作者:WeOLAP 团队 数据挖掘团队
擅长 OLAP 分析的 ClickHouse 不仅可以用于 vector search,还可承担起整条 embedding 的加工处理工作,All in one Pipeline 也让速度远超传统批处理框架数倍;检索性能虽无法与专业 sim 检索服务相媲美,但因“搜索分析一体化”,让它在 AI 近线处理占据一席之地。 本文工作由 vcc、 levi、 longpo、 zifei、 luis 等人协同完成
背景
在过去的一年里,大型语言模型 (LLM) 以及 ChatGPT 等产品吸引了全世界的想象力,推动新一轮技术浪潮。embedding 和 vector search(向量搜索)的概念是支持推荐、问答、图像搜索等功能的核心。我们发现社区中“向量搜索”的兴趣显著增加;具体来说,大家感兴趣了解的是:何时需要专门向量数据库,何时不需要?相比于语义性检索引擎(ES)与专业的高性能检索服务,OLAP 数仓的向量检索能力在场景有何区别?
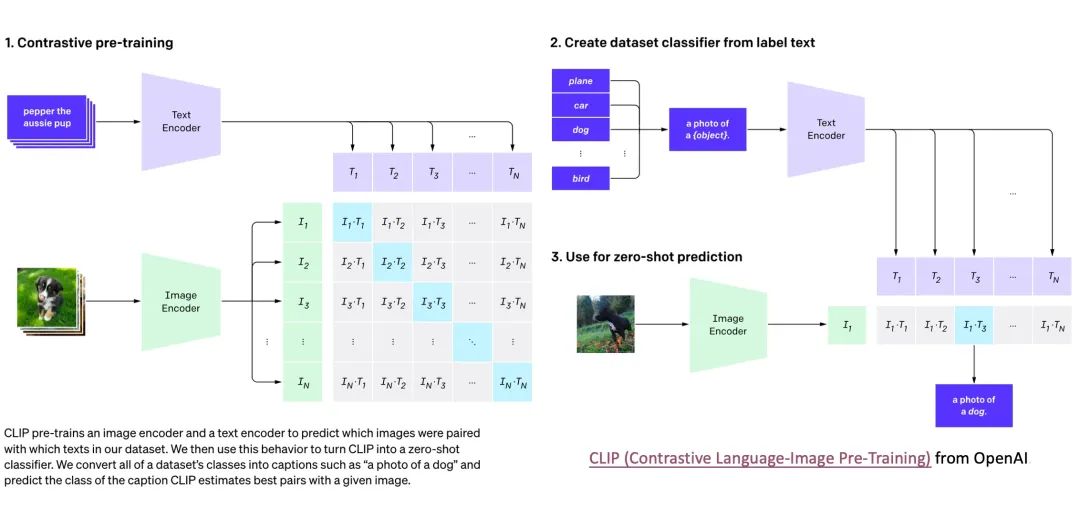
在调研对 ClickHouse 对向量检索/加工能力时,我们惊讶地发现, 现代 OLAP 数仓已具在其内部独立搭建 CLIP 等主流机器学习模型的数据处理全流程能力 (图 1),包含 embedding 推理生成,ETL 加工处理,召回检索,科学分析场景,实现 搜索分析体验一体化 !
于是,我们协助画像业务进行 Pipeline 架构改造,实现画像 embedding 从“季度更新”到“日更新”的功能架构升级,以及 All in One 分析处理体验;这让画像刻画“更实时、更准确”,诸多业务指标显著提升!

从向量检索说起
文本搜索:传统的检索是基于文本分词的精确匹配;早期全文检索引擎都是基于不同的索引方式(倒排索引,BTree 等)加上精确匹配和排序算法(BM25、TF-IDF)等实现的,代表如早期的 Elastic Search (ES);但它的局限性很显著,就是无法表达图像,音频,近似词等更多种模态中的通用信息;
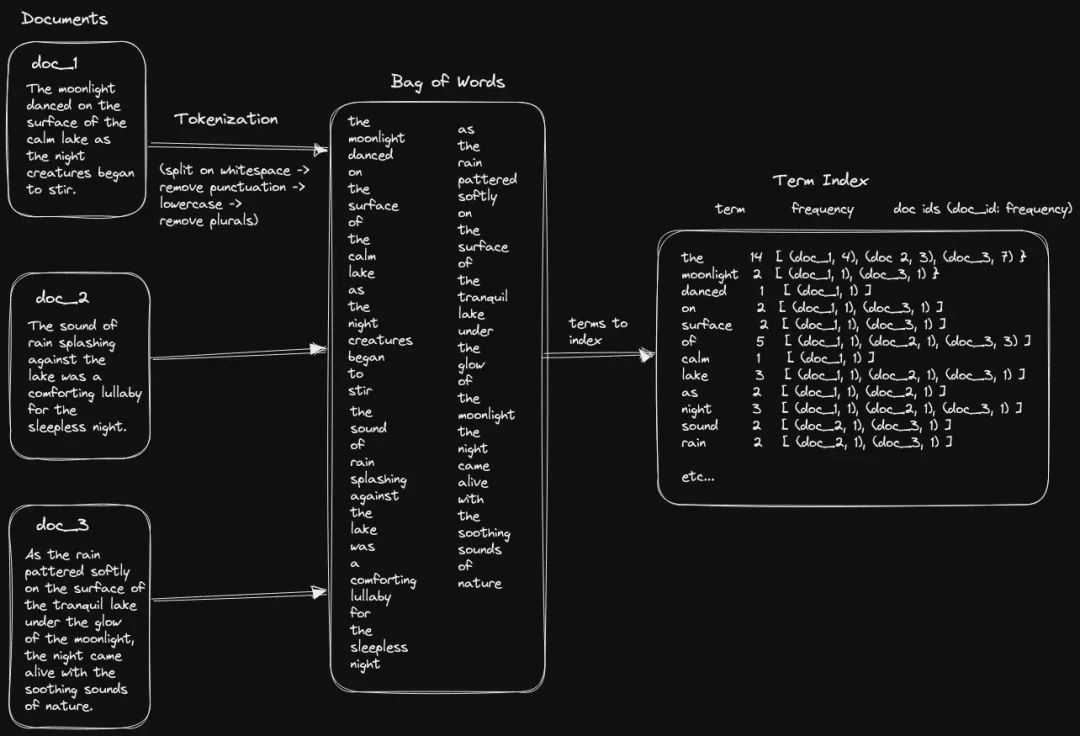
什么是 Embedding?
“万物皆可 Embedding,向量是 AI 理解世界的通用模式 ”:""An embedding is a mapping from discrete objects, such as words, to vectors of real numbers. — Tensorflow 社区
可以看到,Embedding 是真实世界中“离散”的实体,映射到“连续”向量空间的一种表示。这种“连续性”极大地增强了表示的易用性:
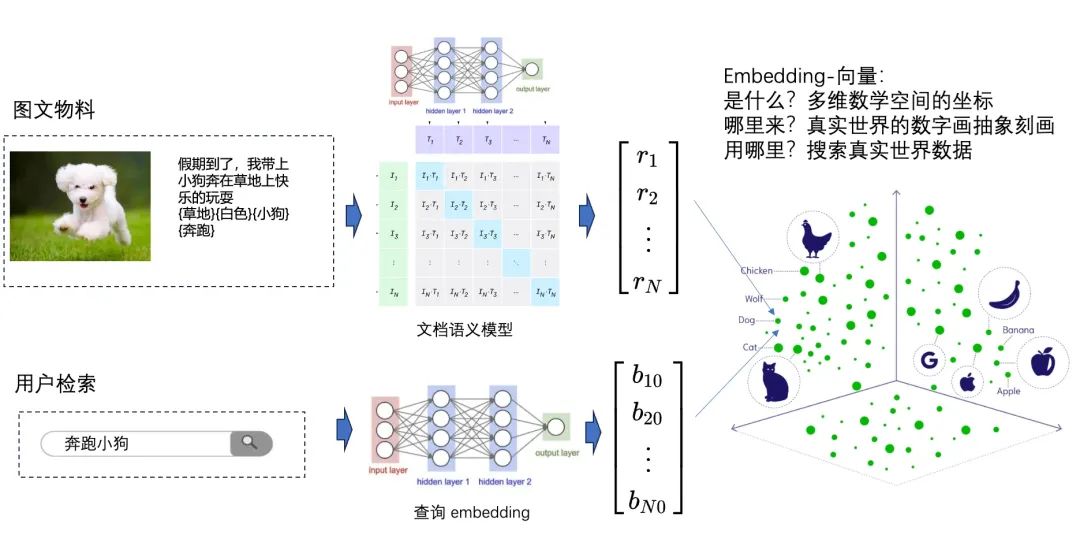
Sematic Search
语义检索:通用的语义检索,通过深度学习的训练,将真实世界数字化后的离散特征提取出来,投影到数学空间上,同时神奇的保留距离之间相似度的能力,这就是 embedding;例如:”图片“通过 embedding 映射在高维空间,图片的相似度检索就会变成“高维空间”Top K“距离求解”问题,也就是近似向量检索问题(Approximate Nearest Neighbor Search, ANNS)。在大模型出现之前,向量检索已经成熟并广泛应用在“推荐”、“文本/视频搜索”等领域了:

向量数据库介绍:
ChatGPT 掀起的大模型浪潮,embedding 在其中的核心地位,使得向量化数据库又成为时代新宠,各大数据库厂商和资本争相涌入:
如果说 LLM 是容易失忆的大脑,向量数据库就是海马体: 一方面,LLM 能浏览专用数据与知识,解决 Hallucination 的问题使回答更精准;另一方面,LLM 能回忆自己过往的经验与历史,更了解用户的需求,通过反思实现更好的个性化 AI Native : LLM + 交互 + 记忆(专有数据 + 个性化) + 多模态 Form Pinecone
大模型离不开向量检索:
多数厂商认为,为解决 LLM 无记忆,数据隐私等问题,向量数据库会成为未来大模型必然用到的组件,正如关系型数据库在 web 中的应用一样。为什么说大模型“没有记忆”,需要向量数据库呢?熟悉 LLM 的算法同学都了解,原生 LLM 的强大信息处理能力,仅限于有限的上下文“黄金窗口”;而有了向量数据库,LLM 可以检索到并组织起相关的“记忆碎片”,从而关联到海量的内容放入这个黄金窗口,因此也被人们誉为大模型的“海马体”。此外,embedding 作为一种数据脱敏的媒介,也可以降低中间数据传输的敏感性,对于数据隐私有一定的保护能力。看一个实际样例:

无记忆交互:LLM 世界知识被压缩为静态参数,模型不会随着交互记住记录和喜好,也无法调用额外的知识信息来辅助判断,因此只能根据历史训练做回答,经常产生幻觉。为解决这一问题,检索增强的“有记忆交互”便产生了.
有记忆交互:一个典型应用方法就是检索增强的语言模型(Retrieval Augmented LLMs),查询专用知识库和外部实时信息,帮助回答特定的问题。当模型需要记忆大量聊天记录或其它行业知识时,可将其存储处理后存在向量化数据库中,提问时匹配相似语料返回,使得答复更加有理有据、结合行业知识、减少幻觉。

市面上向量数据库总览:
如今市面上的向量数据库产品,大致分为两大类,一类是基于原生向量检索引擎实现了关系型数据库的开发;一类是基于原生数据库系统添加了向量检索功能:
- 从向量检索到数据库:Pinecone, weaviate ,chroma ,drant ..
- 从数据库到向量检索:Elasticsearch ,ClickHouse ,PG ,Redis ..
在我们的应用中,ClickHouse 以其出色的关系型查询性能成为了我们的首选:
我们再来看看 ClickHouse 社区官方宣传:“Specialized vector databases exist: who cares?ClickHouse is always the best : )”

这看起来确实有些嚣张了,那我们下面就用线上 case 来看看实际表现情况。
Vector Search in ClickHouse:
微信业务场景举例:
我们基于 ClickHouse 原生的向量数据库能力,在微信实际应用场景中进行了探索,取得了不错的效果:
1.用户 lookalike 定向场景:短视频红点投放中,例如客户提供万级量级种子包,画像系统使用 embedding 表征用户的特征和行为。为实现精准的人群 lookalike 投放,需要在数亿 embedding 中选择相似近邻来扩充人群包到百万甚至更多。原始业务为实现这一功能,基于批处理工具处理,难以精确求解;通过聚类方式求近似解也需要跑一周,且任务稳定性不足。算法工程师急需更便捷的工具流程来实现这一常用的业务功能。
2.文章 embedding 近似度分析:算法调试检索场景;例如实现一个——给“用户 A”推荐与 A“阅读习惯类似群体”阅读过的文章这个策略。研究员一般会采不同 embedding 模型 + 多类距离计算方式 + 不同的算法组合策等方式,尝试调试出主观上表现好召回策略,后续再上 AB 实验分析。此过程需要大量的手工调试分析,需要一种高效敏捷调试交互看板,进行策略探索;可以看到,我们主要关注近/离线加工场景中的向量化检索场景:特点是, 涉及计算量大(如 亿 * 亿 近似度计算),长时间批处理而非高频点查,频繁调试、含有额外二次计算环节 。此类场景在 ANN 服务/“sim 服务"中无法分析加工,传统数仓又无法高效查询,搬移数据繁琐,而 ClickHouse 提供的 Vector Search in OLAP 能力可以很好地满足这类需求。
如何使用:
在 ClickHouse 内利用 Array(FloatXX)来表示不同精度的 embedding,提供如下距离计算方式:
- Cosine Distance: cosineDistance(vector1, vector2),This gives us a Cosine similarity
- L2 Distance: L2Distance(vector1, vector2),This measures the L2 distance between 2 points
1.建表并导入数据:
CREATE TABLE laion
(
`url` String,
`caption` String,
`text_embedding` Array(Float32),
`image_embedding` Array(Float32),
`similarity` Float64
)
ENGINE = MergeTree
ORDER BY (similarity)
复制
2.查询分析:点查样例
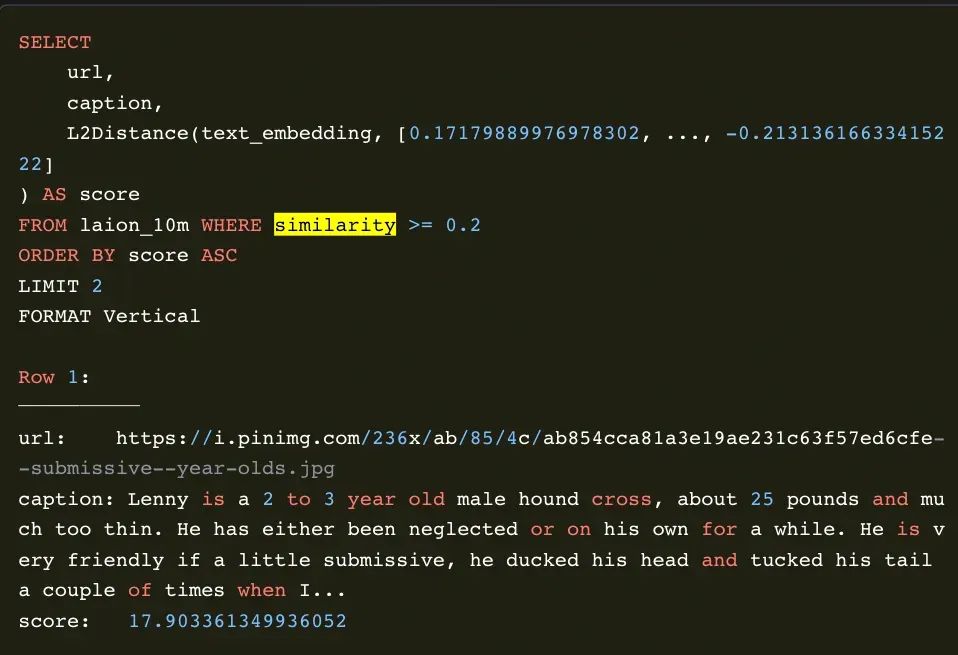

查询优化:
样例:拿一个实际业务 User-Items-Items 的查询优化举例,对于一个精确求解(暴力求解)的计算的需求,可通过一些简单优化提升性能,从 16s 优化到 1s;
算法需求描述:先求某个 id 对应的集合 Items_emb_set,再遍历每个 item 求解它离 items_emb_set 集合每个元素的平均值,并按照每个分类取距离最近一条;
可看到算法还是有些复杂的,通过 SQL 表达会让调试不同的组合策略更容易:
with ( -- id ->items_set
select groupUniqArray(itemid) from table
where xxx IN ('1234') and day_='2023-06-18' ) as itemid_filter_arr
,( -- items_ids -> [items_emb,items_emb]select groupArray(embedding) AS arr1 FROM tableWHERE emb_type = 'xxx' and has(itemid_filter_arr,itemid)) as emb_set
,embedding AS emb_l
,arrayReduce('avg',arrayMap(x -> cosineDistance(x,emb_l),emb_set)) as cosineDistance --
select itemid,title,xxx, 1-cosineDistance as similarity FROM table
WHERE emb_type = 'xxx' order by cosineDistance asc
limit 1 by xxx
复制
原始 SQL 需要跑 16s ,优化方式如下:
- SQL 改写:采用 with 替代 Join,减少冗余计算;prefilter 提前过滤不必要元素
- 数据结构优化:使用 zstd 压缩;float 32 -> bfloat 16,业务原始模型不需要这么高的精度,通过降低性能精度提升性能,这是模型训练常见的做法;如:reinterpretAsFloat32(bitAnd(reinterpretAsUInt32(toFloat320rZero (x)), 0xFFFF0000))
- 参数调优:对于百万到千万级的数据,part 数较少导致线程并行度低,通过指定线程,强制分片的方式提升性能,解决线程间数据倾斜问题。如:merge_tree_min_rows_for_concurrent_read,force_repartition_after_reading_from_merge_tree 等参数。

业务原始科学探索,采用 SparkSQL 直接检索,字符串处理性能极差,处理分钟级别,改进后秒内返回;

内核优化:上述 case 在数据量大的经过 SQL 优化仍然会出现计算超时且 CPU 并没有打满,于是我们打开 profile tool, 发现执行过程中有大量的 data copy,时间开销巨大,于是我们重写了 embedding distance 相关的计算函数,消除了不必要的内存拷贝,并优化了特定场景下的计算逻辑,减少运算指令数量,使性能提升 4X 以上,如下图所示:内核优化前耗时在内存拷贝上,优化后主要在计算。


索引优化:
最近邻搜索(NNS)通常会转化为性能更好的近似最近邻搜索(ANNS, Approximate Nearest Neighbor Search)问题来解决,一般有至少 10X 以上性能提升;借助市面上优秀库索引来做近似求解问题,可保证高性能(1ms)且高召回(95%以上),优秀的算法库诸如 FAISS, ScaNN, hnswlib:常见算法:
- 暴力检索:FLAT 结果 100% 召回,费算力
- 图搜索:HNSW 性能高,召回高,如 hnswlib
- 聚类倒排 + 量化 (IVF-PQ):faiss 的 IVFx_HNSWy + PQz 算法 10 ~ 30 倍压缩
- 树搜索:KD-Tree 、Annoy 实现简单,工业界较少用到 目前ClickHouse已支持的ANNS算法有Annoy和HNSW两类;社区版性能测下来还有有较大提升空间,会根据业务需要持续优化内核;

综合案例:近线流式加工处理 Pipeline 升级
案例背景:
OLAP 生态不仅可以做 vector search,还能做 emb 推理生成和 SQL 数据加工处理,我们看一个画像平台改造案例,穿插看一下该场景的通用泛化能力;早期画像采用“图谱标签”来表示用户画像,直观准确;近些年引入大模型 embedding 方式来进行补充;embedding 既能表现用户圈层、兴趣聚合等高维抽象关系,又具有较强的通用性和可拓展性;值得关注的是,用户画像和行为的 embedding 的生成更新的"新鲜度”,影响各业务对画像理解,涉及投放、推荐,增长等多个领域。
早期架构痛点:
- 多异构系统加工处理:原 Hadoop 生态加工处理慢,且涉及系统多,数据存多份,流程复杂,调试麻烦;业务描述,常出现流程 emb 数据有重复,但是涉及维护团队多很难定位
- 缺乏联合检索能力:无法进行多列联合检索能力,如 vector search + 全文检索 + 统计
- 新鲜度缺失:原有架构采用离线处理生态,无法进行 emb 画像实时生成和处理,导致线上画像新鲜度不够
改造前:PySpark 作数据加工,Python 脚本 hnswlib 库计算精准投放,ElasticSearch 全文检索,OLAP 做数据科学,离线全量推理耗时一周左右。
改造后:从离线架构到近线架构升级,近线实时增量处理,且流批一体,数据流转尽量少,生态统一,SQL 表达(部分功能灰度上线中);
emb 生成服务:
通用 Embedding 生成服务:基于数据中心积累的一系列通用 Embedding 模型,我们可以便捷地嵌入 ClickHouse 能力之中,提供适配不同业务场景的 Embedding 计算服务。 用户 Embedding 生成服务:将用户的最新的画像和行为,表达为 embedding 从而刻画兴趣特征,它的更新频率直接影响整个微信各个业务对用户理解。此前采用传统批处理系统进行 embedding 处理生成,因为数据量大,流程繁琐造成 Pipeline 不稳定,维护工作量大,更新频率一般为季度;
下面我们来进行通过 ClickHouse 原有 SQL 能力 + udf 进行改造:
1:编写 embedding 推理 udf:可本地 GPU 调用模型,也可以远程调用推理服务;

2.注册:udf 函数 text2Embedding yaml 文件
cat /etc/clickhouse-server/text2Embedding_function.yamlfunction:name: text2Embeddingtype: executable_poolpool_size: 2format: TabSeparatedcommand: 'text2Embedding.py'return_type: Array(Float32)argument:type: String
复制
3.查询:
insert into xxx select text2Embedding(text) from table
复制
性能优化效果:
借助 ClickHouse 内的 udf 函数功能,再实现推理 Python 脚本后,将含有 ClickHouse 的镜像部署到纯 GPU 计算集群,即实现高性能 emb 推理生成 pipeline(打满 A10 双卡 GPU);
实时推荐训练都有明显的潮汐资源利用现象,借助 CK 存算分离的架构,可利用算力平台非保障低优 GPU 资源 (A100,H800) ,更好利用实时训练”凌晨低峰空闲“资源;


注:性能瓶颈主要在本地 GPU 推理服务上,已不在 ClickHouse udf 调用上和 IO 上;当然也可在 CPU 集群通过 udf batch 调用远程 tfcc 等推理服务。
线上采用 1.2B 画像大模型,经过多进程+池化重用+参数调优+数据结构优化+批处理等手段,可跑满 A10 CPU + GPU ;推理性能仍有不少优化空间,后续有需要会继续与 tfcc 团队、画像团队持续优化;
| 机器环境 | 线上模型 mt5-large 1.2B 处理能力 |
|---|---|
| CPU,IT5.16XLARGE256 | xx row/s |
| GPU,NVIDIA A10 2 卡 (保障资源) | 256 rows/sec |
| GPU,NVIDIA A100 8 卡(空闲期低优资源) | 2600 rows/sec |
| GPU,NVIDIA H800 8 卡(空闲期低优资源) | xx rows/sec |
部分调优思路:

训练数据加工:
user embedding 生成后,为了支持后续召回,需要将 user embedding 与 item embedding 进行关联,格式化处理,后续供给BERDE轻量级“双塔语义编码模型”进行训练;此过程中主要是涉及亿级表 JOIN 操作,字符串操作,模型训练大 IO 串行读取,都是 SQL 擅长表达的范式,更复杂的操作可通过物化视图和字典来完成。
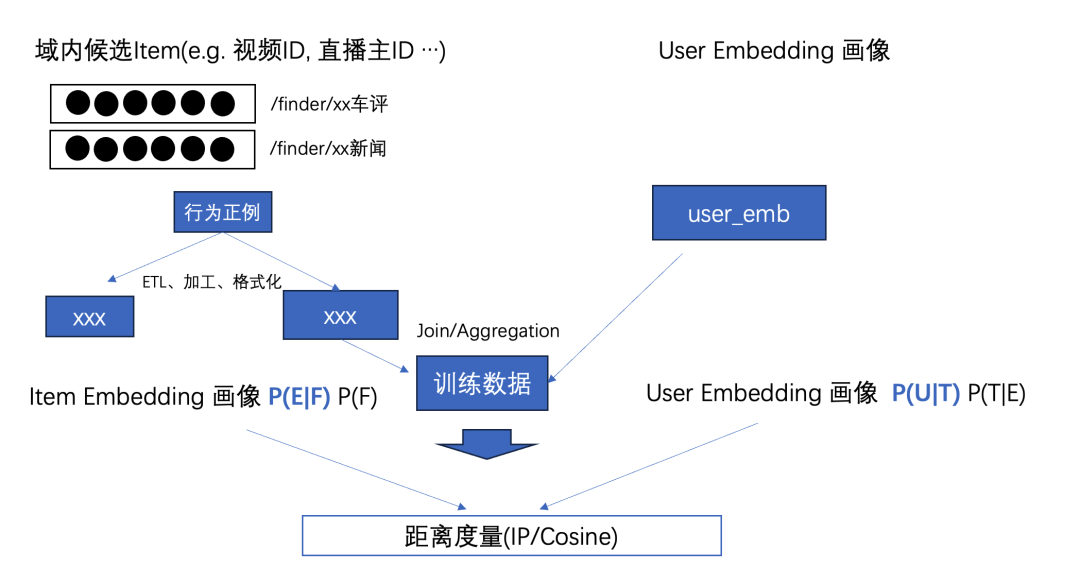
类似的 AI 流程中的“加工场景”比较常见,如 NLP 当中也存在 ETL 和文档去重流程,以及统计分析和全文检索需求,都有类似的加工 pipeline;
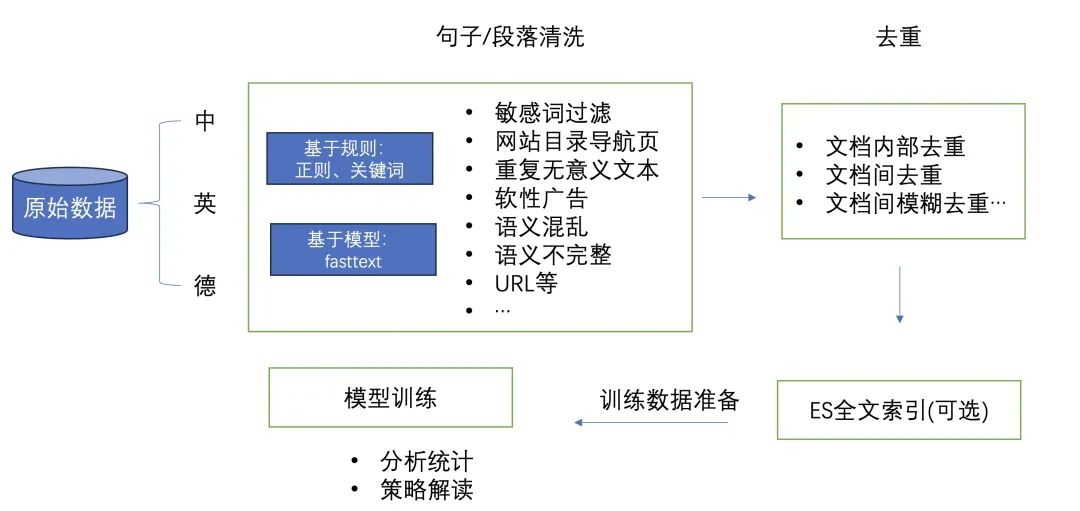
ods/dwd 表采用 OLAP 在加工处理适用场景:
- 对于中等规模(亿级)数据之间的 join,cube, bitmap 运算,ETL 等 SQL 操作,性能提升显著
- 超大规模数据,OLAP 稳定性尚不成熟,传统批处理组件当前更有优势
全文检索:
对于一些"文本探索"的联合查询通常需要全文检索功能,ClickHouse 早期也支持; ClickHouse 近期已支持"倒排索引”,性能更为出色,线上亿级数据测试可到达亚秒内返回;与专业的 ES 相比主要缺乏相关性算法支持(BM25 等),但 数仓更多优势在于统计分析与海量数据加工处理能力,已可成为一些 ES 场景的平替产品 。

画像自助分析:
根据分类标签进行画像分析,提取用户包是各类投放、广告系统的对标签的常见用法,为了提升性能,通常这些运算都是建立在 bitmap 上的,更详细性能优化可参考《BitBooster 让微信分析提速 10 倍 》 ;
其它生态:
- 数据流:通过 ClickHouse -> Pulsar -> mkv ; ClickHouse -> hdfs -> fkv 提供线上业务支持;
- 精准投放:主要涉及 emb 点查分析,emb 批处理(小表对大表计算距离),emb 海量计算等场景
- 科学探索:精细化运营 BI 看板查询,样本质量分析
- 推理探索:通过 udf 远程调用推理服务,使用一条 SQL 完成“模型调用”+“数据分析”的融合查询
总结:何时需要一个专用的向量数据库?
仓内优势:离/近线分析处理 All in One 如果你的数据正巧要在数仓内存储一份,并且有“向量检索”以及"科学探索"需求,偶尔进行批处理,OLAP 数仓内将是你的最佳选择!算法同学将从四处奔走各个系统中解脱出来:
- ALL in One: 科学探索,全文检索、数据加工 Pipeline,Vector Search,训练存储一体化,省去了多个存储系统之间的交互流程问题与多份存储 ,这多数时候是真实痛点 。
- SQL 表达:交互友好,高效的元数据过滤(post-filter/pre-filter),便捷的聚合统计操作,丰富的函数,以及 udf 扩展功能,让自定义扩展游刃有余。
- 海量数据下的高性能:借助 ClickHouse 原始引擎的向量化执行、极致工程实现、MPP 分布式架构,将提供 TB 级数据 5X 以上性能提升,远超“传统批处理”框架的加工分析能力。
- 融合检索:全文检索 + vector 检索 + 统计分析 + 即时推理 一站式 SQL 体验 例如,回答问题:作者是小 A,文章中含有"大模型"关键字,且 embedding 近似小于 0.03 ,在各类别下相似文章的分别有多少 ?
你很多时候更需要专业的 sim 检索服务:All in One 的支持也意味着部分“专项性能缺失”,以下场景建议采用更专业的“sim 检索服务”,“向量数据库”支持:
- 高 qps 下的低延迟:在线推荐服务召回通常有更高性能要求,优秀的 sim 检索服务可提供 100 万 qps 的 1ms 低延迟查询,且有 98%以上的召回率;
- 与业务系统的亲和度高:sim 检索服务对业务亲和度更高,定制化专项需求更友好,而标准数据库则更注重其通用型; 此类专用系统出色的能力,都 OLAP 架构设计望尘莫及的;
湖仓融合趋势和现代 OLAP 的发展,让大数据数仓和专业数据库的边界正在日趋模糊,那它们的边界又该哪里?实践会给我们答案。
道阻且长,行则将至;行而不辍,未来可期。
引用:
- ClickHouse with AI
- Vector Search with CLickHouse Vector Search with ClickHouse - Part 1
- Vector Database 研究报告


)



ALU)
 并查集)




)






