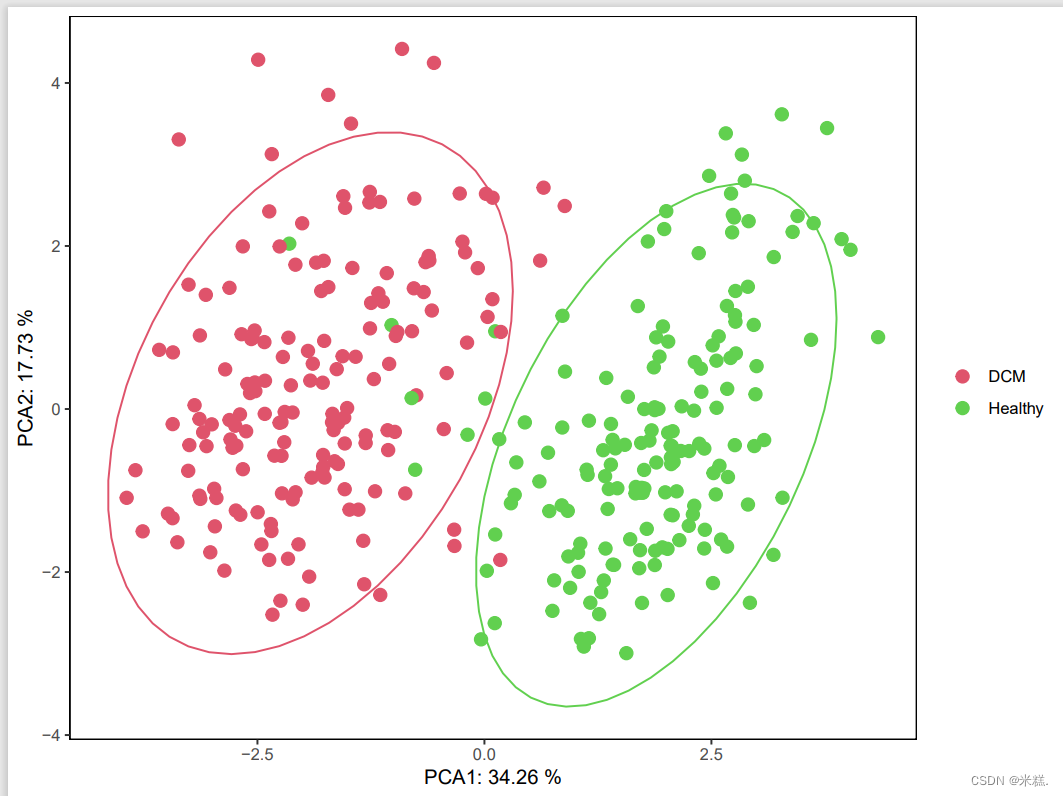
横坐标和纵坐标分别表示PC1和PC2的方差在这一组指标中的总方差中所占的比例,如果在PCA图中两个样本聚集在一起,就说明他们的差异性比较小,如果两个样本离着比较远,则说明他们的差异较大。
ROC曲线图
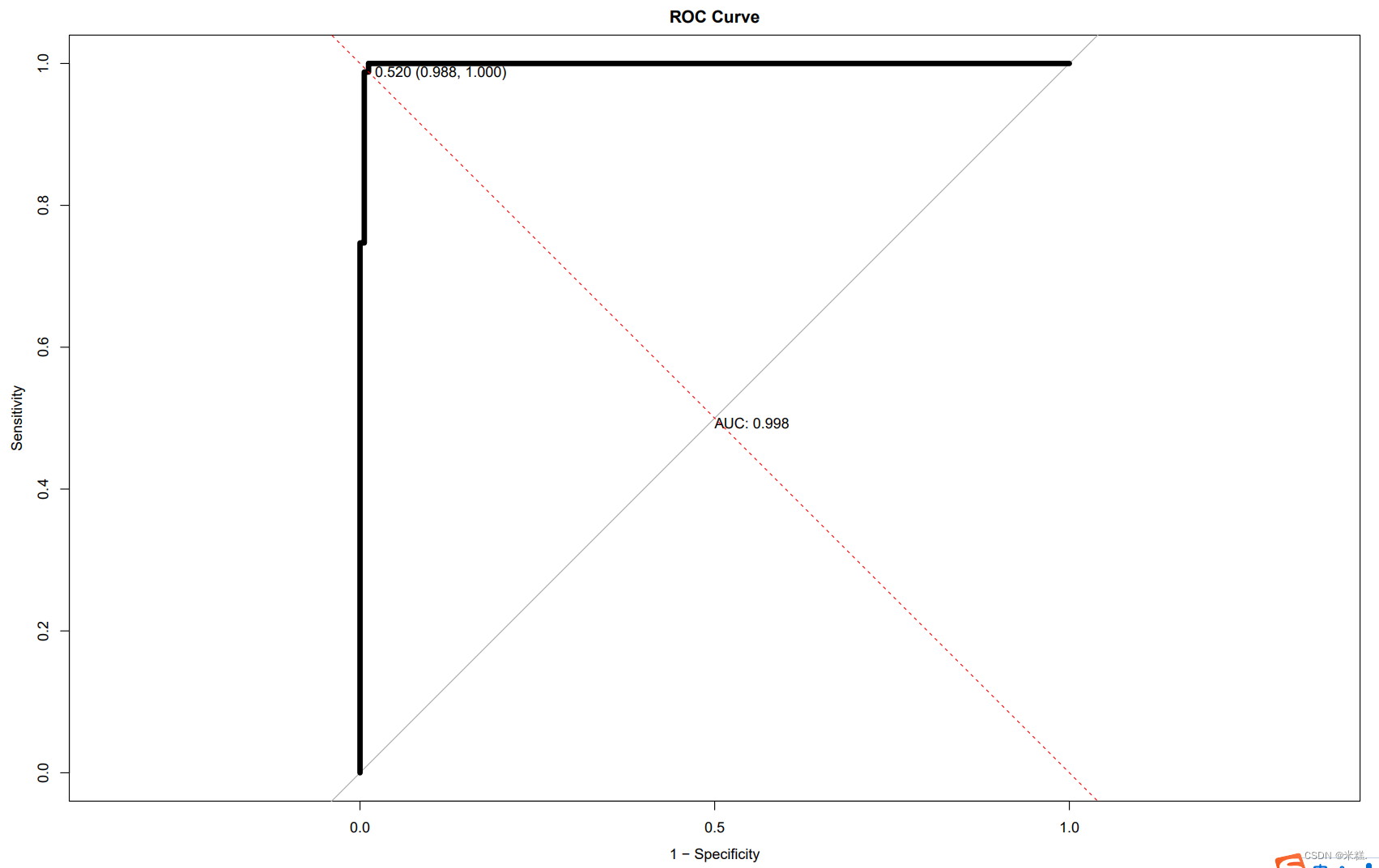
ROC曲线在生信中主要用于评估模型的性能,可以看到ROC曲线中有一条42度的直线,这条直线与ROC曲线所围成的面积越大,表示模型性能越好。
在 ROC 曲线上有几个重要的参数需要解读:
- 真阳性率: 也称为灵敏度,表示本身患病,同时被模型预测为患病的比例,计算公式为(模型正确预测的患病人数)/(实际患病的总人数)
- 假阳性率:实际为阴性,但是被模型预测为阳性 ,计算公式为(本来没患病但是被模型预测为患病的人数)/(实际患病的人数)
- AUC(Area Under the Curve): ROC 曲线下的面积,AUC 值越接近1,表示分类模型的性能越好,AUC 值越大通常意味着模型的准确性越高。
在 ROC 曲线中,我们希望曲线尽量向左上角凸起,即 TPR 高、FPR 低,这表示模型的性能较好。而 ROC 曲线下的面积 AUC 越大,则说明模型性能越好。


)






)


)






