大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 大模型应用向开发路径及一点个人思考
- 大模型应用开发实用开源项目汇总
- 大模型问答项目问答性能评估方法
- 大模型数据侧总结
- 大模型token等基本概念及参数和内存的关系
文章目录
- 大模型相关目录
SOTA:State of the Art 业内最优水平,最先进的技术。
AIGC:狭义概念是利用AI自动生成内容的生产方式。广义的AIGC可以看作是像人类一样具备生成创造能力的AI技术,即生成式AI,它可以基于训练数据和生成算法模型,自主生成创造新的文本、图像、音乐、视频、3D交互内容等各种形式的内容和数据,以及包括开启科学新发现、创造新的价值和意义等。
LLM:大语言模型(large language model ),基于海量文本数据训练的深度学习模型。
token:根据事先定义好的编码算法对应出来的最小文本输入单元,一个token可以是一个单词,也可以是字符块。因此文本数据集长度和token只是正相关而非严格对应。
prompt:“提示词”,在AI大模型中,Prompt的作用主要是给AI模型提示输入信息的上下文和输入模型的参数信息。本质是起到提示作用的长token。
chatGLM 7B:一般指参数的个数,B是Billion/十亿的意思,175B是1750亿参数。
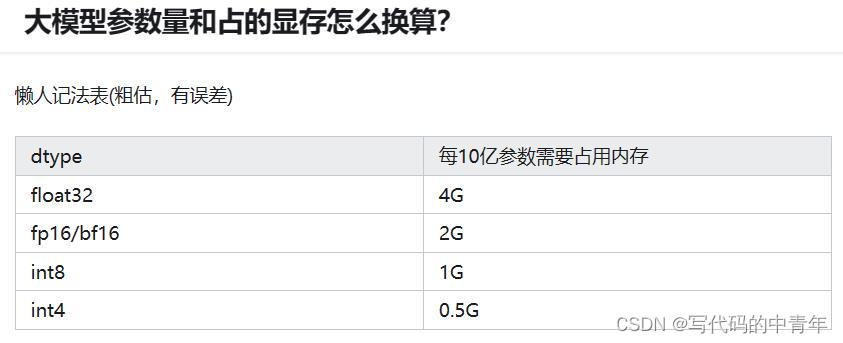
int float:一般有fp32、fp16、bf16、int8等几种模型保存格式,主要是模型参数的保存精度。
CLIP : Contrastive Language-Image Pre-Training,大规模预训练图文表征模型,用大量来自网络的图文对数据集,将文本作为图像标签,进行训练。一张图像和它对应的文本描述,希望通过对比学习,模型能够学习到文本-图像对的匹配关系。
Stable Diffusion:Diffusion算法在去噪任意图片后,得到的结果往往是不可预测的。然而,如果我们能让Diffusion算法接受文字提示,以生成我们想要的图片,那将会是一个重大突破。这就是目前AIGC领域的一个热点——AI绘画:用户只需输入文字描述,系统即可自动生成相应的图像。其核心算法——Stable Diffusion,实际上是多模态算法CLIP和图像生成算法Diffusion的结合。在这个过程中,CLIP作为文字提示的输入,进一步影响Diffusion,从而生成我们需要的图片。
Fine-tuning (微调):微调(Fine-tuning)是一种常用的机器学习方法,主要用于对已经预训练过的模型进行调整,使其适应新的任务。
指令微调,指的是使用一些自然语言描述的指令形式样本去用监督学习的方式微调预训练大模型(base model),经过指令精调后,LLM能在一些未见过的任务上表现较好的能力,甚至是多语言场景。
增量微调,是指在神经网络中增加额外的层并基于一定的数据集进行训练,如lora,adapter。
LORA:Low-Rank Adapta-tion ,用于模型微调的一种新技术,在保持模型质量的同时显着减少下游任务的可训练参数数量,广泛应用于LLM和扩散模型微调。
Agent:人工智能代理,使用语言模型来选择要采取的一系列操作,Agent适用于具有记忆和对话功能的更复杂场景。解锁 LLM 的能力限制。特殊性在于它可以使用各种外部工具来完成我们给定的操作。
RAG:检索增强生成,AI和传统检索技术(Retrieval Technology)的有机结合,用AI总结知识检索内容,用于控制输出精确程度和扩展知识。
LangChain:用于开发大语言模型应用的开发框架。




“线程安全”是什么?有哪些线程安全的集合工具)







)
![[Redis]——Redis持久化的两种方式RDB、AOF](http://pic.xiahunao.cn/[Redis]——Redis持久化的两种方式RDB、AOF)
 1.23.0高可用集群)
 call)


)
