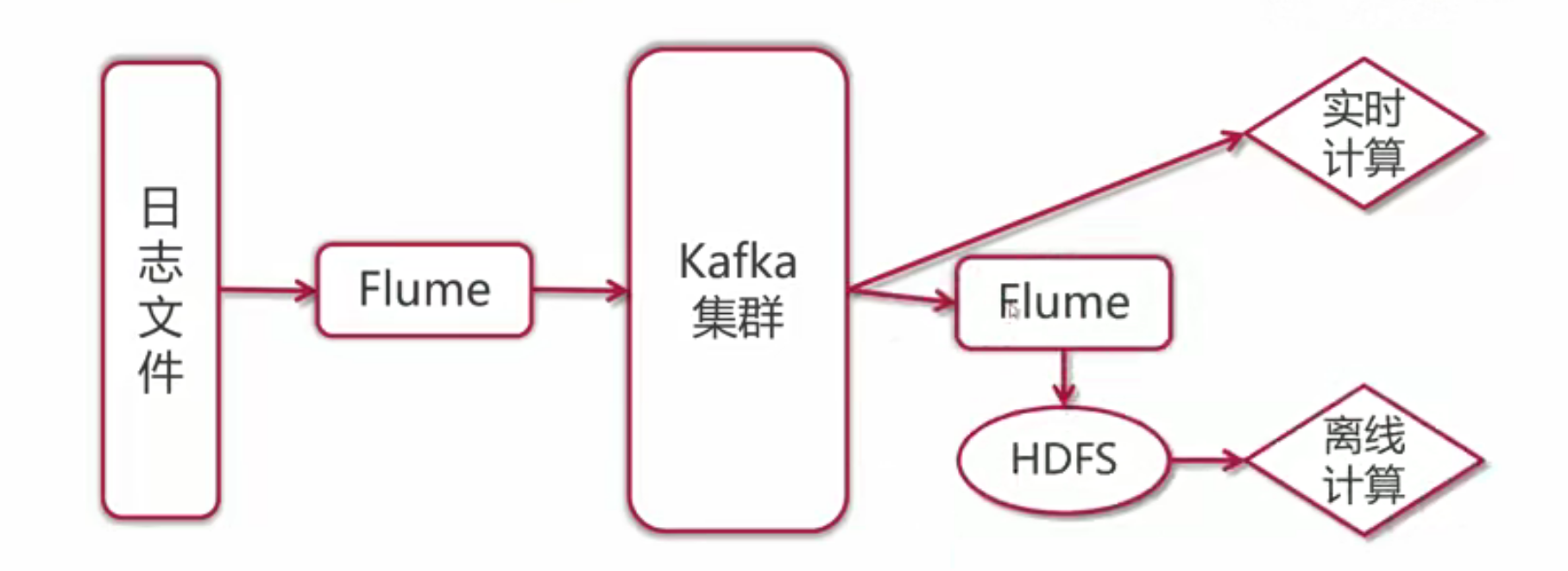
之前提到Flume可以直接采集数据存储到HDFS中,那为什么还要引入Kafka这个中间件呢,这个是因为在实际应用场景中,我们既需要实时计算也需要离线计算。
Kfka to HDFS配置
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1# source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.channels = channel1
a1.sources.r1.batchSize = 10
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop01:9092,hadoop02:9092,hadoop03:9092
a1.sources.r1.kafka.topics = test_r2p5
a1.sources.r1.kafka.consumer.group.id = flume-group1# Bind the source and sink to the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1000# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://192.168.52.100:9000/kafkaout/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = access
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
File to Kafka配置
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1# source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/log/test.log# Bind the source and sink to the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1000# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = test_r2p5
a1.sinks.k1.kafka.bootstrap.servers = hadoop01:9092,hadoop02:9092,hadoop03:9092
a1.sinks.k1.kafka.flumeBatchSize = 10
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
创建Topic
[root@hadoop01 kafka_2.12-2.4.0]# bin/kafka-topics.sh --create --zookeeper hadoop01:2181 --partitions 5 --replication-factor 2 --topic test_r2p5启动flume
[root@hadoop04 conf-kafka-hdfs]# bin/flume-ng agent --name a1 --conf conf-kafka-hdfs --conf-file conf-kafka-hdfs/kafka-to-hdfs.conf -Dflume.root.logger=INFO,console
[root@hadoop04 apache-flume-1.11.0-bin]# bin/flume-ng agent --name a1 --conf conf-file-kafka --conf-file conf-file-kafka/file-to-kafka.conf -Dflume.root.logger=INFO,console创建test.log文件
[root@hadoop04 log]# echo hello world >> /home/log/test.log验证
[root@hadoop01 kafka_2.12-2.4.0]# hdfs dfs -cat /kafkaout/2024-03-13/access.1710307375351.tmp
hello worldp01 kafka_2.12-2.4.0]# hdfs dfs -cat /kafkaout/2024-03-13/access.1710307375351.tmp
hello world



)

)

,并设计一个算法删除所有值大于min而且小于max的元素。)

)

)
CMP指令)






