
论文题目: DB-LLM: Accurate Dual-Binarization for Efficient LLMs
论文链接: https://arxiv.org/abs/2402.11960
大型语言模型(LLMs)的双重二值化方法:新纪元的高效自然语言处理。随着大型语言模型(LLMs)在自然语言处理领域取得显著进展,它们在实际应用中却受到高昂的内存和计算消耗的限制。而量化作为提高LLMs计算效率的最有效手段之一,却在现有的超低位宽量化中遇到了严重的准确性下降问题。
为此,我们在本论文中提出了一种针对LLMs的新颖双重二值化方法——DB-LLM,在微观层面,我们综合考虑了两比特位宽的准确性优势和二值化的效率优势,引入了灵活的双重二值化(FDB)技术。通过将2位量化权重分割为两套独立的二进制集合,FDB在保证表示准确性的同时,引入了灵活性,利用二值化的高效位操作,并保持了超低位量化的高稀疏性。在宏观层面,我们发现了LLMs在量化后预测中存在的失真问题,即与样本模糊性相关的偏差。
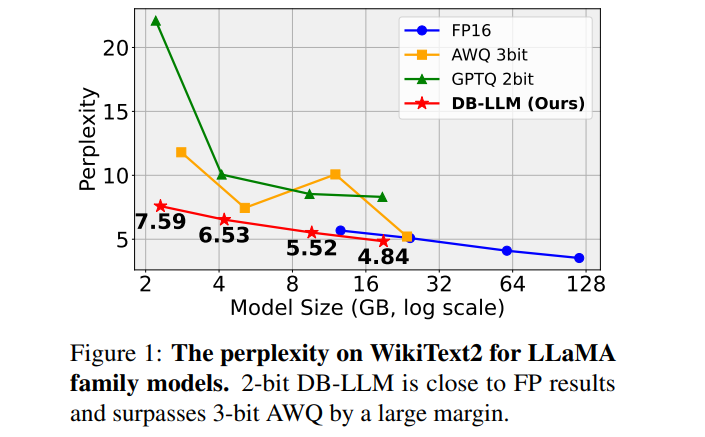
我们提出了偏差感知蒸馏(DAD)方法,使模型能够根据不同样本进行不同的关注。**全面的实验表明,我们的DB-LLM不仅在超低位量化方面大幅超越当前最先进技术(例如,复杂度从9.64降至7.23),而且在相同位宽下,与最先进方法相比,计算消耗额外减少了20%**。
01. 引言
超低位量化(≤ 4位)作为一种极其高效的量化形式,能实现超过8倍的内存压缩比。尽管这些专门的仅权重量化方案在存储消耗上实现了节省,但它们仍无法避免昂贵的浮点运算。我们注意到,这些量化方案会导致严重的准确性下降。例如,尽管应用了先进的2位量化技术,65B模型的性能仍然略低于7B模型。
本文的动机包含微观层面和宏观层面两个方面:
-
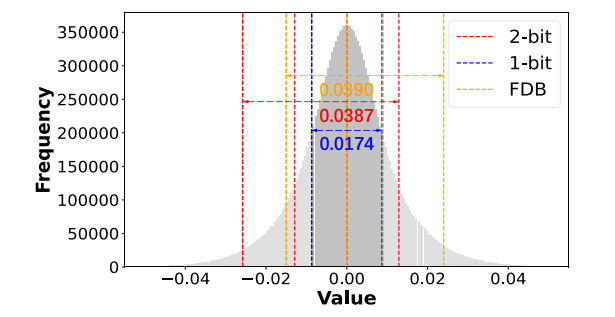
微观层面,近期研究表明,LLMs的权重呈对称高斯分布,且少部分显著权重对量化性能至关重要。在多低位量化的角度进行深入探究时发现,二值化受限于表征能力较弱,且剩余两级权重趋向于零,导致忽视了关键的显著权重,从而产生较高的损失值。而2位量化自然克服了表征瓶颈,虽然最小损失点显著降低,但损失曲面仍然陡峭,带来优化难度。因此,为结合二值化的高效率和2位量化的灵活表征能力,提出灵活的双重二值化(FDB)方法。
-
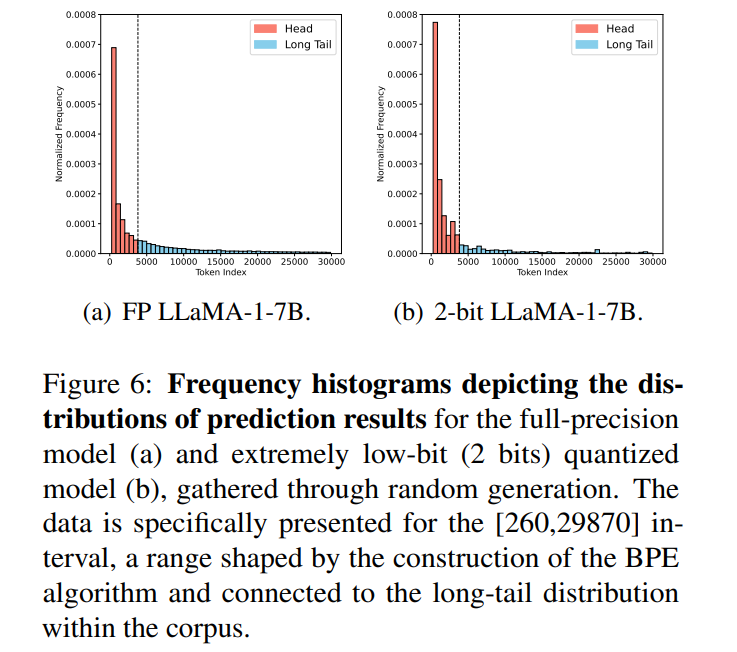
宏观层面,量化的大型语言模型在预测偏好上的长尾分布存在偏差。当前主流大型语言模型的构建基于利用长尾语料库的字节对编码(BPE),而全精度LLMs的预测偏好遵循长尾分布。然而,极低位模型的预测偏离了此分布,显示出增加的失真,特别是在倾向于预测词汇表中高频头部类别。对比同样输入下,低位模型预测常见头部类别的概率约是预测不常见尾部类别的1.6倍,表明了对更普遍类别的偏见。通过信息熵度量失败预测的不确定性,发现量化模型在处理含糊样本时的挑战,倾向于更保守的预测。因此,提出了偏差感知蒸馏(DAD)方法,通过利用一对熵(即教师-学生熵)作为难度指标来优先处理不确定样本。
为解决这些问题,我们提出了一种新型的双重二值化方法,称为DB-LLM,以实现精确的2位LLMs。具体来说,我们首先引入灵活的双重二值化(FDB),通过灵活的双二值化器增强表示能力,同时充分利用二值化参数的效率优势。其次,我们提出了偏差感知蒸馏(DAD)来减轻扭曲偏好,这种方法通过重加权蒸馏损失来放大样本间的模糊性,使低位LLMs能够感知每个样本的不确定性,实现平衡的知识传递。
02. 本文方法
2.1 灵活的双重二值化(Flexible Dual Binarization)
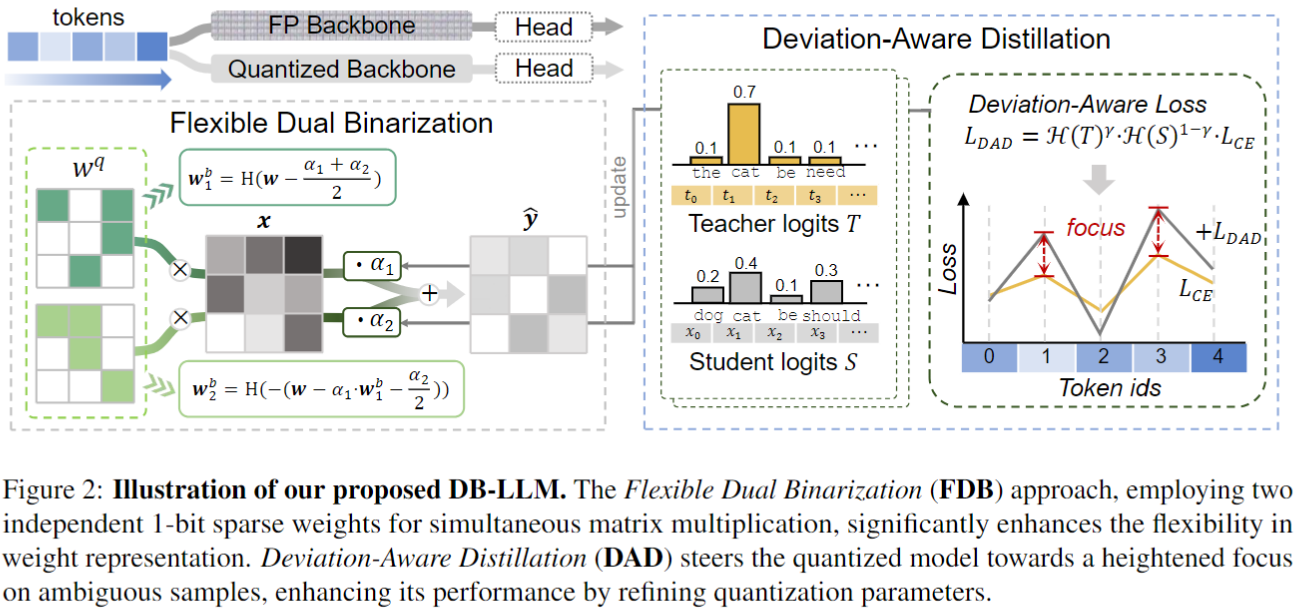
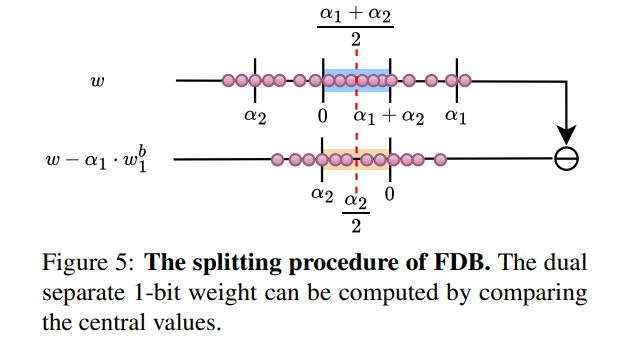
FDB方法结合了二值化的高效性和2位量化的准确性。它将2位量化的权重分割为两组独立的1位二进制数,并映射到0和1,旨在同时增强表示能力和利用二值化的位运算效率。
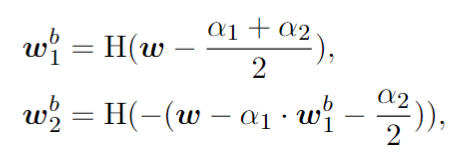
通过这种方式,FDB不仅保持了超低位量化的高稀疏性特点,还提高了对权重的灵活表示,使损失曲面更加平坦,并降低了损失。
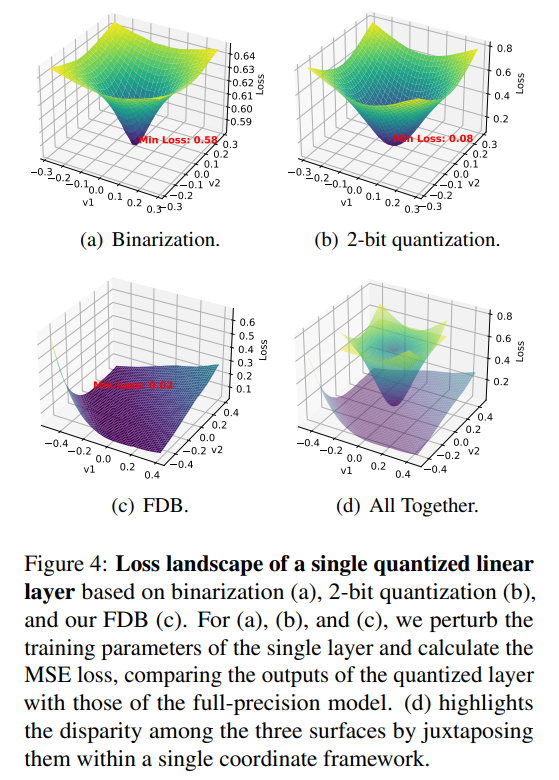
具体来说,FDB首先从相对较高位宽的LLM中继承性能,然后通过微调尺度参数进一步增强表示能力。FDB将2位量化权重分为两个1位权重,并分别为它们分配缩放因子α1和α2,这些参数将在微调阶段进行优化。
2.2 偏差感知蒸馏(Deviation-Aware Distillation)
DAD方法是为了解决超低位量化后LLM的预测偏差问题而提出的。研究发现,经过量化的模型更倾向于预测高频的头部类别,而不是低频的尾部类别,从而表现出对常见类别的偏见。
DAD通过利用教师模型和学生模型的熵作为样本难度的指标,优先处理不确定性高的样本。它通过在蒸馏损失函数中引入教师-学生联合熵,重新加权损失函数,使低位模型更加关注模棱两可的样本,从而实现从全精度教师模型到量化模型的更平衡的知识转移。
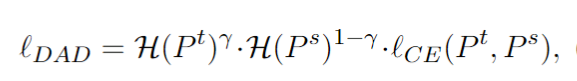
03. 实验效果
生成任务上的困惑度指标: 在生成任务中,DB-LLM模型展示了出色的性能。尤其在使用2位量化时,该模型在不同规模的LLaMA家族模型(如LLaMA-1-30B和LLaMA-1-65B)上表现优异。例如,在LLaMA-1-30B模型上,DB-LLM实现了5.52的困惑度(Perplexity),而在LLaMA-1-65B模型上达到了4.84。这些结果不仅接近全精度LLaMA-1-7B模型的困惑度(5.68),甚至优于其他3位量化方法,如AWQ。这一成果突显了DB-LLM在保持高性能的同时,有效降低量化位宽的能力。
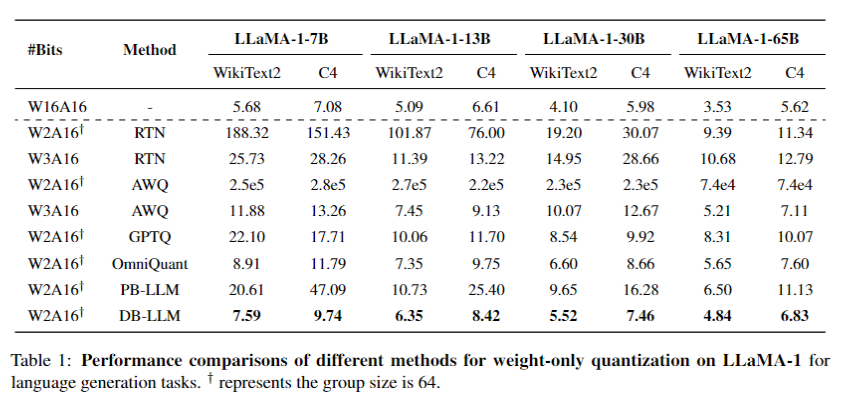
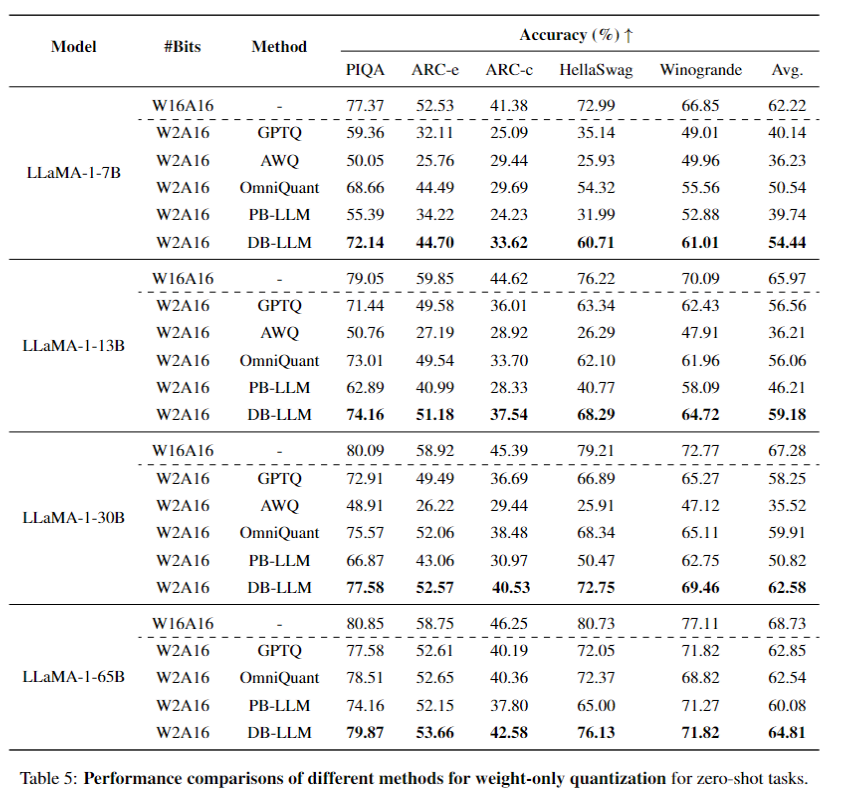
零样本(zero-shot)任务效果: 在零样本任务中,DB-LLM同样表现出色。在多个零样本任务(如PIQA、ARC-e、ARC-c、HellaSwag和Winogrande)中,DB-LLM在2位量化情况下均实现了令人满意的准确度,全面超越其他方法。具体来说,在LLaMA-1-7B模型上,DB-LLM在这些任务中的平均准确度明显高于其他量化方法,显示了其在处理零样本任务时的高效性和通用性。
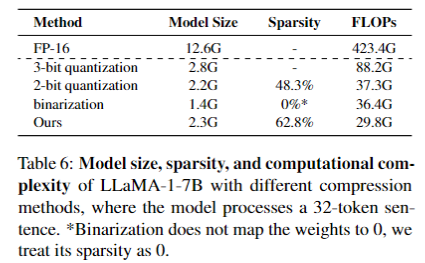
节省存储和计算效率: 在存储和计算效率方面,DB-LLM取得了显著的成果。在LLaMA-1-7B模型上,DB-LLM将模型的存储空间从12.6G降低至2.3G。同时,在计算效率方面,除了受益于位运算,由于权重稀疏性(超过60%)得以提升,相比全精度模型(FP16),DB-LLM将单次推理所需的浮点运算数(FLOPs)从423.4G大幅减少至29.8G,降低了约14.2倍。这种显著的降低不仅在计算资源受限的设备上具有重要价值,同时也减轻了存储和计算的负担。
04. 总结
文中介绍的DB-LLM模型通过结合柔性双重二值化(FDB)方法和偏差感知蒸馏(DAD)方法,有效提升了大型语言模型(LLM)在超低位量化情况下的性能和效率。FDB方法有效地结合了二值化的运算效率和2位量化的准确性,通过将2位量化的权重分割成两组1位二进制数,不仅保持了超低位量化的高稀疏性,还提高了权重的灵活表示能力。而DAD方法则针对超低位量化后模型的预测偏差问题,通过利用教师-学生模型的熵作为样本难度的指标,优先处理不确定性高的样本,实现了从全精度教师模型到量化模型的更平衡的知识转移。这两种方法的结合使DB-LLM在保持低计算需求的同时,也在精度上达到了超越当前最先进技术的水平。
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区







)











