前言:
IVI中控上的语音识别,在目前市场上也是非常显眼的一个创新,大幅改变了传统IVI的操作习惯。

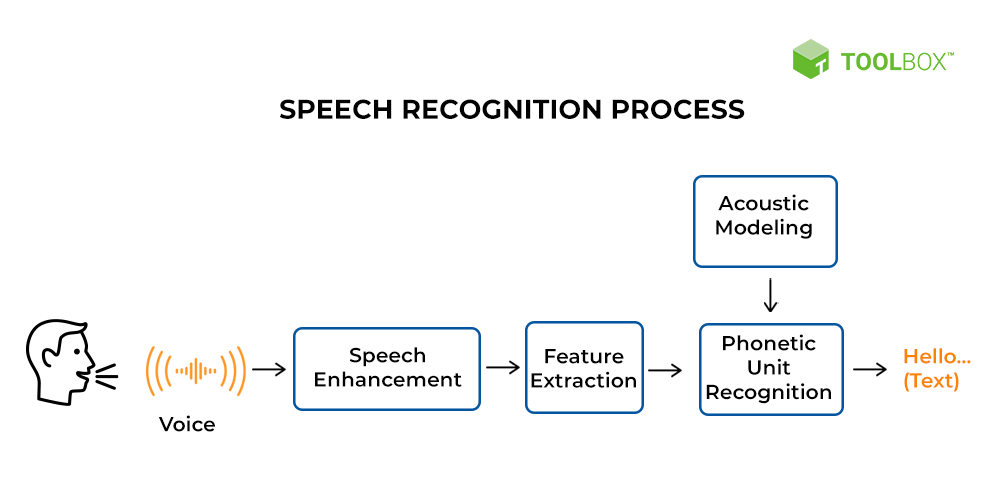
语音识别Speech recognition,也称为自动语音识别(ASR)、计算机语音识别或语音到文本,是一种使程序能够将人类语音处理成书面格式的能力。
语音识别Speech recognition是计算机科学computer science 和计算语言学computational linguistics的一个跨学科子领域,它开发了能够通过计算机识别口语并将其翻译成文本的方法和技术。它也被称为自动语音识别automatic speech recognition(ASR)、计算机语音识别computer speech recognition或语音到文本speech to text(STT)。它融合了计算机科学、语言学和计算机工程领域的知识和研究。相反的过程是语音合成 speech synthesis。
一些语音识别系统需要“训练training”(也称为“注册enrollment”),即单个说话者将文本或孤立的词汇读入系统。该系统分析人的特定声音,并使用它来微调对该人语音的识别,从而提高准确性。不使用训练的系统被称为“扬声器独立speaker-independent”系统。使用训练的系统被称为“依赖说
)
)

:将格式化字符串输出到数组中)




)








|fastsam模型)

)