折腾了一整天,踩了GPU加速的一堆坑,记录一下。
1.GPU加速方式
上篇已经写了llama2部署的大概流程:【【个人开发】llama2部署实践(一)】——基于CPU部署
针对llama.cpp文件内容,仅需再make的时候带上参数编译,既可实现GPU加速。
make LLAMA_CUBLAS=1
备注:可用的版本组合:
cc (GCC) 9.3.1 20200408 (Red Hat 9.3.1-2)
g++ (GCC) 9.3.1 20200408 (Red Hat 9.3.1-2)
Build cuda_11.8.r11.8/compiler.31833905_0
2.踩坑分享
a.编译报错
more than one instance of overloaded function “log2” matches the argument list:
复现不出来了,大意:function.h文件中,math函数中log参数传递有误。
思考一下,应该就是c文件的问题,文件路径在cuda中,评估应该是cuda版本的问题。选择卸载原来cuda12.04的版本,下载11.8版本。
b.卸载CUDA:
一通无脑卸载
yum remove nvidia-*
rpm -qa|grep -i nvid|sort
yum remove kmod-nvidia-*rm -rf /usr/local/cuda-12.0
rm -rf /usr/local/cuda
c.下载CUDA11.8
其他三种下载方式都试了,最后用run这种方式搞出来的。
# 访问https://developer.nvidia.com/cuda-downloads
# 使用run文件方式
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sudo sh cuda_11.8.0_520.61.05_linux.run
# 参考链接:https://zhuanlan.zhihu.com/p/589442446
run在执行的时候可能会出现报错:
The NVIDIA proprietary driver is already installed in this system. It was installed through a 3d party repository
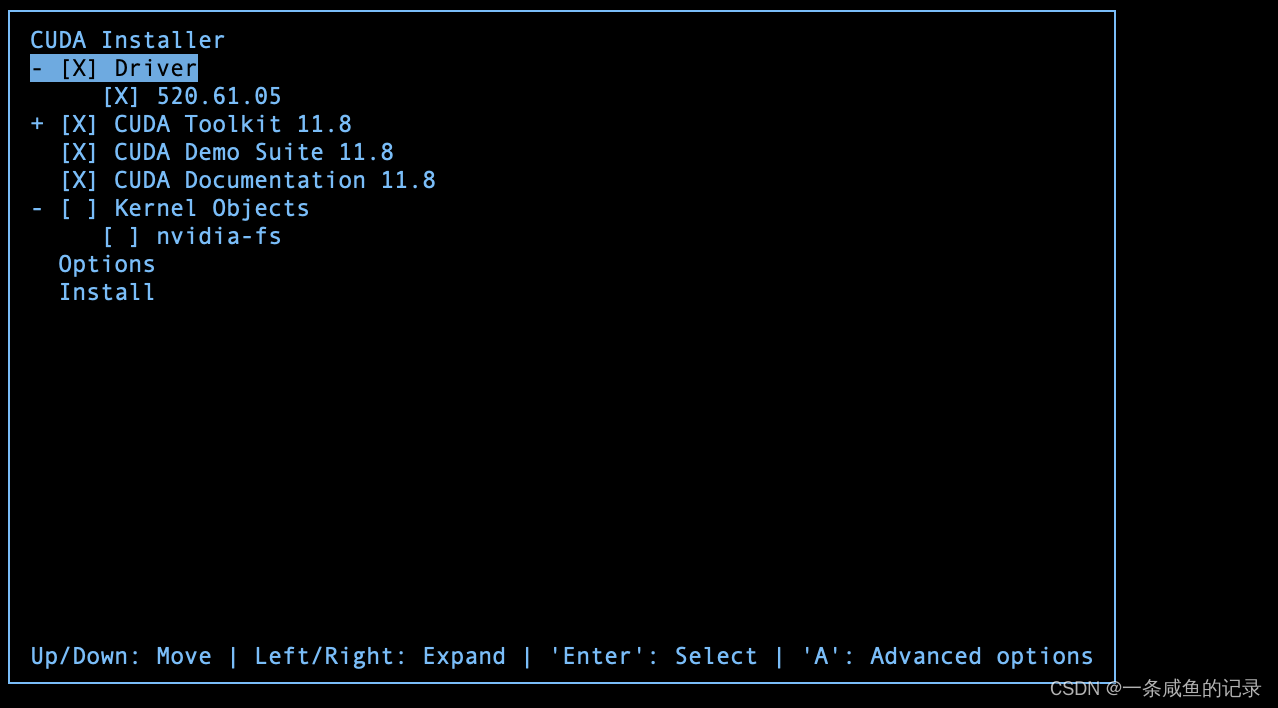
意思是驱动已经装上去了,不需要再装。所以选择页面取消Driver的勾选,即可。
注:如果服务器使用nvidia-smi能显示显卡出信息,则说明已经安全驱动,我这里将Toolkit理解为一个客户端工具
d.重新编译llama.cpp
如何重新编译后带上ngl参数去跑main程序,留意一下有没有下面的warning。
warning: not compiled with GPU offload support, --n-gpu-layers option will be ignored
warning: see main README.md for information on enabling GPU BLAS support
如果有那说明仍然没有使用GPU,建议重新拉llama.cpp代码进行编译。
make LLAMA_CUBLAS=1
e.重新启动
./main -m /data/opt/llama2_model/llama-2-7b-bin/ggml-model-f16.bin -n 256 --repeat_penalty 1.1 --color -i -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -ngl 15
f.查看进程
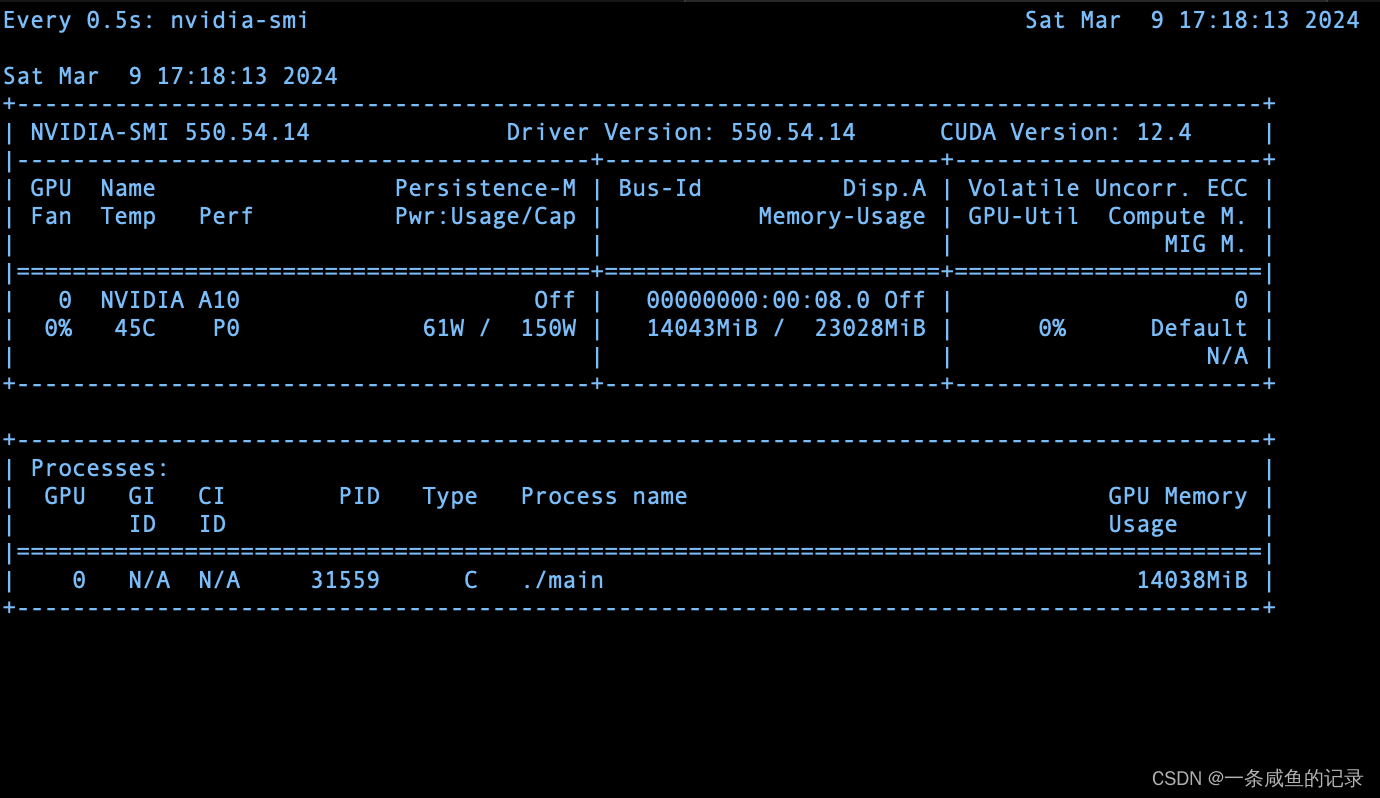
使用下面命令能监听到进程,如果processes存在进程,即可!
watch -n 0.5 nvidia-smi
以上,End!

)



》之概述篇 - 我为什么要翻译介绍美国人工智能科技公司IAB 系列(2))



——MP模型)

)

-动态提醒功能(RocketMQ))


类型趣谈-上)


