系列文章:
0、基本常用功能及其操作
1,20G文件,分类,放入不同文件,每个单独处理
2,数据的归类并处理
3,txt文件指定的数据处理并可视化作图
4,上万行log数据提取并作图进阶版
5、上万行数据提取并分类进阶版(本文)
一、需求
如果同时测试的数据和器件非常多,比如像芯片测试,同侧数量非常多的情况下,1,2,8,16,等等,我们想单独分析每个器件的数据怎么办呢,这时需要先分开,或者你直接打印对应的文件数量,但是那样有点小问题,不太优雅,所以我们有了这个需求
二、思路
1、文件操作,读取并每行识别
2、特定的字符的识别(正则表达式)
3、如何将对应的行,写出到新的数据
对相应操作不熟悉的同学,可以参考文章开头的系列文章: 0、基本常用功能及其操作
三、代码及其解释
用了正则表达式来提取并识别对应的字符或者数字
文件操作
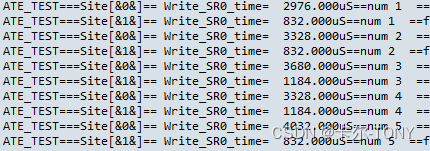
def site_select():import re# 定义一个函数,用于提取 Site[& 和 &]= 之间的数据def extract_data(line):match = re.search(r'Site\[&(.*?)&\]=(.*?)$', line)if match:site_name = match.group(1).strip()data = match.group(2).strip()return site_name, datareturn None, None# 读取输入文件input_file = "./log/SR0_00-P.txt"# 打开输入文件并逐行处理with open(input_file, 'r') as f:for line in f:site_name, data = extract_data(line)if site_name and data:output_file = f"./log/{site_name}_data.txt"with open(output_file, 'a') as site_file:site_file.write(line)print("数据已成功写入到对应的文件中。") 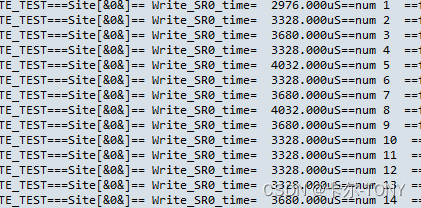
于是呢,我们就自动把每个SITE或者器件的log文件分开了
当然有待提高,可接着前一篇文章的内容作图,链接如下或者文章开头