需求分析
需要对数据集进行预处理,选择合适的特征进行聚类分析,确定聚类的数量和初始中心点,调用Mahout提供的K-Means算法进行聚类计算,评估聚类结果的准确性和稳定性。同时,需要对Mahout的使用和参数调优进行深入学习和实践,以保证聚类结果的有效性和可靠性。
系统实现
1.对实验整体的理解:
本次实验,我们的目的是理解聚类的原理,并且掌握常见聚类的算法,以及掌握使用Mahout实现K-Means聚类分析算法的过程。
2.实验整体流程分析:
- 创建项目,导入开发依赖包
- 编写工具类
- 编写聚类分析的代码
- 将聚类结果输出
- 评估聚类的效果
3.准备工作:
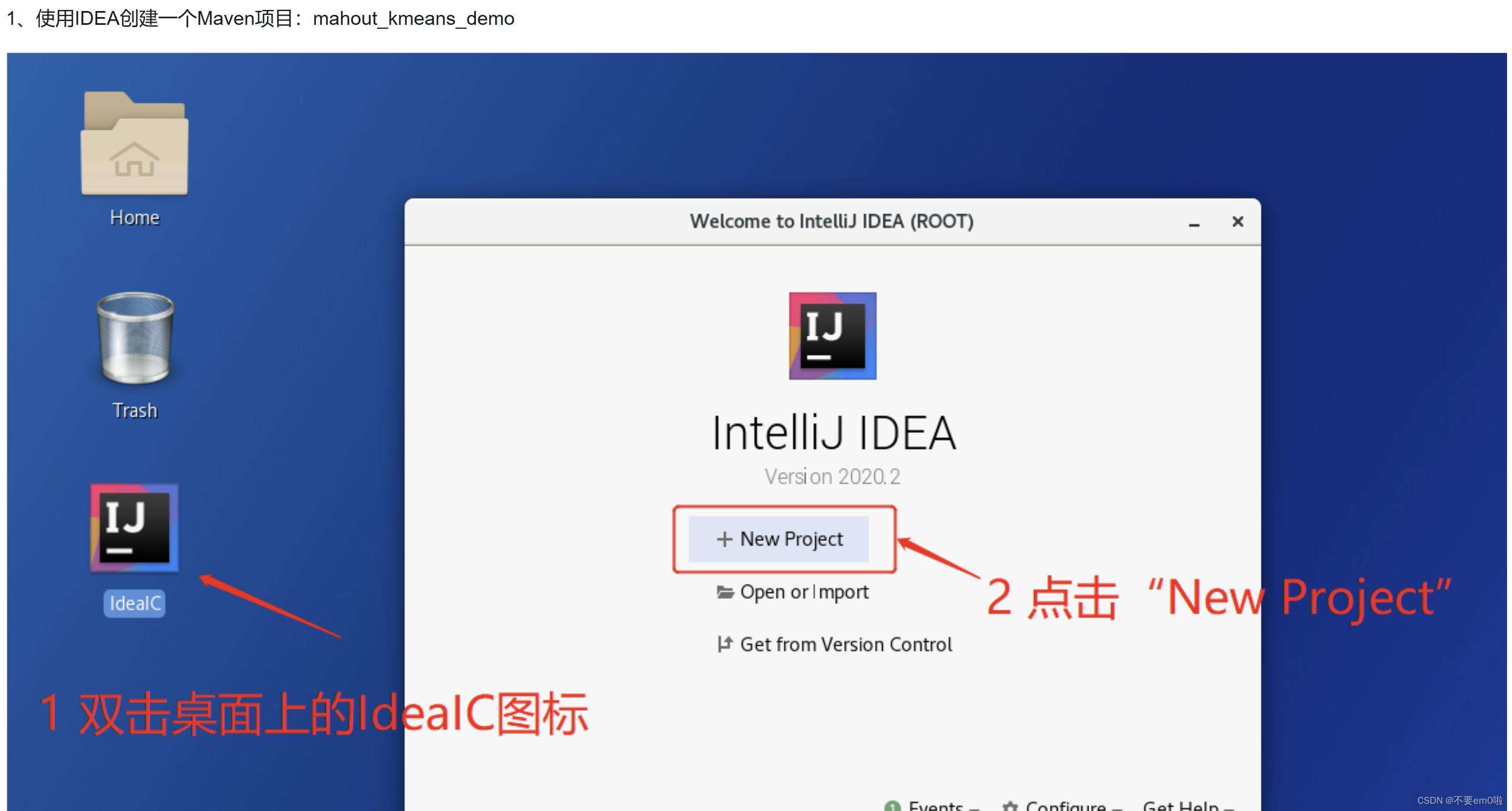
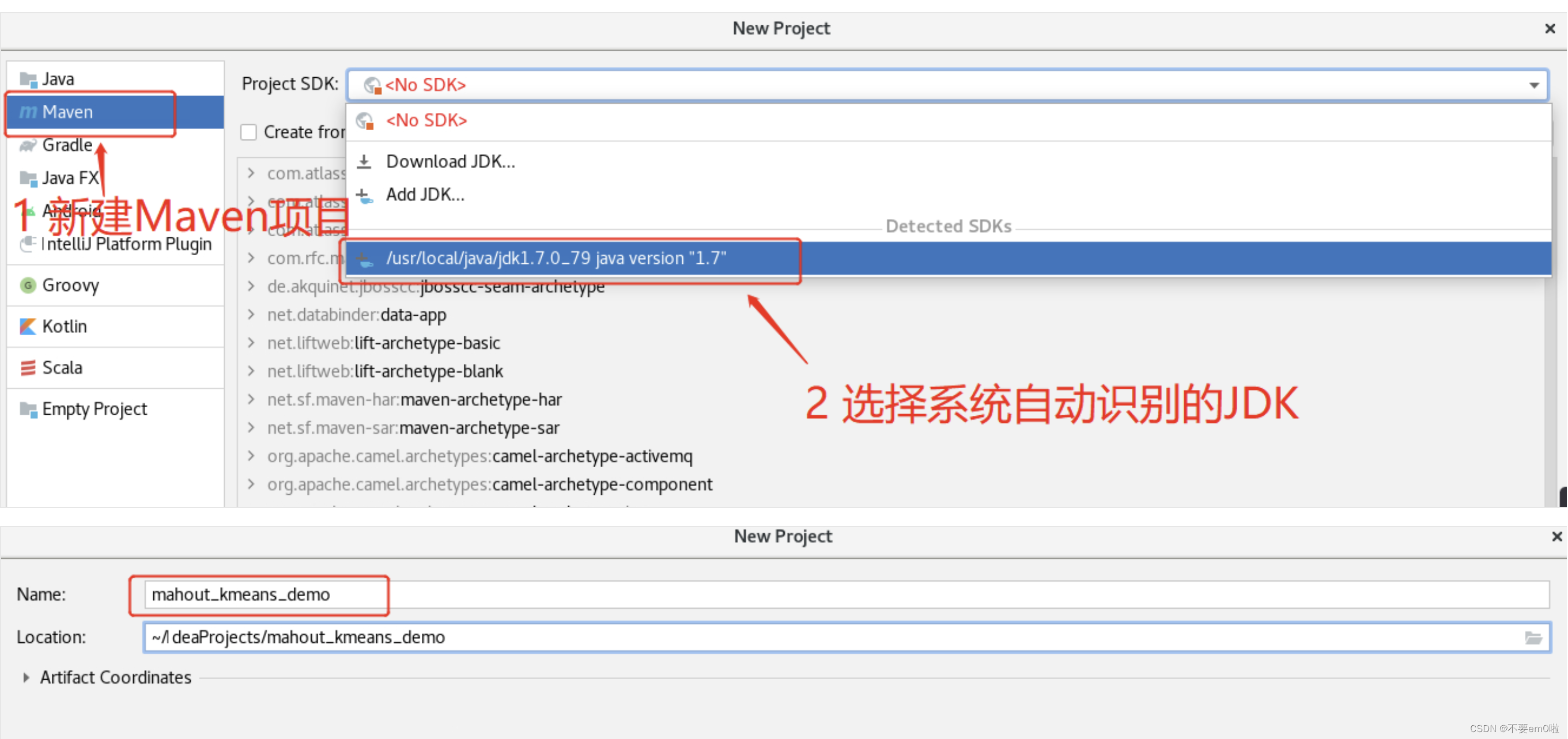
- 使用IDEA创建一个Maven项目:mahout_kmeans_demo
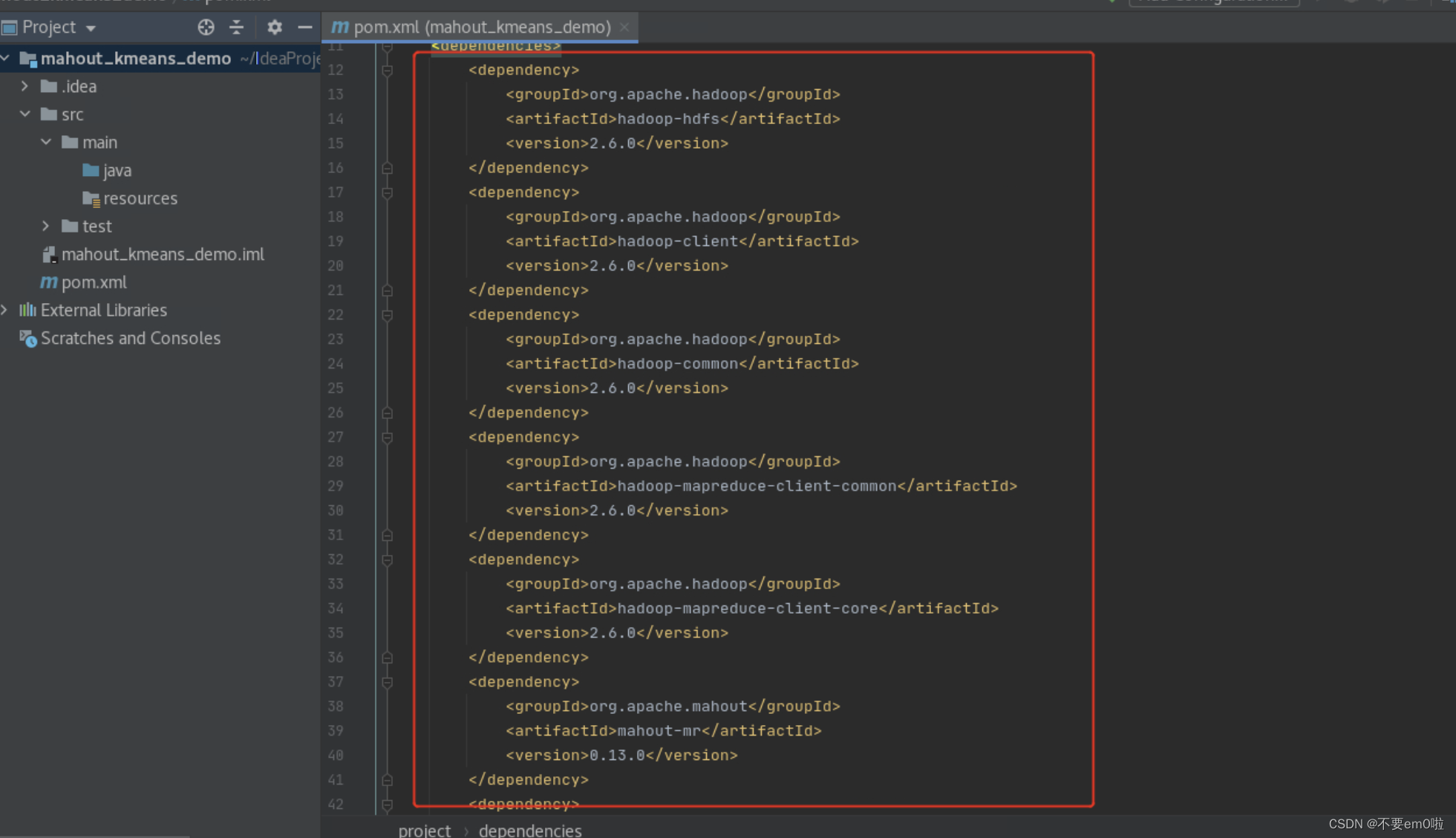
- 修改pom.xml文件,导入开发MapReduce所需的Jar包
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-mr</artifactId><version>0.13.0</version></dependency><dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-math</artifactId><version>0.13.0</version></dependency><dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-hdfs</artifactId><version>0.13.0</version></dependency><dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-integration</artifactId><version>0.13.0</version></dependency><dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-examples</artifactId><version>0.13.0</version></dependency>
</dependencies>下载相关依赖包
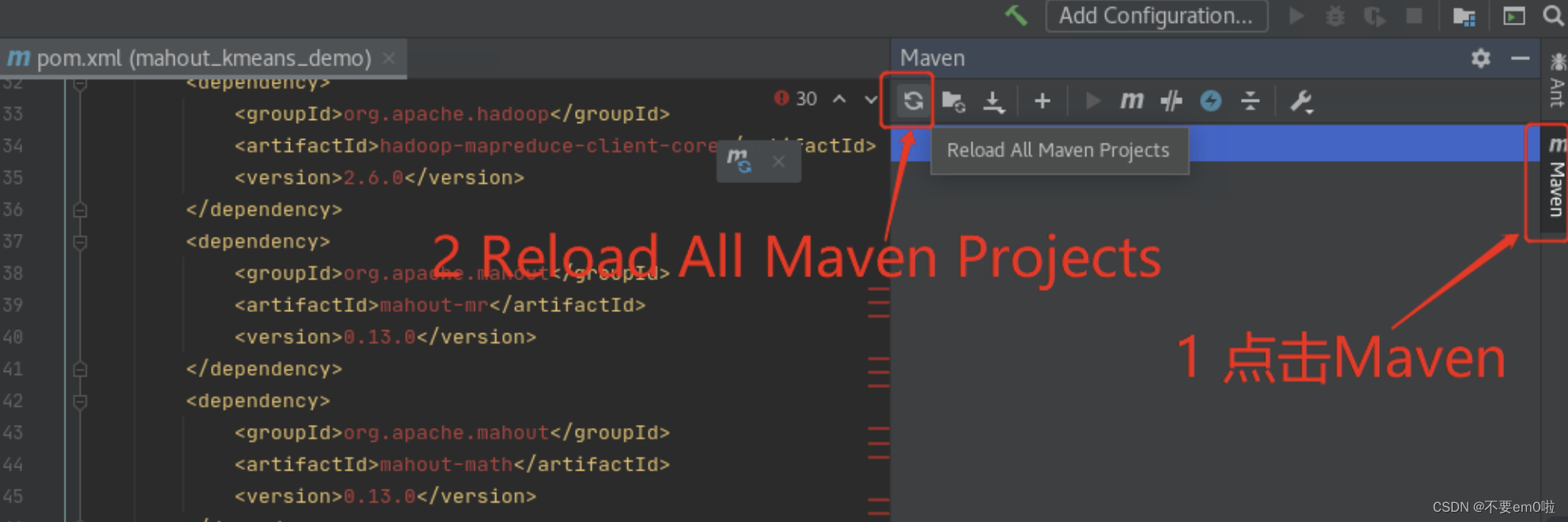
等待pom.xml文件不再出现错误即可
- 准备实验数据并下载

- 启动Hadoop集群。
终端输入start-all.sh
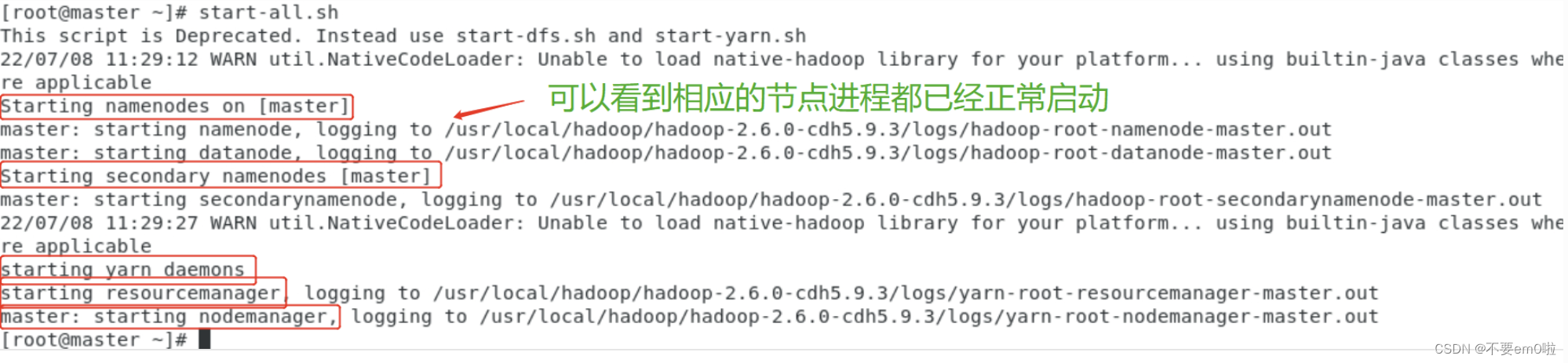
可以使用jps命令查看集群启动情况。

4.执行聚类过程:
- 编写工具类HdfsUtil,对HDFS的基本操作进行封装
package com;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.mapred.JobConf;import java.io.IOException;
import java.net.URI;public class HdfsUtil {private static final String HDFS = "hdfs://master:9000/";private String hdfsPath;private Configuration conf;public HdfsUtil(Configuration conf) {this(HDFS, conf);}public HdfsUtil(String hdfs, Configuration conf) {this.hdfsPath = hdfs;this.conf = conf;}public static JobConf config() {JobConf conf = new JobConf(HdfsUtil.class);conf.setJobName("HdfsDAO");return conf;}public void mkdirs(String folder) throws IOException {Path path = new Path(folder);FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);if (!fs.exists(path)) {fs.mkdirs(path);System.out.println("Create: " + folder);}fs.close();}public void rmr(String folder) throws IOException {Path path = new Path(folder);FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);fs.deleteOnExit(path);System.out.println("Delete: " + folder);fs.close();}public void ls(String folder) throws IOException {Path path = new Path(folder);FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);FileStatus[] list = fs.listStatus(path);System.out.println("ls: " + folder);System.out.println("==========================================================");for (FileStatus f : list) {System.out.printf("name: %s, folder: %s, size: %d\n", f.getPath(), f.isDir(), f.getLen());}System.out.println("==========================================================");fs.close();}public void createFile(String file, String content) throws IOException {FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);byte[] buff = content.getBytes();FSDataOutputStream os = null;try {os = fs.create(new Path(file));os.write(buff, 0, buff.length);System.out.println("Create: " + file);} finally {if (os != null)os.close();}fs.close();}public void copyFile(String local, String remote) throws IOException {FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);fs.copyFromLocalFile(new Path(local), new Path(remote));System.out.println("copy from: " + local + " to " + remote);fs.close();}public void download(String remote, String local) throws IOException {Path path = new Path(remote);FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);fs.copyToLocalFile(path, new Path(local));System.out.println("download: from" + remote + " to " + local);fs.close();}public void cat(String remoteFile) throws IOException {Path path = new Path(remoteFile);FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);FSDataInputStream fsdis = null;System.out.println("cat: " + remoteFile);try {fsdis = fs.open(path);IOUtils.copyBytes(fsdis, System.out, 4096, false);} finally {IOUtils.closeStream(fsdis);fs.close();}}
}- 编写KMeansMahout类,执行聚类过程
package com;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.mahout.clustering.Cluster;
import org.apache.mahout.clustering.canopy.CanopyDriver;
import org.apache.mahout.clustering.conversion.InputDriver;
import org.apache.mahout.clustering.kmeans.KMeansDriver;
import org.apache.mahout.common.HadoopUtil;
import org.apache.mahout.common.distance.EuclideanDistanceMeasure;
import org.apache.mahout.utils.clustering.ClusterDumper;public class KMeansMahout {private static final String HDFS = "hdfs://master:9000";public static void main(String[] args) throws Exception {String localFile = "/home/data/iris.dat";// mahout输出至HDFS的目录String outputPath = HDFS + "/user/hdfs/kmeans/output";// mahout的输入目录String inputPath = HDFS + "/user/hdfs/kmeans/input/";// canopy算法的t1和t2double t1 = 2;double t2 = 1;// 收敛阀值double convergenceDelta = 0.5;// 最大迭代次数int maxIterations = 10;Path output = new Path(outputPath);Path input = new Path(inputPath);Configuration conf = new Configuration();HdfsUtil hdfs = new HdfsUtil(HDFS, conf);hdfs.rmr(inputPath);hdfs.mkdirs(inputPath);hdfs.copyFile(localFile, inputPath);hdfs.ls(inputPath);// 每次执行聚类前,删除掉上一次的输出目录HadoopUtil.delete(conf, output);// 执行聚类run(conf, input, output, new EuclideanDistanceMeasure(), t1, t2, convergenceDelta, maxIterations);}private static void run(Configuration conf, Path input, Path output,EuclideanDistanceMeasure euclideanDistanceMeasure, double t1, double t2,double convergenceDelta, int maxIterations) throws Exception {Path directoryContainingConvertedInput = new Path(output, "data");System.out.println("Preparing Input");// 将输入文件序列化,并选取RandomAccessSparseVector作为保存向量的数据结构InputDriver.runJob(input, directoryContainingConvertedInput,"org.apache.mahout.math.RandomAccessSparseVector");System.out.println("Running Canopy to get initial clusters");// 保存canopy的目录Path canopyOutput = new Path(output, "canopies");// 执行Canopy聚类CanopyDriver.run(conf, directoryContainingConvertedInput, canopyOutput,euclideanDistanceMeasure, t1, t2, false, 0.0, false);System.out.println("Running KMeans");// 执行k-means聚类,并使用canopy目录KMeansDriver.run(conf, directoryContainingConvertedInput,new Path(canopyOutput, Cluster.INITIAL_CLUSTERS_DIR + "-final"),output, convergenceDelta, maxIterations, true, 0.0, false);System.out.println("run clusterdumper");// 将聚类的结果输出至HDFSClusterDumper clusterDumper = new ClusterDumper(new Path(output, "clusters-*-final"),new Path(output, "clusteredPoints"));clusterDumper.printClusters(null);}
}在KmeansMahout类上点击右键并执行程序
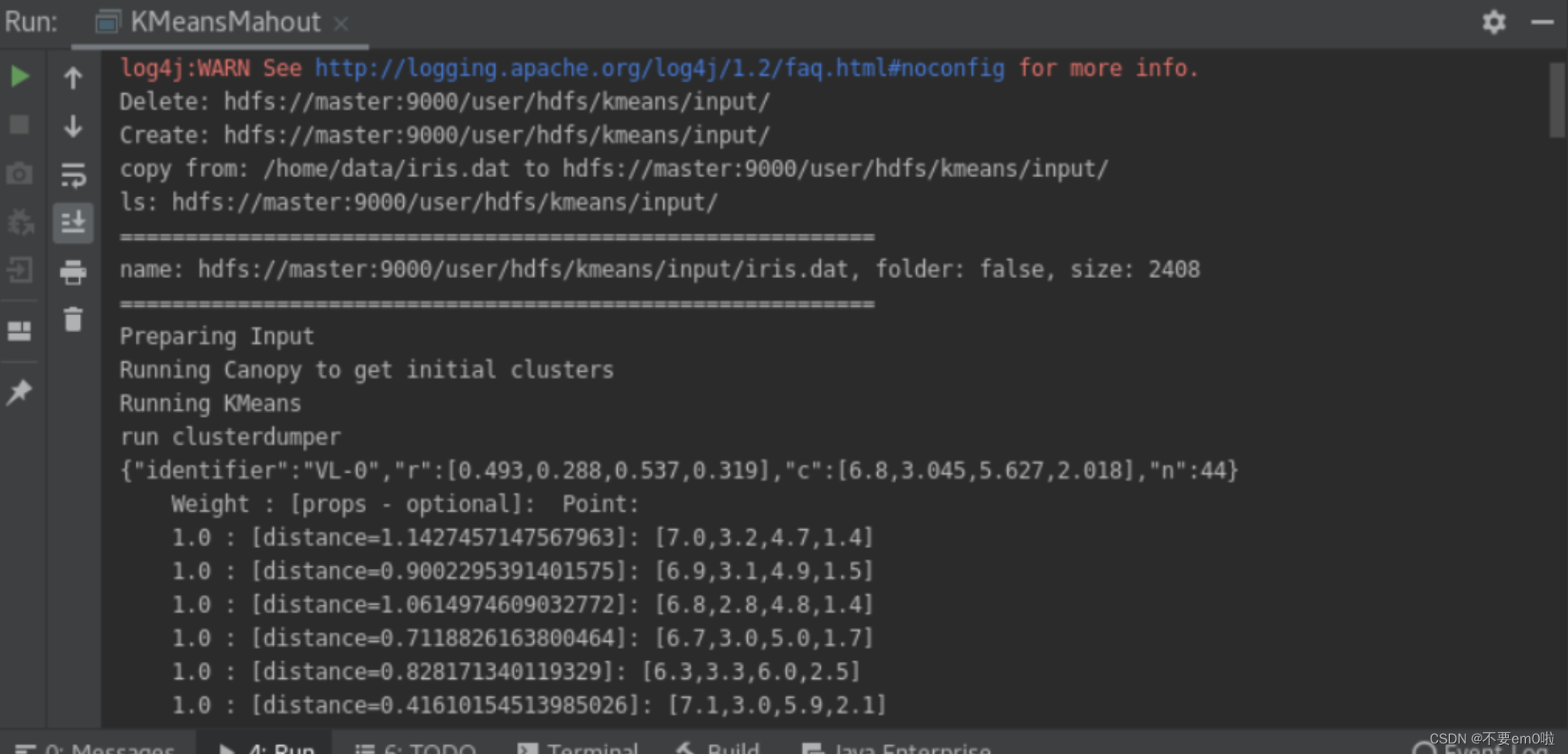
 执行结果在HDFS目录中
执行结果在HDFS目录中
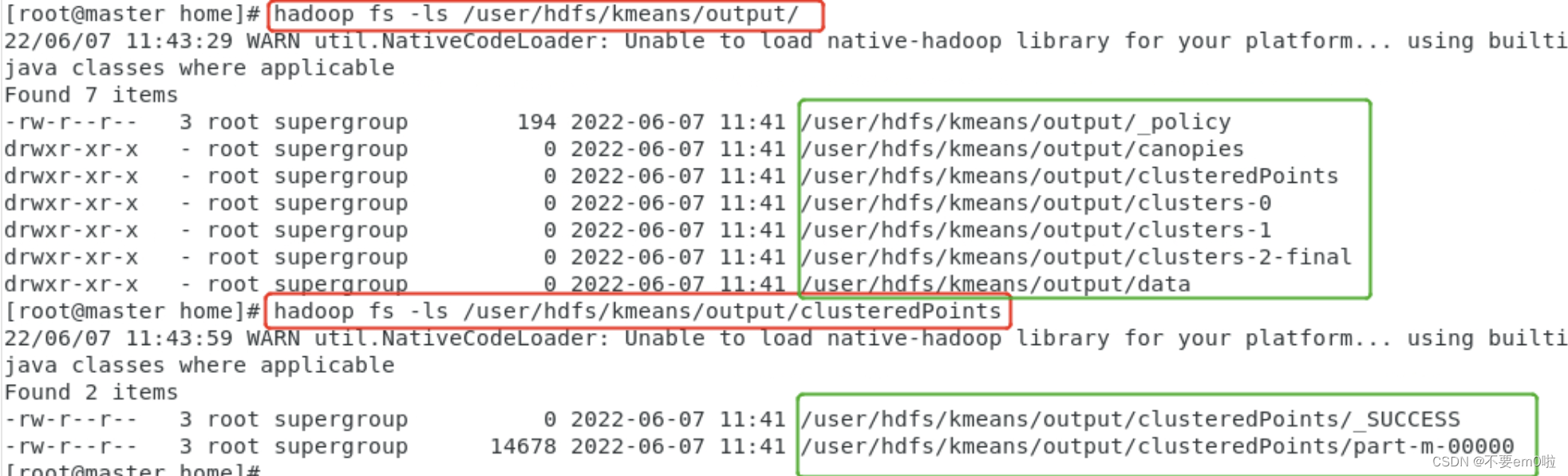
5.解析聚类结果:
- 从Mahout的输出目录下提取出所要的信息
- 编写ClusterOutput类,解析聚类后结果
package com;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.mahout.clustering.classify.WeightedPropertyVectorWritable;
import org.apache.mahout.math.Vector;import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;public class ClusterOutput {private static final String HDFS = "hdfs://master:9000";public static void main(String[] args) {try {// 需要被解析的mahout的输出文件String clusterOutputPath = "/user/hdfs/kmeans/output";// 解析后的聚类结果,将输出至本地磁盘String resultPath = "/home/data/result.txt";BufferedWriter bw;Configuration conf = new Configuration();conf.set("fs.default.name", HDFS);FileSystem fs = FileSystem.get(conf);SequenceFile.Reader reader = null;reader = new SequenceFile.Reader(fs, new Path(clusterOutputPath + "/clusteredPoints/part-m-00000"), conf);bw = new BufferedWriter(new FileWriter(new File(resultPath)));// key为聚簇中心IDIntWritable key = new IntWritable();WeightedPropertyVectorWritable value = new WeightedPropertyVectorWritable();while (reader.next(key, value)) {// 得到向量Vector vector = value.getVector();String vectorValue = "";// 将向量各个维度拼接成一行,用\t分隔for (int i = 0; i < vector.size(); i++) {if (i == vector.size() - 1) {vectorValue += vector.get(i);} else {vectorValue += vector.get(i) + "\t";}}bw.write(key.toString() + "\t" + vectorValue + "\n\n");}bw.flush();reader.close();} catch (Exception e) {e.printStackTrace();}}
}在ClusterOutput类上右键执行程序
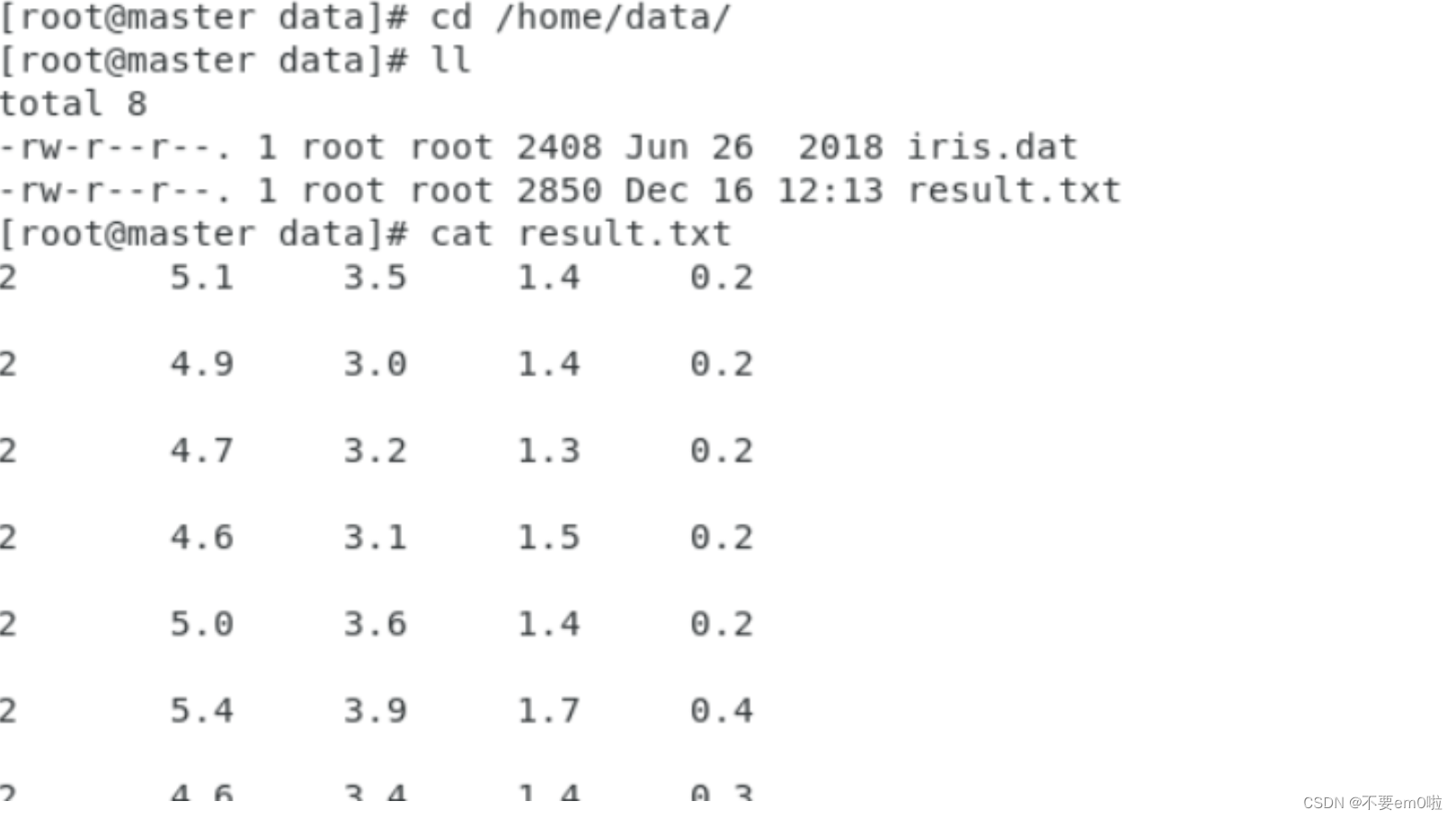
 执行结果被保存在/home/data/result.txt文件中,打开终端执行以下命令
执行结果被保存在/home/data/result.txt文件中,打开终端执行以下命令
6.评估聚类效果:
- 编写InterClusterDistances类,计算平均簇间距离
package com;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.mahout.clustering.Cluster;
import org.apache.mahout.clustering.iterator.ClusterWritable;
import org.apache.mahout.common.distance.DistanceMeasure;
import org.apache.mahout.common.distance.EuclideanDistanceMeasure;import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;public class InterClusterDistances {private static final String HDFS = "hdfs://master:9000";public static void main(String[] args) throws Exception {String inputFile = HDFS + "/user/hdfs/kmeans/output";System.out.println("聚类结果文件地址:" + inputFile);Configuration conf = new Configuration();Path path = new Path(inputFile + "/clusters-2-final/part-r-00000");System.out.println("Input Path:" + path);FileSystem fs = FileSystem.get(path.toUri(), conf);List<Cluster> clusters = new ArrayList<Cluster>();SequenceFile.Reader reader = new SequenceFile.Reader(fs, path, conf);Writable key = (Writable) reader.getKeyClass().newInstance();ClusterWritable value = (ClusterWritable) reader.getValueClass().newInstance();while (reader.next(key, value)) {Cluster cluster = value.getValue();clusters.add(cluster);value = (ClusterWritable) reader.getValueClass().newInstance();}System.out.println("Cluster In Total:" + clusters.size());DistanceMeasure measure = new EuclideanDistanceMeasure();double max = 0;double min = Double.MAX_VALUE;double sum = 0;int count = 0;Set<Double> total = new HashSet<Double>();// 如果聚类的个数大于1才开始计算if (clusters.size() != 1 && clusters.size() != 0) {for (int i = 0; i < clusters.size(); i++) {for (int j = 0; j < clusters.size(); j++) {double d = measure.distance(clusters.get(i).getCenter(), clusters.get(j).getCenter());min = Math.min(d, min);max = Math.max(d, max);total.add(d);sum += d;count++;}}System.out.println("Maximum Intercluster Distance:" + max);System.out.println("Minimum Intercluster Distance:" + min);System.out.println("Average Intercluster Distance:" + sum / count);for (double d : total) {System.out.print("[" + d + "] ");}} else if (clusters.size() == 1) {System.out.println("只有一个类,无法判断聚类质量");} else if (clusters.size() == 0) {System.out.println("聚类失败");}}
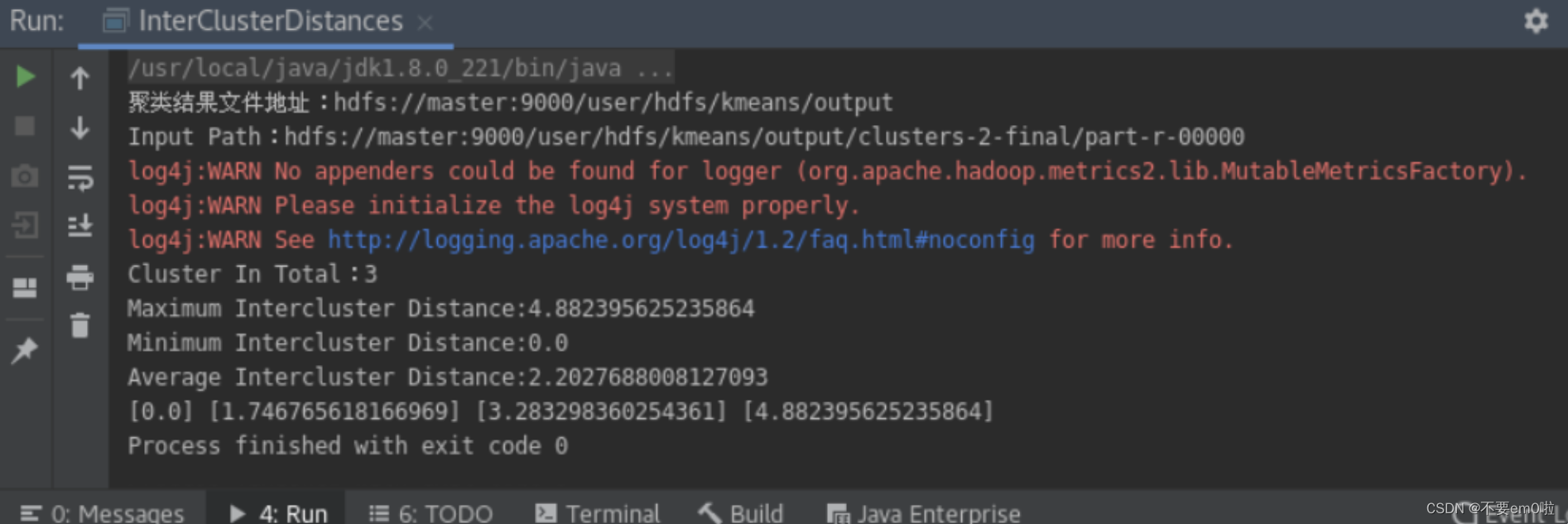
}同样右键执行程序,得到下图结果








)
(2))

)


)


步骤讲解)
![[C语言]——C语言常见概念(1)](http://pic.xiahunao.cn/[C语言]——C语言常见概念(1))
