主要介绍SpeechPrompt、SpeechPrompt V2、SpeechGen
SpeechPrompt
模型结构和原理(语音到符号)
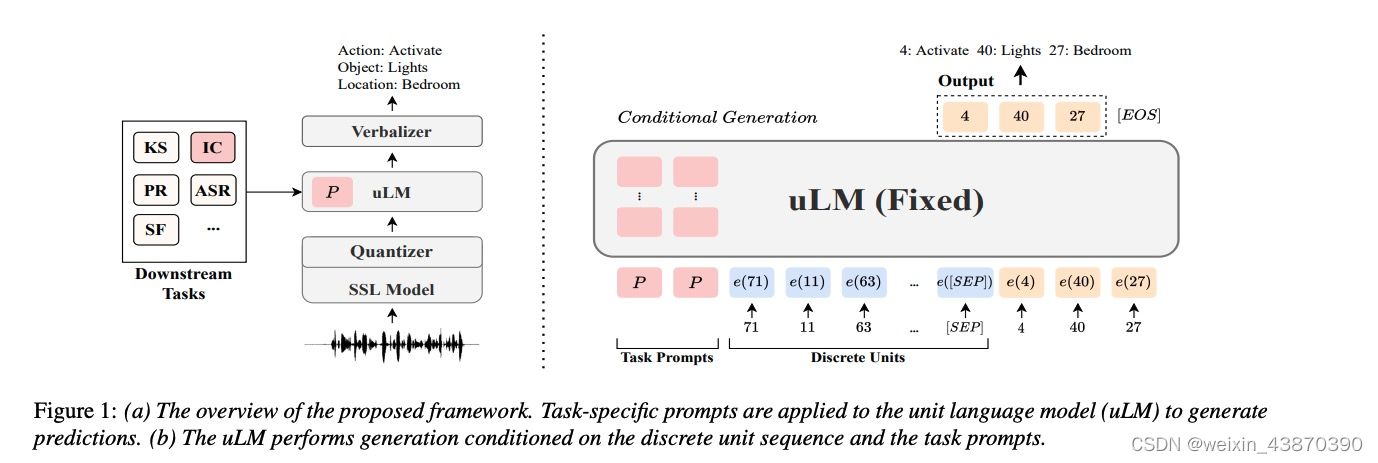
- 整体思路:音频特征提取(HuBert/CPC),离散–》deep prompt + speechLM(GSLM)—》概率映射–>目标
- Verbalizer选择根据概率统计,优于随机
- deep prompt优于input prompt
- 参数量:uLM 参数量为151M;prompt参数和长度有关系,分类任务长度较短,参数少,生成任务长度长,参数量大,例如l=180时,参数为4.5M
- 音频特征提取:HuBert效果好于CPC
适合任务
适合任务:语音分类任务,序列生成任务均可,但不能生成音频(效果不太好)。比如关键词识别,意图分类,ASR,槽位填充。但实际上,针对ASR、SF效果并不好,原因是GSLM有限,不适合这种输出长度很长的任务,语音分类任务又些效果还可以。
SpeechPrompt V2
模型结构和原理(语音到符号)
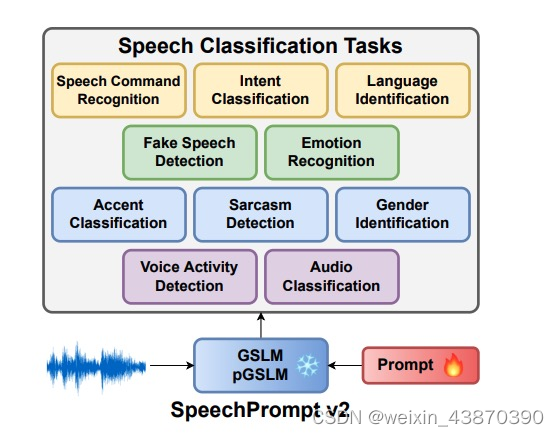
- 整体思路:音频特征提取(HuBert),离散–》deep prompt + speechLM(GSLM/pGSLM)—》线性映射–>目标 SpeechPrompt
- V2的加强版,主要改进有两点。第一:speech LM可以选择GSLM和它的升级版pGSLM,多了韵律信息;第二:概率映射改为了线性学习映射。另外呢,这篇文章主要关注分类任务,多了更多的分类任务的数据、训练和试验。
- 参数量:uLM 参数量为151M;prompt参数和长度有关系,分类任务长度较短,参数少,例如l=5时,参数为0.128M
适合任务
适合任务:语音分类任务。比如语音命令词识别、意图分类、语言识别、机器人声识别、情感识别、口音识别、讽刺识别、性别识别、VAD。但并不是在所有任务上,提出的模型效果就好,在有些任务上比传统的finetune的好,有些持平,有些不如传统模型效果。
SpeechGen
模型结构和原理(语音到语音)
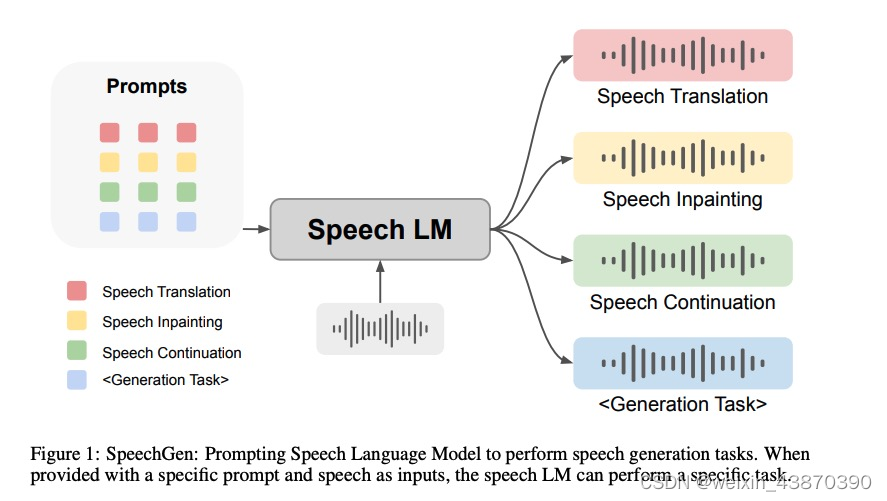
- 整体思路:音频特征提取(HuBert),离散–》deep prompt + speechLM(mBART)–>vocoder解码–〉语音
- mBART是encoder-decoder结构的,在使用prompt时encoder和decoder都添加;
- 训练参数只有prompt的参数
- 参数量:prompt参数l=200时,参数为10M
适合任务
适合任务:语音生成任务。比如语音翻译、语音修复、语音预测等。效果可能受限于speech LM。期待有更好的Speech LM,框架同样适用,效果会更好。现在这种离散化的方式对语音信息有损失。


















)
