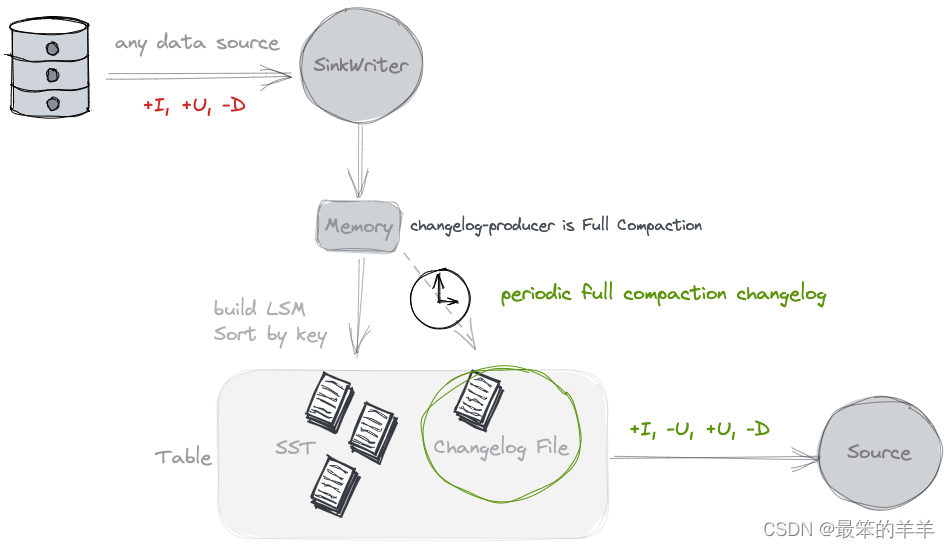
1. Java常用API
1.1 String类
在java中,String类代表字符串,字符串是常量的,不能被改变。如果想改变字符串。可以用字符串的缓冲区,StringBuffer、StringBuilder
1.1.1 String类的创建方式
第一种(常用)
String s = "abc";
第二种
String s = new String("abc");
第三种
char[] char = ['a','b','c'];
String s = new String(char);
String类代表字符串 存入的是常量值
String s = "abc";
s = "bcd";
以上代码 虽然s的值被改变了 但是实际上是重新创建了一个String对象
1.1.2 String类的常用方法
-
charAt(int index)
-
获取字符串中指定位置的字符
-
-
eques("xxx")
-
比较2个字符串的内容是否相等
-
该方法不是String类本身的方法 是父类Object的方法
-
-
replace(char oldChar, char newChar)`
-
字符串替换
-
1.1.3 ==和eques的区别
-
==是逻辑运算符,比较的是基本数据类型 如果比较的是引用类型(String) 比较的就是空间地址值
-
eques是Object类提供的方法 在String中用处是比较2个字符串的内容是否相等
-
注意事项:
-
eques的用法
String s1 = null; String s2 = "zrrd"; if(s2.equest(s1)){}常量值尽量在前面 为了避免空指针异常
-
1.2 StringBuffer、StringBuilder
字符串缓冲区,可以理解为一个容器,但是这个容器只能装载字符串
1.2.1 StringBuffer和StringBuilder的区别
-
StringBuffer是线程安全的,效率低
-
所有方法都使用了synchronized关键字(同步锁)
-
-
StringBuilder是线程不安全的,效率高
-
所有方法都没有synchronized关键字
-
-
两者之间非常相像 只是底层不一样,用法都一致
使用场景:
如果是多线程的环境厦,用StringBuffer,因为要保证线程安全
如果是单线程的环境下,用StringBuilder,因为不需要保护线程安全
1.2.2 创建方式
最常用的
StringBuffer buffer = new StringBuffer("abc");
构造方法可以传入一个字符传,也可以不传,不传值的情况下,就是创建了一个空的缓冲区。
1.2.3 常用方法
-
append("xxx")
-
向缓冲区末尾追加指定字符串
-
-
toString()
-
将缓冲区转为字符串
-
-
subString()
-
subString(int start,int end)
-
从指定位置开始截取到指定位置
-
只包含开始的,不包含结束的
-
-
subString(int start)
-
从指定位置开始 截取到最后(包含最后的值)
-
-
1.3 Date类
Date类代表的是时间对象,可以通过该对象对时间进行一些操作。
1.3.1 创建方式
第一种
获取当前系统时间的对象
Date date = new Date();
第二种
根据指定的毫秒值 获取指定的时间对象
Date date = new Date(时间的毫秒值);
1.3.2 常用方法
获取该时间对象对应的毫秒值
long time = getTime();
1.4 DateFormat类
是操作时间/日期的抽象类,可以把字符串和日期进行互相转换,该类是抽象类,不能被直接实例化,可以用其子类SimpleDateFormat
1.4.1创建对象
SimpleDateFormat simple = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
1.4.2 常用方法
将日期对象转为字符串
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String format = sdf.format(new Date());
System.out.println("转换好的字符串:"+format);
将字符串转为日期对象
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String timeStr = "24-03-16 15:50:34";
Date date = sdf.parse(timeStr);
System.out.println("转换好的日期"+date);
1.5 Calendar类
代表日历类,可以单独对年,月,日,时,分,秒进行操作
如果想获取三年前的今天 用Date和DateFormat来做
思路:
-
获取当前系统的时间毫秒值
-
将毫秒值传入到Date对象 获取到Date对象
-
计算三年的时间 是多少毫秒值
-
进行减法操作
-
在将日期对象转为字符串
import java.text.SimpleDateFormat; import java.util.Date; public class Main {public static void main(String[] args) {// 获取当前时间Date currentDate = new Date();// 创建SimpleDateFormat对象,并设置日期格式SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");// 将当前时间减去3年long threeYearsAgoMillis = currentDate.getTime() - (3L * 365 * 24 * 60 * 60 * 1000);Date threeYearsAgo = new Date(threeYearsAgoMillis);// 使用SimpleDateFormat格式化3年前的时间并输出String formattedDate = sdf.format(threeYearsAgo);System.out.println("当前时间的3年前是:" + formattedDate);} }
如果用日历类来做 就非常简单了
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
public class Main {public static void main(String[] args) {// 获取当前时间Date currentDate = new Date();// 创建一个Calendar对象,并将当前时间设置为其时间Calendar calendar = Calendar.getInstance();calendar.setTime(currentDate);// 将年份减去3calendar.add(Calendar.YEAR, -3);// 获取3年前的时间Date threeYearsAgo = calendar.getTime();// 使用SimpleDateFormat格式化日期SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");String formattedDate = sdf.format(threeYearsAgo);System.out.println("当前时间的3年前是:" + formattedDate);}
}
1.5.1 创建方式
Calendar c = Calendar.getInstance();
1.6 BigInteger、BigDecimal类
BigInter计算大整数,BigDecimal计算小数的,用该类计算小数不会丢失精度,0.093131112363131,用float只是保留单精度,用double只是保留双精度,如果小数特别小,必须精确到最后1位 我们只能用BigDecimal,如银行金额问题。
1.7 Random类
主要用于生成随机数,可以指定范围
1.7.1 创建对象
使用无参构造方式创建
Random ran = new Random();
核心方法
nextInt(int xxxx);
2. 集合
2.1 集合和数组的区别
-
相同点:
-
数组和集合都是存储数据的容器
-
-
不同点
-
数组的长度是固定的,集合的长度是可变的。
-
数组只能存储同类型的对象,集合可以存储不同类型的对象
-
2.2 集合框架体系
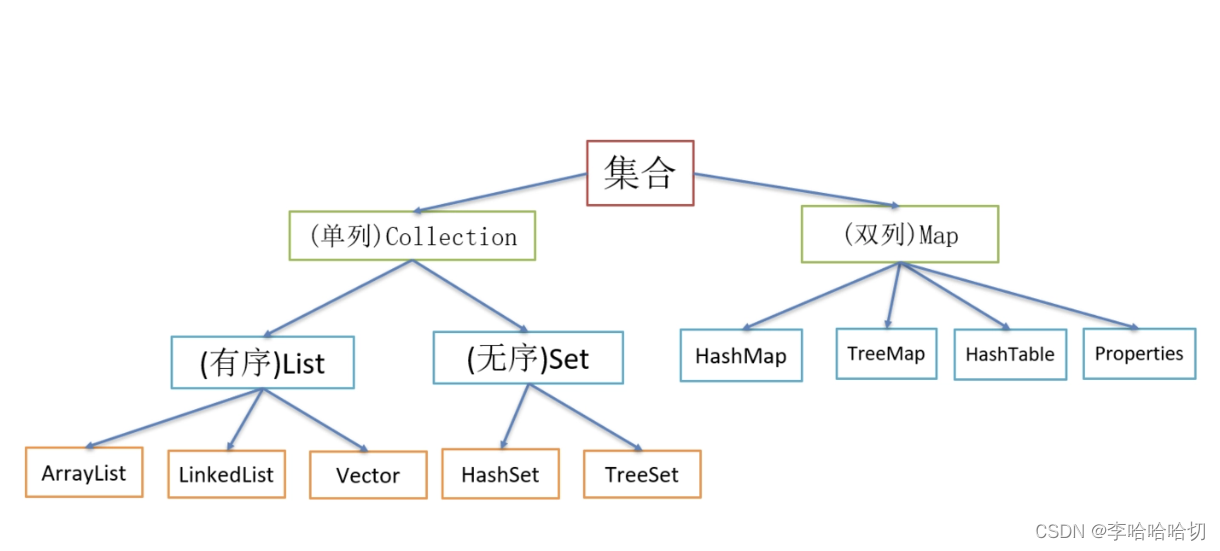
2.3 List集合
2.3.1 List集合的特点和常用方法
-
特点:
-
它是一个元素存取有序的集合。例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的)。
-
它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
-
集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
-
-
常用方法:
-
public void add(E element)
-
public E get(int index)
-
public E remove(int index)
-
public E set(int index, E element)
-
2.3.2 List集合的实现类
-
ArrayList
-
ArrayList集合数据存储的结构是数组结构。元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以
ArrayList是最常用的集合。
-
-
LinkedList
-
LinkedList集合数据存储的结构是链表结构。方便元素添加、删除的集合。
-
-
Vector
-
数组结构实现,查询快,增删慢
-
-
ArrayList、LinkedList和Vector的区别?
-
底层的数据结构是数组,查询快,增删慢,线程不安全,效率高。
-
底层的数据库结构是链表,查询慢,增删快,线程不安全,效率高。
-
底层的数据结构是数组,查询快,增删慢,线程安全,效率低。
-
LinkedList和ArrayList都是List接口的实现类,正常的添加获取删除方法都是一样的
LinkedList可以直接操作首条和最后一条数据
2.4 Set集合
2.4.1 Set集合的特点和常用方法
-
特点
-
Set集合中的元素都是唯一的,不会有重复的元素,即使是null值也只能有一个。另外Set集合是无序的,不能记住元素的添加顺序,因为没有索引值,所以Set集合中的对象不会按特定的方式排序,它只是简单地把对象放到集合中。
-
-
常用方法
-
添加元素: add(E e): 将指定的元素添加到Set集合中。如果元素已经存在,则不进行添加,返回false;否则添加成功,返回true。
-
删除元素:
remove(Object o): 从Set集合中移除指定的元素。 clear(): 清空Set集合中的所有元素。
3. 判断元素是否存在:
contains(Object o): 判断Set集合中是否包含指定的元素。 isEmpty(): 判断 Set集合是否为空,即不包含任何元素。
4. 获取集合大小:
size(): 返回Set集合中的元素个数。
5. 遍历集合:
使用迭代器(Iterator)或增强型for循环来遍历Set集合中的元素。 注意:因为set集合没有下标,所以不可以使用普通for循环进行集合的遍历,但是可以使用增强for
2.4.1 Set集合的实现类
-
HashSet
-
HashSet集合底层采取哈希表存储的数据,特点是无序,不重复,无索引
-
-
TreeSet
-
TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都较好
-
注意:TreeSet集合是一定要排序的,可以将元素按照指定的规则进行排序
-
TreeSet集合排序规则:
-
对于数值类型:Interge,Double,官方默认按照大小进行升序排序。
-
对于字符串类型:默认按照首字符的编号升序排序。
-
对于自定义类型如Student对象,TreeSet无法直接排序。
-
-
TreeSet集合存储对象自定义排序规则方式:
-
让自定义的类(如学生类)实现Comparable接口重写里面的comparaTo方法来制定比较规则。
-
TreeSet集合有参数构造器,可以设置Comparator接口对应的比较器对象,来制定比较规则
-
两种方式返回值规则
-
如果认为第一个元素大于第二个元素返回正整数即可。
-
如果认为第一个元素小于第二个元素返回负整数即可。
-
如果认为第一个元素等于第二个元素返回0即可,此时TreeSet集合只会保留一个元素,认为两者重复。
-
-
-
Set集合的使用场景:
-
是否需要不重复元素
-
不需要排序
-
HashSet
-
-
需要排序
-
TreeSet
-
2.5 Map集合
2.5.1 Map集合的特点和常用方法
-
特点:
-
map是一个双列集合,一个元素中包含两个值(key—Value),map集合中的键与值存在映射关系,key(键)唯一,value(值)允许重复,无序,无索引。
-
-
常用方法:
-
V put(K key, V value) :
-
可以相同的key值,但是添加的value值会覆盖前面的,返回值是前一个,如果没有就返回null
-
-
value get(key):
-
可以用于判断键是否存在的情况。当指定的键不存在的时候,返回的是null。
-
-
2.5.2 Map集合的遍历方式
-
使用keyset()方法
-
使用Entry对象遍历
2.5.3 HashMap
-
特点
-
Hashmap存取是无序的,键位置是唯一的,底层的数据结构是控制键的,jdk1.8前数据结构是:链表+数组 jdk1.8之后是:数组+链表+红黑树。
-
HashMap线程不安全,多线程下扩容容易死循环,多线程下put可能会数据覆盖,put与get并发时,可能导致get为null
-
-
扩容方式:
-
初始容量
-
当添加第一个元素时,hashmap默认的初始数组大小为16,通过位移运算1<<4得出,数组长度为2^n。
-
-
负载因子
-
用来描述hashmap集合中元素的填满程度,默认为0.75f。
-
-
扩容条件
-
HashMap中的元素超过扩容阈值(当前数组容量x加载因子)时,数组扩容为原数组的两倍。或者加入新元素时,如果链表长度大于8,会将当前链表转为红黑树,再转为红黑树之前,会判断数组长度,如果数组长度小于64,会发生扩容,如果数组长度大于64,则正常转为红黑树。
-
-
-
Put过程:
-
当新添加一个KV键值对元素时,通过该元素的key的hash值,计算该元素在数组中应该保存的下标位置。如果该下标位置已经在其他的Node对象(产生哈希冲突),则采用链地址法处理,即将新元素封装成一个新的Node对象,插入到该下标位置的链表尾部(尾插法)。当链表的长度超过8并且数组长度大于64时,为了避免查找性能下降,该链表会转化成黑红树。
HashMap和HashTable的区别
-
HashMap是线程不安全的效率高
-
HashTable是线程安全的,效率低
-
HashMap可以允许key为null值,而HashTable不允许
-
3. 数据库(Mysql)
3.1 常见的数据库
-
Oracle
-
大型的收费数据库,Oracle公司产品,价格昂贵,银行用的都是oracle。
-
-
MySQL
-
开源免费的中小型数据库,后来Sun公司收购了MySQL,而Oracle又收购了Sun公司。
-
目前Oracle推出了收费版本的MySQL,也提供了免费的社区版本
-
-
SQL Server
-
Microsoft 公司推出的收费的中型数据库,C#、.net等语言常用。
-
-
DB2
-
IBM公司的数据库产品,收费的。常应用在银行系统中。
-
-
SQLite
-
嵌入式的微型数据库。Android内置的数据库采用的就是该数据库
-
3.2 Mysql的基础知识
-
基本概念
-
MySQL由一个或多个数据表组成,每个数据表包含表头、列、行、键和值。表头是列的名称,列包含具有相同数据类型的数据,行包含描述某条记录的具体信息,值与列的数据类型相同,键在当前列中具有唯一性
-
-
数据类型:
-
MySQL有三大类数据类型,分别是数值、日期时间和字符串,这些大类下又细分为更多子类型,如整数、小数、日期、时间等。
-
-
架构设计:
-
MySQL的逻辑架构包括客户端、核心服务层和存储引擎层。客户端提供连接处理、身份验证等功能,核心服务层处理SQL解析、权限判断等,存储引擎层负责数据的存储和获取。
-
-
事务:
-
事务具有原子性、一致性、隔离性和持久性四个特性。事务中的操作要么全部成功,要么全部失败回滚;事务执行前后都必须处于一致性状态;事务之间不能相互影响,即隔离性;事务一旦提交,对数据库的改变就是永久性的。
-
-
索引:
-
MySQL使用B-Tree索引和Hash索引。B-Tree索引是一种平衡的m-way查找树,可以利用多个分支节点减少查询数据时所经历的节点数。Hash索引通过哈希函数将键映射到存储位置,适用于等值查询。
-
3.3 SQL
全称 Structured Query Language,结构化查询语言。操作关系型数据库的编程语言,定义了 一套操作关系型数据库统一标准
3.3.1 Sql的分类
SQL语句,根据其功能,主要分为四类:DDL、DML、DQL、DCL。
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
这里我们重点复习DML和DQL 也就是对表中数据的增删改查
3.3.2 DML
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
-
添加数据
-
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...);
-
INSERT INTO 表名 VALUES (值1, 值2, ...);
-
-
修改数据
-
UPDATE 表名 SET 字段名1 = 值1,字段名2 = 值2, .... [WHERE 条件];
-
-
删除数据
-
DELETE FROM 表名 [WHERE 条件];
-
3.3.3 DQL
DQL英文全称是Data Query Language(数据查询语言),数据查询语言,用来查询数据库中表的记录
3.3.3.1 基本语法
SELECT字段列表 FROM表名列表 WHERE条件列表 GROUP BY分组字段列表 HAVING分组后条件列表 ORDER BY排序字段列表 LIMIT分页参数
3.3.3.2 查询的分类
-
基本查询 (不带任何条件)
-
条件查询 (WHERE)
-
聚合函数 (count、max、min、avg、sum)
-
分组查询 (group by)
-
排序查询 (order by)
-
分页查询 (limit)
3.4 事务
MySQL事务是一组在数据库中执行的操作,它们必须要么全部成功执行,要么全部不执行。MySQL事务被设计为确保数据库中的数据的完整性和一致性,即使在并发访问的情况下也是如此。在并发访问的情况下,事务确保数据的正确性,而不会出现数据不一致或错误的情况。
3.4.1 特性
-
原子性(Atomicity)
-
事务是一个原子操作,它要么全部成功,要么全部失败回滚。如果事务中的任何操作失败,则所有操作都将回滚到之前的状态,以确保数据库中的数据不会被部分更改。
-
-
一致性(Consistency)
-
事务的执行必须使数据库从一个一致状态转换到另一个一致状态。这意味着事务必须满足所有约束条件,以保持数据的完整性和一致性。
-
-
隔离性(Isolation)
-
并发事务的执行不能相互干扰。事务必须在独立的空间内执行,这意味着它们看起来像是在独占访问数据库。
-
-
持久性(Durability)
-
一旦事务完成提交,其结果就是永久性的,并且即使在系统故障的情况下,也必须能够恢复这些结果
-
3.4.2 事务的操作
1、START TRANSACTION(或BEGIN):开始一个事务。所有在该语句之后执行的语句都将视为该事务的一部分。
2、COMMIT:提交事务。如果事务成功,则所有修改将成为永久性的。如果提交失败,则事务将回滚到其开始状态。
3、ROLLBACK:撤消事务中进行的所有修改,并将数据库恢复到事务开始时的状态。
3.4.3 隔离级别
MySQL支持四种事务隔离级别,分别是:
-
Read Uncommitted(读取未提交内容):在这个级别下,所有事务都可以看到其他未提交事务的执行结果,这可能导致“脏读”现象,即事务A读取到事务B未提交的数据修改。
-
Read Committed(读取提交内容):这是大多数数据库系统的默认隔离级别,也是MySQL的默认隔离级别。在这个级别下,事务只能读取到其他已提交事务所做的修改,这样可以避免“脏读”问题。
-
Repeatable Read(可重复读取):在可重复读取隔离级别下,对同一字段多次读取的结果都是一致的。这意味着,如果一个事务在查询数据时,其他事务没有提交修改,那么事务再次查询时,会看到相同的数据。然而,这个级别仍然可能发生“幻读”现象,即在同一个查询范围内,另一个事务插入了新行,导致事务再次查询时发现“幻影”行。
-
Serializable(可串行化):这是最高的事务隔离级别,它通过强制事务排序,确保所有操作按照一个固定的顺序执行,从而避免并发问题。但是,这种隔离级别会导致性能大幅下降,因为它会锁定所有依赖的行,以防止任何违反隔离级别规则的操作发生。
总结来说,MySQL的事务隔离级别提供了不同程度的一致性和隔离性,以防止并发操作导致的数据不