引言:电商推荐系统的新突破
随着电子商务平台的蓬勃发展,推荐系统已成为帮助用户在信息过载时代中筛选和发现产品的关键工具。然而,传统的推荐系统主要依赖历史数据和用户反馈,这限制了它们在新商品推出和用户意图转变时的有效性。为了克服这些挑战,研究人员和工程师们一直在探索新的方法来增强推荐系统的性能和适应性。
最近,一项新的研究提出了一种结合了大语言模型(Large Language Models, LLMs)和推荐系统的方法,这一方法通过构建一个推理知识图谱(Inferential Knowledge Graph),使得推荐系统能够更好地理解和预测用户的购买意图。
这项研究的核心在于一个名为LLM-KERec(Large Language Model based Complementary Knowledge Enhanced Recommendation System)的系统,它通过实体提取器从商品和用户信息中提取统一的概念术语,并生成基于实体流行度和特定策略的实体对。大语言模型用于确定每对实体间的互补关系,并构建互补知识图谱。此外,新的互补回忆模块和实体-实体-商品(Entity-Entity-Item, E-E-I)权重决策模型通过使用真实的互补曝光-点击样本来细化排名模型的评分。
通过在三个行业数据集上进行广泛的实验,结果表明LLM-KERec在性能上显著优于现有方法。此外,详细分析显示,LLM-KERec通过推荐互补商品来增强用户的消费热情。总而言之,LLM-KERec通过整合互补知识并利用大语言模型来捕捉用户意图转变、适应新商品,并在不断演变的电商环境中提高推荐效率,从而克服了传统推荐系统的局限性。
论文标题:
Breaking the Barrier: Utilizing Large Language Models for Industrial Recommendation Systems through an Inferential Knowledge Graph
论文链接:
https://arxiv.org/pdf/2402.13750.pdf
LLM-KERec系统:大语言模型与推荐系统的结合
1. 传统推荐系统的局限性
传统推荐系统在电子商务网站和在线平台广泛应用,以解决信息过载问题。它们的主要目标是从用户过去的行为中推断出用户偏好,推荐与用户兴趣相符的最合适的商品。然而,这些系统主要依赖历史数据和用户反馈,这使得它们难以捕捉用户意图的转变。尤其是在新商品不断涌现的情况下,传统系统在冷启动场景中的表现受限,难以适应不断变化的电子商务环境。此外,用户交互样本的稀疏性导致现有的点击率预测模型在推荐替代品(即用户已经点击或购买的商品)方面比推荐互补商品(即与用户购买的商品相辅相成的商品)更有效。
2. LLM-KERec系统的创新构想
为了解决上述挑战,提出了一种新颖的基于大语言模型的互补知识增强推荐系统(LLM-KERec)。该系统结合了传统模型的高效协同信号处理能力与大语言模型和互补图,帮助用户快速找到他们偏好的商品。这种方法不仅减少了传统模型推荐结果的同质性,还提高了整体点击率和转化率。LLM-KERec通过实体提取器从所有商品和用户账单信息中提取统一的概念术语(称为实体),然后基于实体的流行度和精心设计的策略生成实体对。大语言模型确定每对实体间的互补关系,并构建互补知识图。此外,新的互补召回模块和实体-实体-商品(E-E-I)权重决策模型通过真实的互补曝光-点击样本来优化排名模型的评分,以实现互补商品的推荐。
3. LLM-KERec系统的整体框架
LLM-KERec系统的架构包括两个主要部分:传统推荐模块和基于LLM的补充知识增强模块(下图)。

传统推荐模块:在传统推荐架构中,当用户打开应用程序时,系统会自动发送请求到服务器。服务器触发召回模块,返回大量候选商品,然后通过粗排模型进行筛选,最终通过精排模型和重排模型决定商品的展示顺序。这些模型通常使用历史曝光和点击日志进行训练,因此,现有推荐模型往往倾向于推荐基于用户正面反馈的相似商品。
基于LLM的补充知识增强:LLM-KERec系统创建了一个统一的实体(类别)系统,用于用户账单行为和所有商品之间的连接。每个商品或账单都被分类到一个独特的实体中,这些实体作为各种内容之间的桥梁。利用世界知识和常识知识,系统采用大语言模型来确定两个实体之间是否存在补充关系,并构建补充知识图谱。然后,使用真实的曝光和点击反馈训练实体-实体-商品(E-E-I)权重决策模型,将知识注入排名模型中,以提供个性化的推荐。
实体提取器的设计与作用
1. 实体字典的构建
在现实世界的应用中,如支付宝,用户的行为跨越多种场景,每个场景都有不同的内容。为了将这些多样化的信息和知识统一起来,建立了一个统一的关联模式,即实体字典。在实体字典中,每个实体代表一个特定的概念,如“手机”或“可乐”。由专家小组精心设计的实体字典包含了数以万计的实体,并且每周定期更新,以适应新商品和内容的变化。
2. 从用户行为中提取实体
基于实体字典,我们的工作重点转移到了从支付宝中的各种用户行为中提取实体,包括账单、访问日志以及营销场景中商品的实体信息。这个提取过程可以看作是一个命名实体识别(NER)任务,该任务在自然语言处理(NLP)领域已经被广泛研究。为了执行实体提取,我们使用了BERT-CRF模型,该模型结合了BERT的迁移能力和CRF的结构化预测。BERT-CRF模型使我们能够准确地从支付宝中的用户行为中提取实体(下图)。在基于大语言模型的互补知识增强中,我们的主要目标是建立用户购买行为与推荐商品之间的联系。为此,我们从每个用户最近的账单中提取实体,形成他们最近的实体交易序列。此外,我们还从商品信息中提取实体,并为每个商品分配一个独特的实体作为其类别。

构建互补知识图谱
1. 实体对的生成策略
在构建互补知识图谱的过程中,首先需要生成实体对。实体对的生成策略是基于实体的流行度和特定策略来确定的。这些策略包括对实体进行排序,将它们分为极其流行、流行和不流行的类别,并专注于流行实体之间的配对。此外,也会构建包含极其流行和不流行实体的配对,以确保图谱对不流行项的全面覆盖。通过这种分段组合策略,可以在保证下游模块的可靠支持的同时,最小化资源浪费。
此外,在实际场景中,经常会出现少数实体经常被购买,而大多数实体很少被消费的长尾分布(下图)。如果只关注尾部实体组合,就很难提高推荐系统的整体性能。
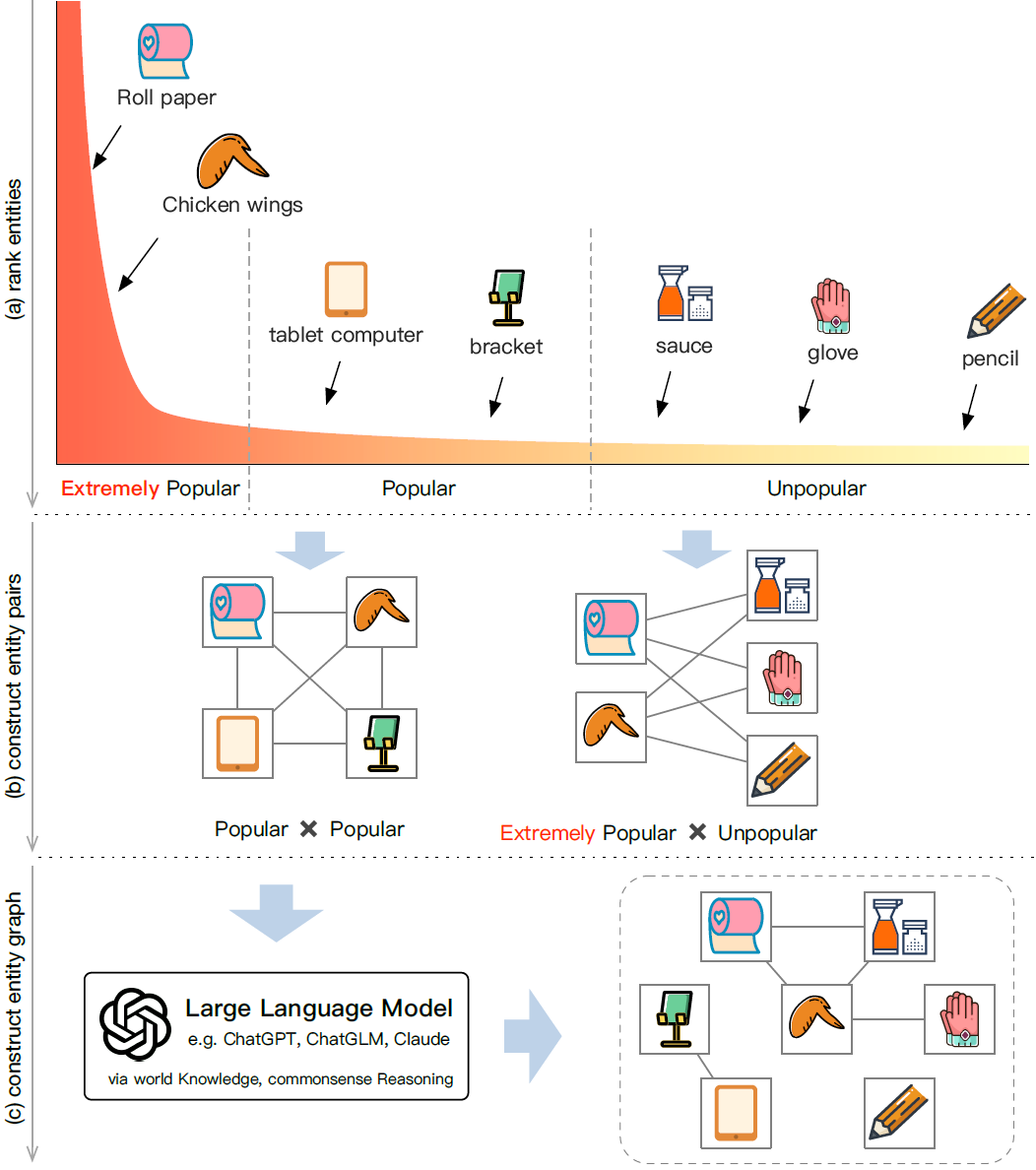
2. 大语言模型在知识图谱中的应用
大语言模型(LLM)因其在自然语言处理中的出色理解和推理能力而受到研究者的关注。在本研究中,我们利用大语言模型来确定实体对中是否存在互补关系。我们使用Claude 21作为底层语言模型,并精心设计了可靠的提示(prompts)来引导模型进行逐步分析,并提供可靠的推理证据。通过这种方式,我们可以增强推理结果的可解释性,并通过手动注释样本来不断完善提示,以达到推理结果的可接受准确度。
E-E-I权重决策模型
E-E-I权重决策模型是一个两阶段的互补知识增强过程(下图),包括排名阶段(Ranking Stage)和整合阶段(Integration Stage)。

1. 排名阶段
在E-E-I权重决策模型中,我们采用了双塔架构,其中两个塔的输出分别代表互补项和账单实体的表示。这两个输出的点积作为偏好级别指标。对于项的表示,我们可以从数据库中提取丰富的特征集,包括基本特征、统计特征和交互特征等。然而,对于实体的表示,由于缺乏具体信息来描述它们,除了预先分配的ID之外,需要使用图神经网络(GNN)和对比学习来从两个不同的视角——第一顺序可替代视角和第二顺序互补视角——来代表实体。
2. 整合阶段
整合阶段中,召回模块通过新增互补召回路径来优化推荐,确保不过量召回商品,并基于E-E-I模型分数和用户最近购买记录,选出最多k个互补商品。在训练精细排名模型时,E-E-I模型提供分数和嵌入信息,帮助模型更精确地评估商品。这解决了曝光偏差问题,使排名模型能更全面地考虑互补商品,结合用户行为进行个性化推荐,提高了点击率和转化率。
三个工业数据集的测试结果
1. 离线性能比较

在三个工业数据集(上图)上进行的离线实验结果表明(下表),LLM-KERec在点击和转化的AUC值上均优于其他基线方法。例如,在数据集A上,LLM-KERec在点击AUC上达到了0.67284,而在转化AUC上达到了0.82507,这些结果都显著优于其他基线方法。这些数据集包括了不同的用户群体分布、用户意图和行为,从而为系统的性能提供了全面的评估。

2. 在线A/B测试性能
在线A/B测试结果显示,LLM-KERec在真实的工业应用场景中取得了显著的性能提升。在Super 567、消费者频道和支付结果页面的三个推荐场景中,LLM-KERec分别实现了6.24%、6.45%和10.07%的转化率提升。这些结果证明了LLM-KERec在实际工业推荐场景中的有效性。
通过这些实验,我们验证了LLM-KERec系统在处理互补商品推荐时的有效性,并展示了其在不同场景下的性能优势。
不同大语言模型的比较
1. ChatGPT、ChatGLM和Claude的性能对比
在构建互补图时,大语言模型的选择对于确定实体对之间的互补关系至关重要。我们对ChatGPT、ChatGLM和Claude三种模型进行了比较。基于手动评估的1000个互补实体对样本,Claude模型在相关性评分上优于其他两种模型,显示出更高的相关性水平。这表明Claude模型在理解和推理自然语言处理方面的能力更强,能够更准确地识别实体对之间的互补关系。
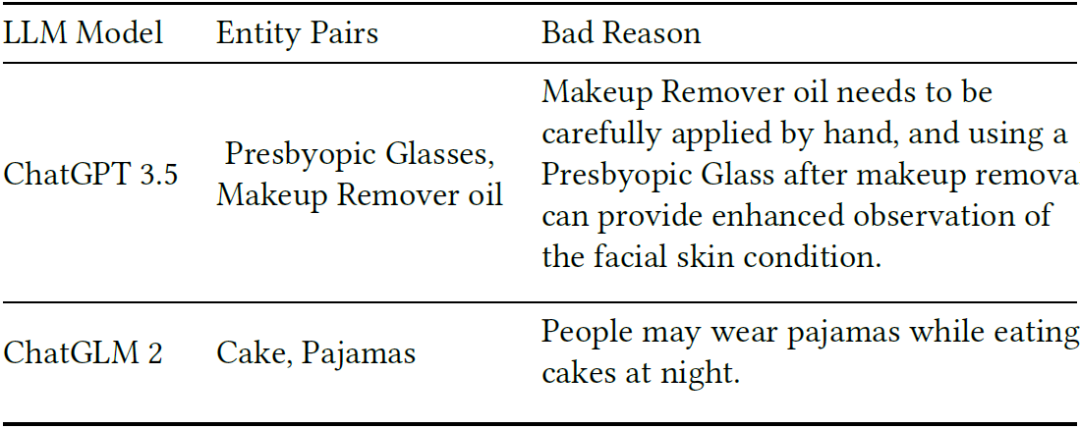
2. 模型误判:大语言模型需更精细的调整
在实际应用中,即使是性能最佳的模型也会出现误判。例如,ChatGPT将“老花镜”与“卸妆油”联系起来,认为使用老花镜可以在卸妆后更好地观察面部皮肤状况(下表)。而ChatGLM则将“蛋糕”与“睡衣”联系起来,认为人们可能在晚上穿着睡衣吃蛋糕。这些解释过于富有想象力,强行建立了实体对之间的联系,实际上这些实体对并不具有互补关系。这些错误案例表明,即使是大语言模型也需要更精细的调整和优化,以便更准确地捕捉和推理用户的购买行为和意图。
案例:LLM-KERec系统具有更高的互补实体对转化率
我们计算并比较了LLM-KERec和基线模型推荐的一组互补实体对的转化率(CVR)。比较结果在下图中展示。在图中,空白方块表示两个实体词之间没有关联关系,而彩色方块表示实验组的CVR相对于基线组有所提高。红色方块代表实验组的CVR高于基线组,而蓝色方块则表示实验组的CVR低于基线组。从图中可以观察到,实验组推荐的互补对通常比基线组推荐的具有更高的CVR。
总结:LLM-KERec系统的贡献与未来展望
1. LLM-KERec系统的贡献
LLM-KERec系统是一种创新的推荐系统,它通过结合大语言模型(LLM)和互补知识图谱,有效地解决了传统推荐系统在适应新商品和捕捉用户意图转变方面的局限性。通过在三个行业数据集上的广泛实验表明,LLM-KERec系统在性能上显著优于现有方法。该系统的核心贡献包括:
-
实体提取器的设计:通过设计实体提取器,LLM-KERec系统能够从商品和用户账单信息中提取统一的概念术语(实体),为构建知识图谱打下基础。
-
互补知识图谱的构建:利用大语言模型判定实体对之间的互补关系,并构建互补知识图谱。这一图谱不仅反映了用户的购买模式,还能够根据实时反馈调整图边权重,从而提升推荐的个性化和准确性。
-
E-E-I权重决策模型:通过实体-实体-商品(E-E-I)权重决策模型,LLM-KERec系统能够根据用户的最近账单和商品信息推荐互补商品,进一步优化了排名模型的得分。
2. 未来展望
LLM-KERec系统的成功部署在推荐系统领域开辟了新的道路,但仍有进一步的发展空间。未来的研究和开发可以集中在以下几个方面:
-
实体提取器和知识图谱的持续优化:随着电子商务环境的不断演变,新商品的不断涌现,实体提取器和知识图谱需要定期更新以适应变化,保持推荐系统的时效性和准确性。
-
大语言模型的进一步探索:当前研究已经比较了不同的大语言模型(如ChatGPT、ChatGLM和Claude)在构建互补知识图谱中的表现。未来可以进一步探索如何更有效地利用这些模型的推理能力,以及如何将它们与推荐系统更紧密地结合。
-
个性化和上下文感知的增强:通过深入理解用户行为和上下文信息,推荐系统可以更准确地预测用户的需求,提供更加个性化的推荐。
-
系统的可扩展性和效率:随着数据量的增长和用户需求的多样化,推荐系统需要在保证推荐质量的同时,提高处理大规模数据的能力。
-
用户隐私和数据安全:在提升推荐系统性能的同时,保护用户隐私和数据安全是至关重要的。未来的研究需要在遵守数据保护法规的前提下,探索更安全的数据处理和推荐方法。
总之,LLM-KERec系统的提出为推荐系统领域带来了新的视角和方法,其未来的发展有望进一步推动个性化推荐的边界,为用户提供更加丰富和精准的购物体验。




)








函数的基本使用)
)





![BUUCTF---[极客大挑战 2019]Http1](http://pic.xiahunao.cn/BUUCTF---[极客大挑战 2019]Http1)
)
