OpenAI的文生视频模型SORA与大语言模型(LLM)的主要区别在于它们的应用领域和处理的数据类型,数据处理能力、技术架构、多模态能力和创新点。SORA作为一款专注于视频生成的模型,展现了在处理视觉数据方面的独特优势和创新能力。
1.应用领域:
SORA专注于视频生成,能够根据文本描述生成长达60秒的视频,这些视频包含精细复杂的场景和生动的角色表情,SORA的一个显著特点是其能够在一个生成的视频中创建多个镜头,准确地保留角色和视觉细节。这一点是其他文生视频模型目前无法实现的。此外,SORA通过一次性为模型提供多帧的预测解决了视频连续性的问题。
尽管大语言模型在生成文本内容方面非常强,但在理解、生成视频、图像等方面略显不足。而SORA展现出了良好的多模态能力,不仅支持文本生成视频,还具备图像生成视频等能力。大语言模型(如GPT系列)主要用于文本内容的生成、理解和处理。
2.数据处理能力:
SORA采用的是基于patch块的表示方法,能够对不同分辨率、时长和宽高比的视频和图像进行训练。这意味着SORA在处理视觉数据方面具有高度的灵活性和适应性。相比之下,大语言模型主要处理文本数据,通过token化的方式将各种形式的文本代码、数学和自然语言统一起来。

3.技术架构:
SORA利用了扩散模型和Transformer架构,这使得它不仅具备从文本生成视频的能力,还能从静态图片或扩展已有视频中生成新的内容。SORA是一种类似DiT的扩散模型(DiT的架构如上图所示),舍弃了传统的U-Net架构,性能相比U-Net更优,同时继承了 Transformer 模型类出色的缩放特性。
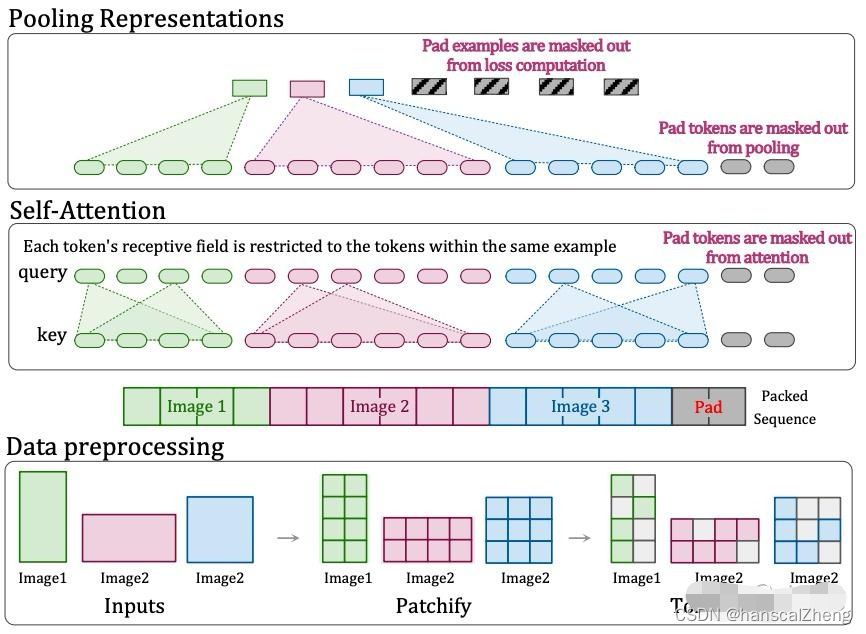
SORA同时采用NaViT的patch打包在同一序列的方法,实现可变的持续时间、分辨率、宽高比等效果。
而大语言模型则侧重于使用Transformer架构来理解和生成文本内容。


——队列)

)

)




)







