第二十四章:类元编程
每个人都知道调试比一开始编写程序要困难两倍。所以如果你在编写时尽可能聪明,那么你将如何调试呢?
Brian W. Kernighan 和 P. J. Plauger,《编程风格的要素》¹
类元编程是在运行时创建或自定义类的艺术。在 Python 中,类是一等对象,因此可以使用函数在任何时候创建一个新类,而无需使用 class 关键字。类装饰器也是函数,但设计用于检查、更改甚至替换装饰的类为另一个类。最后,元类是类元编程的最高级工具:它们让你创建具有特殊特性的全新类别的类,例如我们已经看到的抽象基类。
元类很强大,但很难证明其合理性,甚至更难正确使用。类装饰器解决了许多相同的问题,并且更容易理解。此外,Python 3.6 实现了 PEP 487—更简单的类创建自定义,提供了支持以前需要元类或类装饰器完成的任务的特殊方法。²
本章按复杂性递增的顺序介绍了类元编程技术。
警告
这是一个令人兴奋的话题,很容易让人着迷。因此,我必须提供这些建议。
为了可读性和可维护性,你可能应该避免在应用代码中使用本章描述的技术。
另一方面,如果你想编写下一个伟大的 Python 框架,这些就是你的工具。
本章新内容
第一版《流畅的 Python》“类元编程”章节中的所有代码仍然可以正确运行。然而,由于自 Python 3.6 以来添加了新功能,一些先前的示例不再代表最简单的解决方案。
我用不同的示例替换了那些示例,突出了 Python 的新元编程特性或添加了进一步的要求,以证明使用更高级技术的合理性。一些新示例利用类型提示提供了类构建器,类似于 @dataclass 装饰器和 typing.NamedTuple。
“现实世界中的元类” 是一个关于元类适用性的高层考虑的新部分。
提示
一些最好的重构是通过删除由更新和更简单的解决相同问题的方法所导致的冗余代码来实现的。这适用于生产代码以及书籍。
我们将从审查 Python 数据模型中为所有类定义的属性和方法开始。
类作为对象
像 Python 中的大多数程序实体一样,类也是对象。每个类在 Python 数据模型中都有一些属性,这些属性在《Python 标准库》的“内置类型”章节中的 “4.13. 特殊属性” 中有文档记录。这本书中已经多次出现了其中的三个属性:__class__、__name__ 和 __mro__。其他类的标准属性包括:
cls.__bases__
类的基类元组。
cls.__qualname__
类或函数的限定名称,这是从模块的全局范围到类定义的点路径。当类在另一个类内部定义时,这是相关的。例如,在 Django 模型类中,比如 Ox,有一个名为 Meta 的内部类。Meta 的 __qualname__ 是 Ox.Meta,但它的 __name__ 只是 Meta。此属性的规范是 PEP 3155—类和函数的限定名称。
cls.__subclasses__()
此方法返回类的直接子类列表。该实现使用弱引用以避免超类和其子类之间的循环引用——后者在其__bases__属性中保留对超类的强引用。该方法列出当前内存中的子类。尚未导入的模块中的子类不会出现在结果中。
cls.mro()
解释器在构建类时调用此方法,以获取存储在类的__mro__属性中的超类元组。元类可以重写此方法以自定义正在构建的类的方法解析顺序。
提示
此部分提到的属性都不会被dir(…)函数列出。
现在,如果一个类是一个对象,那么一个类的类是什么?
类型:内置类工厂
我们通常认为type是一个返回对象类的函数,因为type(my_object)的作用是返回my_object.__class__。
然而,type是一个在用三个参数调用时创建新类的类。
考虑这个简单的类:
class MyClass(MySuperClass, MyMixin):x = 42def x2(self):return self.x * 2
使用type构造函数,你可以用这段代码在运行时创建MyClass:
MyClass = type('MyClass',(MySuperClass, MyMixin),{'x': 42, 'x2': lambda self: self.x * 2},)
那个type调用在功能上等同于之前的class MyClass…块语句。
当 Python 读取一个class语句时,它调用type以使用这些参数构建类对象:
name
出现在class关键字之后的标识符,例如,MyClass。
bases
在类标识符之后的括号中给出的超类元组,如果在class语句中未提及超类,则为(object,)。
dict
属性名称到值的映射。可调用对象变成方法,就像我们在“方法是描述符”中看到的那样。其他值变成类属性。
注意
type构造函数接受可选的关键字参数,这些参数会被type本身忽略,但会原封不动地传递到__init_subclass__中,后者必须消耗这些参数。我们将在“介绍 init_subclass”中学习这个特殊方法,但我不会涉及关键字参数的使用。更多信息,请阅读PEP 487—更简单的类创建自定义。
type类是一个元类:一个构建类的类。换句话说,type类的实例是类。标准库提供了一些其他元类,但type是默认的:
>>> type(7)
<class 'int'>
>>> type(int)
<class 'type'>
>>> type(OSError)
<class 'type'>
>>> class Whatever:
... pass
...
>>> type(Whatever)
<class 'type'>
我们将在“元类 101”中构建自定义元类。
接下来,我们将使用内置的type来创建一个构建类的函数。
一个类工厂函数
标准库有一个类工厂函数,在本书中出现了多次:collections.namedtuple。在第五章中,我们还看到了typing.NamedTuple和@dataclass。所有这些类构建器都利用了本章介绍的技术。
我们将从一个用于可变对象类的超级简单工厂开始——这是@dataclass的最简单替代品。
假设我正在编写一个宠物店应用程序,我想将狗的数据存储为简单记录。但我不想写这样的样板代码:
class Dog:def __init__(self, name, weight, owner):self.name = nameself.weight = weightself.owner = owner
无聊…每个字段名称出现三次,而且那些样板代码甚至不能为我们提供一个漂亮的repr:
>>> rex = Dog('Rex', 30, 'Bob')
>>> rex
<__main__.Dog object at 0x2865bac>
借鉴collections.namedtuple,让我们创建一个record_factory,可以动态创建像Dog这样的简单类。示例 24-1 展示了它应该如何工作。
示例 24-1. 测试record_factory,一个简单的类工厂
>>> Dog = record_factory('Dog', 'name weight owner') # ①>>> rex = Dog('Rex', 30, 'Bob')>>> rex # ②Dog(name='Rex', weight=30, owner='Bob')>>> name, weight, _ = rex # ③>>> name, weight('Rex', 30)>>> "{2}'s dog weighs {1}kg".format(*rex) # ④"Bob's dog weighs 30kg">>> rex.weight = 32 # ⑤>>> rexDog(name='Rex', weight=32, owner='Bob')>>> Dog.__mro__ # ⑥(<class 'factories.Dog'>, <class 'object'>)
①
工厂可以像namedtuple一样调用:类名,后跟用单个字符串中的空格分隔的属性名称。
②
漂亮的repr。
③
实例是可迭代的,因此它们可以在赋值时方便地解包…
④
…或者当传递给format等函数时。
⑤
记录实例是可变的。
⑥
新创建的类继承自object——与我们的工厂无关。
record_factory的代码在示例 24-2 中。³
示例 24-2. record_factory.py:一个简单的类工厂
from typing import Union, Any
from collections.abc import Iterable, IteratorFieldNames = Union[str, Iterable[str]] # ①def record_factory(cls_name: str, field_names: FieldNames) -> type[tuple]: # ②slots = parse_identifiers(field_names) # ③def __init__(self, *args, **kwargs) -> None: # ④attrs = dict(zip(self.__slots__, args))attrs.update(kwargs)for name, value in attrs.items():setattr(self, name, value)def __iter__(self) -> Iterator[Any]: # ⑤for name in self.__slots__:yield getattr(self, name)def __repr__(self): # ⑥values = ', '.join(f'{name}={value!r}'for name, value in zip(self.__slots__, self))cls_name = self.__class__.__name__return f'{cls_name}({values})'cls_attrs = dict( # ⑦__slots__=slots,__init__=__init__,__iter__=__iter__,__repr__=__repr__,)return type(cls_name, (object,), cls_attrs) # ⑧def parse_identifiers(names: FieldNames) -> tuple[str, ...]:if isinstance(names, str):names = names.replace(',', ' ').split() # ⑨if not all(s.isidentifier() for s in names):raise ValueError('names must all be valid identifiers')return tuple(names)
①
用户可以将字段名称提供为单个字符串或字符串的可迭代对象。
②
接受类似于collections.namedtuple的前两个参数;返回一个type,即一个类,其行为类似于tuple。
③
构建属性名称的元组;这将是新类的__slots__属性。
④
此函数将成为新类中的__init__方法。它接受位置参数和/或关键字参数。⁴
⑤
按照__slots__给定的顺序产生字段值。
⑥
生成漂亮的repr,遍历__slots__和self。
⑦
组装类属性的字典。
⑧
构建并返回新类,调用type构造函数。
⑨
将由空格或逗号分隔的names转换为str列表。
示例 24-2 是我们第一次在类型提示中看到type。如果注释只是-> type,那意味着record_factory返回一个类,这是正确的。但是注释-> type[tuple]更精确:它表示返回的类将是tuple的子类。
record_factory在示例 24-2 的最后一行构建了一个由cls_name的值命名的类,以object作为其唯一的直接基类,并且具有一个加载了__slots__、__init__、__iter__和__repr__的命名空间,其中最后三个是实例方法。
我们可以将__slots__类属性命名为其他任何名称,但然后我们必须实现__setattr__来验证被分配的属性名称,因为对于类似记录的类,我们希望属性集始终相同且顺序相同。但是,请记住,__slots__的主要特点是在处理数百万个实例时节省内存,并且使用__slots__有一些缺点,讨论在“使用 slots 节省内存”中。
警告
由record_factory创建的类的实例不可序列化,也就是说,它们无法使用pickle模块的dump函数导出。解决这个问题超出了本示例的范围,本示例旨在展示type类在简单用例中的应用。要获取完整解决方案,请查看collections.namedtuple的源代码;搜索“pickling”一词。
现在让我们看看如何模拟更现代的类构建器,比如typing.NamedTuple,它接受一个用户定义的class语句编写的类,并自动增强其功能。
引入__init_subclass__。
__init_subclass__和__set_name__都在PEP 487—更简单的类创建自定义中提出。我们第一次在“LineItem Take #4: Automatic Naming of Storage Attributes”中看到描述符的__set_name__特殊方法。现在让我们研究__init_subclass__。
在第五章中,我们看到typing.NamedTuple和@dataclass允许程序员使用class语句为新类指定属性,然后通过类构建器增强该类,自动添加必要的方法如__init__,__repr__,__eq__等。
这两个类构建器都会读取用户class语句中的类型提示以增强类。这些类型提示还允许静态类型检查器验证设置或获取这些属性的代码。然而,NamedTuple和@dataclass在运行时不利用类型提示进行属性验证。下一个示例中的Checked类会这样做。
注意
不可能支持每种可能的静态类型提示进行运行时类型检查,这可能是为什么typing.NamedTuple和@dataclass甚至不尝试的原因。然而,一些也是具体类的类型可以与Checked一起使用。这包括通常用于字段内容的简单类型,如str,int,float和bool,以及这些类型的列表。
示例 24-3 展示了如何使用Checked构建Movie类。
示例 24-3. initsub/checkedlib.py:创建Checked的Movie子类的 doctest
>>> class Movie(Checked): # ①... title: str # ②... year: int... box_office: float...>>> movie = Movie(title='The Godfather', year=1972, box_office=137) # ③>>> movie.title'The Godfather'>>> movie # ④Movie(title='The Godfather', year=1972, box_office=137.0)
①
Movie继承自Checked—我们稍后将在示例 24-5 中定义。
②
每个属性都用构造函数进行了注释。这里我使用了内置类型。
③
必须使用关键字参数创建Movie实例。
④
作为回报,您会得到一个漂亮的__repr__。
用作属性类型提示的构造函数可以是任何可调用的函数,接受零个或一个参数并返回适合预期字段类型的值,或者通过引发TypeError或ValueError拒绝参数。
在示例 24-3 中使用内置类型作为注释意味着这些值必须被类型的构造函数接受。对于int,这意味着任何x,使得int(x)返回一个int。对于str,在运行时任何值都可以,因为str(x)在 Python 中适用于任何x。⁵
当不带参数调用时,构造函数应返回其类型的默认值。⁶
这是 Python 内置构造函数的标准行为:
>>> int(), float(), bool(), str(), list(), dict(), set()
(0, 0.0, False, '', [], {}, set())
在Movie这样的Checked子类中,缺少参数会导致实例使用字段构造函数返回的默认值。例如:
>>> Movie(title='Life of Brian')Movie(title='Life of Brian', year=0, box_office=0.0)
构造函数在实例化期间和在实例上直接设置属性时用于验证:
>>> blockbuster = Movie(title='Avatar', year=2009, box_office='billions')Traceback (most recent call last):...TypeError: 'billions' is not compatible with box_office:float>>> movie.year = 'MCMLXXII'Traceback (most recent call last):...TypeError: 'MCMLXXII' is not compatible with year:int
Checked 子类和静态类型检查
在一个带有Movie实例movie的*.py*源文件中,如示例 24-3 中定义的,Mypy 将此赋值标记为类型错误:
movie.year = 'MCMLXXII'
然而,Mypy 无法检测到这个构造函数调用中的类型错误:
blockbuster = Movie(title='Avatar', year='MMIX')
这是因为Movie继承了Checked.__init__,该方法的签名必须接受任何关键字参数以支持任意用户定义的类。
另一方面,如果您声明一个带有类型提示list[float]的Checked子类字段,Mypy 可以标记具有不兼容内容的列表的赋值,但Checked将忽略类型参数并将其视为list。
现在让我们看一下checkedlib.py的实现。第一个类是Field描述符,如示例 24-4 所示。
示例 24-4. initsub/checkedlib.py:Field描述符类
from collections.abc import Callable # ①
from typing import Any, NoReturn, get_type_hintsclass Field:def __init__(self, name: str, constructor: Callable) -> None: # ②if not callable(constructor) or constructor is type(None): # ③raise TypeError(f'{name!r} type hint must be callable')self.name = nameself.constructor = constructordef __set__(self, instance: Any, value: Any) -> None:if value is ...: # ④value = self.constructor()else:try:value = self.constructor(value) # ⑤except (TypeError, ValueError) as e: # ⑥type_name = self.constructor.__name__msg = f'{value!r} is not compatible with {self.name}:{type_name}'raise TypeError(msg) from einstance.__dict__[self.name] = value # ⑦
①
请注意,自 Python 3.9 以来,用于注释的Callable类型是collections.abc中的 ABC,而不是已弃用的typing.Callable。
②
这是一个最小的Callable类型提示;constructor的参数类型和返回类型都隐含为Any。
③
对于运行时检查,我们使用callable内置函数。⁷ 对type(None)的测试是必要的,因为 Python 将类型中的None解读为NoneType,即None的类(因此可调用),但是一个无用的构造函数,只返回None。
④
如果Checked.__init__将value设置为...(内置对象Ellipsis),我们将不带参数调用constructor。
⑤
否则,使用给定的value调用constructor。
⑥
如果constructor引发这些异常中的任何一个,我们将引发TypeError,并提供一个包含字段和构造函数名称的有用消息;例如,'MMIX'与 year:int 不兼容。
⑦
如果没有引发异常,则将value存储在instance.__dict__中。
在__set__中,我们需要捕获TypeError和ValueError,因为内置构造函数可能会引发其中之一,具体取决于参数。例如,float(None)引发TypeError,但float('A')引发ValueError。另一方面,float('8')不会引发错误,并返回8.0。我在此声明,这是这个玩具示例的一个特性,而不是一个 bug。
提示
在“LineItem Take #4: 自动命名存储属性”中,我们看到了描述符的方便__set_name__特殊方法。我们在Field类中不需要它,因为描述符不是在客户端源代码中实例化的;用户声明的类型是构造函数,正如我们在Movie类中看到的(示例 24-3)。相反,Field描述符实例是由Checked.__init_subclass__方法在运行时创建的,我们将在示例 24-5 中看到。
现在让我们专注于Checked类。我将其拆分为两个列表。示例 24-5 显示了该类的顶部,其中包含此示例中最重要的方法。其余方法在示例 24-6 中。
示例 24-5. initsub/checkedlib.py:Checked类的最重要方法
class Checked:@classmethoddef _fields(cls) -> dict[str, type]: # ①return get_type_hints(cls)def __init_subclass__(subclass) -> None: # ②super().__init_subclass__() # ③for name, constructor in subclass._fields().items(): # ④setattr(subclass, name, Field(name, constructor)) # ⑤def __init__(self, **kwargs: Any) -> None:for name in self._fields(): # ⑥value = kwargs.pop(name, ...) # ⑦setattr(self, name, value) # ⑧if kwargs: # ⑨self.__flag_unknown_attrs(*kwargs) # ⑩
①
我编写了这个类方法,以隐藏对typing.get_type_hints的调用,使其不被类的其他部分所知晓。如果我需要支持 Python ≥ 3.10,我会调用inspect.get_annotations。请查看“运行时注解的问题”以了解这些函数的问题。
②
当定义当前类的子类时,会调用__init_subclass__。它将新的子类作为第一个参数传递进来,这就是为什么我将参数命名为subclass而不是通常的cls。有关更多信息,请参阅“init_subclass 不是典型的类方法”。
③
super().__init_subclass__()并非绝对必要,但应该被调用,以便与可能在相同继承图中实现.__init_subclass__()的其他类友好相处。请参阅“多重继承和方法解析顺序”。
④
遍历每个字段的name和constructor…
⑤
…在subclass上创建一个属性,该属性的name绑定到一个使用name和constructor参数化的Field描述符。
⑥
对于类字段中的每个name…
⑦
…从kwargs中获取相应的value并将其从kwargs中删除。使用...(Ellipsis对象)作为默认值允许我们区分给定值为None的参数和未给定的参数。⁸
⑧
这个setattr调用触发了Checked.__setattr__,如示例 24-6 所示。
⑨
如果kwargs中还有剩余项,它们的名称与声明的字段不匹配,__init__将失败。
⑩
错误由__flag_unknown_attrs报告,列在示例 24-6 中。它使用*names参数来传递未知属性名称。我在*kwargs中使用单个星号将其键作为参数序列传递。
现在让我们看看Checked类的剩余方法,从示例 24-5 继续。请注意,我在_fields和_asdict方法名称前加上_的原因与collections.namedtuple API 相同:为了减少与用户定义的字段名称发生冲突的机会。
示例 24-6. initsub/checkedlib.py:Checked类的剩余方法
def __setattr__(self, name: str, value: Any) -> None: # ①if name in self._fields(): # ②cls = self.__class__descriptor = getattr(cls, name)descriptor.__set__(self, value) # ③else: # ④self.__flag_unknown_attrs(name)def __flag_unknown_attrs(self, *names: str) -> NoReturn: # ⑤plural = 's' if len(names) > 1 else ''extra = ', '.join(f'{name!r}' for name in names)cls_name = repr(self.__class__.__name__)raise AttributeError(f'{cls_name} object has no attribute{plural} {extra}')def _asdict(self) -> dict[str, Any]: # ⑥return {name: getattr(self, name)for name, attr in self.__class__.__dict__.items()if isinstance(attr, Field)}def __repr__(self) -> str: # ⑦kwargs = ', '.join(f'{key}={value!r}' for key, value in self._asdict().items())return f'{self.__class__.__name__}({kwargs})'
①
拦截所有尝试设置实例属性。这是为了防止设置未知属性。
②
如果属性name已知,则获取相应的descriptor。
③
通常我们不需要显式调用描述符__set__。在这种情况下是必要的,因为__setattr__拦截所有尝试在实例上设置属性的尝试,包括在存在覆盖描述符(如Field)的情况下。⁹
④
否则,属性name是未知的,__flag_unknown_attrs将引发异常。
⑤
构建一个有用的错误消息,列出所有意外参数,并引发AttributeError。这是NoReturn特殊类型的一个罕见例子,详见NoReturn。
⑥
从Movie对象的属性创建一个dict。我会将这个方法命名为_as_dict,但我遵循了collections.namedtuple中_asdict方法开始的惯例。
⑦
实现一个好的__repr__是在这个例子中拥有_asdict的主要原因。
Checked示例说明了在实现__setattr__以阻止实例化后设置任意属性时如何处理覆盖描述符。在这个例子中,实现__setattr__是否值得讨论是有争议的。如果没有,设置movie.director = 'Greta Gerwig'将成功,但director属性不会以任何方式被检查,并且不会出现在__repr__中,也不会包含在_asdict返回的dict中——这两者在示例 24-6 中定义。
在record_factory.py(示例 24-2)中,我使用__slots__类属性解决了这个问题。然而,在这种情况下,这种更简单的解决方案是不可行的,如下所述。
为什么__init_subclass__无法配置__slots__
__slots__属性仅在它是传递给type.__new__的类命名空间中的条目之一时才有效。向现有类添加__slots__没有效果。Python 仅在类构建后调用__init_subclass__,此时配置__slots__已经太晚了。类装饰器也无法配置__slots__,因为它甚至比__init_subclass__应用得更晚。我们将在“发生了什么:导入时间与运行时”中探讨这些时间问题。
要在运行时配置 __slots__,您自己的代码必须构建作为 type.__new__ 的最后一个参数传递的类命名空间。为此,您可以编写一个类工厂函数,例如 record_factory.py,或者您可以采取核心选项并实现一个元类。我们将看到如何在 “元类 101” 中动态配置 __slots__。
在 PEP 487 简化了 Python 3.7 中使用 __init_subclass__ 自定义类创建的过程之前,类似的功能必须使用类装饰器来实现。这是下一节的重点。
使用类装饰器增强类
类装饰器是一个可调用对象,类似于函数装饰器:它以装饰的类作为参数,并应返回一个用于替换装饰类的类。类装饰器通常通过属性赋值在装饰类本身后注入更多方法后返回装饰类本身。
选择类装饰器而不是更简单的 __init_subclass__ 最常见的原因可能是为了避免干扰其他类特性,如继承和元类。¹⁰
在本节中,我们将学习 checkeddeco.py,它提供了与 checkedlib.py 相同的服务,但使用了类装饰器。和往常一样,我们将从 checkeddeco.py 中的 doctests 中提取的用法示例开始查看(示例 24-7)。
示例 24-7. checkeddeco.py:创建使用 @checked 装饰的 Movie 类
>>> @checked... class Movie:... title: str... year: int... box_office: float...>>> movie = Movie(title='The Godfather', year=1972, box_office=137)>>> movie.title'The Godfather'>>> movieMovie(title='The Godfather', year=1972, box_office=137.0)
示例 24-7 和 示例 24-3 之间唯一的区别是 Movie 类的声明方式:它使用 @checked 装饰而不是继承 Checked。否则,外部行为相同,包括类型验证和默认值分配在 “引入 init_subclass” 中示例 24-3 之后显示的内容。
现在让我们看看 checkeddeco.py 的实现。导入和 Field 类与 checkedlib.py 中的相同,列在 示例 24-4 中。没有其他类,只有 checkeddeco.py 中的函数。
之前在 __init_subclass__ 中实现的逻辑现在是 checked 函数的一部分——类装饰器列在 示例 24-8 中。
示例 24-8. checkeddeco.py:类装饰器
def checked(cls: type) -> type: # ①for name, constructor in _fields(cls).items(): # ②setattr(cls, name, Field(name, constructor)) # ③cls._fields = classmethod(_fields) # type: ignore # ④instance_methods = ( # ⑤__init__,__repr__,__setattr__,_asdict,__flag_unknown_attrs,)for method in instance_methods: # ⑥setattr(cls, method.__name__, method)return cls # ⑦
①
请记住,类是 type 的实例。这些类型提示强烈暗示这是一个类装饰器:它接受一个类并返回一个类。
②
_fields 是模块中稍后定义的顶层函数(在 示例 24-9 中)。
③
用 Field 描述符实例替换 _fields 返回的每个属性是 __init_subclass__ 在 示例 24-5 中所做的。这里还有更多的工作要做…
④
从 _fields 中构建一个类方法,并将其添加到装饰类中。type: ignore 注释是必需的,因为 Mypy 抱怨 type 没有 _fields 属性。
⑤
将成为装饰类的实例方法的模块级函数。
⑥
将每个 instance_methods 添加到 cls 中。
⑦
返回装饰后的 cls,实现类装饰器的基本约定。
checkeddeco.py 中的每个顶层函数都以下划线开头,除了 checked 装饰器。这种命名约定有几个原因是合理的:
-
checked是 checkeddeco.py 模块的公共接口的一部分,但其他函数不是。 -
示例 24-9 中的函数将被注入到装饰类中,而前导的
_减少了与装饰类的用户定义属性和方法的命名冲突的机会。
checkeddeco.py的其余部分列在示例 24-9 中。这些模块级函数与checkedlib.py的Checked类的相应方法具有相同的代码。它们在示例 24-5 和 24-6 中有解释。
请注意,_fields函数在checkeddeco.py中承担了双重职责。它在checked装饰器的第一行中用作常规函数,并且还将被注入为装饰类的类方法。
示例 24-9. checkeddeco.py:要注入到装饰类中的方法
def _fields(cls: type) -> dict[str, type]:return get_type_hints(cls)def __init__(self: Any, **kwargs: Any) -> None:for name in self._fields():value = kwargs.pop(name, ...)setattr(self, name, value)if kwargs:self.__flag_unknown_attrs(*kwargs)def __setattr__(self: Any, name: str, value: Any) -> None:if name in self._fields():cls = self.__class__descriptor = getattr(cls, name)descriptor.__set__(self, value)else:self.__flag_unknown_attrs(name)def __flag_unknown_attrs(self: Any, *names: str) -> NoReturn:plural = 's' if len(names) > 1 else ''extra = ', '.join(f'{name!r}' for name in names)cls_name = repr(self.__class__.__name__)raise AttributeError(f'{cls_name} has no attribute{plural} {extra}')def _asdict(self: Any) -> dict[str, Any]:return {name: getattr(self, name)for name, attr in self.__class__.__dict__.items()if isinstance(attr, Field)}def __repr__(self: Any) -> str:kwargs = ', '.join(f'{key}={value!r}' for key, value in self._asdict().items())return f'{self.__class__.__name__}({kwargs})'
checkeddeco.py模块实现了一个简单但可用的类装饰器。Python 的@dataclass做了更多的事情。它支持许多配置选项,向装饰类添加更多方法,处理或警告有关与装饰类中的用户定义方法的冲突,并甚至遍历__mro__以收集在装饰类的超类中声明的用户定义属性。Python 3.9 中dataclasses包的源代码超过 1200 行。
对于元编程类,我们必须意识到 Python 解释器在构建类时何时评估代码块。接下来将介绍这一点。
当发生什么时:导入时间与运行时
Python 程序员谈论“导入时间”与“运行时”,但这些术语并没有严格定义,它们之间存在一个灰色地带。
在导入时,解释器:
-
从顶部到底部一次性解析一个*.py*模块的源代码。这是可能发生
SyntaxError的时候。 -
编译要执行的字节码。
-
执行编译模块的顶层代码。
如果本地__pycache__中有最新的*.pyc*文件可用,则解析和编译将被跳过,因为字节码已准备就绪。
尽管解析和编译明显是“导入时间”活动,但在那个时候可能会发生其他事情,因为 Python 中的几乎每个语句都是可执行的,它们可能运行用户代码并可能改变用户程序的状态。
特别是,import语句不仅仅是一个声明,¹¹,而且当模块在进程中首次导入时,它实际上运行模块的所有顶层代码。对同一模块的进一步导入将使用缓存,然后唯一的效果将是将导入的对象绑定到客户模块中的名称。该顶层代码可以执行任何操作,包括典型的“运行时”操作,例如写入日志或连接到数据库。¹²这就是为什么“导入时间”和“运行时”之间的边界模糊:import语句可以触发各种“运行时”行为。反过来,“导入时间”也可能发生在运行时的深处,因为import语句和__import__()内置可以在任何常规函数内使用。
这一切都相当抽象和微妙,所以让我们做一些实验,看看发生了什么。
评估时间实验
考虑一个evaldemo.py脚本,它使用了一个类装饰器、一个描述符和一个基于__init_subclass__的类构建器,所有这些都在builderlib.py模块中定义。这些模块有几个print调用来展示发生了什么。否则,它们不执行任何有用的操作。这些实验的目标是观察这些print调用发生的顺序。
警告
在单个类中同时应用类装饰器和__init_subclass__类构建器很可能是过度设计或绝望的迹象。这种不寻常的组合在这些实验中很有用,可以展示类装饰器和__init_subclass__对类应用的更改的时间。
让我们从builderlib.py开始,分为两部分:示例 24-10 和示例 24-11。
示例 24-10. builderlib.py:模块顶部
print('@ builderlib module start')class Builder: # ①print('@ Builder body')def __init_subclass__(cls): # ②print(f'@ Builder.__init_subclass__({cls!r})')def inner_0(self): # ③print(f'@ SuperA.__init_subclass__:inner_0({self!r})')cls.method_a = inner_0def __init__(self):super().__init__()print(f'@ Builder.__init__({self!r})')def deco(cls): # ④print(f'@ deco({cls!r})')def inner_1(self): # ⑤print(f'@ deco:inner_1({self!r})')cls.method_b = inner_1return cls # ⑥
①
这是一个类构建器,用于实现…
②
…一个__init_subclass__方法。
③
定义一个函数,将在下面的赋值中添加到子类中。
④
一个类装饰器。
⑤
要添加到装饰类的函数。
⑥
返回作为参数接收的类。
继续查看示例 24-11 中的builderlib.py…
示例 24-11. builderlib.py:模块底部
class Descriptor: # ①print('@ Descriptor body')def __init__(self): # ②print(f'@ Descriptor.__init__({self!r})')def __set_name__(self, owner, name): # ③args = (self, owner, name)print(f'@ Descriptor.__set_name__{args!r}')def __set__(self, instance, value): # ④args = (self, instance, value)print(f'@ Descriptor.__set__{args!r}')def __repr__(self):return '<Descriptor instance>'print('@ builderlib module end')
①
一个描述符类,用于演示当…
②
…创建一个描述符实例,当…
③
…__set_name__将在owner类构建期间被调用。
④
像其他方法一样,这个__set__除了显示其参数外什么也不做。
如果你在 Python 控制台中导入builderlib.py,你会得到以下内容:
>>> import builderlib
@ builderlib module start
@ Builder body
@ Descriptor body
@ builderlib module end
注意builderlib.py打印的行前缀为@。
现在让我们转向evaldemo.py,它将触发builderlib.py中的特殊方法(示例 24-12)。
示例 24-12. evaldemo.py:用于实验builderlib.py的脚本
#!/usr/bin/env python3from builderlib import Builder, deco, Descriptorprint('# evaldemo module start')@deco # ①
class Klass(Builder): # ②print('# Klass body')attr = Descriptor() # ③def __init__(self):super().__init__()print(f'# Klass.__init__({self!r})')def __repr__(self):return '<Klass instance>'def main(): # ④obj = Klass()obj.method_a()obj.method_b()obj.attr = 999if __name__ == '__main__':main()print('# evaldemo module end')
①
应用一个装饰器。
②
子类化Builder以触发其__init_subclass__。
③
实例化描述符。
④
这只会在模块作为主程序运行时调用。
evaldemo.py中的print调用显示了#前缀。如果你再次打开控制台并导入evaldemo.py,示例 24-13 就是输出结果。
示例 24-13. evaldemo.py的控制台实验
>>> import evaldemo
@ builderlib module start # ①
@ Builder body @ Descriptor body @ builderlib module end # evaldemo module start # Klass body # ②
@ Descriptor.__init__(<Descriptor instance>) # ③
@ Descriptor.__set_name__(<Descriptor instance>,<class 'evaldemo.Klass'>, 'attr') # ④
@ Builder.__init_subclass__(<class 'evaldemo.Klass'>) # ⑤
@ deco(<class 'evaldemo.Klass'>) # ⑥
# evaldemo module end
①
前四行是from builderlib import…的结果。如果你在之前的实验后没有关闭控制台,它们将不会出现,因为builderlib.py已经被加载。
②
这表明 Python 开始读取Klass的主体。此时,类对象还不存在。
③
描述符实例被创建并绑定到命名空间中的attr,Python 将把它传递给默认的类对象构造函数:type.__new__。
④
此时,Python 内置的type.__new__已经创建了Klass对象,并在每个提供该方法的描述符类的描述符实例上调用__set_name__,将Klass作为owner参数传递。
⑤
然后type.__new__在Klass的超类上调用__init_subclass__,将Klass作为唯一参数传递。
⑥
当type.__new__返回类对象时,Python 会应用装饰器。在这个例子中,deco返回的类会绑定到模块命名空间中的Klass。
type.__new__的实现是用 C 语言编写的。我刚描述的行为在 Python 的“数据模型”参考中的“创建类对象”部分有文档记录。
请注意,evaldemo.py的main()函数(示例 24-12)没有在控制台会话中执行(示例 24-13),因此没有创建Klass的实例。我们看到的所有操作都是由“import time”操作触发的:导入builderlib和定义Klass。
如果你将evaldemo.py作为脚本运行,你将看到与示例 24-13 相同的输出,但在最后之前会有额外的行。额外的行是运行main()(示例 24-14)的结果。
示例 24-14。作为程序运行evaldemo.py
$ ./evaldemo.py
[... 9 lines omitted ...]
@ deco(<class '__main__.Klass'>) # ①
@ Builder.__init__(<Klass instance>) # ②
# Klass.__init__(<Klass instance>)
@ SuperA.__init_subclass__:inner_0(<Klass instance>) # ③
@ deco:inner_1(<Klass instance>) # ④
@ Descriptor.__set__(<Descriptor instance>, <Klass instance>, 999) # ⑤
# evaldemo module end
①
前 10 行(包括这一行)与示例 24-13 中显示的相同。
②
在Klass.__init__中由super().__init__()触发。
③
在main中由obj.method_a()触发;method_a是由SuperA.__init_subclass__注入的。
④
在main中由obj.method_b()触发;method_b是由deco注入的。
⑤
在main中由obj.attr = 999触发。
具有__init_subclass__和类装饰器的基类是强大的工具,但它们仅限于使用type.__new__在内部构建的类。在需要调整传递给type.__new__的参数的罕见情况下,您需要一个元类。这是本章和本书的最终目的地。
元类 101
[元类]比 99%的用户应该担心的更深奥。如果你想知道是否需要它们,那就不需要(真正需要它们的人确信自己需要它们,并不需要解释为什么)。
Tim Peters,Timsort 算法的发明者和多产的 Python 贡献者¹³
元类是一个类工厂。与示例 24-2 中的record_factory相比,元类是作为一个类编写的。换句话说,元类是一个其实例是类的类。图 24-1 使用 Mills & Gizmos 符号表示了一个元类:一个生产另一个元类的工厂。

图 24-1。元类是一个构建类的类。
考虑 Python 对象模型:类是对象,因此每个类必须是另一个类的实例。默认情况下,Python 类是type的实例。换句话说,type是大多数内置和用户定义类的元类:
>>> str.__class__
<class 'type'>
>>> from bulkfood_v5 import LineItem
>>> LineItem.__class__
<class 'type'>
>>> type.__class__
<class 'type'>
为了避免无限递归,type的类是type,正如最后一行所示。
请注意,我并不是说str或LineItem是type的子类。我要说的是str和LineItem是type的实例。它们都是object的子类。图 24-2 可能会帮助您面对这个奇怪的现实。
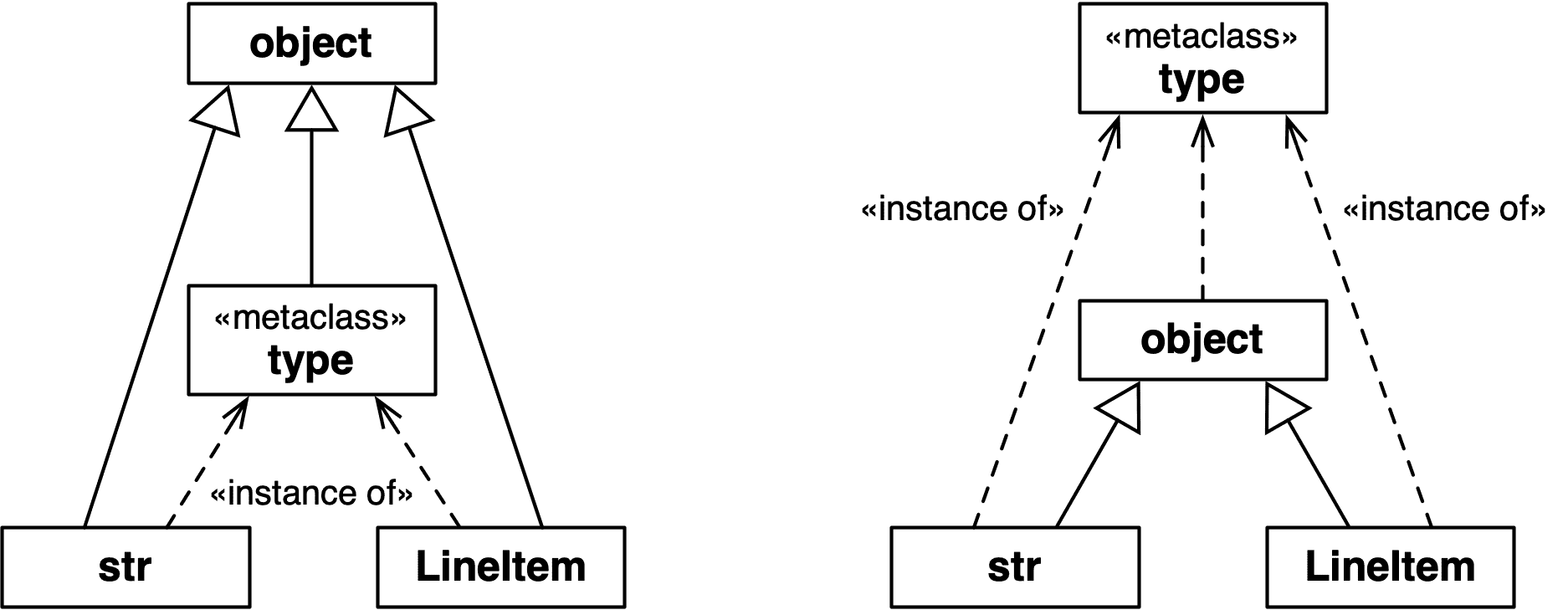
图 24-2。两个图表都是正确的。左边的图表强调str、type和LineItem是object的子类。右边的图表清楚地表明str、object和LineItem是type的实例,因为它们都是类。
注意
类object和type有一个独特的关系:object是type的一个实例,而type是object的一个子类。这种关系是“魔法”的:它不能在 Python 中表达,因为任何一个类都必须在另一个类定义之前存在。type是其自身的实例的事实也是神奇的。
下一个片段显示collections.Iterable的类是abc.ABCMeta。请注意,Iterable是一个抽象类,但ABCMeta是一个具体类——毕竟,Iterable是ABCMeta的一个实例:
>>> from collections.abc import Iterable
>>> Iterable.__class__
<class 'abc.ABCMeta'>
>>> import abc
>>> from abc import ABCMeta
>>> ABCMeta.__class__
<class 'type'>
最终,ABCMeta的类也是type。 每个类都是type的实例,直接或间接,但只有元类也是type的子类。 这是理解元类最重要的关系:元类(例如ABCMeta)从type继承了构造类的能力。 图 24-3 说明了这种关键关系。
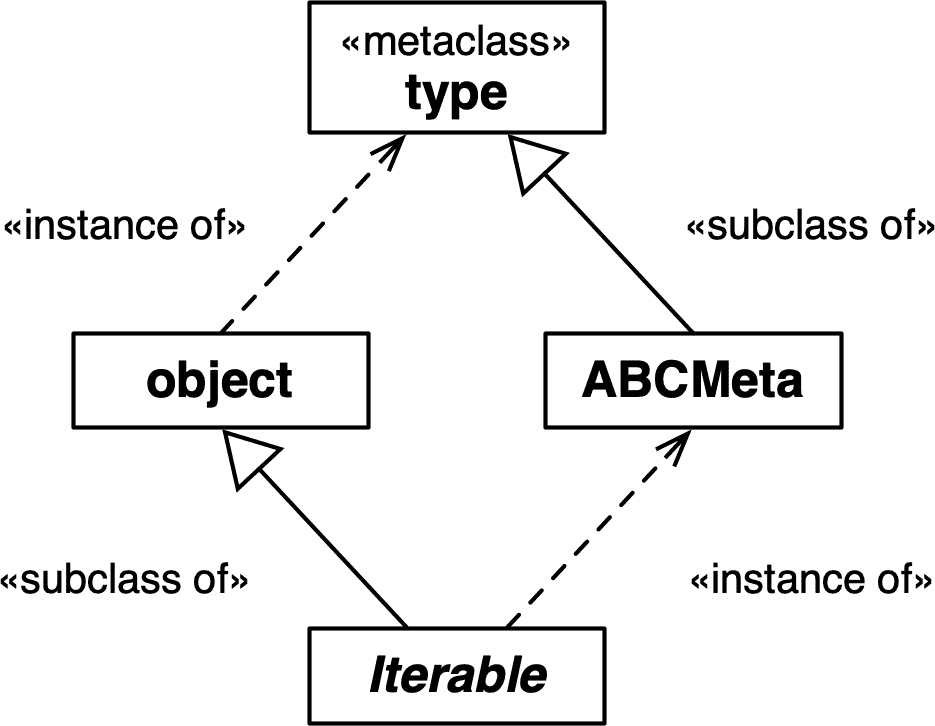
图 24-3。Iterable是object的子类,也是ABCMeta的实例。 object和ABCMeta都是type的实例,但这里的关键关系是ABCMeta也是type的子类,因为ABCMeta是一个元类。 在这个图表中,Iterable是唯一的抽象类。
这里的重要要点是元类是type的子类,这就是使它们作为类工厂运作的原因。 通过实现特殊方法,元类可以定制其实例,如下一节所示。
元类如何定制类
要使用元类,了解__new__如何在任何类上运行至关重要。 这在“使用 new 进行灵活的对象创建”中讨论过。
当元类即将创建一个新实例(即类)时,类似的机制发生在“元”级别。 考虑这个声明:
class Klass(SuperKlass, metaclass=MetaKlass):x = 42def __init__(self, y):self.y = y
要处理该class语句,Python 使用这些参数调用MetaKlass.__new__:
meta_cls
元类本身(MetaKlass),因为__new__作为类方法运行。
cls_name
字符串Klass。
bases
单元素元组(SuperKlass,),在多重继承的情况下有更多元素。
cls_dict
一个类似于:
{x: 42, `__init__`: <function __init__ at 0x1009c4040>}
当您实现MetaKlass.__new__时,您可以检查并更改这些参数,然后将它们传递给super().__new__,后者最终将调用type.__new__来创建新的类对象。
在super().__new__返回后,您还可以对新创建的类进行进一步处理,然后将其返回给 Python。 然后,Python 调用SuperKlass.__init_subclass__,传递您创建的类,然后对其应用类装饰器(如果存在)。 最后,Python 将类对象绑定到其名称在周围的命名空间中 - 通常是模块的全局命名空间,如果class语句是顶级语句。
元类__new__中最常见的处理是向cls_dict中添加或替换项目 - 代表正在构建的类的命名空间的映射。 例如,在调用super().__new__之前,您可以通过向cls_dict添加函数来向正在构建的类中注入方法。 但是,请注意,添加方法也可以在构建类之后完成,这就是为什么我们能够使用__init_subclass__或类装饰器来完成的原因。
在type.__new__运行之前,您必须向cls_dict添加的一个属性是__slots__,如“为什么 init_subclass 无法配置 slots”中讨论的那样。 元类的__new__方法是配置__slots__的理想位置。 下一节将展示如何做到这一点。
一个很好的元类示例
这里介绍的MetaBunch元类是Python in a Nutshell,第 3 版第四章中最后一个示例的变体,作者是 Alex Martelli,Anna Ravenscroft 和 Steve Holden,编写以在 Python 2.7 和 3.5 上运行。 假设是 Python 3.6 或更高版本,我能够进一步简化代码。
首先,让我们看看Bunch基类提供了什么:
>>> class Point(Bunch):... x = 0.0... y = 0.0... color = 'gray'...>>> Point(x=1.2, y=3, color='green')Point(x=1.2, y=3, color='green')>>> p = Point()>>> p.x, p.y, p.color(0.0, 0.0, 'gray')>>> pPoint()
请记住,Checked根据类变量类型提示为子类中的Field描述符分配名称,这些描述符实际上不会成为类的属性,因为它们没有值。
另一方面,Bunch 的子类使用具有值的实际类属性,然后这些值成为实例属性的默认值。生成的 __repr__ 省略了等于默认值的属性的参数。
MetaBunch — Bunch 的元类 — 从用户类中声明的类属性生成新类的 __slots__。这阻止了未声明属性的实例化和后续赋值:
>>> Point(x=1, y=2, z=3)Traceback (most recent call last):...AttributeError: No slots left for: 'z'>>> p = Point(x=21)>>> p.y = 42>>> pPoint(x=21, y=42)>>> p.flavor = 'banana'Traceback (most recent call last):...AttributeError: 'Point' object has no attribute 'flavor'
现在让我们深入研究 示例 24-15 中 MetaBunch 的优雅代码。
示例 24-15. metabunch/from3.6/bunch.py:MetaBunch 元类和 Bunch 类
class MetaBunch(type): # ①def __new__(meta_cls, cls_name, bases, cls_dict): # ②defaults = {} # ③def __init__(self, **kwargs): # ④for name, default in defaults.items(): # ⑤setattr(self, name, kwargs.pop(name, default))if kwargs: # ⑥extra = ', '.join(kwargs)raise AttributeError(f'No slots left for: {extra!r}')def __repr__(self): # ⑦rep = ', '.join(f'{name}={value!r}'for name, default in defaults.items()if (value := getattr(self, name)) != default)return f'{cls_name}({rep})'new_dict = dict(__slots__=[], __init__=__init__, __repr__=__repr__) # ⑧for name, value in cls_dict.items(): # ⑨if name.startswith('__') and name.endswith('__'): # ⑩if name in new_dict:raise AttributeError(f"Can't set {name!r} in {cls_name!r}")new_dict[name] = valueelse: ⑪new_dict['__slots__'].append(name)defaults[name] = valuereturn super().__new__(meta_cls, cls_name, bases, new_dict) ⑫class Bunch(metaclass=MetaBunch): ⑬pass
①
要创建一个新的元类,继承自 type。
②
__new__ 作为一个类方法工作,但类是一个元类,所以我喜欢将第一个参数命名为 meta_cls(mcs 是一个常见的替代方案)。其余三个参数与直接调用 type() 创建类的三参数签名相同。
③
defaults 将保存属性名称和它们的默认值的映射。
④
这将被注入到新类中。
⑤
读取 defaults 并使用从 kwargs 弹出的值或默认值设置相应的实例属性。
⑥
如果 kwargs 中仍有任何项,这意味着没有剩余的插槽可以放置它们。我们认为快速失败是最佳实践,因此我们不希望悄悄地忽略额外的项。一个快速有效的解决方案是从 kwargs 中弹出一项并尝试在实例上设置它,故意触发 AttributeError。
⑦
__repr__ 返回一个看起来像构造函数调用的字符串 — 例如,Point(x=3),省略了具有默认值的关键字参数。
⑧
初始化新类的命名空间。
⑨
遍历用户类的命名空间。
⑩
如果找到双下划线 name,则将项目复制到新类命名空间,除非它已经存在。这可以防止用户覆盖由 Python 设置的 __init__、__repr__ 和其他属性,如 __qualname__ 和 __module__。
⑪
如果不是双下划线 name,则追加到 __slots__ 并将其 value 保存在 defaults 中。
⑫
构建并返回新类。
⑬
提供一个基类,这样用户就不需要看到 MetaBunch。
MetaBunch 起作用是因为它能够在调用 super().__new__ 之前配置 __slots__ 以构建最终类。通常在元编程时,理解操作的顺序至关重要。让我们进行另一个评估时间实验,这次使用元类。
元类评估时间实验
这是 “评估时间实验” 的一个变体,加入了一个元类。builderlib.py 模块与之前相同,但主脚本现在是 evaldemo_meta.py,列在 示例 24-16 中。
示例 24-16. evaldemo_meta.py:尝试使用元类进行实验
#!/usr/bin/env python3from builderlib import Builder, deco, Descriptor
from metalib import MetaKlass # ①print('# evaldemo_meta module start')@deco
class Klass(Builder, metaclass=MetaKlass): # ②print('# Klass body')attr = Descriptor()def __init__(self):super().__init__()print(f'# Klass.__init__({self!r})')def __repr__(self):return '<Klass instance>'def main():obj = Klass()obj.method_a()obj.method_b()obj.method_c() # ③obj.attr = 999if __name__ == '__main__':main()print('# evaldemo_meta module end')
①
从 metalib.py 导入 MetaKlass,我们将在 示例 24-18 中看到。
②
将 Klass 声明为 Builder 的子类和 MetaKlass 的实例。
③
此方法是由 MetaKlass.__new__ 注入的,我们将会看到。
警告
为了科学研究,示例 24-16 违背一切理性,将三种不同的元编程技术应用于 Klass:一个装饰器,一个使用 __init_subclass__ 的基类,以及一个自定义元类。如果你在生产代码中这样做,请不要责怪我。再次强调,目标是观察这三种技术干扰类构建过程的顺序。
与之前的评估时间实验一样,这个例子除了打印显示执行流程的消息外什么也不做。示例 24-17 展示了 metalib.py 顶部部分的代码—其余部分在 示例 24-18 中。
示例 24-17. metalib.py:NosyDict 类
print('% metalib module start')import collectionsclass NosyDict(collections.UserDict):def __setitem__(self, key, value):args = (self, key, value)print(f'% NosyDict.__setitem__{args!r}')super().__setitem__(key, value)def __repr__(self):return '<NosyDict instance>'
我编写了 NosyDict 类来重写 __setitem__ 以显示每个 key 和 value 在设置时的情况。元类将使用一个 NosyDict 实例来保存正在构建的类的命名空间,揭示 Python 更多的内部工作原理。
metalib.py 的主要吸引力在于 示例 24-18 中的元类。它实现了 __prepare__ 特殊方法,这是 Python 仅在元类上调用的类方法。__prepare__ 方法提供了影响创建新类过程的最早机会。
提示
在编写元类时,我发现采用这种特殊方法参数的命名约定很有用:
-
对于实例方法,使用
cls而不是self,因为实例是一个类。 -
对于类方法,使用
meta_cls而不是cls,因为类是一个元类。请记住,__new__表现为类方法,即使没有@classmethod装饰器。
示例 24-18. metalib.py:MetaKlass
class MetaKlass(type):print('% MetaKlass body')@classmethod # ①def __prepare__(meta_cls, cls_name, bases): # ②args = (meta_cls, cls_name, bases)print(f'% MetaKlass.__prepare__{args!r}')return NosyDict() # ③def __new__(meta_cls, cls_name, bases, cls_dict): # ④args = (meta_cls, cls_name, bases, cls_dict)print(f'% MetaKlass.__new__{args!r}')def inner_2(self):print(f'% MetaKlass.__new__:inner_2({self!r})')cls = super().__new__(meta_cls, cls_name, bases, cls_dict.data) # ⑤cls.method_c = inner_2 # ⑥return cls # ⑦def __repr__(cls): # ⑧cls_name = cls.__name__return f"<class {cls_name!r} built by MetaKlass>"print('% metalib module end')
①
__prepare__ 应该声明为类方法。它不是实例方法,因为在 Python 调用 __prepare__ 时正在构建的类还不存在。
②
Python 调用元类的 __prepare__ 来获取一个映射,用于保存正在构建的类的命名空间。
③
返回 NosyDict 实例以用作命名空间。
④
cls_dict 是由 __prepare__ 返回的 NosyDict 实例。
⑤
type.__new__ 要求最后一个参数是一个真实的 dict,所以我给了它从 UserDict 继承的 NosyDict 的 data 属性。
⑥
在新创建的类中注入一个方法。
⑦
像往常一样,__new__ 必须返回刚刚创建的对象—在这种情况下是新类。
⑧
在元类上定义 __repr__ 允许自定义类对象的 repr()。
在 Python 3.6 之前,__prepare__ 的主要用途是提供一个 OrderedDict 来保存正在构建的类的属性,以便元类 __new__ 可以按照用户类定义源代码中的顺序处理这些属性。现在 dict 保留插入顺序,__prepare__ 很少被需要。你将在 “使用 prepare 进行元类黑客” 中看到它的创造性用法。
在 Python 控制台中导入 metalib.py 并不是很令人兴奋。请注意使用 % 作为此模块输出的行的前缀:
>>> import metalib
% metalib module start
% MetaKlass body
% metalib module end
如果导入 evaldemo_meta.py,会发生很多事情,正如你在 示例 24-19 中所看到的。
示例 24-19. 使用 evaldemo_meta.py 的控制台实验
>>> import evaldemo_meta
@ builderlib module start @ Builder body @ Descriptor body @ builderlib module end % metalib module start % MetaKlass body % metalib module end # evaldemo_meta module start # ①
% MetaKlass.__prepare__(<class 'metalib.MetaKlass'>, 'Klass', # ②(<class 'builderlib.Builder'>,)) % NosyDict.__setitem__(<NosyDict instance>, '__module__', 'evaldemo_meta') # ③
% NosyDict.__setitem__(<NosyDict instance>, '__qualname__', 'Klass') # Klass body @ Descriptor.__init__(<Descriptor instance>) # ④
% NosyDict.__setitem__(<NosyDict instance>, 'attr', <Descriptor instance>) # ⑤
% NosyDict.__setitem__(<NosyDict instance>, '__init__',<function Klass.__init__ at …>) # ⑥
% NosyDict.__setitem__(<NosyDict instance>, '__repr__',<function Klass.__repr__ at …>) % NosyDict.__setitem__(<NosyDict instance>, '__classcell__', <cell at …: empty>) % MetaKlass.__new__(<class 'metalib.MetaKlass'>, 'Klass',(<class 'builderlib.Builder'>,), <NosyDict instance>) # ⑦
@ Descriptor.__set_name__(<Descriptor instance>,<class 'Klass' built by MetaKlass>, 'attr') # ⑧
@ Builder.__init_subclass__(<class 'Klass' built by MetaKlass>) @ deco(<class 'Klass' built by MetaKlass>) # evaldemo_meta module end
①
在此之前的行是导入 builderlib.py 和 metalib.py 的结果。
②
Python 调用 __prepare__ 来开始处理 class 语句。
③
在解析类体之前,Python 将__module__和__qualname__条目添加到正在构建的类的命名空间中。
④
创建描述符实例…
⑤
…并绑定到类命名空间中的attr。
⑥
__init__和__repr__方法被定义并添加到命名空间中。
⑦
Python 完成处理类体后,调用MetaKlass.__new__。
⑧
__set_name__、__init_subclass__和装饰器按照这个顺序被调用,在元类的__new__方法返回新构造的类之后。
如果将evaldemo_meta.py作为脚本运行,将调用main(),并会发生一些其他事情(示例 24-20)。
示例 24-20。将evaldemo_meta.py作为程序运行
$ ./evaldemo_meta.py
[... 20 lines omitted ...]
@ deco(<class 'Klass' built by MetaKlass>) # ①
@ Builder.__init__(<Klass instance>)
# Klass.__init__(<Klass instance>)
@ SuperA.__init_subclass__:inner_0(<Klass instance>)
@ deco:inner_1(<Klass instance>)
% MetaKlass.__new__:inner_2(<Klass instance>) # ②
@ Descriptor.__set__(<Descriptor instance>, <Klass instance>, 999)
# evaldemo_meta module end
①
前 21 行,包括这一行,与示例 24-19 中显示的相同。
②
由main中的obj.method_c()触发;method_c是由MetaKlass.__new__注入的。
现在让我们回到Checked类的概念,其中Field描述符实现了运行时类型验证,并看看如何使用元类来实现。
用于 Checked 的元类解决方案
我不想鼓励过早优化和过度设计,所以这里有一个虚构的场景来证明使用__slots__重写checkedlib.py的合理性,这需要应用元类。随意跳过。
我们接下来将研究的metaclass/checkedlib.py模块是initsub/checkedlib.py的一个可替换项。它们中嵌入的 doctests 是相同的,以及用于 pytest 的checkedlib_test.py 文件。
checkedlib.py中的复杂性对用户进行了抽象。这里是使用该包的脚本的源代码:
from checkedlib import Checkedclass Movie(Checked):title: stryear: intbox_office: floatif __name__ == '__main__':movie = Movie(title='The Godfather', year=1972, box_office=137)print(movie)print(movie.title)
这个简洁的Movie类定义利用了三个Field验证描述符的实例,一个__slots__配置,从Checked继承的五个方法,以及一个元类将它们全部整合在一起。checkedlib的唯一可见部分是Checked基类。
考虑图 24-4。 Mills & Gizmos Notation 通过使类和实例之间的关系更加可见来补充 UML 类图。
例如,使用新的checkedlib.py的Movie类是CheckedMeta的一个实例,并且是Checked的一个子类。此外,Movie的title、year和box_office类属性是Field的三个单独实例。每个Movie实例都有自己的_title、_year和_box_office属性,用于存储相应字段的值。
现在让我们从Field类开始研究代码,如示例 24-21 所示。
Field描述符类现在有点不同。在先前的示例中,每个Field描述符实例将其值存储在具有相同名称的属性中。例如,在Movie类中,title描述符将字段值存储在托管实例中的title属性中。这使得Field不需要提供__get__方法。
然而,当类像Movie一样使用__slots__时,不能同时拥有相同名称的类属性和实例属性。每个描述符实例都是一个类属性,现在我们需要单独的每个实例存储属性。代码使用带有单个_前缀的描述符名称。因此,Field实例有单独的name和storage_name属性,并且我们实现Field.__get__。
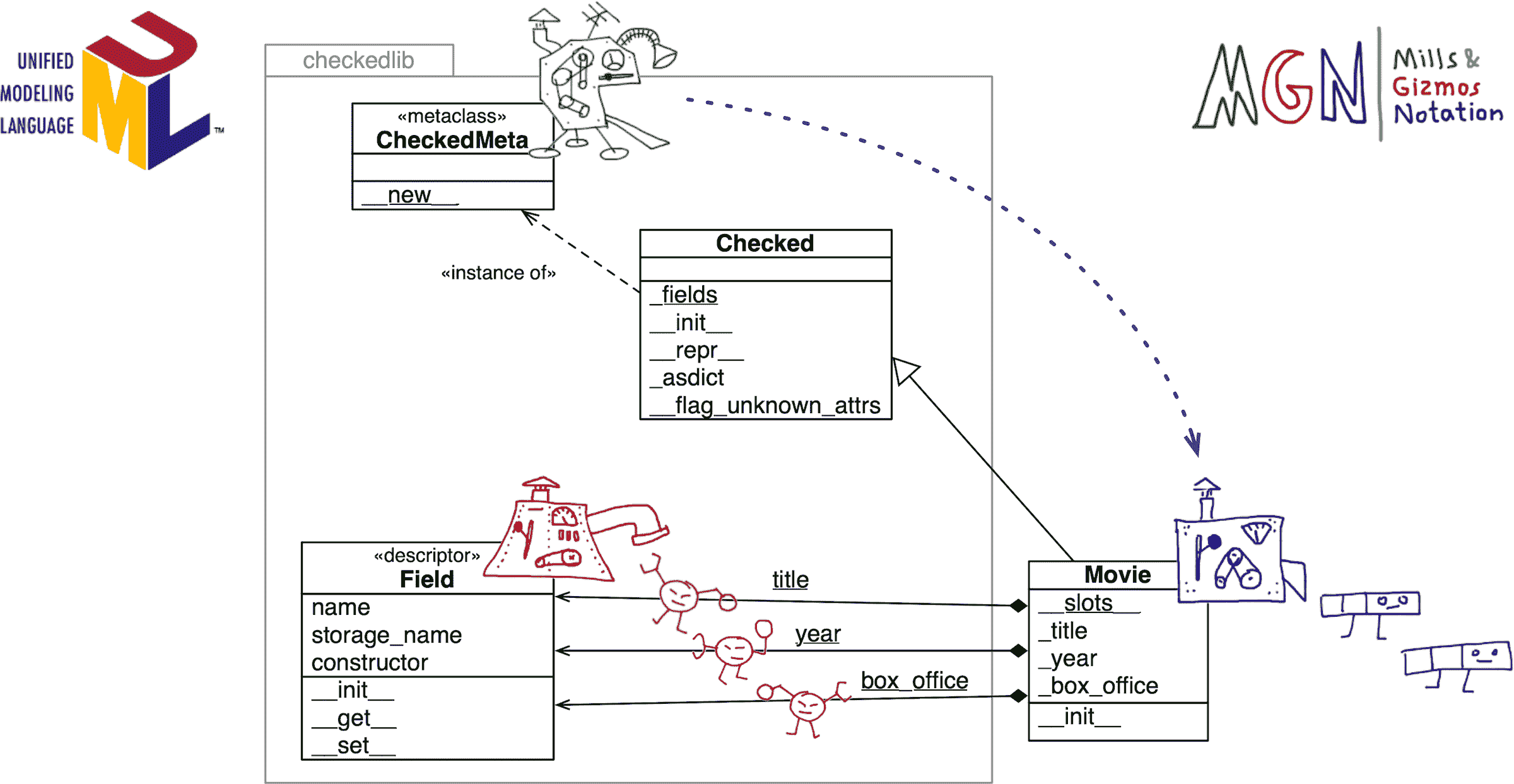
图 24-4。带有 MGN 注释的 UML 类图:CheckedMeta元工厂构建Movie工厂。Field工厂构建title、year和box_office描述符,它们是Movie的类属性。字段的每个实例数据存储在Movie的_title、_year和_box_office实例属性中。请注意checkedlib的包边界。Movie的开发者不需要理解checkedlib.py内部的所有机制。
示例 24-21 显示了带有storage_name和__get__的Field描述符的源代码。
示例 24-21。元类/checkedlib.py:带有storage_name和__get__的Field描述符
class Field:def __init__(self, name: str, constructor: Callable) -> None:if not callable(constructor) or constructor is type(None):raise TypeError(f'{name!r} type hint must be callable')self.name = nameself.storage_name = '_' + name # ①self.constructor = constructordef __get__(self, instance, owner=None):if instance is None: # ②return selfreturn getattr(instance, self.storage_name) # ③def __set__(self, instance: Any, value: Any) -> None:if value is ...:value = self.constructor()else:try:value = self.constructor(value)except (TypeError, ValueError) as e:type_name = self.constructor.__name__msg = f'{value!r} is not compatible with {self.name}:{type_name}'raise TypeError(msg) from esetattr(instance, self.storage_name, value) # ④
①
从name参数计算storage_name。
②
如果__get__的instance参数为None,则描述符是从托管类本身而不是托管实例中读取的。因此我们返回描述符。
③
否则,返回存储在名为storage_name的属性中的值。
④
__set__现在使用setattr来设置或更新托管属性。
示例 24-22 显示了驱动此示例的元类的代码。
示例 24-22。元类/checkedlib.py:CheckedMeta元类
class CheckedMeta(type):def __new__(meta_cls, cls_name, bases, cls_dict): # ①if '__slots__' not in cls_dict: # ②slots = []type_hints = cls_dict.get('__annotations__', {}) # ③for name, constructor in type_hints.items(): # ④field = Field(name, constructor) # ⑤cls_dict[name] = field # ⑥slots.append(field.storage_name) # ⑦cls_dict['__slots__'] = slots # ⑧return super().__new__(meta_cls, cls_name, bases, cls_dict) # ⑨
①
__new__是CheckedMeta中唯一实现的方法。
②
仅在cls_dict不包含__slots__时增强类。如果__slots__已经存在,则假定它是Checked基类,而不是用户定义的子类,并按原样构建类。
③
为了获取之前示例中的类型提示,我们使用typing.get_type_hints,但这需要一个现有的类作为第一个参数。此时,我们正在配置的类尚不存在,因此我们需要直接从cls_dict(Python 作为元类__new__的最后一个参数传递的正在构建的类的命名空间)中检索__annotations__。
④
迭代type_hints以…
⑤
…为每个注释属性构建一个Field…
⑥
…用Field实例覆盖cls_dict中的相应条目…
⑦
…并将字段的storage_name追加到我们将用于的列表中…
⑧
…填充cls_dict中的__slots__条目——正在构建的类的命名空间。
⑨
最后,我们调用super().__new__。
metaclass/checkedlib.py的最后部分是Checked基类,这个库的用户将从中派生类来增强他们的类,如Movie。
这个版本的Checked的代码与initsub/checkedlib.py中的Checked相同(在示例 24-5 和示例 24-6 中列出),有三个变化:
-
添加一个空的
__slots__,以向CheckedMeta.__new__表明这个类不需要特殊处理。 -
移除
__init_subclass__。它的工作现在由CheckedMeta.__new__完成。 -
移除
__setattr__。它变得多余,因为向用户定义的类添加__slots__可以防止设置未声明的属性。
示例 24-23 是Checked的最终版本的完整列表。
示例 24-23。元类/checkedlib.py:Checked基类
class Checked(metaclass=CheckedMeta):__slots__ = () # skip CheckedMeta.__new__ processing@classmethoddef _fields(cls) -> dict[str, type]:return get_type_hints(cls)def __init__(self, **kwargs: Any) -> None:for name in self._fields():value = kwargs.pop(name, ...)setattr(self, name, value)if kwargs:self.__flag_unknown_attrs(*kwargs)def __flag_unknown_attrs(self, *names: str) -> NoReturn:plural = 's' if len(names) > 1 else ''extra = ', '.join(f'{name!r}' for name in names)cls_name = repr(self.__class__.__name__)raise AttributeError(f'{cls_name} object has no attribute{plural} {extra}')def _asdict(self) -> dict[str, Any]:return {name: getattr(self, name)for name, attr in self.__class__.__dict__.items()if isinstance(attr, Field)}def __repr__(self) -> str:kwargs = ', '.join(f'{key}={value!r}' for key, value in self._asdict().items())return f'{self.__class__.__name__}({kwargs})'
这结束了一个带有验证描述符的类构建器的第三次渲染。
下一节涵盖了与元类相关的一些一般问题。
真实世界中的元类
元类很强大,但也很棘手。在决定实现元类之前,请考虑以下几点。
现代特性简化或替代元类
随着时间的推移,几种常见的元类用法被新的语言特性所取代:
类装饰器
比元类更容易理解,更不太可能与基类和元类发生冲突。
__set_name__
避免需要自定义元类逻辑来自动设置描述符的名称。¹⁵
__init_subclass__
提供了一种透明对终端用户进行自定义类创建的方式,甚至比装饰器更简单——但可能会在复杂的类层次结构中引入冲突。
内置dict保留键插入顺序
消除了使用__prepare__的#1 原因:提供一个OrderedDict来存储正在构建的类的命名空间。Python 只在元类上调用__prepare__,因此如果您需要按照源代码中出现的顺序处理类命名空间,则必须在 Python 3.6 之前使用元类。
截至 2021 年,CPython 的每个活跃维护版本都支持刚才列出的所有功能。
我一直在倡导这些特性,因为我看到我们行业中有太多不必要的复杂性,而元类是复杂性的入口。
元类是稳定的语言特性
元类是在 2002 年与所谓的“新式类”、描述符和属性一起在 Python 2.2 中引入的。
令人惊讶的是,Alex Martelli 于 2002 年 7 月首次发布的MetaBunch示例在 Python 3.9 中仍然有效——唯一的变化是在 Python 3 中指定要使用的元类的方式,即使用语法class Bunch(metaclass=MetaBunch):。
我提到的“现代特性简化或替代元类”中的任何添加都不会破坏使用元类的现有代码。但是,使用元类的遗留代码通常可以通过利用这些特性来简化,尤其是如果可以放弃对不再维护的 Python 版本(3.6 之前的版本)的支持。
一个类只能有一个元类
如果您的类声明涉及两个或更多个元类,您将看到这个令人困惑的错误消息:
TypeError: metaclass conflict: the metaclass of a derived class
must be a (non-strict) subclass of the metaclasses of all its bases
这可能发生在没有多重继承的情况下。例如,像这样的声明可能触发TypeError:
class Record(abc.ABC, metaclass=PersistentMeta):pass
我们看到abc.ABC是abc.ABCMeta元类的一个实例。如果Persistent元类本身不是abc.ABCMeta的子类,则会出现元类冲突。
处理该错误有两种方法:
-
找到其他方法来做你需要做的事情,同时避免涉及到的元类之一。
-
编写自己的
PersistentABCMeta元类,作为abc.ABCMeta和PersistentMeta的子类,使用多重继承,并将其作为Record的唯一元类。¹⁶
提示
我可以想象实现满足截止日期的两个基本元类的元类的解决方案。根据我的经验,元类编程总是比预期时间长,这使得在严格的截止日期之前采用这种方法是有风险的。如果您这样做并且达到了截止日期,代码可能会包含微妙的错误。即使没有已知的错误,您也应该将这种方法视为技术债务,因为它很难理解和维护。
元类应该是实现细节
除了type,整个 Python 3.9 标准库中只有六个元类。较为知名的元类可能是abc.ABCMeta、typing.NamedTupleMeta和enum.EnumMeta。它们中没有一个旨在明确出现在用户代码中。我们可能将它们视为实现细节。
尽管您可以使用元类进行一些非常古怪的元编程,但最好遵循最少惊讶原则,以便大多数用户确实将元类视为实现细节。¹⁷
近年来,Python 标准库中的一些元类已被其他机制替换,而不会破坏其包的公共 API。未来保护这类 API 的最简单方法是提供一个常规类,供用户子类化以访问元类提供的功能,就像我们在示例中所做的那样。
为了总结我们对类元编程的覆盖范围,我将与您分享我在研究本章时发现的最酷、最小的元类示例。
使用 prepare 的元类技巧
当我为第二版更新这一章节时,我需要找到简单但具有启发性的示例来替换自 Python 3.6 以来不再需要元类的bulkfood LineItem代码。
最简单且最有趣的元类概念是由巴西 Python 社区中更为人熟知的 João S. O. Bueno(简称 JS)给我的。他的想法之一是创建一个自动生成数值常量的类:
>>> class Flavor(AutoConst):... banana... coconut... vanilla...>>> Flavor.vanilla2>>> Flavor.banana, Flavor.coconut(0, 1)
是的,代码如图所示是有效的!实际上,这是autoconst_demo.py中的一个 doctest。
这里是用户友好的AutoConst基类和其背后的元类,实现在autoconst.py中:
class AutoConstMeta(type):def __prepare__(name, bases, **kwargs):return WilyDict()class AutoConst(metaclass=AutoConstMeta):pass
就是这样。
显然,技巧在于WilyDict。
当 Python 处理用户类的命名空间并读取banana时,它在__prepare__提供的映射中查找该名称:一个WilyDict的实例。WilyDict实现了__missing__,在“missing 方法”中有介绍。WilyDict实例最初没有'banana'键,因此触发了__missing__方法。它会即时创建一个具有键'banana'和值0的项目,并返回该值。Python 对此很满意,然后尝试检索'coconut'。WilyDict立即添加该条目,值为1,并返回它。同样的情况也发生在'vanilla',然后映射到2。
我们之前已经看到了__prepare__和__missing__。真正的创新在于 JS 如何将它们结合在一起。
这里是WilyDict的源代码,也来自autoconst.py:
class WilyDict(dict):def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)self.__next_value = 0def __missing__(self, key):if key.startswith('__') and key.endswith('__'):raise KeyError(key)self[key] = value = self.__next_valueself.__next_value += 1return value
在实验过程中,我发现 Python 在正在构建的类的命名空间中查找__name__,导致WilyDict添加了一个__name__条目,并增加了__next_value。因此,我在__missing__中添加了那个if语句,以便为看起来像 dunder 属性的键引发KeyError。
autoconst.py包既需要又展示了对 Python 动态类构建机制的掌握。
我很高兴为AutoConstMeta和AutoConst添加更多功能,但是我不会分享我的实验,而是让您享受 JS 的巧妙技巧。
以下是一些想法:
-
如果你有值,可以检索常量名称。例如,
Flavor[2]可以返回'vanilla'。您可以通过在AutoConstMeta中实现__getitem__来实现这一点。自 Python 3.9 起,您可以在AutoConst本身中实现__class_getitem__。 -
支持对类进行迭代,通过在元类上实现
__iter__。我会让__iter__产生常量作为(name, value)对。 -
实现一个新的
Enum变体。这将是一项重大工作,因为enum包中充满了技巧,包括具有数百行代码和非平凡__prepare__方法的EnumMeta元类。
尽情享受!
注意
__class_getitem__特殊方法是在 Python 3.9 中添加的,以支持通用类型,作为PEP 585—标准集合中的类型提示通用的一部分。由于__class_getitem__,Python 的核心开发人员不必为内置类型编写新的元类来实现__getitem__,以便我们可以编写像list[int]这样的通用类型提示。这是一个狭窄的功能,但代表了元类的更广泛用例:实现运算符和其他特殊方法以在类级别工作,例如使类本身可迭代,就像Enum子类一样。
总结
元类、类装饰器以及__init_subclass__对以下方面很有用:
-
子类注册
-
子类结构验证
-
将装饰器应用于多个方法
-
对象序列化
-
对象关系映射
-
基于对象的持久性
-
在类级别实现特殊方法
-
实现其他语言中的类特性,比如特性和面向方面的编程
在某些情况下,类元编程也可以帮助解决性能问题,通过在导入时执行通常在运行时重复执行的任务。
最后,让我们回顾一下亚历克斯·马特利在他的文章“水禽和 ABC”中的最终建议:
而且,不要在生产代码中定义自定义 ABCs(或元类)…如果你有这种冲动,我敢打赌这很可能是“所有问题看起来都像钉子”综合症的情况,对于刚刚得到闪亮新锤子的人来说,你(以及未来维护你代码的人)将更喜欢坚持简单直接的代码,避免深入这样的领域。
我相信马特利的建议不仅适用于 ABCs 和元类,还适用于类层次结构、运算符重载、函数装饰器、描述符、类装饰器以及使用__init_subclass__的类构建器。
这些强大的工具主要用于支持库和框架开发。应用程序自然应该使用这些工具,如 Python 标准库或外部包提供的那样。但在应用程序代码中实现它们通常是过早的抽象。
好的框架是被提取出来的,而不是被发明的。¹⁸
大卫·海涅迈尔·汉森,Ruby on Rails 的创始人
章节总结
本章以类对象中发现的属性概述开始,比如__qualname__和__subclasses__()方法。接下来,我们看到了type内置函数如何用于在运行时构建类。
引入了__init_subclass__特殊方法,设计了第一个旨在用Field实例替换用户定义子类中属性类型提示的Checked基类,这些实例应用构造函数以在运行时强制执行这些属性的类型。
通过一个@checked类装饰器实现了相同的想法,它为用户定义的类添加特性,类似于__init_subclass__允许的。我们看到,无论是__init_subclass__还是类装饰器都无法动态配置__slots__,因为它们只在类创建后操作。
“导入时间”和“运行时”概念通过实验证明了涉及模块、描述符、类装饰器和__init_subclass__时 Python 代码执行顺序的清晰。
我们对元类的覆盖始于对type作为元类的整体解释,以及用户定义的元类如何实现__new__以自定义它构建的类。然后我们看到了我们的第一个自定义元类,经典的MetaBunch示例使用__slots__。接下来,另一个评估时间实验展示了元类的__prepare__和__new__方法在__init_subclass__和类装饰器之前被调用,为更深层次的类定制提供了机会。
第三次迭代的Checked类构建器使用Field描述符和自定义__slots__配置,随后是关于实践中元类使用的一些一般考虑。
最后,我们看到了由乔昂·S·O·布恩诺发明的AutoConst黑客,基于一个具有__prepare__返回实现__missing__的映射的元类的狡猾想法。在不到 20 行的代码中,autoconst.py展示了结合 Python 元编程技术的强大力量。
我还没有找到一种语言能像 Python 一样,既适合初学者,又适合专业人士,又能激发黑客的兴趣。感谢 Guido van Rossum 和所有使之如此的人。
进一步阅读
Caleb Hattingh——本书的技术审阅者——编写了autoslot包,提供了一个元类,通过检查__init__的字节码并找到对self属性的所有赋值来自动创建一个__slots__属性在用户定义的类中。这非常有用,也是一个优秀的学习示例:autoslot.py中只有 74 行代码,包括 20 行注释解释最困难的部分。
本章在 Python 文档中的基本参考资料是Python 语言参考中“数据模型”章节中的“3.3.3. 自定义类创建”,涵盖了__init_subclass__和元类。在“内置函数”页面的type类文档,以及Python 标准库中“内置类型”章节的“4.13. 特殊属性”也是必读的。
在Python 标准库中,types模块文档涵盖了 Python 3.3 中添加的两个简化类元编程的函数:types.new_class和types.prepare_class。
类装饰器在PEP 3129—类装饰器中得到正式规范,由 Collin Winter 编写,参考实现由 Jack Diederich 编写。PyCon 2009 年的演讲“类装饰器:彻底简化”(视频),也是由 Jack Diederich 主持,是该功能的一个快速介绍。除了@dataclass之外,在 Python 标准库中一个有趣且简单得多的类装饰器示例是functools.total_ordering,它为对象比较生成特殊方法。
对于元类,在 Python 文档中的主要参考资料是PEP 3115—Python 3000 中的元类,其中引入了__prepare__特殊方法。
Python 速查手册,第 3 版,由 Alex Martelli、Anna Ravenscroft 和 Steve Holden 编写,权威性很高,但是在PEP 487—简化类创建发布之前编写。该书中的主要元类示例——MetaBunch——仍然有效,因为它不能用更简单的机制编写。Brett Slatkin 的Effective Python,第 2 版(Addison-Wesley)包含了几个关于类构建技术的最新示例,包括元类。
要了解 Python 中类元编程的起源,我推荐 Guido van Rossum 在 2003 年的论文“统一 Python 2.2 中的类型和类”。该文本也适用于现代 Python,因为它涵盖了当时称为“新式”类语义的内容——Python 3 中的默认语义,包括描述符和元类。Guido 引用的参考文献之一是Ira R. Forman 和 Scott H. Danforth的Putting Metaclasses to Work: a New Dimension in Object-Oriented Programming(Addison-Wesley),这本书在Amazon.com上获得了五星评价,他在评论中补充说:
这本书为 Python 2.2 中的元类设计做出了贡献
真遗憾这本书已经绝版;我一直认为这是我所知道的关于协同多重继承这一困难主题的最佳教程,通过 Python 的
super()函数支持。¹⁹
如果你对元编程感兴趣,你可能希望 Python 拥有终极的元编程特性:语法宏,就像 Lisp 系列语言以及最近的 Elixir 和 Rust 所提供的那样。语法宏比 C 语言中的原始代码替换宏更强大且更不容易出错。它们是特殊函数,可以在编译步骤之前使用自定义语法重写源代码为标准代码,使开发人员能够引入新的语言构造而不改变编译器。就像运算符重载一样,语法宏可能会被滥用。但只要社区理解并管理这些缺点,它们支持强大且用户友好的抽象,比如 DSL(领域特定语言)。2020 年 9 月,Python 核心开发者 Mark Shannon 发布了PEP 638—语法宏,提倡这一点。在最初发布一年后,PEP 638 仍处于草案阶段,没有关于它的讨论。显然,这不是 Python 核心开发者的首要任务。我希望看到 PEP 638 进一步讨论并最终获得批准。语法宏将允许 Python 社区在对核心语言进行永久更改之前尝试具有争议性的新功能,比如海象操作符(PEP 572)、模式匹配(PEP 634)以及评估类型提示的替代规则(PEP 563 和 649)。与此同时,你可以通过MacroPy包尝试语法宏的味道。
¹ 引自《编程风格的要素》第二版第二章“表达式”,第 10 页。
² 这并不意味着 PEP 487 打破了使用这些特性的代码。这只是意味着一些在 Python 3.6 之前使用类装饰器或元类的代码现在可以重构为使用普通类,从而简化并可能提高效率。
³ 感谢我的朋友 J. S. O. Bueno 对这个示例的贡献。
⁴ 我没有为参数添加类型提示,因为实际类型是Any。我添加了返回类型提示,否则 Mypy 将不会检查方法内部。
⁵ 对于任何对象来说都是如此,除非它的类重写了从object继承的__str__或__repr__方法并具有错误的实现。
⁶ 这个解决方案避免使用None作为默认值。避免空值是一个好主意。一般情况下很难避免,但在某些情况下很容易。在 Python 和 SQL 中,我更喜欢用空字符串代替None或NULL来表示缺失的数据。学习 Go 强化了这个想法:在 Go 中,原始类型的变量和结构字段默认初始化为“零值”。如果你感兴趣,可以查看在线 Go 之旅中的“零值”。
⁷ 我认为callable应该适用于类型提示。截至 2021 年 5 月 6 日,这是一个未解决的问题。
⁸ 如在“循环、哨兵和毒丸”中提到的,Ellipsis对象是一个方便且安全的哨兵值。它已经存在很长时间了,但最近人们发现它有更多的用途,正如我们在类型提示和 NumPy 中看到的。
⁹ 重写描述符的微妙概念在“重写描述符”中有解释。
¹⁰ 这个理由出现在PEP 557–数据类的摘要中,解释了为什么它被实现为一个类装饰器。
¹¹ 与 Java 中的import语句相比,后者只是一个声明,让编译器知道需要某些包。
¹² 我并不是说仅仅因为导入模块就打开数据库连接是一个好主意,只是指出这是可以做到的。
¹³ 发送给 comp.lang.python 的消息,主题:“c.l.p.中的尖刻”。这是 2002 年 12 月 23 日同一消息的另一部分,在前言中引用。那天 TimBot 受到启发。
¹⁴ 作者们很友好地允许我使用他们的例子。MetaBunch首次出现在 Martelli 于 2002 年 7 月 7 日在 comp.lang.python 组发布的消息中,主题是“一个不错的元类示例(回复:Python 中的结构)”,在讨论 Python 中类似记录的数据结构之后。Martelli 的原始代码适用于 Python 2.2,只需进行一次更改即可在 Python 3 中使用元类,您必须在类声明中使用 metaclass 关键字参数,例如,Bunch(metaclass=MetaBunch),而不是旧的约定,即添加一个__metaclass__类级属性。
¹⁵ 在《流畅的 Python》第一版中,更高级版本的LineItem类使用元类仅仅是为了设置属性的存储名称。请查看第一版代码库中bulkfood 的元类代码。
¹⁶ 如果您考虑到使用元类的多重继承的影响而感到头晕,那很好。我也会远离这个解决方案。
¹⁷ 在决定研究 Django 的模型字段是如何实现之前,我靠写 Django 代码谋生几年。直到那时我才了解描述符和元类。
¹⁸ 这句话被广泛引用。我在 DHH 的博客中发现了一个早期的直接引用帖子,发布于 2005 年。
¹⁹ 我买了一本二手书,发现它是一本非常具有挑战性的阅读。
²⁰ 请参见第 xvii 页。完整文本可在Berkeley.edu上找到。
²¹ 《机器之美:优雅与技术之心》 作者 David Gelernter(Basic Books)开篇讨论了工程作品中的优雅和美学,从桥梁到软件。后面的章节不是很出色,但开篇值得一读。
后记
Python 是一个成年人的语言。
Alan Runyan,Plone 联合创始人
Alan 的简洁定义表达了 Python 最好的特质之一:它不会干扰你,而是让你做你必须做的事情。这也意味着它不会给你工具来限制别人对你的代码和构建的对象所能做的事情。
30 岁时,Python 仍在不断增长。但当然,它并不完美。对我来说,最令人恼火的问题之一是标准库中对CamelCase、snake_case和joinedwords的不一致使用。但语言定义和标准库只是生态系统的一部分。用户和贡献者的社区是 Python 生态系统中最好的部分。
这是社区最好的一个例子:在第一版中写关于asyncio时,我感到沮丧,因为 API 有许多函数,其中几十个是协程,你必须用yield from调用协程—现在用await—但你不能对常规函数这样做。这在asyncio页面中有记录,但有时你必须读几段才能找出特定函数是否是协程。所以我给 python-tulip 发送了一封标题为“建议:在asyncio文档中突出显示协程”的消息。asyncio核心开发者 Victor Stinner;aiohttp的主要作者 Andrew Svetlov;Tornado 的首席开发人员 Ben Darnell;以及Twisted的发明者 Glyph Lefkowitz 加入了讨论。Darnell 提出了一个解决方案,Alexander Shorin 解释了如何在 Sphinx 中实现它,Stinner 添加了必要的配置和标记。在我提出问题不到 12 小时后,整个asyncio在线文档集都更新了今天你可以看到的coroutine标签。
那个故事并不发生在一个独家俱乐部。任何人都可以加入 python-tulip 列表,当我写这个提案时,我只发过几次帖子。这个故事说明了一个真正对新想法和新成员开放的社区。Guido van Rossum 过去常常出现在 python-tulip 中,并经常回答基本问题。
另一个开放性的例子:Python 软件基金会(PSF)一直致力于增加 Python 社区的多样性。一些令人鼓舞的结果已经出现。2013 年至 2014 年,PSF 董事会首次选举了女性董事:Jessica McKellar 和 Lynn Root。2015 年,Diana Clarke 在蒙特利尔主持了 PyCon 北美大会,大约三分之一的演讲者是女性。PyLadies 成为一个真正的全球运动,我为我们在巴西有这么多 PyLadies 分部感到自豪。
如果你是 Python 爱好者但还没有参与社区,我鼓励你这样做。寻找你所在地区的 PyLadies 或 Python 用户组(PUG)。如果没有,就创建一个。Python 无处不在,所以你不会孤单。如果可以的话,参加活动。也参加线上活动。在新冠疫情期间,我在线会议的“走廊轨道”中学到了很多东西。来参加 PythonBrasil 大会—多年来我们一直有国际演讲者。和其他 Python 爱好者一起交流不仅带来知识分享,还有真正的好处。比如真正的工作和真正的友谊。
我知道如果没有多年来在 Python 社区结识的许多朋友的帮助,我不可能写出这本书。
我的父亲,贾伊罗·拉马尔,曾经说过“Só erra quem trabalha”,葡萄牙语中的“只有工作的人会犯错”,这是一个避免被犯错的恐惧所束缚的好建议。在写这本书的过程中,我肯定犯了很多错误。审阅者、编辑和早期发布的读者发现了很多错误。在第一版早期发布的几个小时内,一位读者在书的勘误页面上报告了错别字。其他读者提供了更多报告,朋友们直接联系我提出建议和更正。O’Reilly 的编辑们在制作过程中会发现其他错误,一旦我停止写作就会开始。我对任何错误和次优的散文负责并致歉。
我很高兴完成这第二版,包括错误,我非常感谢在这个过程中帮助过我的每个人。
希望很快能在某个现场活动中见到你。如果看到我,请过来打个招呼!
进一步阅读
我将以关于“Pythonic”的参考资料结束本书——这本书试图解决的主要问题。
Brandon Rhodes 是一位出色的 Python 教师,他的演讲“Python 美学:美丽和我为什么选择 Python”非常出色,标题中使用了 Unicode U+00C6(LATIN CAPITAL LETTER AE)。另一位出色的教师 Raymond Hettinger 在 PyCon US 2013 上谈到了 Python 中的美:“将代码转化为美丽、惯用的 Python”。
伊恩·李在 Python-ideas 上发起的“风格指南的演变”主题值得一读。李是pep8包的维护者,用于检查 Python 源代码是否符合 PEP 8 规范。为了检查本书中的代码,我使用了flake8,它包含了pep8、pyflakes,以及 Ned Batchelder 的McCabe 复杂度插件。
除了 PEP 8,其他有影响力的风格指南还有Google Python 风格指南和Pocoo 风格指南,这两个团队为我们带来了 Flake、Sphinx、Jinja 2 等伟大的 Python 库。
Python 之旅者指南!是关于编写 Pythonic 代码的集体作品。其中最多产的贡献者是 Kenneth Reitz,由于他出色的 Pythonic requests 包,他成为了社区英雄。David Goodger 在 PyCon US 2008 上做了一个名为“像 Pythonista 一样编码:Python 的惯用法”的教程。如果打印出来,教程笔记有 30 页长。Goodger 创建了 reStructuredText 和 docutils——Sphinx 的基础,Python 出色的文档系统(顺便说一句,这也是 MongoDB 和许多其他项目的官方文档系统)。
马蒂恩·法森在“什么是 Pythonic?”中直面这个问题。在 python-list 中,有一个同名主题的讨论线程。马蒂恩的帖子是 2005 年的,而主题是 2003 年的,但 Pythonic 的理念并没有改变太多——语言本身也是如此。一个标题中带有“Pythonic”的很棒的主题是“Pythonic way to sum n-th list element?”,我在“Soapbox”中广泛引用了其中的内容。
PEP 3099 — Python 3000 中不会改变的事情解释了为什么许多事情仍然保持原样,即使 Python 3 进行了重大改革。很长一段时间,Python 3 被昵称为 Python 3000,但它提前了几个世纪到来——这让一些人感到沮丧。PEP 3099 是由 Georg Brandl 撰写的,汇编了许多由BDFL,Guido van Rossum 表达的观点。“Python Essays”页面列出了 Guido 本人撰写的几篇文章。