文章目录
- 一、Semantic Kernel介绍和发展
- 1)SK 的语言开发进展
- 2)SK的生态位
- 3)SK基础架构
- 二、环境搭建
- 1)初始化
- 2)Semantic Functions(不用编写代码,用配置实现回调函数)
- 3)Native Functions(传统编程的回调函数)
- 4)用 SKContext 实现多参数 Functions
- 5)Plugins/Skills(plugin/skill 就是一组函数的集合。它可以包含两种函数:)
- 三、函数的嵌套调用
- 1)Semantic Function 嵌套调用(不用代码的函数)
- 2)Native Function 嵌套调用(纯代码调用)
- 四、Memory
- 1)初始化 Embedding
- 2)文本向量化
- 3)向量搜索
- 4)现在用函数嵌套做一个简单的 RAG
- 5)连接其它 VectorDB
- 五、Planner开发Agent
- 1)什么是智能体(Agent)
- 2)SK Python 提供了四种 Planner:
- 3)用 Planner 实现一个能使用搜索和日历工具的 Agent
- 六、VS Code 插件创建和调试Semantic Function
- 七、Semantic Kernel 对新版 Assistants API 的支持计划
一、Semantic Kernel介绍和发展
- 定义介绍
1、Semantic Kernel 是微软研发的一个开源的,面向大模型的开发框架(SDK);
2、它支持你用不同开发语言(C#/Python/Java)基于 OpenAI API/Azure OpenAI API/Huggingface 开发大模型应用;
3、它封装了一系列开箱即用的工具,包括:提示词模板、链式调用、规划能力等。 - SDK(补充说明)
SDK:Software Development Kit,它是一组软件工具和资源的集合,旨在帮助开发者创建、测试、部署和维护应用程序或软件。
1)SK 的语言开发进展
1、C# 版最成熟,已开始 1.0.1:https://github.com/microsoft/semantic-kernel
2、Python 是 beta 版:https://github.com/microsoft/semantic-kernel
3、Java 版 alpha 阶段:https://github.com/microsoft/semantic-kernel/tree/experimental-java
4、TypeScript 版……,已经放弃了:https://github.com/microsoft/semantic-kernel/tree/experimental-typescript
文档写得特别好,但追不上代码更新速度:
5、更多讲解:https://learn.microsoft.com/en-us/semantic-kernel/overview/
6、更偏实操:https://github.com/microsoft/semantic-kernel/blob/main/python/notebooks/00-getting-started.ipynb
7、API Reference (目前只有C#): https://learn.microsoft.com/en-us/dotnet/api/microsoft.semantickernel?view=semantic-kernel-dotnet
8、更多生态:https://github.com/geffzhang/awesome-semantickernel
这里可以了解最新进展:https://learn.microsoft.com/en-us/semantic-kernel/get-started/supported-languages
2)SK的生态位
- 补充
微软将此技术栈命名为 Copilot Stack。
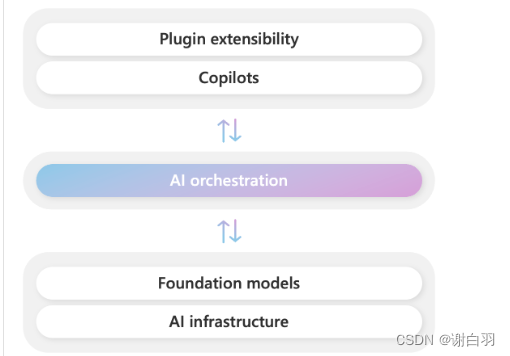
- 解释:
1、Plugin extensibility: 插件扩展
2、Copilots: AI 助手(副驾驶),例如 GitHub Copilot、Office 365 Copilot、Windows Copilot
3、AI orchestration: AI 编排,SK 就在这里
4、Foundation models: 基础大模型,例如 GPT-4
5、AI infrastructure: AI 基础设施,例如 PyTorch、GPU
3)SK基础架构
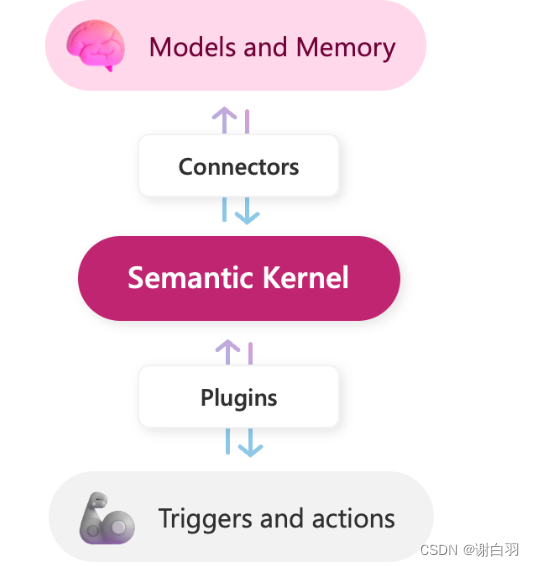
- 解释
1、Models and Memory: 类比为大脑
2、Connectors: 用来连接各种外部服务,类似驱动程序
3、Plugins: 用来连接内部技能
4、Triggers and actions: 外部系统的触发器和动作,类比为四肢 - 说明
1、Semantic Functions:通过 Prompt 实现的 LLM 能力
2、Native Functions: 编程语言原生的函数功能
3、在 SK 中,一组 Function 组成一个技能(Skill/Plugin)。要运行 Skill/Plugin,需要有一个配置和管理的单元,这个组织管理单元就是 Kernel。
4、Kernel 负责管理底层接口与调用顺序,例如:OpenAI/Azure OpenAI 的授权信息、默认的 LLM 模型选择、对话上下文、技能参数的传递等等
二、环境搭建
- 准备
1、安装 Python 3.x:https://www.python.org/downloads/
2、安装 SK 包:pip install semantic-kernel
3、在项目目录创建 .env 文件,添加以下内容:
# .env
OPENAI_API_KEY=""
OPENAI_BASE_URL=""
AZURE_OPENAI_DEPLOYMENT_NAME=""
AZURE_OPENAI_ENDPOINT=""
AZURE_OPENAI_API_KEY=""
--OpenAI 和 Azure,配置好一个就行。!pip install semantic-kernel==0.4.0.dev
1)初始化
- 环境初始化
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion
import os# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())# 创建 semantic kernel
kernel = sk.Kernel()# 配置 OpenAI 服务。OPENAI_BASE_URL 会被自动加载生效
api_key = os.getenv('OPENAI_API_KEY')
model = OpenAIChatCompletion("gpt-3.5-turbo",api_key
)# 把 LLM 服务加入 kernel
# 可以加多个。第一个加入的会被默认使用,非默认的要被指定使用
kernel.add_text_completion_service("my-demo", model)
- 接口解释
划重点: 用我们熟悉的操作系统来类比,可以更好地理解 SK。
1、启动操作系统:kernel = sk.Kernel()
2、安装驱动程序:kernel.add_xxx_service()
3、安装应用程序:func = kernel.create_semantic_function()
4、运行应用程序:func()
- 举例使用prompt说笑话(实验室版本)
# 定义 semantic function (实验室版本)
# 参数由{{ }}标识tell_joke_about = kernel.create_semantic_function("给我讲个关于{{$input}}的笑话吧")# 运行 function 看结果
result = await kernel.run_async(tell_joke_about,input_str="Hello world")
print(result)
- 举例使用prompt说笑话
import asyncioasync def run_function(*args):return await kernel.invoke(*args)result = asyncio.run(run_function(tell_joke_about, input_str="Hello world")
)
- 新版加载方式
注意:新版的加载方式将发生变化,详见:https://github.com/microsoft/semantic-kernel/blob/main/python/notebooks/03-prompt-function-inline.ipynb
2)Semantic Functions(不用编写代码,用配置实现回调函数)
- 介绍
Semantic Functions 是纯用数据(Prompt + 配置文件)定义的,不需要编写任何代码。所以它与编程语言无关,可以被任何编程语言调用 - 组成
1、skprompt.txt: 存放 prompt,可以包含参数,还可以调用其它函数
2、config.json: 存放配置,包括函数功能,参数的数据类型,以及调用大模型时的参数
- 举例:
根据用户的自然语言指示,生成 Linux 命令 - skprompt.txt
已知数据库结构为:CREATE TABLE Courses (id INT AUTO_INCREMENT PRIMARY KEY,course_date DATE NOT NULL,start_time TIME NOT NULL,end_time TIME NOT NULL,course_name VARCHAR(255) NOT NULL,instructor VARCHAR(255) NOT NULL
);
请将下述用户输入转为SQL表达式
用户输入:{{$input}}直接输出SQL语句,不要评论,不要分析,不要Markdown标识!
- config.json
{"schema": 1,"type": "completion","description": "将用户的输入转换成 SQL 语句", #功能描述"completion": { "max_tokens": 256,"temperature": 0,"top_p": 0,"presence_penalty": 0,"frequency_penalty": 0},"input": {"parameters": [{"name": "input","description": "用户的输入","defaultValue": ""}]}
}
- 说明
type 只有 “completion” 和 “embedding” 两种 - 注意
新版格式将发生变化,详见:https://github.com/microsoft/semantic-kernel/blob/main/python/notebooks/02-running-prompts-from-file.ipynb - 备注
上面两个文件都在 demo/MyPlugins/Text2SQL/ 目录下。
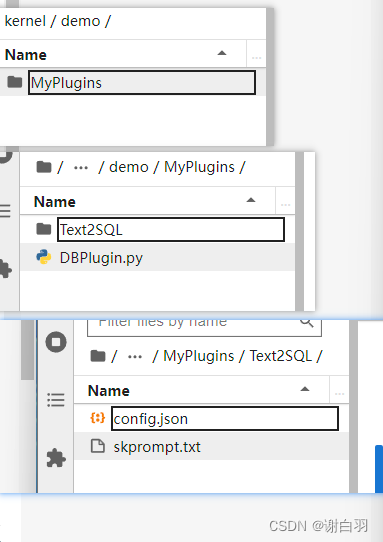
- 附加(查询数据库)
from semantic_kernel.skill_definition import sk_functionclass DBConnector:def __init__(self, db_cursor):self.db_cursor = db_cursor@sk_function(description="查询数据库", # function 描述name="query_database", # function 名字)def exec(self, sql_exp: str) -> str:self.db_cursor.execute(sql_exp)records = cursor.fetchall()return str(records)
- 正式开始调用
# 加载 semantic function。注意目录结构
my_plugins = kernel.import_semantic_skill_from_directory("./demo", "MyPlugins")# 运行
result = await kernel.run_async(my_plugins["Text2SQL"],input_str="2024年4月有哪些课",
)
print(result)
- 回复
SELECT * FROM Courses WHERE course_date BETWEEN '2024-04-01' AND '2024-04-30';
- 若要维护多轮对话(加入历史)
需求:例如我们要维护一个多轮对话,通过 request 和 history 两个变量分别存储 当前输入 和 对话历史
prompt = """对话历史如下:
{{$history}}
---
User: {{$request}}
Assistant: """
- 实际代码展示
history = []while True:request = input("User > ").strip()if not request:break# 通过 ContextVariables 维护多个输入变量variables = sk.ContextVariables()variables["request"] = requestvariables["history"] = "\n".join(history)# 运行 promptsemantic_function = kernel.create_semantic_function(prompt)result = await kernel.run_async(semantic_function,input_vars=variables, # 注意这里从 input_str 改为 input_vars)# 将新的一轮添加到 history 中history.append("User: " + request)history.append("Assistant: " + result.result)print("Assistant > " + result.result)
- 回复
User > 你好
Assistant > 你好,请问有什么可以帮助您的吗?
User > 我刚才问你什么
Assistant > 您刚才问我有什么可以帮助您的。您还有其他问题需要我回答吗?
User >
- 注意
1、官方提供了一些 Semantic Functions 例子参考:https://github.com/microsoft/semantic-kernel/tree/main/samples/plugins
2、注意:新版将引入一个 ChatHistory 类来管理对话上下文,详见:https://github.com/microsoft/semantic-kernel/blob/main/python/notebooks/04-kernel-arguments-chat.ipynb
3)Native Functions(传统编程的回调函数)
- 需求
用编程语言写的函数,如果用 SK 的 Native Function 方式定义,就能纳入到 SK 的编排体系,可以被 Planner、其它 plugin 调用。 - 举例
写一个查询数据库的函数。这个函数名是 query_database。输入为一个 SQL 表达式。它可以放到目录结构中,在 demo/MyPlugins/DBPlugin.py 里加入。
from semantic_kernel.skill_definition import sk_functionclass DBConnector:def __init__(self, db_cursor):self.db_cursor = db_cursor@sk_function(description="查询数据库", # function 描述name="query_database", # function 名字)def exec(self, sql_exp: str) -> str:self.db_cursor.execute(sql_exp)records = cursor.fetchall()return str(records)-------------------------------------
# 定义本地函数和数据库import sqlite3# 创建数据库连接
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()# 创建orders表
cursor.execute("""
CREATE TABLE Courses (id INT AUTO_INCREMENT PRIMARY KEY,course_date DATE NOT NULL,start_time TIME NOT NULL,end_time TIME NOT NULL,course_name VARCHAR(255) NOT NULL,instructor VARCHAR(255) NOT NULL
);
""")# 插入5条明确的模拟记录
timetable = [('2024-01-23', '20:00', '22:00', '大模型应用开发基础', '孙志岗'),('2024-01-25', '20:00', '22:00', 'Prompt Engineering', '孙志岗'),('2024-01-29', '20:00', '22:00', '赠课:软件开发基础概念与环境搭建', '西树'),('2024-02-20', '20:00', '22:00', '从AI编程认知AI', '林晓鑫'),('2024-02-22', '20:00', '22:00', 'Function Calling', '孙志岗'),('2024-02-29', '20:00', '22:00', 'RAG和Embeddings', '王卓然'),('2024-03-05', '20:00', '22:00', 'Assistants API', '王卓然'),('2024-03-07', '20:00', '22:00', 'Semantic Kernel', '王卓然'),('2024-03-14', '20:00', '22:00', 'LangChain', '王卓然'),('2024-03-19', '20:00', '22:00', 'LLM应用开发工具链', '王卓然'),('2024-03-21', '20:00', '22:00', '手撕 AutoGPT', '王卓然'),('2024-03-26', '20:00', '22:00', '模型微调(上)', '王卓然'),('2024-03-28', '20:00', '22:00', '模型微调(下)', '王卓然'),('2024-04-09', '20:00', '22:00', '多模态大模型(上)', '多老师'),('2024-04-11', '20:00', '22:00', '多模态大模型(中)', '多老师'),('2024-04-16', '20:00', '22:00', '多模态大模型(下)', '多老师'),('2024-04-18', '20:00', '22:00', 'AI产品部署和交付(上)', '王树冬'),('2024-04-23', '20:00', '22:00', 'AI产品部署和交付(下)', '王树冬'),('2024-04-25', '20:00', '22:00', '抓住大模型时代的创业机遇', '孙志岗'),('2024-05-07', '20:00', '22:00', '产品运营和业务沟通', '孙志岗'),('2024-05-09', '20:00', '22:00', '产品设计', '孙志岗'),('2024-05-14', '20:00', '22:00', '项目方案分析与设计', '王卓然'),
]for record in timetable:cursor.execute('''INSERT INTO Courses (course_date, start_time, end_time, course_name, instructor)VALUES (?, ?, ?, ?, ?)''', record)# 提交事务
conn.commit()
----------------------
#加载function
# 加载 native function
db_connector = kernel.import_skill(DBConnector(cursor), "DBConnector")# 看结果
result = await kernel.run_async(db_connector["query_database"],input_str="SELECT COUNT(*) as count FROM Courses WHERE instructor = '王卓然'",
)print(result)
- 回复
[(9,)]
4)用 SKContext 实现多参数 Functions
- 需求
需要实现多参数(如果 Function 都只有一个参数,那么只要把参数定义为 {{KaTeX parse error: Expected 'EOF', got '}' at position 6: input}̲},就可以按前面的例子来使用,…input}}会默认被赋值。多参数时,就不能用默认机制了,需要定义 SKContext 类型的变量。) - 多参数的用法
from semantic_kernel.skill_definition import sk_function, sk_function_context_parameter
from semantic_kernel.orchestration.sk_context import SKContextclass NewDBConnector:def __init__(self, db_cursor):self.db_cursor = db_cursor@sk_function(description="查询数据库", # function 描述name="query_database", # function 名字)@sk_function_context_parameter(name="sql_exp",description="SQL表达式",)@sk_function_context_parameter(name="output_prefix",description="输出的文本前缀",)def exec(self, context: SKContext) -> str:self.db_cursor.execute(context['sql_exp'])records = cursor.fetchall()return f"{context['output_prefix']}: {str(records)}"
----------------
# 加载 native function
new_db_connector = kernel.import_skill(NewDBConnector(cursor), "NewDBConnector")# 创建 SKContext
context = sk.ContextVariables()# 变量赋值
context["sql_exp"] = "SELECT COUNT(*) as count FROM Courses WHERE instructor = '王卓然'"
context["output_prefix"] = "课节数"# 看结果
result = await kernel.run_async(new_db_connector["query_database"],input_vars=context
)
print(result)
- 回复
课节数: [(9,)]
- 注意
注意:多参数的 Native Function 的写法,在新版中会简化,详见:https://github.com/microsoft/semantic-kernel/blob/main/python/notebooks/08-native-function-inline.ipynb
5)Plugins/Skills(plugin/skill 就是一组函数的集合。它可以包含两种函数:)
- 介绍
简单说,plugin/skill 就是一组函数的集合。它可以包含两种函数:
1、Semantic Functions - 语义函数,本质是 Prompt Engineering
2、Native Functions - 原生函数,类似 OpenAI 的 Function Calling值得一提的是,SK 的 plugin 会和 ChatGPT、Bing、Microsoft 365 通用。「很快」你用 SK 写的 plugin 就可以在这些平台上无缝使用了。这些平台上的 plugin 也可以通过 SK 被你调用。
- 补充
Plugins 最初命名为 Skills,后来改为 Plugins。但是文档中还可能有「Skill」遗留。见到后,就知道两者是一回事就好 - 配套内置的plugin
from semantic_kernel.core_plugins import <PluginName>
ConversationSummaryPlugin- 生成对话的摘要HttpPlugin- 发出 HTTP 请求,支持 GET、POST、PUT 和 DELETEMathPlugin- 加法和减法计算TextMemoryPlugin- 保存文本到 memory 中,可以对其做向量检索TextPlugin- 把文本全部转为大写或小写,去掉头尾的空格(trim)TimePlugin- 获取当前时间及用多种格式获取时间参数WaitPlugin- 等待指定的时间WebSearchEnginePlugin- 在互联网上搜索给定的文本

)













)



