非线性容器实现能快速查找的数据结构,其底层通过 hash 或者红黑树实现,包括 HashMap、HashSet、TreeMap、TreeSet、LightWeightMap、LightWeightSet、PlainArray 七种。非线性容器中的 key 及 value 的类型均满足 ECMA 标准。
HashMap
HashMap 可用来存储具有关联关系的 key-value 键值对集合,存储元素中 key 是唯一的,每个 key 会对应一个 value 值。
HashMap 依据泛型定义,集合中通过 key 的 hash 值确定其存储位置,从而快速找到键值对。HashMap 的初始容量大小为 16,并支持动态扩容,每次扩容大小为原始容量的 2 倍。HashMap 底层基于 HashTable 实现,冲突策略采用链地址法。
HashMap 和 TreeMap 相比,HashMap 依据键的 hashCode 存取数据,访问速度较快。而 TreeMap 是有序存取,效率较低。
HashSet 基于 HashMap 实现。HashMap 的输入参数由 key、value 两个值组成。在 HashSet 中,只对 value 对象进行处理。
需要快速存取、删除以及插入键值对数据时,推荐使用 HashMap。
HashMap 进行增、删、改、查操作的常用 API 如下:

HashSet
HashSet 可用来存储一系列值的集合,存储元素中 value 是唯一的。
HashSet 依据泛型定义,集合中通过 value 的 hash 值确定其存储位置,从而快速找到该值。HashSet 初始容量大小为 16,支持动态扩容,每次扩容大小为原始容量的 2 倍。value 的类型满足 ECMA 标准中要求的类型。HashSet 底层数据结构基于 HashTable 实现,冲突策略采用链地址法。
HashSet 基于 HashMap 实现。在 HashSet 中,只对 value 对象进行处理。
HashSet 和 TreeSet 相比,HashSet 中的数据无序存放,即存放元素的顺序和取出的顺序不一致,而 TreeSet 是有序存放。它们集合中的元素都不允许重复,但 HashSet 允许放入 null 值,TreeSet 不允许。
可以利用 HashSet 不重复的特性,当需要不重复的集合或需要去重某个集合的时候使用。
HashSet 进行增、删、改、查操作的常用 API 如下:

TreeMap
TreeMap 可用来存储具有关联关系的 key-value 键值对集合,存储元素中 key 是唯一的,每个 key 会对应一个 value 值。
TreeMap 依据泛型定义,集合中的 key 值是有序的,TreeMap 的底层是一棵二叉树,可以通过树的二叉查找快速的找到键值对。key 的类型满足 ECMA 标准中要求的类型。TreeMap 中的键值是有序存储的。TreeMap 底层基于红黑树实现,可以进行快速的插入和删除。
TreeMap 和 HashMap 相比,HashMap 依据键的 hashCode 存取数据,访问速度较快。而 TreeMap 是有序存取,效率较低。
一般需要存储有序键值对的场景,可以使用 TreeMap。
TreeMap 进行增、删、改、查操作的常用 API 如下:

TreeSet
TreeSet 可用来存储一系列值的集合,存储元素中 value 是唯一的。
TreeSet 依据泛型定义,集合中的 value 值是有序的,TreeSet 的底层是一棵二叉树,可以通过树的二叉查找快速的找到该 value 值,value 的类型满足 ECMA 标准中要求的类型。TreeSet 中的值是有序存储的。TreeSet 底层基于红黑树实现,可以进行快速的插入和删除。
TreeSet 基于 TreeMap 实现,在 TreeSet 中,只对 value 对象进行处理。TreeSet 可用于存储一系列值的集合,元素中 value 唯一且有序。
TreeSet 和 HashSet 相比,HashSet 中的数据无序存放,而 TreeSet 是有序存放。它们集合中的元素都不允许重复,但 HashSet 允许放入 null 值,TreeSet 不允许。
一般需要存储有序集合的场景,可以使用 TreeSet。
TreeSet 进行增、删、改、查操作的常用 API 如下:

LightWeightMap
LightWeightMap 可用来存储具有关联关系的 key-value 键值对集合,存储元素中 key 是唯一的,每个 key 会对应一个 value 值。LightWeightMap 依据泛型定义,采用更加轻量级的结构,底层标识唯一 key 通过 hash 实现,其冲突策略为线性探测法。集合中的 key 值的查找依赖于 hash 值以及二分查找算法,通过一个数组存储 hash 值,然后映射到其他数组中的 key 值以及 value 值,key 的类型满足 ECMA 标准中要求的类型。
初始默认容量大小为 8,每次扩容大小为原始容量的 2 倍。
LightWeightMap 和 HashMap 都是用来存储键值对的集合,LightWeightMap 占用内存更小。
当需要存取 key-value 键值对时,推荐使用占用内存更小的 LightWeightMap。
LightWeightMap 进行增、删、改、查操作的常用 API 如下:

LightWeightSet
LightWeightSet 可用来存储一系列值的集合,存储元素中 value 是唯一的。
LightWeightSet 依据泛型定义,采用更加轻量级的结构,初始默认容量大小为 8,每次扩容大小为原始容量的 2 倍。集合中的 value 值的查找依赖于 hash 以及二分查找算法,通过一个数组存储 hash 值,然后映射到其他数组中的 value 值,value 的类型满足 ECMA 标准中要求的类型。
LightWeightSet 底层标识唯一 value 基于 hash 实现,其冲突策略为线性探测法,查找策略基于二分查找法。
LightWeightSet 和 HashSet 都是用来存储键值的集合,LightWeightSet 的占用内存更小。
当需要存取某个集合或是对某个集合去重时,推荐使用占用内存更小的 LightWeightSet。
LightWeightSet 进行增、删、改、查操作的常用 API 如下:

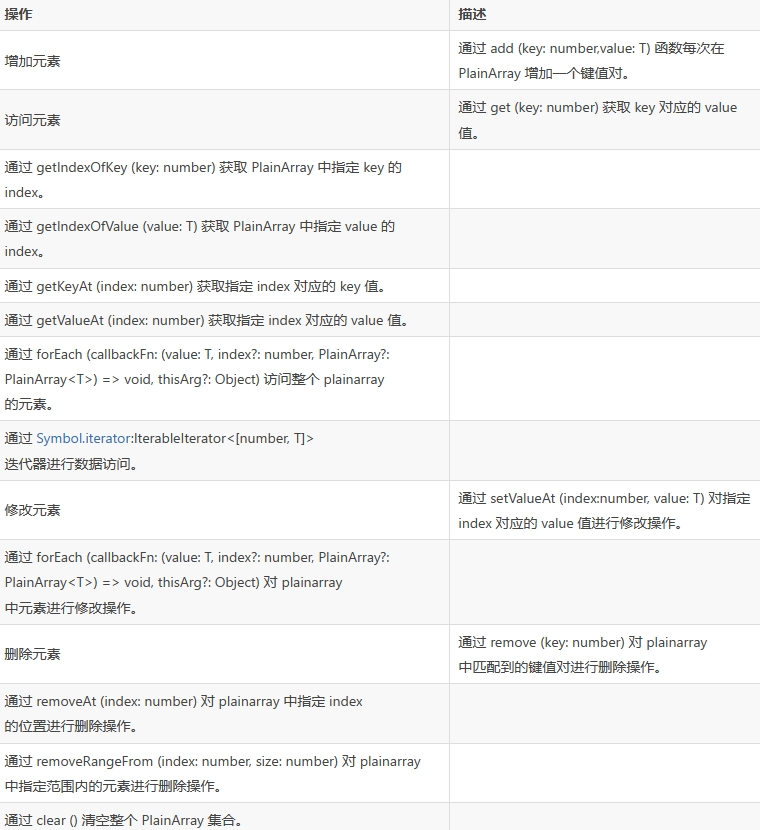
PlainArray
PlainArray 可用来存储具有关联关系的键值对集合,存储元素中 key 是唯一的,并且对于 PlainArray 来说,其 key 的类型为 number 类型。每个 key 会对应一个 value 值,类型依据泛型的定义,PlainArray 采用更加轻量级的结构,集合中的 key 值的查找依赖于二分查找算法,然后映射到其他数组中的 value 值。
初始默认容量大小为 16,每次扩容大小为原始容量的 2 倍。
PlainArray 和 LightWeightMap 都是用来存储键值对,且均采用轻量级结构,但 PlainArray 的 key 值类型只能为 number 类型。
当需要存储 key 值为 number 类型的键值对时,可以使用 PlainArray。
PlainArray 进行增、删、改、查操作的常用 API 如下:
非线性容器的使用
此处列举常用的非线性容器 HashMap、TreeMap、LightWeightMap、PlainArray 的使用示例,包括导入模块、增加元素、访问元素及修改等操作,示例代码如下所示:
// HashMap
import HashMap from '@ohos.util.HashMap'; // 导入HashMap模块
let hashMap = new HashMap();
hashMap.set('a', 123);
hashMap.set(4, 123); // 增加元素
console.info(`result: ${hashMap.hasKey(4)}`); // 判断是否含有某元素
console.info(`result: ${hashMap.get('a')}`); // 访问元素
// TreeMap
import TreeMap from '@ohos.util.TreeMap'; // 导入TreeMap模块
let treeMap = new TreeMap();
treeMap.set('a', 123);
treeMap.set('6', 356); // 增加元素
console.info(`result: ${treeMap.get('a')}`); // 访问元素
console.info(`result: ${treeMap.getFirstKey()}`); // 访问首元素
console.info(`result: ${treeMap.getLastKey()}`); // 访问尾元素
// LightWeightMap
import LightWeightMap from '@ohos.util.LightWeightMap'; // 导入LightWeightMap模块
let lightWeightMap = new LightWeightMap();
lightWeightMap.set('x', 123);
lightWeightMap.set('8', 356); // 增加元素
console.info(`result: ${lightWeightMap.get('a')}`); // 访问元素
console.info(`result: ${lightWeightMap.get('x')}`); // 访问元素
console.info(`result: ${lightWeightMap.getIndexOfKey('8')}`); // 访问元素
// PlainArray
import PlainArray from '@ohos.util.PlainArray' // 导入PlainArray模块
let plainArray = new PlainArray();
plainArray.add(1, 'sdd');
plainArray.add(2, 'sff'); // 增加元素
console.info(`result: ${plainArray.get(1)}`); // 访问元素
console.info(`result: ${plainArray.getKeyAt(1)}`); // 访问元素
那么要想成为一名鸿蒙高级开发,以上知识点是必须要掌握的,除此之外,还需要掌握一些鸿蒙应用开发相关的一些技术,需要我们共同去探索。
为了能够让大家跟上互联网时代的技术迭代,在这里我特邀了几位行业大佬整理出一份最新版的鸿蒙学习提升资料,有需要的小伙伴自行领取,限时开源,先到先得~~~~
领取以下高清学习路线原图请点击→《鸿蒙 (Harmony OS)开发学习手册》纯血鸿蒙HarmonyOS基础技能学习路线图
领取以上完整高清学习路线图,请点击→《鸿蒙基础入门学习指南》小编自己整理的部分学习资料(包含有高清视频、开发文档、电子书籍等)
以上分享的学习路线都适合哪些人跟着学习?
-应届生/计算机专业
通过学习鸿蒙新兴技术,入行互联网,未来高起点就业。
-0基础转行
提前布局新方向,抓住风口,自我提升,获得更多就业机会。
-技术提升/进阶跳槽
发展瓶颈期,提升职场竞争力,快速掌握鸿蒙技术,享受蓝海红利。
最后
鸿蒙开发学习是一个系统化的过程,从基础知识的学习到实战技能的锤炼,再到对前沿技术的探索,每一环节都至关重要。希望这份教程资料能帮助您快速入门并在鸿蒙开发之路上步步攀升,成就一番事业。让我们一起乘风破浪,拥抱鸿蒙生态的广阔未来!
如果你觉得这篇内容对你有帮助,我想麻烦大家动动小手给我:点赞,转发,有你们的 『点赞和评论』,才是我创造的动力。
关注我,同时可以期待后续文章ing,不定期分享原创知识。
想要获取更多完整鸿蒙最新VIP学习资料,请点击→《鸿蒙HarmonyOS分布式项目实战》













)





