今天为大家介绍一款大语言模型(LLM)部署和推理工具——Xinference[1],其特点是部署快捷、使用简单、推理高效,并且支持多种形式的开源模型,还提供了 WebGUI 界面和 API 接口,方便用户进行模型部署和推理。
现在就让我们一起来了解和使用 Xinference 吧!
Xinference 介绍
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于各种模型的推理。通过 Xinference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xinference 与最前沿的 AI 模型,发掘更多可能。下面是 Xinference 与其他模型部署推理工具的对比:

技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗技术与面试交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:技术交流
Xinference 安装
Xinference 支持两种方式的安装,一种是使用 Docker 镜像安装,另外一种是直接在本地进行安装。想了解 Docker 安装方式的朋友可以参考官方的Docker 安装文档[2],我们这里主要介绍本地安装的方式。
首先安装 Xinference 的 Python 依赖:
pip install "xinference[all]"
Xinference 依赖的第三方库比较多,所以安装需要花费一些时间,等安装完成后,我们就可以启动 Xinference 服务了,启动命令如下:
xinference-local
启动成功后,我们可以通过地址 http://localhost:9777来访问 Xinference 的 WebGUI 界面了。

**注意:**在 Xinference 安装过程中,有可能会安装 PyTorch 的其他版本(其依赖的vllm[3]组件需要安装),从而导致 GPU 服务器无法正常使用,因此在安装完 Xinference 之后,可以执行以下命令看 PyTorch 是否正常:
python -c "import torch; print(torch.cuda.is_available())"
如果输出结果为True,则表示 PyTorch 正常,否则需要重新安装 PyTorch,PyTorch 的安装方式可以参考PyTorch 的页面[4]。
模型部署与使用
在 Xinference 的 WebGUI 界面中,我们部署模型非常简单,下面我们来介绍如何部署 LLM 模型。
首先我们在Launch Model菜单中选择LANGUAGE MODELS标签,输入模型关键字chatglm3来搜索我们要部署的 ChatGLM3 模型。

然后点击chatglm3卡片,会出现如下界面:

在部署 LLM 模型时,我们有以下参数可以进行选择:
-
Model Format: 模型格式,可以选择量化和非量化的格式,非量化的格式是
pytorch,量化格式有ggml、gptq等 -
Model Size:模型的参数量大小,如果是 ChatGLM3 的话就只有 6B 这个选项,而如果是 Llama2 的话,则有 7B、13B、70B 等选项
-
Quantization:量化精度,有 4bit、8bit 等量化精度选择
-
N-GPU:选择使用第几个 GPU
-
Model UID(可选): 模型自定义名称,不填的话就默认用原始模型名称
参数填写完成后,点击左边的火箭图标按钮即开始部署模型,后台会根据参数选择下载量化或非量化的 LLM 模型。部署完成后,界面会自动跳转到Running Models菜单,在LANGUAGE MODELS标签中,我们可以看到部署好的 ChatGLM3-6B 模型。
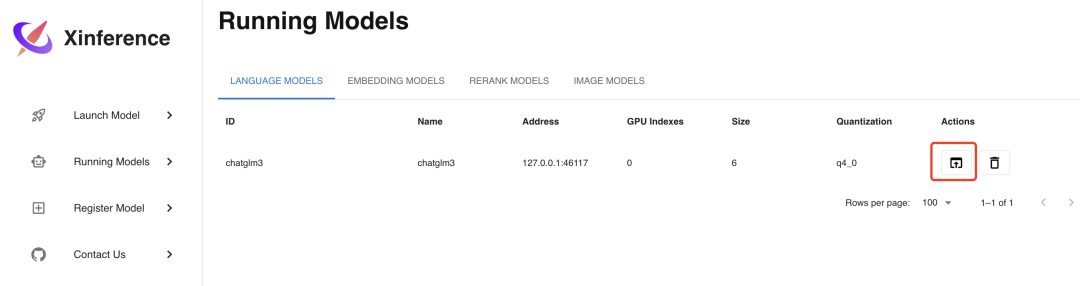
我们如果点击上图的红色方框图标Launch Web UI,浏览器会弹出 LLM 模型的 Web 界面,在这个界面中,你可以与 LLM 模型进行对话,界面如下:

API 接口
如果你不满足于使用 LLM 模型的 Web 界面,你也可以调用 API 接口来使用 LLM 模型,其实在 Xinference 服务部署好的时候,WebGUI 界面和 API 接口已经同时准备好了,在浏览器中访问http://localhost:9997/docs/就可以看到 API 接口列表。

接口列表中包含了大量的接口,不仅有 LLM 模型的接口,还有其他模型(比如 Embedding 或 Rerank )的接口,而且这些都是兼容 OpenAI API 的接口。以 LLM 的聊天功能为例,我们使用 Curl 工具来调用其接口,示例如下:
curl -X 'POST' \'http://localhost:9997/v1/chat/completions' \-H 'accept: application/json' \-H 'Content-Type: application/json' \-d '{"model": "chatglm3","messages": [{"role": "user","content": "hello"}]}'# 返回结果
{"model": "chatglm3","object": "chat.completion","choices": [{"index": 0,"message": {"role": "assistant","content": "Hello! How can I help you today?",},"finish_reason": "stop"}],"usage": {"prompt_tokens": 8,"total_tokens": 29,"completion_tokens": 37}
}
多模态模型
我们再来部署多模态模型,多模态模型是指可以识别图片的 LLM 模型,部署方式与 LLM 模型类似。
首先选择Launch Model菜单,在LANGUAGE MODELS标签下的模型过滤器Model Ability中选择vl-chat,可以看到目前支持的 2 个多模态模型:

我们选择qwen-vl-chat这个模型进行部署,部署参数的选择和之前的 LLM 模型类似,选择好参数后,同样点击左边的火箭图标按钮进行部署,部署完成后会自动进入Running Models菜单,显示如下:

点击图中Launch Web UI的按钮,浏览器会弹出多模态模型的 Web 界面,在这个界面中,你可以使用图片和文字与多模态模型进行对话,界面如下:

Embedding 模型
Embedding 模型是用来将文本转换为向量的模型,使用 Xinference 部署的话更加简单,只需要在Launch Model菜单中选择Embedding标签,然后选择相应模型,不像 LLM 模型一样需要选择参数,只需直接部署模型即可,这里我们选择部署bge-base-en-v1.5这个 Embedding 模型。


我们通过 Curl 命令调用 API 接口来验证部署好的 Embedding 模型:
curl -X 'POST' \'http://localhost:9997/v1/embeddings' \-H 'accept: application/json' \-H 'Content-Type: application/json' \-d '{"model": "bge-base-en-v1.5","input": "hello"
}'# 显示结果
{"object": "list","model": "bge-base-en-v1.5-1-0","data": [{"index": 0,"object": "embedding","embedding": [0.0007792398682795465, …]}],"usage": {"prompt_tokens": 37,"total_tokens": 37}
}
Rerank 模型
Rerank 模型是用来对文本进行排序的模型,使用 Xinference 部署的话也很简单,方法和 Embedding 模型类似,部署步骤如下图所示,这里我们选择部署bge-reranker-base这个 Rerank 模型:


我们通过 Curl 命令调用 API 接口来验证部署好的 Rerank 模型:
curl -X 'POST' \'http://localhost:9997/v1/rerank' \-H 'accept: application/json' \-H 'Content-Type: application/json' \-d '{"model": "bge-reranker-base","query": "What is Deep Learning?","documents": ["Deep Learning is ...","hello"]
}'# 显示结果
{"id": "88177e80-cbeb-11ee-bfe5-0242ac110007","results": [{"index": 0,"relevance_score": 0.9165927171707153,"document": null},{"index": 1,"relevance_score": 0.00003880404983647168,"document": null}]
}
图像模型
Xinference 还支持图像模型,使用图像模型可以实现文生图、图生图等功能。Xinference 内置了几种图像模型,分别是 Stable Diffusion(SD)的各个版本。部署方式和文本模型类似,都是在 WebGUI 界面上启动模型即可,无需进行参数选择,但因为 SD 模型比较大,在部署图像模型前请确保服务器上有 50GB 以上的空间。这里我们选择部署sdxl-turbo图像模型,部署步骤截图如下:


我们可以使用 Python 代码调用的方式来使用图像模型生成图片,示例代码如下:
from xinference.client import Clientclient = Client("http://localhost:9997")
model = client.get_model("sdxl-turbo")model.text_to_image("An astronaut walking on the mars")
这里我们使用了 Xinference 的客户端工具来实现文生图功能,生成的图片会自动保存在 Xinfercnce 的 Home 目录下的image文件夹中,Home 目录的默认地址是~/.xinference,我们也可以在启动 Xinference 服务时指定 Home 目录,启动命令如下:
XINFERENCE_HOME=/tmp/xinference xinference-local
语音模型
语音模型是 Xinference 最近新增的功能,使用语音模型可以实现语音转文字、语音翻译等功能。在部署语音模型之前,需要先安装ffmpeg组件,以 Ubuntu 操作系统为例,安装命令如下:
sudo apt update && sudo apt install ffmpeg
目前 Xinference 还不支持在 WebGUI 界面上部署语音模型,需要通过命令行的方式来部署语音模型,在执行部署命令之前需要确保 Xinference 服务已经启动(xinference-local),部署命令如下:
xinference launch -u whisper-1 -n whisper-large-v3 -t audio
-
-u:表示模型 ID -
-n:表示模型名称 -
-t:表示模型类型
命令行部署的方式不仅适用语音模型,也同样适用于其他类型的模型。我们通过调用 API 接口来使用部署好的语音模型,接口兼容 OpenAI 的 Audio API 接口,因此我们也可以用 OpenAI 的 Python 包来使用语音模型,示例代码如下:
import openai# api key 可以随便写一个
client = openai.Client(api_key="not empty", base_url="http://127.0.0.1:9997/v1")
audio_file = open("/your/audio/file.mp3", "rb")# 使用 openai 的方法来调用语音模型
completion = client.audio.transcriptions.create(model="whisper-1", file=audio_file)
print(f"completion: {completion}")audio_file.close()
其他
模型来源
Xinference 默认是从 HuggingFace 上下载模型,如果需要使用其他网站下载模型,可以通过设置环境变量XINFERENCE_MODEL_SRC来实现,使用以下代码启动 Xinference 服务后,部署模型时会从Modelscope[5]上下载模型:
XINFERENCE_MODEL_SRC=modelscope xinference-local
模型独占 GPU
在 Xinference 部署模型的过程中,如果你的服务器只有一个 GPU,那么你只能部署一个 LLM 模型或多模态模型或图像模型或语音模型,因为目前 Xinference 在部署这几种模型时只实现了一个模型独占一个 GPU 的方式,如果你想在一个 GPU 上同时部署多个以上模型,就会遇到这个错误:No available slot found for the model。
但如果是 Embedding 或者 Rerank 模型的话则没有这个限制,可以在同一个 GPU 上部署多个模型。
总结
今天给大家介绍了 Xinference 这个开源的部署推理工具,因为其部署方便,支持模型多等特点让我印象非常深刻,希望这篇文章可以让更多人了解这个工具,如果在使用的过程中遇到问题,也欢迎在评论区留言讨论。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。
参考:
[1]Xinference: https://github.com/xorbitsai/inference
[2]Docker 安装文档: https://inference.readthedocs.io/en/latest/getting_started/using_docker_image.html
[3] vllm: https://github.com/vllm-project/vllm
[4]PyTorch 的页面: https://pytorch.org/
[5] Modelscope: https://modelscope.cn/

—— 保存视频流)

















