(2024.03.05-2024.03.15)论文阅读简单记录和汇总
2024/03/05:随便简单写写,以后不会把太详细的记录在CSDN,有道的Markdown又感觉不好用。
目录
- (ICMM 2024)Quality Scalable Video Coding Based on Neural Representation
- (arxiv 2024) Immersive Video Compression using Implicit Neural Representations
- (ICMM 2024)Prior-Knowledge-Free Video Frame Interpolation with Bidirectional Regularized Implicit Neural Representations
- (ICLR 2024)PROGRESSIVE FOURIER NEURAL REPRESENTATION FOR SEQUENTIAL VIDEO COMPILATION
- (ICNC 2024)Implicit Neural Representation-based Hybrid Digital-Analog Image Delivery
- (arxiv 2024)NERV++: AN ENHANCED IMPLICIT NEURAL VIDEO REPRESENTATION
1. (MMM 2024)Quality Scalable Video Coding Based on Neural Representation 基于神经表示的质量可伸缩视频编码
1.1 摘要与贡献
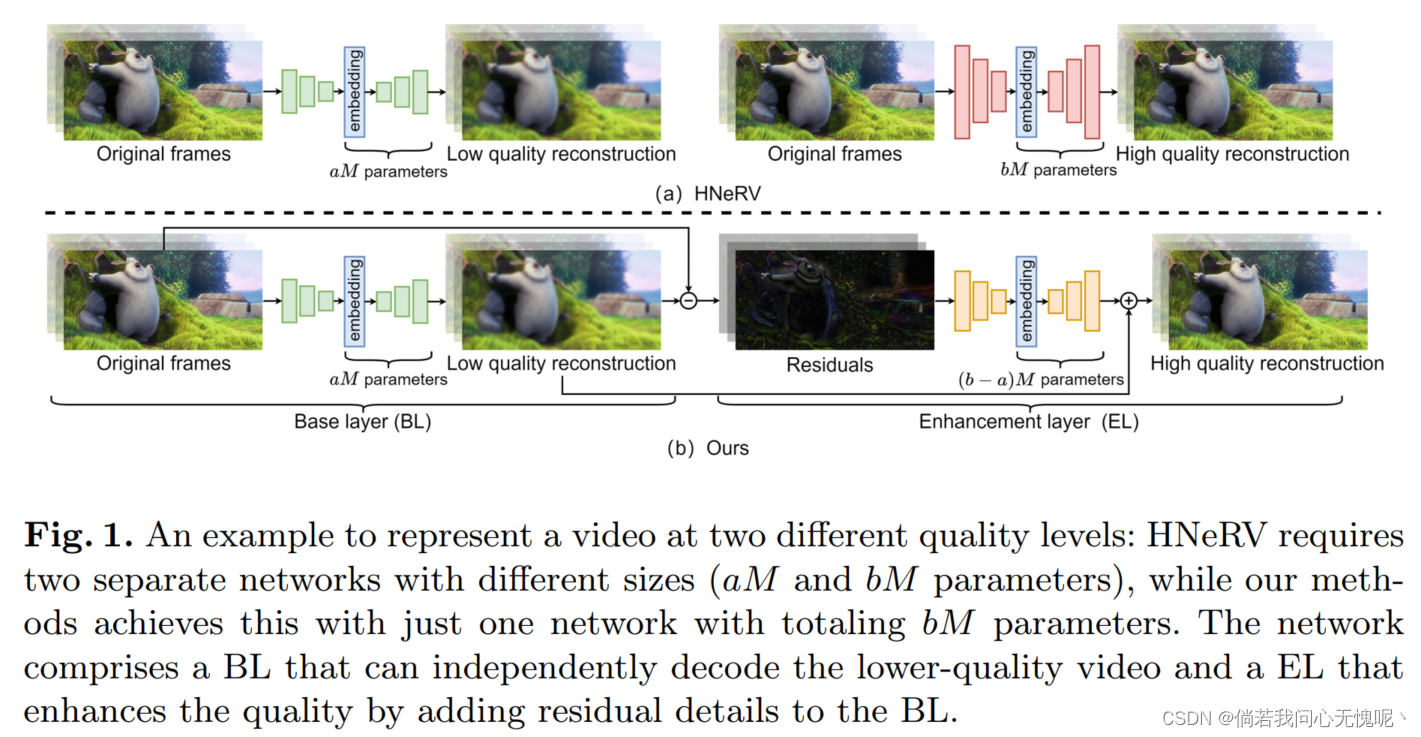
视频神经表示(NeRV)将每个视频 编码成一个网络,为视频压缩提供了一个有前途的解决方案。然而,现有的NeRV方法仅限于用固定大小的模型表示单质量视频。为了适应不同的质量 要求,NeRV方法需要多个不同大小的独立网络,从而导致额外的训练和存储成本。为了解决这个问题,我们提出了一种基于神经表示的质量可扩展视频编码方法,其中由一个基本层(base layer, BL)和几个增强层(enhancement layer, EL)组成的分层网络表示具有粗到细质量的相同视频。BL 是最小的子网,代表基本内容。通过逐渐加入捕获低质量重构帧与原始帧之间残差的增强层EL,可以形成更大的子网。由于较大的子网共享较小子网的参数,因此我们的方法节省了40%的存储空间。此外,我们的结构设计和训练策略使每个子网的平均PSNR优于基线+0.29。
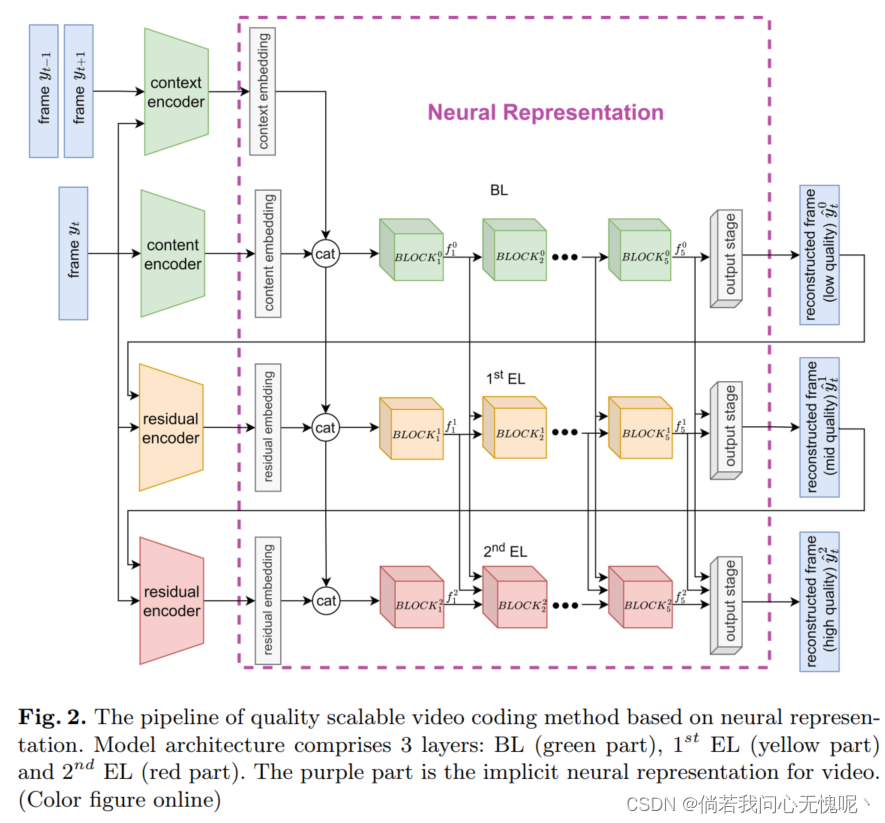
本文提出了一种基于 神经表示(QSVCNR)的高质量可扩展视频编码方法。在HNeRV[15]的基础上,我们设计了一个由基础层(BL)和一个或多个增强层(el)组成的分层网络。图1给出了一个例子。分层网络可以实现从粗到精的重建,并自然地将表示分解为基本组件和渐进的细节级别,分别保存在不同的层中。BL作为最小的子网,可以独立重建粗视频。通过逐步引入ELs 来拟合低质量重构帧与原始帧之间的残差,构建更大的子网。我们采用逐层监督对整个网络进行端到端的训练。主要贡献如下:
- 我们提出了一种基于神经表示的质量可扩展视频编码方法,其中由BL和多个el组成的层次网络以粗到细的质量表示相同的视频。
- 我们引入了额外的结构,包括用于BL的上下文编码器,用于el的残差编码器和层间连接,并设计了端到端训练策略,以提高我们方法的表示能力。
- 在bunny[19]和UVG[20]数据集上,我们提出的方法节省了40% 的存储空间,每个子网平均提高 +0.29与基线相比的PSNR。
1.2 总结
本文提出了一种基于神经表示的视频质量可扩展编码方法,其中一个BL和多个EL组成的分层网络同时表示具有不同质量的同一视频。无需重新训练多个单独的网络,这些层可以逐渐组合成 ,形成不同大小的子网。为了节省存储空间,较大的子网可以共享较小子网的参数。此外,上下文编码器通过利用时间冗余来提高性能,而剩余编码器和层间连接有效地增强了EL学习高频细节的能力。整个网络可以端到端进行训练,允许跨不同层的优化目标的动态平衡。结果显示,这些子网络优于同样大小的单独训练的网络。
它提出了一种基于神经表示的可伸缩质量视频编码方法(QSVCNR),使用单个分层网络同时表示同一视频的不同质量级别。较大的子网络可共享较小子网络的参数,从而节省了40%的存储空间。该方法还引入了诸如上下文编码器、残差编码器和层间连接等设计,提高了子网络的表示能力,使每个质量级别的重建性能均优于基线方法。端到端的多任务训练策略也有助于在不同子网络之间平衡目标。总的来说,QSVCNR在节省存储的同时,还提升了视频重建的码率-畸变性能。不足之处是,该方法目前只在较低的码率范围进行了评估,对于高码率场景的表现有待进一步研究。此外,分层网络设计增加了一定的复杂性,可能会影响编码和解码的效率。另外,该方法主要关注质量可伸缩性,对其他可伸缩性(如空间、时间等)的支持尚不明确。总的来说,这是一项有趣而有创新的工作,提出了一种新颖的基于神经表示的可伸缩视频编码方案,为未来的视频压缩研究提供了新的思路。
2. (arxiv 2024) Immersive Video Compression using Implicit Neural Representations 使用隐式神经表示的沉浸式视频压缩
2.1 摘要与贡献
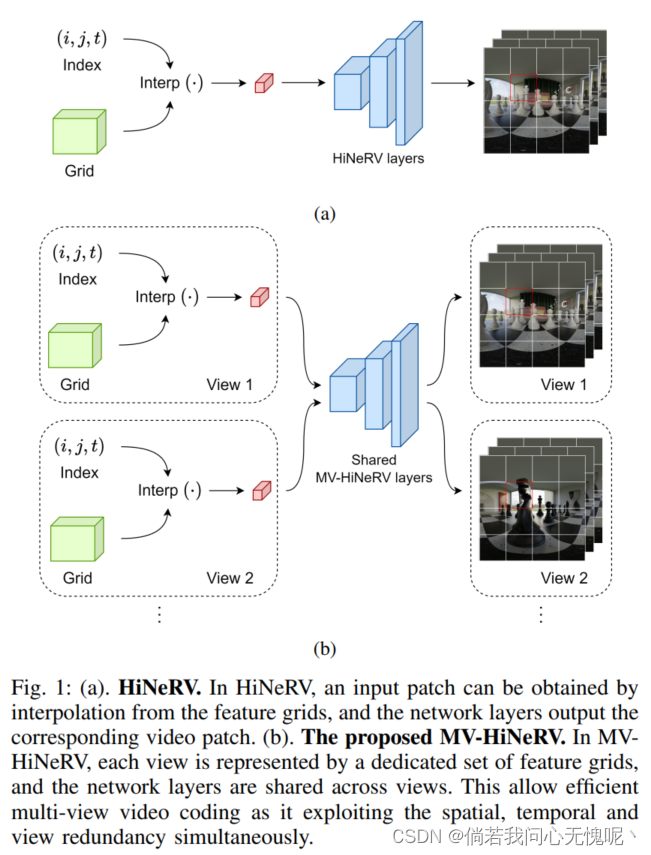
最近关于隐式神经表示 (INRs)的研究已经证明了它们在有效表示和编码传统视频内容方面的潜力。在本文中,我们通过提出MV-HiNeRV,一种新的基于INR的沉浸式视频编解码器, 首次将其应用扩展到沉浸式(多视图) 视频。MV-HiNeRV是最先进的基于inr的视频编解码器HiNeRV的增强版本,HiNeRV是为单视图视频压缩而开发的。我们修改了模型为每个视图学习一组不同的特征网格,并在所有视图之间共享学习到的网络参数。这使得模型能够有效地利用多视图视频中存在的时空和视图间冗余。提出的编解码器在MPEG沉浸式视频(MIV)通用测试 条件下对多视图纹理和深度视频 序列进行压缩,并针对 使用VVenC视频编解码器的MIV测试模型(TMIV)进行测试。结果表明,MV-HiNeRV具有优越的性能,与TMIV相比,其编码增益显著( 达到72.33%)。MV-HiNeRV的部署已公布,以供进一步发展和评估。
2.2 总结
在本文中,我们提出了一种基于inr的编解码器,MVHiNeRV,用于编码多视点视频。MV-HiNeRV是HiNeRV的 扩展,它是为单视图视频压缩而开发的。该方法为每个视图学习不同的特征网格集,并在所有视图中共享模型参数。有效地利用视角间冗余。MV-HiNeRV已针对 MPEG MIV测试模型(TMIV)进行了评估,并取得了显着的 性能改进,平均编码增益为46.92%。结果表明,基于inr的视频编解码器在沉浸式视频格式压缩方面具有巨大的潜力。未来的工作应该集中在更好地集成观看合成器与基于inr的沉浸式视频编解码器。
本文的主要方法和创新点包括:
- 针对多视点视频的特点,对HiNeRV进行了改进,为每个视点学习不同的特征网格(feature grids),但在不同视点之间共享网络参数。这种参数共享的方式可以有效利用不同视点间的冗余信息。
- 在编码器中同时压缩纹理信息和深度信息,最终输出RGB和depth四个通道。
- 采用学习量化和熵正则化的方法来减小模型尺寸,并用一个两阶段的训练流程来优化量化后的模型。
- 在MPEG沉浸视频(MIV)的通用测试条件下,将MV-HiNeRV与MIV测试模型(TMIV)进行了比较。结果显示MV-HiNeRV取得了显著的性能提升,平均比特率节省达到46.92%。
这项工作的主要贡献在于:
- 首次将INR模型应用于沉浸式多视点视频的压缩编码,通过巧妙的模型设计充分利用了INR的优势和多视点视频的特点。
- 提出的MV-HiNeRV在标准测试条件下取得了优于现有方法的性能表现,证明了用INR进行沉浸式视频压缩的有效性和巨大潜力。
- 相关代码已经开源,为将来在这一方向的进一步研究和实际应用提供了基础。
3. (ICMM 2024)Prior-Knowledge-Free Video Frame Interpolation with Bidirectional Regularized Implicit Neural Representations 具有双向正则化隐式神经表示的无先验知识视频帧插值
3.1 摘要与贡献
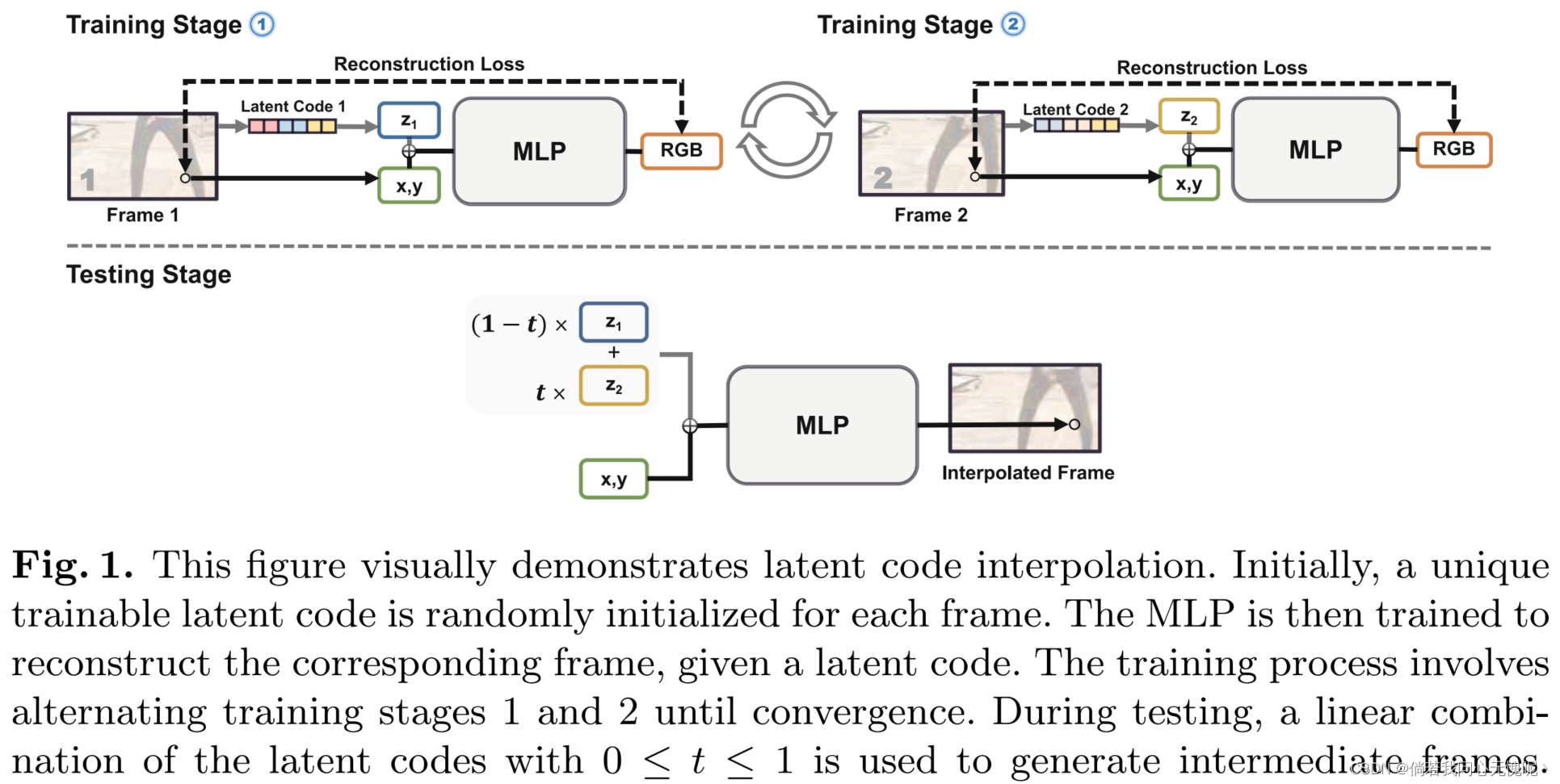
目前流行的基于深度学习的视频帧插值 (VFI)方法大多是预训练的,需要光流模型来获得先验知识。然而,预训练通常是耗时的,并且当应用于与训练域有很大不同的测试域时,可能会引入意想不到的伪影。另外, 隐式神经表征已经显示出无需预训练就能从稀疏图像合成新的视图的能力。在本文中,我们将 VFI视为新颖视图合成的特殊情况,并利用隐式神经表示来执行VFI,而无需预训练或光流模型。我们提出了双向正则化框架(BiRF),这是一种 新颖的VFI方法,它只需要两个输入帧就可以对每个场景进行训练,这与利用包含广泛先验知识的预训练权值的现有方法有本质区别。我们证明,即使不使用先验知识,我们的BiRF也可以生成 与流行的预训练模型相当甚至更好的内插帧。
- 我们提出了一种新的基于隐式神经表示的VFI方法BiRF,它可以在没有任何先验知识的情况下生成中间帧 。
- 我们表明,使用我们提出的双向正则化,inr可以在没有额外先验知识的情况下有效地正则化自己,从而大大 提高了插值质量。此外,BiRF采用了多mlp 架构,在不损失质量的情况下显著提高了训练速度。
- 我们证明,即使没有先验知识,我们的方法也可以产生与流行的预训练方法相当或更好的结果 。此外, 我们在定制数据集上提供了最先进的方法的比较,这些数据集由非自然图像和具有极端运动的微小图像组成。
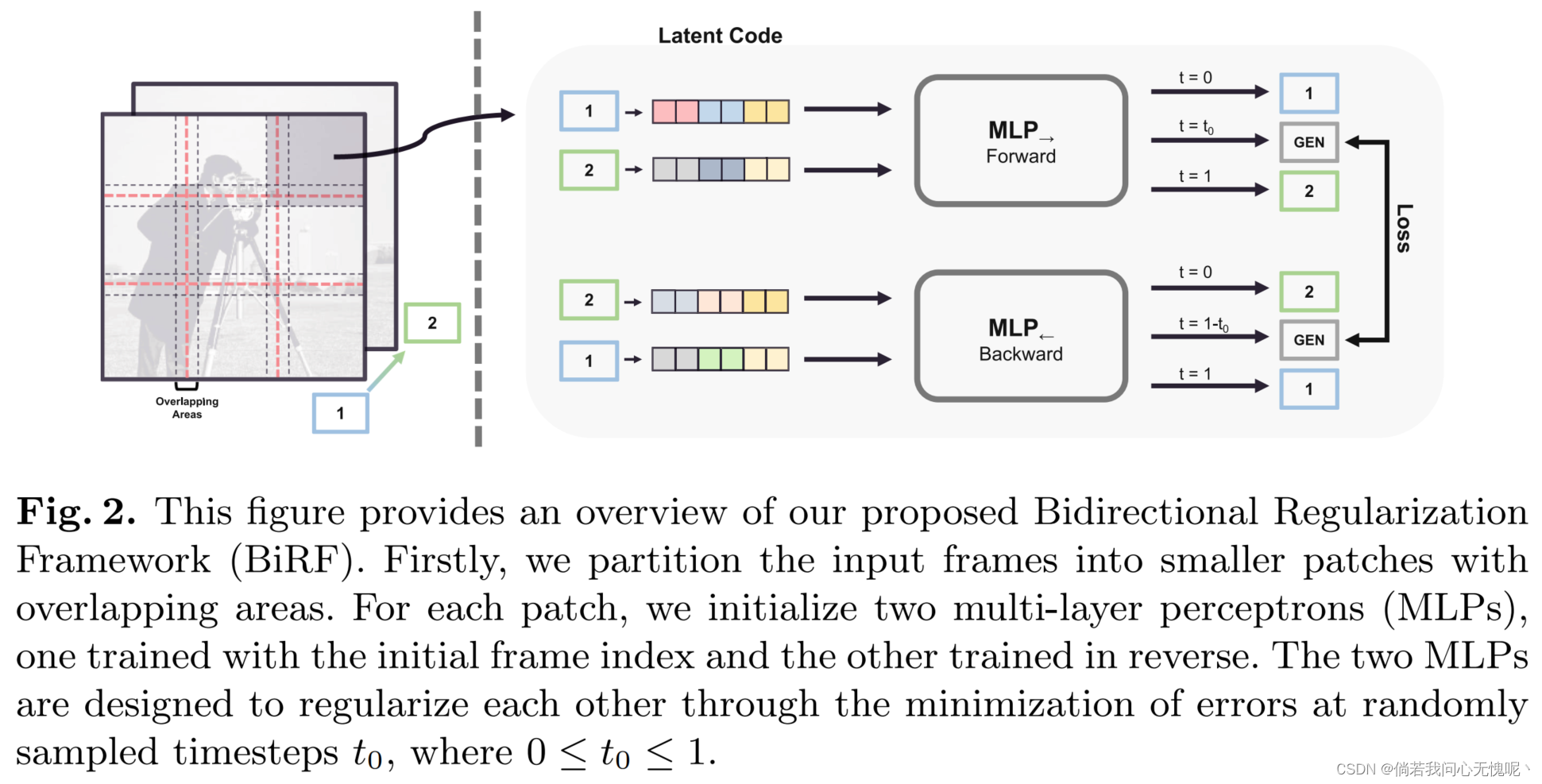
3.2 总结
在本文中,我们提出了双向正则化框架(BiRF),这是一种基于双向正则化隐式神经表示的新型视频帧插值(VFI)方法。通过使两个mlp相互调节 彼此,我们证明了在没有任何先验知识的情况下执行VFI 的可行性。此外,我们通过使用多mlp架构来加速训练。我们提出的方法是根据场景进行训练,不需要预训练或预训练模型。当处理与预训练数据显著不同的测试数据,以及数据访问受限时,此属性特别有利。我们的方法产生的结果与最先进的预训练VFI技术相当,甚至更好。在今后的工作中,我们将重点关注提高插补质量,进一步加快训练速度。虽然我们提出的方法还不适合实时或生产使用,但我们有信心,随着进一步的实施,基于inr的VFI方法将 成为一种实用而灵活的VFI替代方法。
这个双向正则化有点意思,没有仔细读这篇文章,但是感觉是为每两个参考帧之间进行插帧就得训练两个MLP,一个视频插帧下来不知道得训练多少个MLP。
4. (ICLR 2024)PROGRESSIVE FOURIER NEURAL REPRESENTATION FOR SEQUENTIAL VIDEO COMPILATION 渐进傅立叶神经表示用于顺序视频编译
Code:https://github.com/ihaeyong/PFNR.git
4.1 摘要与贡献
神经隐式表示(Neural Implicit Representation, NIR)由于其将复杂和高维数据编码到 表示空间并通过可训练的映射函数轻松地重建它的非凡能力,最近受到了极大的关注。然而,NIR方法假设目标数据和表示模型之间存在一对一的映射关系,而不考虑数据相关性或相似性。这导致对多个复杂数据的泛化较差,并限制了它们的效率和可扩展性。在持续学习的激励下,这项工作研究了如何在序列编码会话中积累和传递多个复杂视频数据的神经隐式表示。为了克服NIR的局限性,我们提出了一种新方法,即渐进傅立叶神经表示(PFNR),其目的是在傅立叶空间中找到一个自适应且紧凑的子模块来编码中的每个训练时段的视频。这种稀疏的神经编码允许神经网络保持自由权重,从而改进对未来视频的适应。此外,在学习新视频的表示时,PFNR将先前视频的表示与冻结的权重进行转移。这种设计允许模型为多个视频不断积累高质量的神经表示,同时确保无损解码,完美地保留先前视频的学习表示。我们在UVG8/17和DAVIS50视频序列基准上验证了我们的PFNR方法,并在强大的持续学习基线上获得了令人印象深刻的性能提升。
- 我们提出了一个实用的神经隐式表示学习场景,其中模型在连续的训练课程中连续编码多个视频。由于整体视频和帧的分布变化,早期的近红外方法对新视频的可转移性较差。
- 我们提出了一种尖端的方法,称为渐进傅里叶神经表示,用于复杂的顺序视频编译。该方法在给定一个超级网络主干网的情况下,为每个视频会话持续学习一个紧凑的子网络,同时在傅里叶空间中完美地保留了先前视频的生成质量。
- 我们证明了我们的方法在多个顺序视频会话上的有效性,在平均PSNR和MS-SSIM方面取得了优于传统基线的性能,而在顺序视频编译期间重建先前编码的视频时没有任何定量或定性的退化。
4.2 总结
神经隐式表示(NIR)由于能够表示复杂的高维数据,近年来得到了广泛的关注。与需要存储和操作单个数据点的显式表示不同,隐式表示通过学习的映射函数捕获信息,而无需显式表示数据点本身。虽然他们经常大幅压缩神经网络以加快编码/解码速度,但现有的方法无法将学习到的表示转移到新的视频中。这项工作研究了随着时间的推移,随着视频的顺序到达,隐式视频表示的持续扩展,其中模型只能访问当前会话的视频。为了解决这个问题,我们提出了一种新的神经视频表示,即渐进式傅立叶神经表示(PFNR),它基于复杂域的彩票假设,从超级网络到给定视频找到自适应子结构。在每次训练中,我们的PFNR在不修改过去的子网权重的情况下,转移之前获得的子网的学习知识来获得当前视频的表示。因此,它可以很好地保留先前视频的解码能力(即灾难性遗忘)。我们在新的UVG8/17和DAVIS50视频序列基准数据集上验证了我们提出的PFNR在基线上的有效性。
5. (ICNC 2024)Implicit Neural Representation-based Hybrid Digital-Analog Image Delivery 基于隐式神经表示的混合数模图像传输
5.1 摘要与贡献
隐式神经表示(INR)是一种新兴的用于表示RGB图像等小数据量多媒体信号的技术。INR的一个关键问题是在有限的数据量下RGB图像高频细节的准确性。许多机器学习的研究都讨论了激活函数和编码来提高准确性。为此,本文提出了一种新的面向通信的INR解决方案。为了向用户表示高频细节,该方案利用模拟传输原始图像和解码图像之间的剩余信号,这些信号来自训练后的INR。INR和模拟传输的集成为低流量用户提供了高频细节,并进一步提高了图像质量作为发射机与每个用户之间无线信道质量的函数。使用RGB图像数据集进行的评估表明,在相同的流量下,该方案比现有的基于inr的图像压缩和标准图像编解码器获得了更好的图像质量。
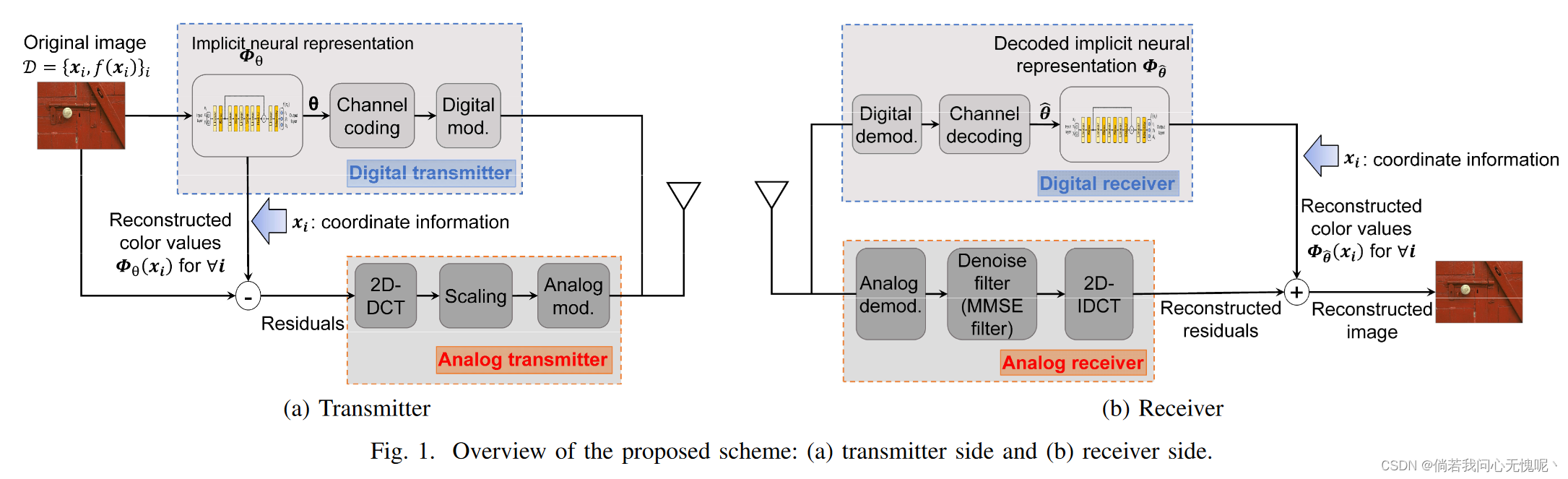
5.2 总结
尽管INR具有以低流量传输高质量RGB图像的潜力,但由于缺乏图像的高频表示,图像质量仍然受到限制。本文提出了一种基于inr的HDA传输方案,克服了基于inr的HDA传输方案的质量限制。除了以数字方式传输训练后的INR参数外,该方案还以模拟方式传输残差。从评价来看,在相同流量下,通过在模拟部分发送残差,与现有的基于inr的图像压缩相比,该方案获得了更好的图像质量。此外,该方案还可以根据发送端和接收端之间的无线信道质量来提高图像质量。
不明觉厉,感觉可以扩展到视频、音频上去
6. (arxiv 2024)NERV++: AN ENHANCED IMPLICIT NEURAL VIDEO REPRESENTATION NERV++:增强的隐式神经视频表示
6.1 摘要与贡献
神经域,也称为隐式神经表示(INRs),已经显示出表示、生成和操作各种数据类型的非凡能力,允许在低内存占用下进行连续的数据重建。尽管应用于视频压缩的inr很有前景,但仍需要大幅度提高其率失真性能,并且需要大量的参数和长时间的训练迭代来捕获高频细节,限制了其更广泛的适用性。解决这个问题仍然是一个相当具有挑战性的任务,这将使inr在压缩任务中更容易访问。我们通过引入视频神经表示(NeRV)++来解决这些缺点,这是一种增强的隐式神经视频表示,作为对原始NeRV解码器架构的更直接而有效的增强,具有可分离的conv2d残差块(SCRBs),它夹在上采样块(UB)之间,以及用于改进特征表示的双线性插值跳过层。 NeRV++允许将视频直接表示为神经网络近似的函数,并且大大提高了当前基于inr的视频编解码器的表示能力。我们在UVG, MCL JVC和Bunny数据集上评估了我们的方法,获得了与INRs具有竞争力的视频压缩结果。这一成果缩小了与基于自编码器的视频编码的差距,标志着基于inr的视频压缩研究迈出了重要的一步。
- 我们已经为神经视频表示开发了一种新颖的紧凑卷积架构,超越了最先进的基于inr的非混合视频编解码器的表示能力。图1举例说明了一个高级图表,以提供所建议框架的更全面的概述。
- 我们设计了nerv++解码器块,作为对原始NeRV解码器架构的更简单而有效的增强。我们的开发特点是可分离的conv2d残差块(SCRB),包含传统的NeRV上采样块(UB)。此外,我们还结合了双线性插值层来改进解码器块的特征表示能力。该设计代表了技术上的飞跃,为高级视频压缩提供了更有效的解决方案。
- 我们在视频压缩任务的关键基准数据集上进行了大量的实验。与以前的作品相比,nerv++展示了具有竞争力的定性和定量结果,并产生了高保真的时间连续重建。

6.2 总结
在本研究中,我们引入了NeRV++模型,这是NeRV框架的高级改进,旨在提高视频压缩效率。我们的创新在于开发了nerv++解码器块,该解码器块在传统NeRV上采样单元周围集成了SCRB,并辅以双线性插值层以改进特征精化。这种配置不仅增强了体系结构,而且显著提高了来自UVG、MCL JVC和Bunny数据集的12个视频的性能,使nerv++成为视频压缩技术领域的有力解决方案。虽然目前的研究结果令人鼓舞,但神经表示视频压缩中作为高效编码器的实际部署需要进一步研究更经济的熵建模技术来提高编码效率。
真给他闹麻了,看数据感觉一大堆问题(E-NeRV和PS-NeRV的性能明显优于NeRV)。看单位是法国的,文章前两个名字全是阿拉伯人,这就没那么意外了。这篇文章个人认为没有任何参考价值,写的稀碎并且严重怀疑其存在数据造假。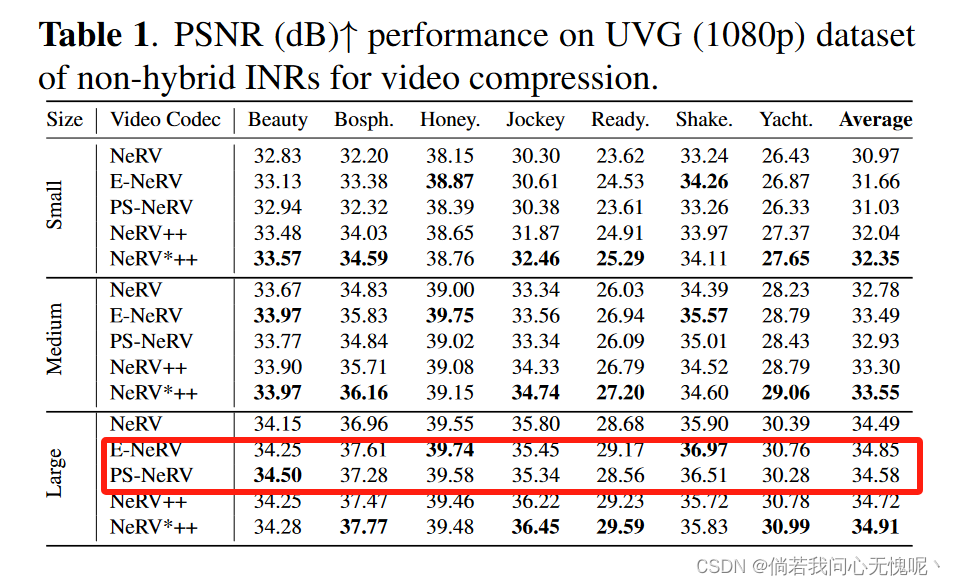

)


——神经元和梯度下降)

)

—— 初次接触)





)


)
)
