声明
本文章基于哔哩哔哩付费课程《小白也能听懂的人工智能原理》。仅供学习记录、分享,严禁他用!!如有侵权,请联系删除
目录
一、知识引入
(一)隐藏层
(二)泛化
(三)深度神经网络
二、编程实验
(一)输入x与第一层
(二)上一层的输出结果与第二层
(三)计算前向传播
(四)计算反向传播
(五)完整代码
一、知识引入
小蓝海底的豆豆发生了进化,毒性变得忽大忽小,与豆豆的大小不再有明显的关系,就需要一个有多样单调性的函数来预测,而不是只具有单一不变的单调性。
将神经元组成一个网络:
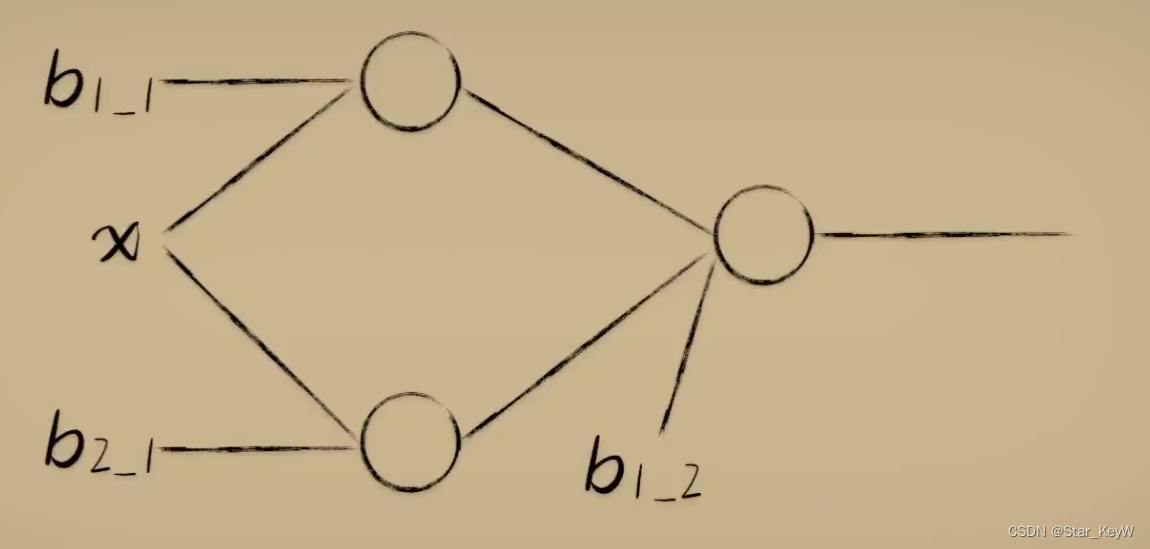
第一个神经元:先通过线性函数计算,再通过激活函数得到最终的输出,利用梯度下降算法,将输出调整为sigmoid式的样子;
第二个神经元也同样,调整为sigmoid式的样子;
将两个神经元的最终输出作为第三个神经元的输入,先通过第三个神经元的线性函数计算,再通过激活函数+梯度下降算法
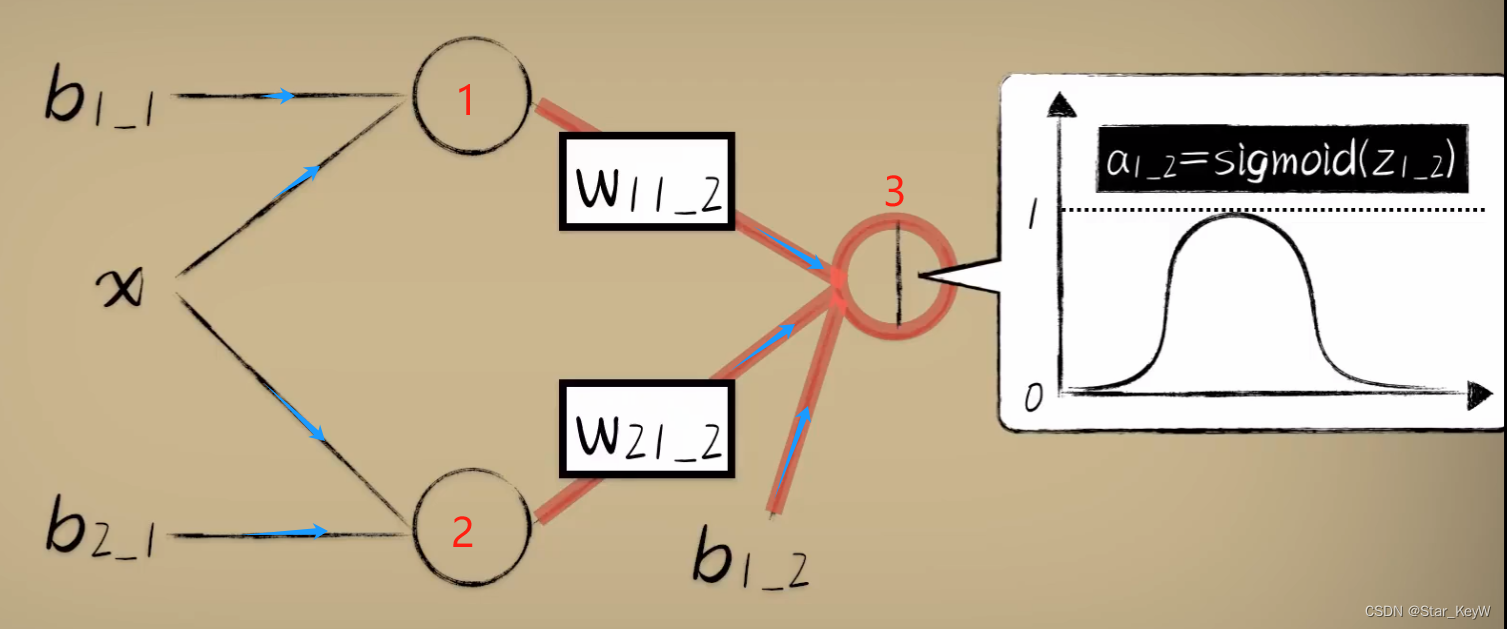
即,将输入分为两个部分,然后分别对两个部分进行调节,然后再送入最后一个神经元,让整体的神经网络形成一个单调性不唯一的更多变函数。从而具备了解决更加复杂问题的能力。
添加一个神经元后,相当于增加了一个抽象的维度,把输入放进不同的维度中,每个维度通过不断地调整权重并进行激活,从而产生对输入的不同理解。最后再把这些抽象维度中的输出合并、降维,得到输出。这个输入数据由于在多个抽象维度中被产生不同的解读,从而让输出得到了更多可能。
当环境中的豆豆毒性发生更多可能的时候,同样可以采取类似的方法:通过增加对输入更多的抽象维度,产生更多的解读,从而实现更加复杂的分类效果。
(一)隐藏层
中间新增添加的神经元节点--“隐藏层”。
正是因为隐藏层的存在,才让神经网络能够在复杂情况下仍旧working。
显而易见,隐藏层的神经元数量越多,就可以产生越复杂的组合,解决越复杂的问题。当然计算量也随之越来越大。
(二)泛化
我们采集的训练数据越充足,那么最后训练得到的模型也就能越好的去预测新的问题。因为越充足的训练数据,就在越大程度上蕴藏了问题的规律特征。新的问题数据也就越难以逃脱这些规律的约束。
所以总说,机器学习神经网络的根基是:海量数据。
一个训练后,拟合适当的模型,进而在遇到新的问题数据时,也能大概率产生正确预测。成为“模型的泛化”。泛化能力也是神经网络追求的核心问题。
(三)深度神经网络
隐藏层超过3层的网络。
二、编程实验
(一)输入x与第一层
# 第一层
# 第一个神经元
w11_1 = np.random.rand() # _后表示第几层,11表示第1个输入和第1个神经元
b1_1 = np.random.rand() # _后表示第几层,1表示第一个神经元权重的偏置项# 第二个神经元
w12_1 = np.random.rand() # _后表示第几层,12表示第1个输入和第2个神经元
b2_1 = np.random.rand() # _后表示第几层,2表示第二个神经元权重的偏置项(二)上一层的输出结果与第二层
# 第二层
w11_2 = np.random.rand() # _后表示第几层,11表示第1个输入和第1个神经元
w21_2 = np.random.rand() # _后表示第几层,21表示第2个输入和第1个神经元
b1_2 = np.random.rand() # _后表示第几层,1表示第一个神经元权重的偏置项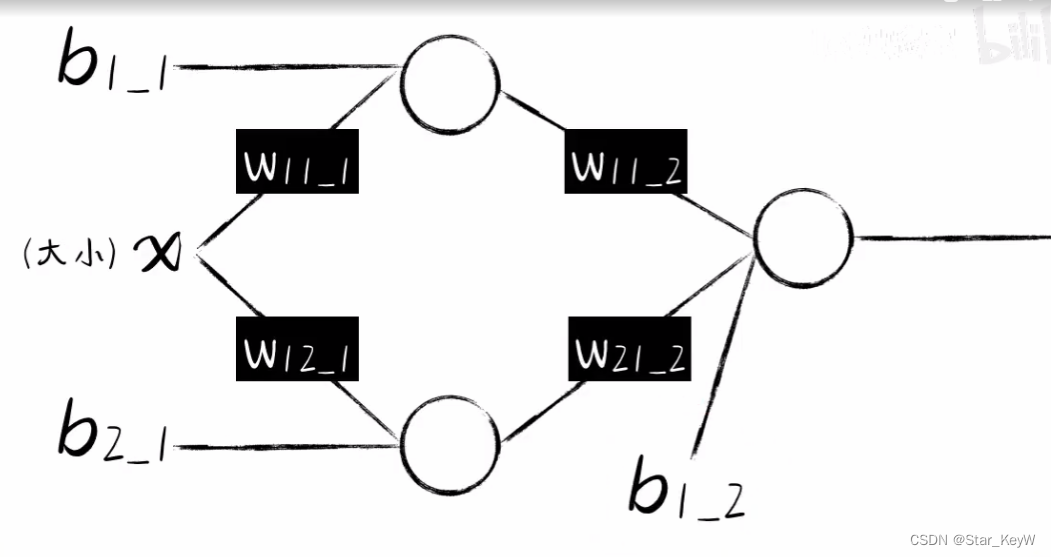
(三)计算前向传播
# 计算前向传播
# 第一层
z1_1 = w11_1 * xs + b1_1
a1_1 = sigmoid(z1_1)
z2_1 = w21_1 * xs + b2_1
a2_1 = sigmoid(z2_1)# 第二层
# 第一层的输出作为输入
z1_2 = w11_2 * a1_1 + w21_2 * a2_1 + b1_2
a1_2 = sigmoid(z1_2)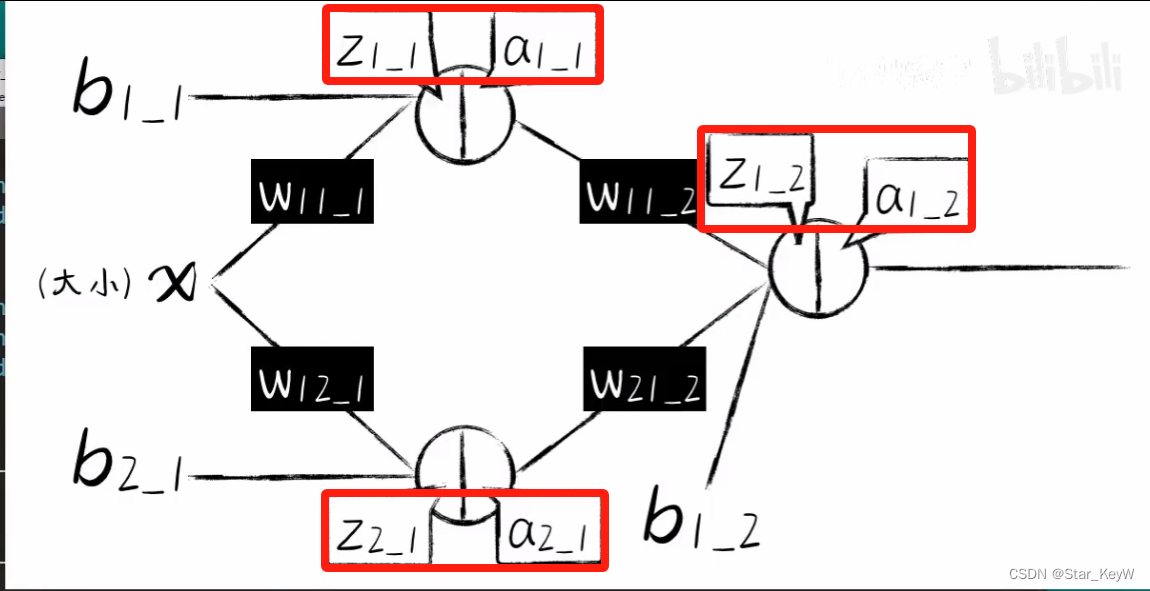
(四)计算反向传播
# 先来一次前向传播
z1_1, a1_1, z2_1, a2_1, z1_2, a1_2 = forward_propagation(x)
# 反向传播
# 代价函数e
e = (y - a1_2)**2# 代价函数对最终输出求导
deda1_2 = -2 * (y - a1_2)
# 第二层神经元的激活函数求导
da1_2dz1_2 = a1_2 * (1 - a1_2)
# z1_2对两个输入神经元的权重求导,即线性函数的导数
dz1_2dw11_2 = a1_1
dz1_2dw21_2 = a2_1
# 链式法则,得到损失函数e对第二层神经元的两个输入的导数
dedw11_2 = deda1_2 * da1_2dz1_2 * dz1_2dw11_2
dedw21_2 = deda1_2 * da1_2dz1_2 * dz1_2dw21_2
# 第二层神经元的偏置项
dz1_2db1_2 = 1
dedb1_2 = deda1_2 * da1_2dz1_2 *dz1_2db1_2# 对隐藏层的神经元进行操作
# 第一个神经元
# 对权重求导
dz1_2da1_1 = w11_2
# 激活函数求导
da1_1dz1_1 = a1_1 * (1 - a1_1)
# 对权重求导
dz1_1dw11_1 = x
# 链式法则
dedw11_1 = deda1_2 * da1_2dz1_2 * dz1_2da1_1 * da1_1dz1_1 * dz1_1dw11_1
# 对偏置项b求导
dz1_1db1_1 = 1
# 链式求导法则
dedb1_1 = deda1_2 * da1_2dz1_2 * dz1_2da1_1 * da1_1dz1_1 * dz1_1db1_1# 对第二个神经元
# 对权重求导
dz1_2da2_1 = w21_2
# 激活函数求导
da2_1dz2_1 = a2_1 * (1 - a2_1)
# 对权重求导
dz2_1dw12_1 = x
dedw12_1 = deda1_2 * da1_2dz1_2 * dz1_2da1_1 * da2_1dz2_1 * dz2_1dw12_1
# 对偏置项b求导
dz2_1db2_1 = 1
# 链式求导法则
dedb2_1 = deda1_2 * da1_2dz1_2 * dz1_2da1_1 * da2_1dz2_1 * dz2_1db2_1alpha = 0.03
# 更新参数
w11_1 = w11_1 - alpha * dedw11_1
w12_1 = w12_1 - alpha * dedw12_1
b1_1 = b1_1 - alpha * dedb1_1w11_2 = w11_2 - alpha * dedw11_2
w21_2 = w21_2 - alpha * dedw21_2
b1_2 = b1_2 - alpha * dedb1_2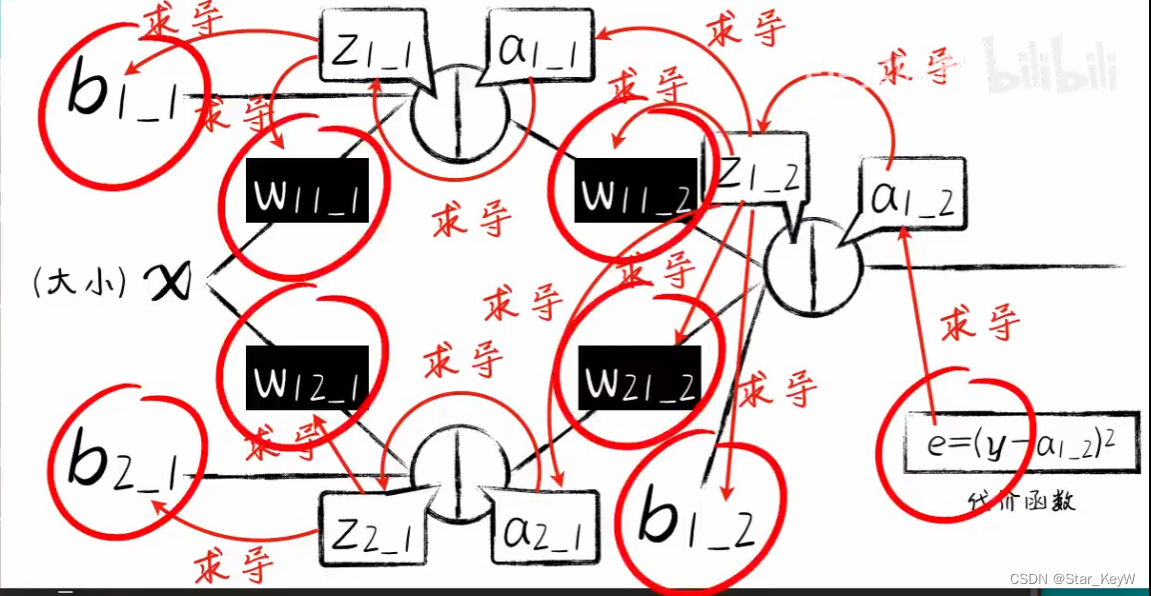
(五)完整代码
import dataset
import matplotlib
import numpy as np
from matplotlib import pyplot as plt
# 首先要知道 matplotlib 的 backend 使用的是默认配置 agg (agg不能显示绘制的图),要想显示绘制的图需要更改 agg 为 TkAgg
matplotlib.use('TkAgg')def sigmoid(x):return 1 / (1 + np.exp(-x))# 生成数据
xs, ys = dataset.get_beans(100)
num = 100# 第一层
# 第一个神经元
w11_1 = np.random.rand() # _后表示第几层,11表示第1个输入和第1个神经元
b1_1 = np.random.rand() # _后表示第几层,1表示第一个神经元权重的偏置项
# 第二个神经元
w12_1 = np.random.rand() # _后表示第几层,12表示第1个输入和第2个神经元
b2_1 = np.random.rand() # _后表示第几层,2表示第二个神经元权重的偏置项# 第二层
w11_2 = np.random.rand() # _后表示第几层,11表示第1个输入和第1个神经元
w21_2 = np.random.rand() # _后表示第几层,21表示第2个输入和第1个神经元
b1_2 = np.random.rand() # _后表示第几层,1表示第一个神经元权重的偏置项# 计算前向传播
def forward_propagation(xs):# 第一层z1_1 = w11_1 * xs + b1_1a1_1 = sigmoid(z1_1)z2_1 = w12_1 * xs + b2_1a2_1 = sigmoid(z2_1)# 第二层# 第一层的输出作为输入z1_2 = w11_2 * a1_1 + w21_2 * a2_1 + b1_2a1_2 = sigmoid(z1_2)return z1_1, a1_1, z2_1, a2_1, z1_2, a1_2# 在全部样本上做了5000次梯度下降
for _ in range(5000):for i in range(100):x = xs[i]y = ys[i]# 先来一次前向传播z1_1, a1_1, z2_1, a2_1, z1_2, a1_2 = forward_propagation(x)# 反向传播# 代价函数ee = (y - a1_2)**2# 代价函数对最终输出求导deda1_2 = -2 * (y - a1_2)# 第二层神经元的激活函数求导da1_2dz1_2 = a1_2 * (1 - a1_2)# z1_2对两个输入神经元的权重求导,即线性函数的导数dz1_2dw11_2 = a1_1dz1_2dw21_2 = a2_1# 链式法则,得到损失函数e对第二层神经元的两个输入的导数dedw11_2 = deda1_2 * da1_2dz1_2 * dz1_2dw11_2dedw21_2 = deda1_2 * da1_2dz1_2 * dz1_2dw21_2# 第二层神经元的偏置项dz1_2db1_2 = 1dedb1_2 = deda1_2 * da1_2dz1_2 *dz1_2db1_2# 对隐藏层的神经元进行操作# 第一个神经元# 对权重求导dz1_2da1_1 = w11_2# 激活函数求导da1_1dz1_1 = a1_1 * (1 - a1_1)# 对权重求导dz1_1dw11_1 = x# 链式法则dedw11_1 = deda1_2 * da1_2dz1_2 * dz1_2da1_1 * da1_1dz1_1 * dz1_1dw11_1# 对偏置项b求导dz1_1db1_1 = 1# 链式求导法则dedb1_1 = deda1_2 * da1_2dz1_2 * dz1_2da1_1 * da1_1dz1_1 * dz1_1db1_1# 对第二个神经元# 对权重求导dz1_2da2_1 = w21_2# 激活函数求导da2_1dz2_1 = a2_1 * (1 - a2_1)# 对权重求导dz2_1dw12_1 = xdedw12_1 = deda1_2 * da1_2dz1_2 * dz1_2da1_1 * da2_1dz2_1 * dz2_1dw12_1# 对偏置项b求导dz2_1db2_1 = 1# 链式求导法则dedb2_1 = deda1_2 * da1_2dz1_2 * dz1_2da1_1 * da2_1dz2_1 * dz2_1db2_1alpha = 0.03w11_1 = w11_1 - alpha * dedw11_1w12_1 = w12_1 - alpha * dedw12_1b1_1 = b1_1 - alpha * dedb1_1w11_2 = w11_2 - alpha * dedw11_2w21_2 = w21_2 - alpha * dedw21_2b1_2 = b1_2 - alpha * dedb1_2# 减少绘图的频率if _ % 50 == 0:# plt.clf()函数清除绘图窗口plt.clf()# 重新绘制散点图和预测曲线plt.scatter(xs, ys)z1_1, a1_1, z2_1, a2_1, z1_2, a1_2 = forward_propagation(xs)plt.plot(xs, a1_2)# 暂停0.01秒plt.pause(0.01)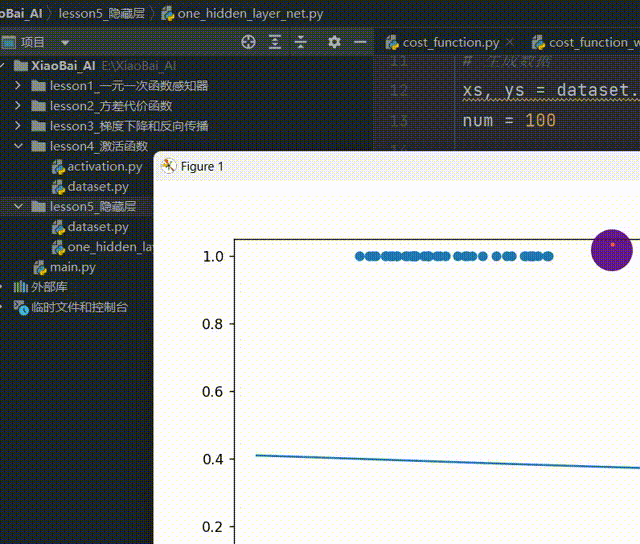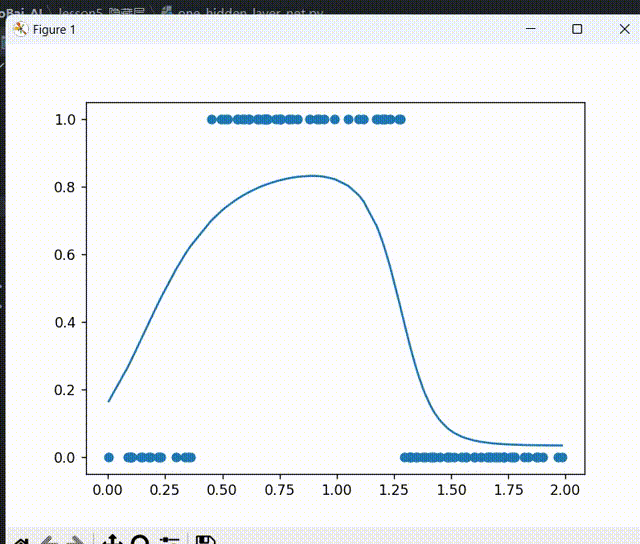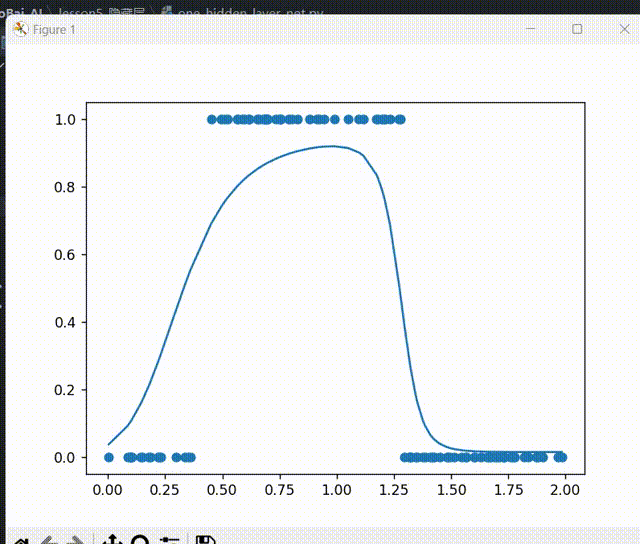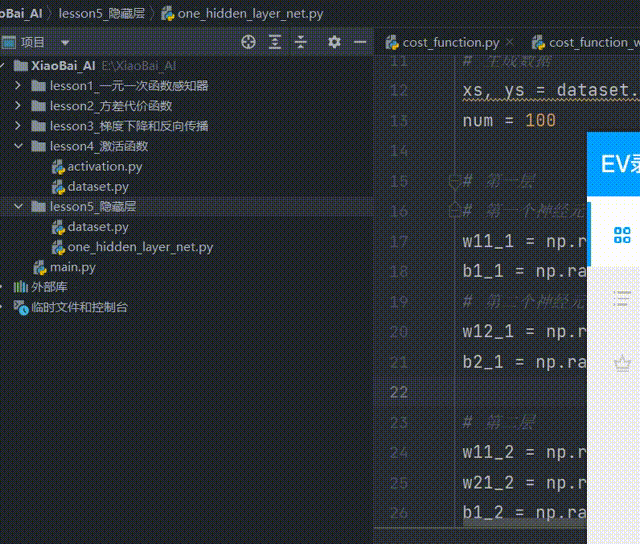



)


)


—解压zip压缩文件)

)







-串口模块QtSerialPort详解)