我们发现网站并没有id、name等属性。那么,我们可以用更高级的定位方法——xpath来定位元素。
什么是xpath?
xpath是一种在XML文档中定位元素的语言。因为HTML可以看做XML的一种实现,所以selenium用户可以使用这种强大语言在web应用中定位元素,xpath是一种路径定位的方式。
xpath扩展了上面id和name等定位方式,提供了很多种可能性。
语法格式:find_element_by_xpath()
以下,我们介绍两种xpath定位方式:前端工具定位和手写xpath。
前端工具定位元素
1.打开Chrome浏览器开发者模式,然后定位到百度搜索框。
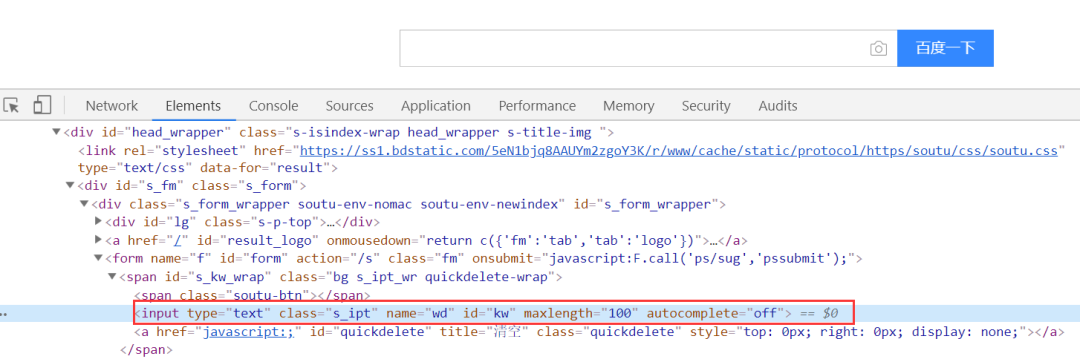
2.定位到元素后,鼠标移至标签元素,右键后选择copy,最后选择Copy XPath,就复制了xpath路径了。
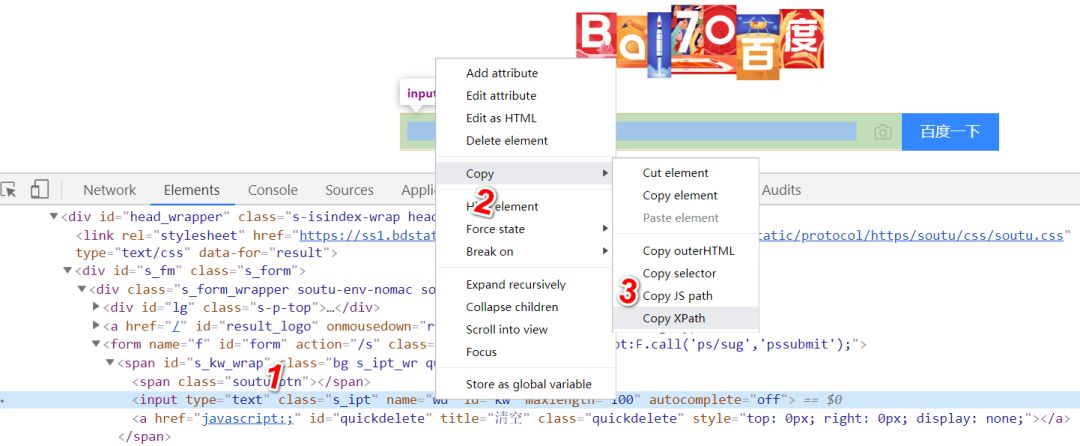
3.复制xpath后,就可以用xpath定位百度搜索框了。
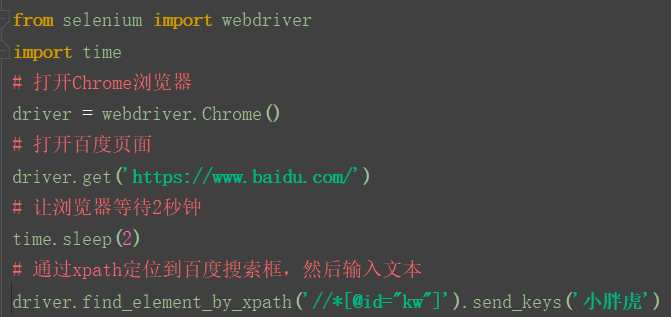
运行之后,百度搜索框输入了小胖虎,用xpath定位成功。
手写xpath定位元素
以下介绍怎么手写xpath。
xpath 使用路径表达式在 XML 文档中选取节点。节点是沿着路径或者 step 来选取的,下面列出了最有用的路径表达式:
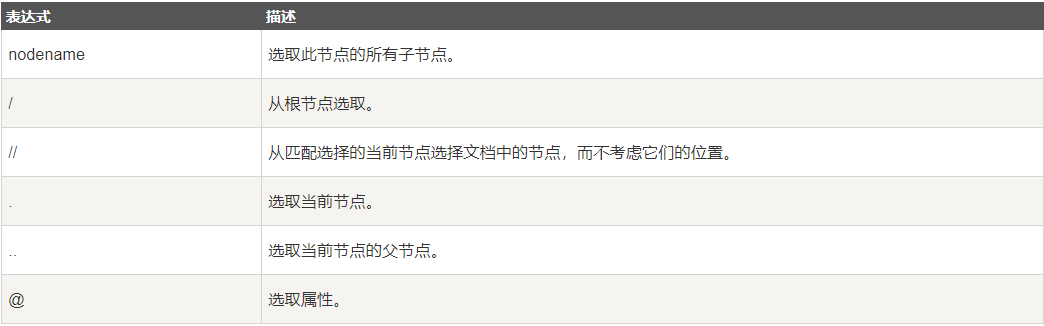
xpath绝对路径:
以百度搜索框为例,绝对路径如下所示。
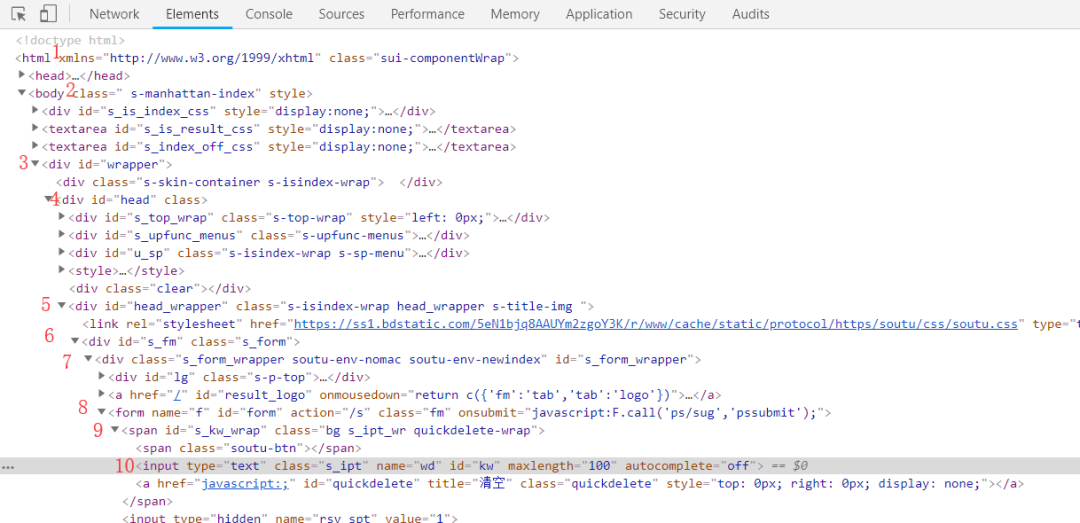
那么我们可以这样写:
find_element_by_xpath("/html/body/div/div/div/div/div/from/span/input")

运行之后,打开百度页面,输入小胖虎,xpath绝对路径定位成功。
但是绝对路径定位,只要页面元素稍微改动,就会定位失败,维护成本比较高,所以并不建议使用xpath绝对定位的方式。
xpath相对定位:
1.利用属性定位
通过元素的属性定位,比如id、name、class等属性,属性匹配定位语法:“//标签名[@属性='属性值'] ",
//表示当前节点, @表示选取属性 ,标签名比如div, span等,也可用 * 表示任意标签。
以百度搜索框为例:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">我们用id属性,xpath定位代码如下:

其他属性如name、class等,也是相同的定位写法。
2.利用层级加属性定位
比如找不到小胖虎,可以通过先找到小胖虎的爸爸,然后找到小胖虎。
以百度搜索框为例, 我们可以找到搜索框input标签的上级标签span, 上上级标签form:

我们通过上级标签span,及上上级标签form分别进行定位:

运行之后,发现通过上级标签span并不能定位到搜索框,而通过上上级标签form可以定位到,所以实战要灵活运用,直到定位到元素。
3.利用逻辑运算符定位
逻辑运算符比如and ,or ,not ,多种条件组合定位。
用百度搜索框为例,使用id加name两种属性组合定位。
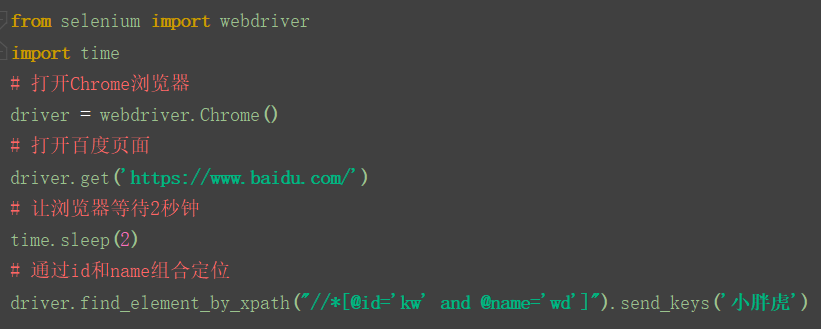
运行之后,打开百度,输入小胖虎,id加name属性组合定位成功。
总结:节点元素无id或name属性时,可以用xpath。觉得麻烦的话可以用开发者工具直接copy,copy的xpath定位不到的,再手写xpath。xpath是定位神器,多练习, 可以解决绝大部分定位问题。
感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!有需要的小伙伴可以点击下方小卡片领取








![[数据结构初阶]队列](http://pic.xiahunao.cn/[数据结构初阶]队列)


 超时时间)




)
)


)