Data Skipping Indexes
Data Skipping Indexes 2
1、简介
影响ClickHouse查询性能的因素很多。在大多数情况下,关键因素是ClickHouse在计算查询WHERE子句条件时是否可以使用主键。因此,选择适用于最常见查询模式的主键对于有效的表设计至关重要。
然而,无论如何仔细地调整主键,都会不可避免地有查询用例来无法有效地使用它。用户通常依赖ClickHouse来获取时间序列类型的数据,但他们通常希望根据其他业务维度分析相同的数据,如客户id、网站URL或产品编号。在这种情况下,查询性能可能会更糟糕,因为需要对每个列值进行完整的扫描,才能应用WHERE子句条件。虽然ClickHouse在这些情况下仍然相对较快,但评估数百万或数十亿的单独的数值会导致“非索引”的查询,比基于主键的查询要慢得多。
在传统的关系数据库中,有一种方法是将一个或多个“辅助”索引附加到一个表中。这是一个b树结构,允许数据库在O(log(n))时间中找到所有匹配的行(log(n))时间,而不是O(n)时间(一个表扫描),其中n是行数。然而,这种类型的辅助索引不会用于ClickHouse(或其面向列的数据库),因为磁盘上没有单独的行来添加索引。
相反,ClickHouse提供了一种不同类型的索引,在特定情况下可以显著提高查询速度。这些结构被标记为“跳过”索引,因为它们使ClickHouse能够跳过读取保证没有匹配值的相当数量的数据块。
2、基本操作
用户只能在MergeTree表族上使用跳数索引。每个数据跳转有四个主要参数:
- 索引名称。索引名用于在每个分区中创建索引文件。此外,在删除或具体化(materializing)索引时需要将其作为参数。
- 索引表达式。索引表达式用于计算存储在索引中的值集。它可以是列、简单运算符及(或)由索引类型决定的函数子集的组合
- TYPE。索引的类型控制着确定是否可以跳过读取和求值每个索引块的计算。
- 粒度(GRANULARITY)。每个索引块由粒度颗粒组成。例如,如果主表索引的粒度为8192行,索引粒度为4,则每个索引的“块”将是32768行。
当用户创建数据跳过索引时,每个数据部分目录中将有两个额外的文件用于表。
skp_idx_{index_name}.idx包含有序的表达式值skp_idx_{index_name}.mrk2包含到关联数据列文件的相应偏移量。
如果WHERE子句过滤条件的某些部分在执行查询和读取相关列文件时匹配跳数索引表达式,ClickHouse将使用索引文件数据来确定是否必须处理或可以绕过每个相关的数据块(假设该块尚未通过应用主键排除)。要使用一个非常简化的示例,请考虑下面这个加载了可预测数据的表。
CREATE TABLE skip_table
(my_key UInt64,my_value UInt64
)
ENGINE MergeTree primary key my_key
SETTINGS index_granularity=8192;INSERT INTO skip_table SELECT number, intDiv(number,4096) FROM numbers(100000000);
在执行一个不使用主键的简单查询时,扫描my_value列中的所有1亿条目:
SELECT * FROM skip_table WHERE my_value IN (125, 700);

现在添加一个非常基本的跳数索引:
ALTER TABLE skip_table ADD INDEX vix my_value TYPE set(100) GRANULARITY 2;

通常跳数索引只应用于新插入的数据,所以仅仅添加索引不会影响上面的查询。
要索引已经存在的数据,使用这个语句:
ALTER TABLE skip_table MATERIALIZE INDEX vix;
使用新创建的索引重新运行查询:
SELECT * FROM skip_table WHERE my_value = 125
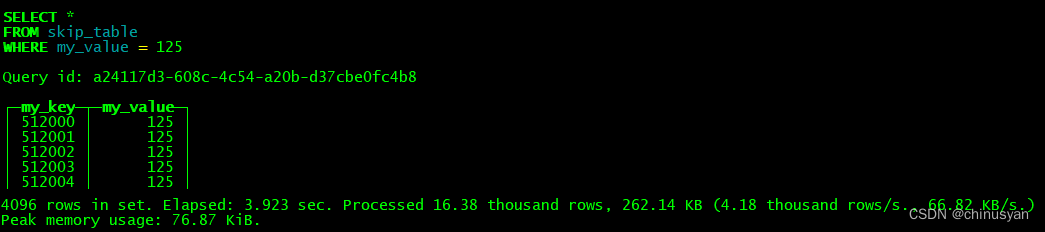
ClickHouse并没有处理1亿行800兆字节的数据,而是只读取和分析了16380行262KB的数据——2个8192行的粒度。
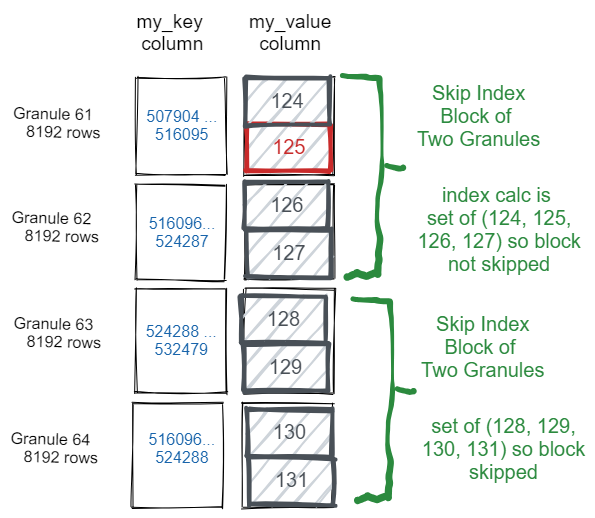
在一个更直观的形式中,这是如何读取和选择my_value为125的4096行,以及如何跳过以下行而不从磁盘读取:
用户可以通过在执行查询时启用跟踪来访问有关跳过索引使用情况的详细信息。从clickhouse-client,设置send_logs_level:
SET send_logs_level='trace';
这将在尝试调优查询SQL和表索引时提供有用的调试信息。从上面的例子中,调试日志显示跳跃索引删除了除两个颗粒外的所有颗粒:
<Debug> executeQuery: (from [::ffff:127.0.0.1]:59550) SELECT * FROM skip_table WHERE my_value = 125 (stage: Complete)<Trace> InterpreterSelectQuery: The min valid primary key position for moving to the tail of PREWHERE is -1<Debug> InterpreterSelectQuery: MergeTreeWhereOptimizer: condition "my_value = 125" moved to PREWHERE<Trace> ContextAccess (default): Access granted: SELECT(my_key, my_value) ON default.skip_table<Trace> InterpreterSelectQuery: FetchColumns -> Complete<Debug> default.skip_table (39a7ab58-a89e-4780-8b49-316b55bb16fd) (SelectExecutor): Key condition: unknown<Debug> default.skip_table (39a7ab58-a89e-4780-8b49-316b55bb16fd) (SelectExecutor): Index `vix` has dropped 12207/12209 granules.<Debug> default.skip_table (39a7ab58-a89e-4780-8b49-316b55bb16fd) (SelectExecutor): Selected 6/6 parts by partition key, 1 parts by primary key, 12209/12209 marks by primary key, 2 marks to read from 1 ranges<Trace> default.skip_table (39a7ab58-a89e-4780-8b49-316b55bb16fd) (SelectExecutor): Spreading mark ranges among streams (default reading)<Trace> default.skip_table (39a7ab58-a89e-4780-8b49-316b55bb16fd) (SelectExecutor): Reading 1 ranges in order from part all_1_36_2_103, approx. 16384 rows starting from 507904<Trace> MergeTreeSelectProcessor: PREWHERE condition was split into 1 steps: "equals(my_value, 125)"<Debug> executeQuery: Read 16384 rows, 256.00 KiB in 0.661823 sec., 24755.863727915166 rows/sec., 386.81 KiB/sec.<Debug> TCPHandler: Processed in 0.662557299 sec.
3、跳数索引类型
3.1 MinMax
minmax
这个轻量级索引类型不需要参数。它存储每个块的索引表达式的最小值和最大值(如果表达式是一个元组,它分别存储元组元素的每个成员的值)。这种类型是理想的列,通常由值松散地排序。在查询处理过程中,该索引类型通常是最不昂贵的。
这种类型的索引只适用于标量或元组表达式——索引永远不会应用于返回数组或映射数据类型的表达式。
3.2 set
set(max_rows)
这种轻量级索引类型接受每个块值集的max_size的单个参数(0允许无限数量的离散值)。该集合包含块中的所有值(如果值的数量超过max_size则为空;max_rows=0表示“没有限制”)。这种索引类型适用于每组粒度(本质上是“聚集在一起”)中基数较低但总体基数较高的列。
此索引的成本、性能和有效性取决于块内的基数。如果每个块包含大量唯一值,那么针对大型索引集评估查询条件的代价将非常昂贵,或者由于索引超过max_size而为空,因此索引将不被应用。
3.3 Bloom Filter Types(布隆过滤器类型)
布隆过滤器是一种数据结构,它允许以很小的误报概率为代价对集合成员进行空间效率测试。在跳数索引的情况下,误报不是一个重要的问题,因为唯一的缺点是读取一些不必要的块。但是,误报的可能性确实意味着索引表达式应该为真,否则可能会跳过有效数据。
因为Bloom过滤器可以更有效地处理对大量离散值的测试,所以它们可以适用于产生更多要测试的值的条件表达式。特别是,Bloom过滤器索引可以应用于数组(其中测试数组的每个值)和映射(map,通过使用mapKeys或mapValues函数将键或值转换为数组)。
有三种基于Bloom过滤器的跳数索引类型:
-
基本的
bloom_filter,它接受一个可选参数,即允许的“误报”率在0到1之间(如果未指定,则使用0.025)。
语法:bloom_filter([false_positive]) -
专用的
tokenbf_v1。它有三个参数,都与调整所使用的布隆过滤器有关:- 1)过滤器的大小(以字节为单位)(更大的过滤器的误报更少,但需要一定的存储成本);
- 2)应用哈希函数的数量(同样,更多的哈希过滤器可以减少误报);
- 3)布隆过滤器哈希函数的种子。
有关这些参数如何影响布隆过滤器功能的更多细节,请参阅这里的计算器。这类索引只使用字符串、FixedString和Map datatypes。输入表达式被分割成由非字母数字字符分隔的字符序列。例如,This is a candidate for a "full text" search列值将包含Thisisacandidateforfulltextsearch。它旨在用于LIKE、EQUALS、in、hasToken()和类似的搜索,在较长的字符串中查找单词和其他值。例如,一种可能的用途是在自由格式的应用程序日志行列中搜索少量的类名或行号。
语法:
tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed) -
专门的
ngrambf_v1(多元组布隆过滤器)。该索引的功能与令牌索引相同。在布隆过滤器设置之前,它需要一个额外的参数,即要索引的元组的大小。ngram是任何字符长度为n的字符串,因此ngram大小为4的字符串A short string将被索引为:
'A sh', ' sho', 'shor', 'hort', 'ort ', 'rt s', 't st', ' str', 'stri', 'trin', 'ring'
这个索引对于文本搜索也很有用,特别是没有单词分隔的语言,比如中文。
语法:ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed)
4、跳数索引函数
跳数索引的核心目的是限制热门查询分析的数据量。考虑到ClickHouse数据的分析性质,这些查询的模式在大多数情况下包括函数表达式。因此,跳数索引必须与常用函数正确交互才能提高效率。这可能发生在以下情况:
- 插入数据,将索引定义为函数表达式(由索引文件中存储的表达式的结果),或
- 处理查询并将表达式应用于存储的索引值,以确定是否排除该块。
每种类型的跳数索引都适用于适合这里列出的索引实现的可用ClickHouse函数的子集。通常,集合索引和基于Bloom过滤器的索引(另一种类型的集合索引)都是无序的,因此不适用于范围。相比之下,minmax 索引特别适合于范围,因为确定范围是否相交非常快。部分匹配函数LIKE、startsWith、endsWith和hasToken的有效性取决于所使用的索引类型、索引表达式和数据的特定形态。
5、跳数索引设置
有两种设置适用于跳数索引。
use_skip_indexes(0 or 1, default 1) 并非所有查询都能有效地使用跳数索引。如果特定的过滤条件可能包括大多数数度,则应用数据跳过索引会产生不必要的,有时甚至是巨大的成本。对于不太可能从跳数索引中获益的查询,将该值设置为0。force_data_skipping_indices(以逗号分隔的索引名称列表)。此设置可用于防止某些类型的低效查询。在某些情况下,除非使用跳跃索引,否则查询表的开销太大,对一个或多个索引名使用此设置将为不使用列出的索引的任何查询返回异常。这将防止编写糟糕的查询消耗服务器资源。
6、跳数最佳实践
跳数索引并不直观,特别是对于习惯于使用RDMS领域中基于行的辅助索引或文档存储中反向索引的用户。为了获得任何好处,应用ClickHouse跳数索引必须避免足够的粒度的读取,以抵消计算索引的成本。关键的是,如果一个值在索引块中出现一次,这意味着必须将整个块读入内存并求值,索引成本是不必要的。
考虑以下数据分布:

假设主键/order by键是timestamp,并且在visitor_id上有一个索引。考虑下面的查询:
SELECT timestamp, url FROM table WHERE visitor_id = 1001
对于这种数据分布,传统的辅助索引是非常有利的。辅助索引将只包含5个行位置,而不是读取所有32768行来查找具有所请求的visitor_id的5行,并且只从磁盘读取这5行。对于ClickHouse 跳数索引,情况正好相反。无论跳过 跳数的类型如何,都将测试visitor_id列中的所有32768个值。
因此,试图通过简单地向主键列添加索引来加快ClickHouse查询的自然冲动通常是不正确的。只有在研究了其他替代方法(如修改主键(请参阅如何选择主键)、使用投影或使用物化视图)之后,才应该使用这种高级功能。即使跳数索引是合适的,也经常需要仔细调优索引和表。
在大多数情况下,一个有用的跳数索引需要主键和目标非主键列/表达式之间有很强的相关性。如果不存在相关性(如上图所示),那么在包含数千个值的块中,至少有一行满足过滤条件的可能性很高,并且很少有块会被跳过。相反,如果主键的值范围(比如一天中的时间)与潜在索引列中的值(比如电视观众的年龄)密切相关,那么minmax类型的索引可能是有益的。请注意,在插入数据时,可以通过在排序/ORDER BY键中包含额外的列,或者通过在插入时对与主键关联的值进行分组的方式来批处理插入,从而增加这种相关性。例如,可以将特定site_id的所有事件分组并由ingest过程插入到一起,即使主键是包含来自大量站点的事件的时间戳。这将导致许多只包含少数站点id的颗粒,因此在通过特定site_id值进行搜索时可以跳过许多块。
跳数索引的另一个很好的候选对象是高基数表达式,其中任何一个值在数据中都是相对稀疏的。一个例子可能是跟踪API请求中的错误代码的可观察性平台。某些错误代码虽然在数据中很少见,但可能对搜索特别重要。error_code列上的集合跳过索引将允许绕过绝大多数不包含错误的块,从而显著改进以错误为中心的查询。
最后,关键的最佳实践是测试、测试、再测试。同样,与用于搜索文档的b-树辅助索引或倒排索引不同,跳数索引行为不容易预测。将它们添加到表中会在数据读取和由于各种原因无法从索引中获益的查询上产生很在的成本。它们应该始终在真实世界的数据类型上进行测试,并且测试应该包括类型、粒度大小和其他参数的变化。测试通常会揭示一些模式和陷阱,这些模式和陷阱在单纯的思想实验中并不明显。
7、SQL 参考中的 Data Skipping Indexes
索引声明位于CREATE查询的columns部分。
INDEX index_name expr TYPE type(...) [GRANULARITY granularity_value]
对于来自*MergeTree族的表,可以指定数据跳过索引。
这些索引聚合了关于块上指定表达式的一些信息,这些块由granularity_value粒度组成(粒度的大小是使用表引擎中的index_granularity设置指定的)。然后在SELECT查询中使用这些聚合,通过跳过不能满足where查询的大数据块来减少从磁盘读取的数据量。
GRANULARITY子句可以省略,granularity_value的默认值为1。
例子:
CREATE TABLE table_name
(u64 UInt64,i32 Int32,s String,...INDEX idx1 u64 TYPE bloom_filter GRANULARITY 3,INDEX idx2 u64 * i32 TYPE minmax GRANULARITY 3,INDEX idx3 u64 * length(s) TYPE set(1000) GRANULARITY 4
) ENGINE = MergeTree()
...
在以下查询中,ClickHouse可以使用示例中的索引来减少从磁盘读取的数据量:
SELECT count() FROM table WHERE u64 == 10;
SELECT count() FROM table WHERE u64 * i32 >= 1234
SELECT count() FROM table WHERE u64 * length(s) == 1234
跳数索引也可以在复合列上创建:
-- on columns of type Map:
INDEX map_key_index mapKeys(map_column) TYPE bloom_filter
INDEX map_value_index mapValues(map_column) TYPE bloom_filter-- on columns of type Tuple:
INDEX tuple_1_index tuple_column.1 TYPE bloom_filter
INDEX tuple_2_index tuple_column.2 TYPE bloom_filter-- on columns of type Nested:
INDEX nested_1_index col.nested_col1 TYPE bloom_filter
INDEX nested_2_index col.nested_col2 TYPE bloom_filter
用户可以创建UDF来估计ngrambf_v1的参数集。查询语句如下:
CREATE FUNCTION bfEstimateFunctions [ON CLUSTER cluster]
AS
(total_nubmer_of_all_grams, size_of_bloom_filter_in_bits) -> round((size_of_bloom_filter_in_bits / total_nubmer_of_all_grams) * log(2));CREATE FUNCTION bfEstimateBmSize [ON CLUSTER cluster]
AS
(total_nubmer_of_all_grams, probability_of_false_positives) -> ceil((total_nubmer_of_all_grams * log(probability_of_false_positives)) / log(1 / pow(2, log(2))));CREATE FUNCTION bfEstimateFalsePositive [ON CLUSTER cluster]
AS
(total_nubmer_of_all_grams, number_of_hash_functions, size_of_bloom_filter_in_bytes) -> pow(1 - exp(-number_of_hash_functions/ (size_of_bloom_filter_in_bytes / total_nubmer_of_all_grams)), number_of_hash_functions);CREATE FUNCTION bfEstimateGramNumber [ON CLUSTER cluster]
AS
(number_of_hash_functions, probability_of_false_positives, size_of_bloom_filter_in_bytes) -> ceil(size_of_bloom_filter_in_bytes / (-number_of_hash_functions / log(1 - exp(log(probability_of_false_positives) / number_of_hash_functions))))
要使用这些函数,我们至少需要指定两个参数。例如,如果粒度中有4300 ngrams ,我们期望误报小于0.0001。其他参数可以通过执行以下查询来估计:
--- estimate number of bits in the filter
SELECT bfEstimateBmSize(4300, 0.0001) / 8 as size_of_bloom_filter_in_bytes;┌─size_of_bloom_filter_in_bytes─┐
│ 10304 │
└───────────────────────────────┘--- estimate number of hash functions
SELECT bfEstimateFunctions(4300, bfEstimateBmSize(4300, 0.0001)) as number_of_hash_functions┌─number_of_hash_functions─┐
│ 13 │
└──────────────────────────┘
当然,您也可以使用这些函数根据其他条件估计参数。功能指的是这里的内容。
特殊用途
- 实验性索引支持近似最近邻(ANN)搜索。详情请看这里。
- 一个实验性的倒排索引,支持全文搜索。详情请看这里。
函数支持
WHERE子句中的条件包含对列进行操作的函数的调用。如果列是索引的一部分,ClickHouse在执行函数时尝试使用该索引。ClickHouse支持使用索引的不同函数子集。
类型set的索引可以被所有函数使用。支持的其他索引类型请参考
扩展
布隆(Bloom Filter)过滤器——全面讲解,建议收藏
增加元素:
往布隆过滤器增加元素,添加的key需要根据k个无偏hash函数计算得到多个hash值,然后对数组长度进行取模得到数组下标的位置,然后将对应数组下标的位置的值置为1
- 通过k个无偏hash函数计算得到k个hash值
- 依次取模数组长度,得到数组索引
- 将计算得到的数组索引下标位置数据修改为1
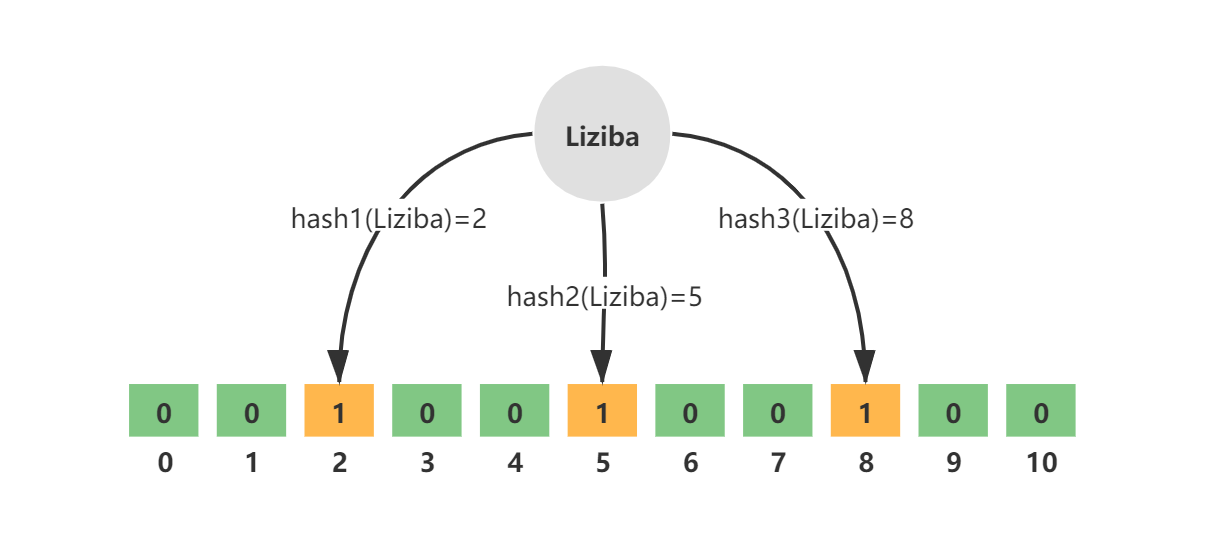
例如,key = Liziba,无偏hash函数的个数k=3,分别为hash1、hash2、hash3。三个hash函数计算后得到三个数组下标值,并将其值修改为1.
如图所示:
查询元素:
布隆过滤器最大的用处就在于判断某样东西一定不存在或者可能存在,而这个就是查询元素的结果。其查询元素的过程如下:
- 通过k个无偏hash函数计算得到k个hash值
- 依次取模数组长度,得到数组索引
- 判断索引处的值是否全部为1,如果全部为1则存在(这种存在可能是误判),如果存在一个0则必定不存在
)







)


——过滤器、拦截器)




![%00截断 [GKCTF 2020]cve版签到](http://pic.xiahunao.cn/%00截断 [GKCTF 2020]cve版签到)


