微软近期在文本至图像生成领域取得了一项重要突破,通过引入多重低秩适应(LoRA)技术,成功地创造出了高度个性化和细节丰富的图像。这一研究不仅为我们带来了全新的图像生成方法,还为我们提供了一种基于GPT-4V的图像质量评估工具。
1. 引入LoRA技术
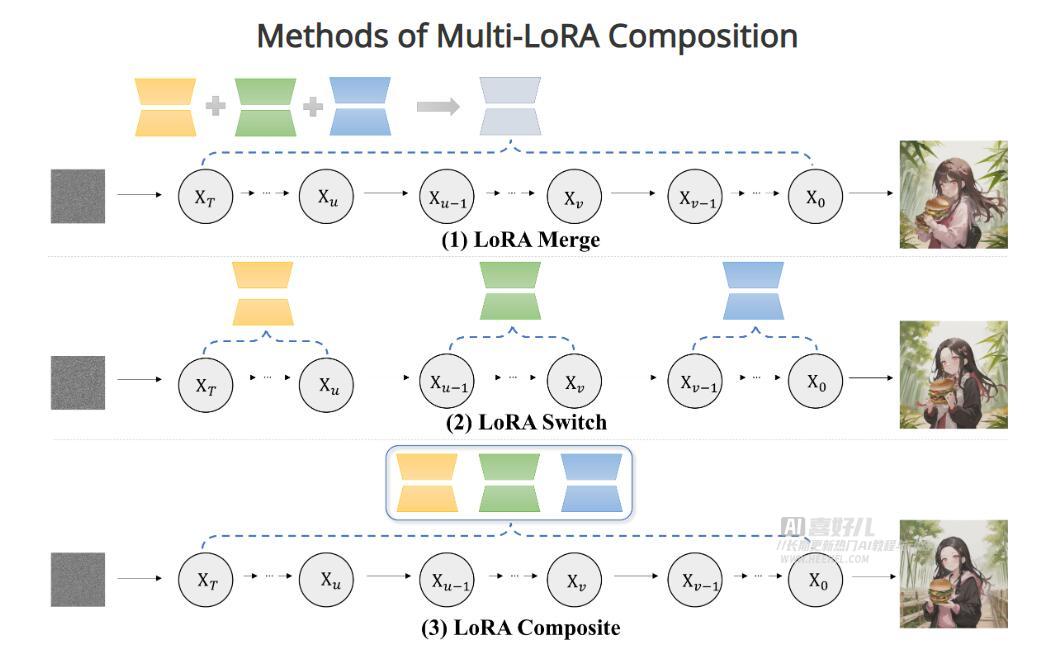
LoRA是一种有效的技术,它通过低秩适应来优化图像生成过程。微软在研究中提出了两种新的方法:LoRA开关和LoRA组合。这两种方法都能够在不经过训练的情况下动态地、精确地整合多个LoRA,从而生成高质量的图像。
2. 免训练方法
与传统的需要微调的方法不同,这项研究采用了免训练的方法。这意味着在整合多个LoRA时,无需对模型进行额外的训练。这种方法不仅简化了图像生成过程,还提高了生成效率。

3. ComposLoRA测试平台
为了评估这项技术的性能,微软创建了一个名为ComposLoRA的综合性测试平台。该平台包含了480套组合和22个在六大类别中预训练好的LoRA。通过该平台,研究人员可以对基于LoRA的可组合图像生成任务进行定量评估,从而更加客观地评价生成图像的质量。
4. 基于GPT-4V的评估工具
微软还提出采用GPT-4V作为评估工具,用以判定组合效果及图像质量。GPT-4V是一个先进的语言模型,具有强大的图像理解能力。通过GPT-4V,研究人员可以更加准确地评估生成图像的质量,并与人类评价进行对比。

5. 卓越的性能表现
实验结果显示,无论是通过自动化评估还是人类评价,微软的方法都显著优于现有的LoRA合并技术。特别是在生成复杂图像组合的场景中,这种方法表现出了更加突出的优势。这表明微软的研究在精确度和图像质量方面都取得了显著的提升。
6. 详尽的分析
为了让我们更好地理解这项技术的优势和应用前景,研究人员还进行了详尽的分析。他们深入探讨了每种方法在不同场景下的优势,并探讨了采用GPT-4V作为评估工具可能存在的偏差。这为未来的研究提供了有价值的参考。
multi-lora-composition项目展示地址:
Multi-LoRA Composition for Image Generation
multi-lora-composition代码下载:
GitHub - maszhongming/Multi-LoRA-Composition: Repository for the Paper "Multi-LoRA Composition for Image Generation"
更多AI工具
专注收录AIGC(通用型AI)垂直领域的工具与软件
综上所述,微软在文本至图像生成领域的研究取得了令人瞩目的成果。通过引入LoRA技术、采用免训练方法以及提出基于GPT-4V的评估工具,他们成功地创造出了高度个性化且细节丰富的图像。随着这些技术的不断发展和完善,我们有理由相信未来的图像生成将更加个性化、多样化且符合人类审美需求。



)

:)




:从制作一个对战小游戏开始(Cocos Creator 《击败老大》)(第二段))








python小高组初赛真题)