一、分类模型简介
本篇将介绍分类模型。对于二分类模型,我们将介绍逻辑回归(logistic regression)和Fisher线性判别分析两种分类算法;对于多分类模型,我们将简单介绍SPSS中的多分类线性判别分析和多分类逻辑回归。
分类模型,顾名思义将数据分类。如有一堆苹果和橙子,有它们的重量,大小,颜色等数据,将它们根据数据分为两类,之后如果给出数据,可以进行一定的判断,这个只有数据的是苹果还是橙子。
二、适用赛题
预测类
- 由已知数据处理分类得到模型
- 对后来的数据进行预测
三、模型流程
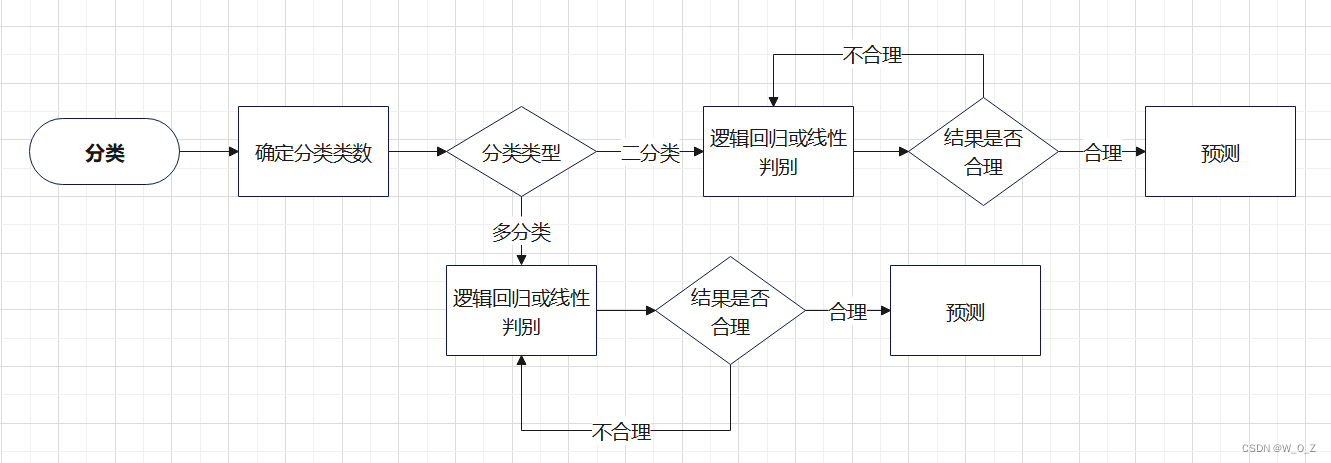
四、流程分析
本篇中的逻辑回归和Fisher线性判别不做证明,且逻辑回归和Fisher线性判别推荐使用SPSS软件进行操作
1.确定分类
分类模型有二分类和多分类两种,开始先得确定要分多少类。比如上面的苹果和橙子例子就是二分类;如果水果种类再多点,像苹果、橙子、柠檬和橘子,就是多分类问题。
2.二分类
①逻辑回归
对于因变量为分类变量的情况,我们可以使用逻辑回归进行处理。把y看成事件发生的概率,y ≥ 0.5表示发生;y < 0.5表示不发生。比如可以说y ≥ 0.5是苹果,y < 0.5是橙子。
线性概率模型(Linear Probability Model 简记LPM)



由于后者有解析表达式(而标准正态分布的cdf没有),所以计算logistic模型比probit模型更为方便。


②Fisher线性判别分析
LDA(Linear Discriminant Analysis)是一种经典的线性判别方法,又称Fisher判别分析。该方法思想比较简单:给定训练集样例,设法将样例投影到一维的直线上,使得同类样例的投影点尽可能接近和密集,异类投影点尽可能远离。
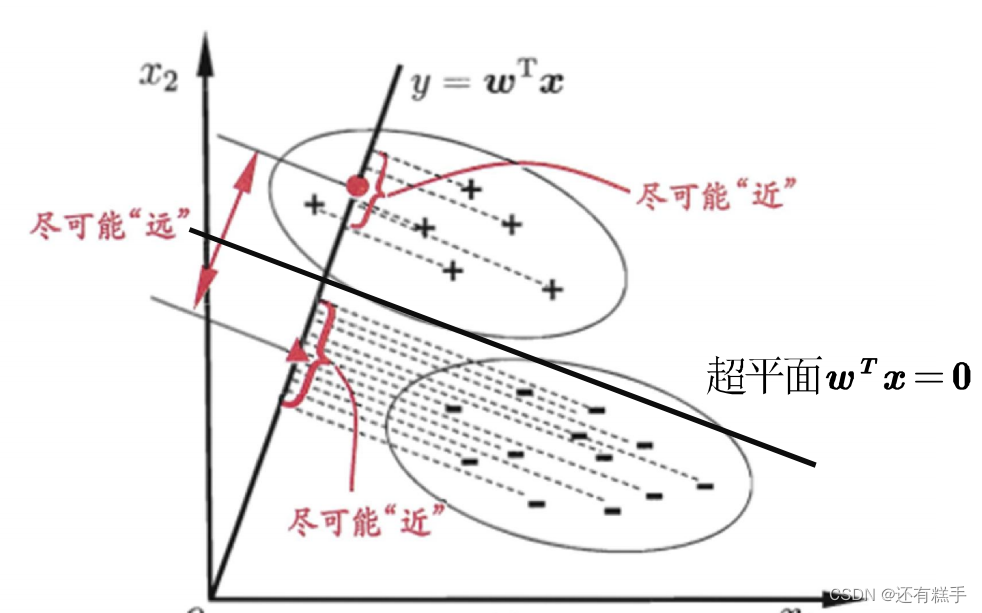
可借助SPSS软件直接得到结果。
3.多分类
多分类的操作和二分类类似,这里不再赘述。
4.合理性
如果预测结果较差怎么办?
可在Logistic回归模型中加入平方项、交互项等。
但在加入平方项之后,虽然预测能力提高了,但有可能会出现过拟合现象。
也就是对于样本数据的预测非常好,但是对于样本外的数据的预测效果可能会很差。
所以如何确定合适的模型?
把数据分为训练组和测试组,用训练组的数据来估计出模型,再用测试组的数据来进行测试。(训练组和测试组的比例一般设置为80%和20%)
注意:为了消除偶然性的影响,可以对上述步骤多重复几次,最终对每个模型求--个平均的准确率,这个步骤称为交叉验证。
5.预测
根据给出的数据,计算得到属于哪个类别的可能性最大。





)













