这篇2月的新论文介绍了Post-Hoc Adaptive Tokenwise Gating Over an Ocean of Specialized Experts (PHATGOOSE),这是一种通过利用一组专门的PEFT模块(如LoRA)实现零样本泛化的新方法
这个方法冻结整个模型,包括PEFT模块,并为每个模块训练一个类似于混合专家(MoE)模型中使用的路由(门控)网络。我们可以将此方法视为创建MoE模型的一种廉价方法,因为每个专家都只是一个LoRA的adapter。

这种门控网络训练的计算量非常小,并且通过在推理期间使用top-k路由策略进行令牌分发,提高了模型处理未显式训练的任务的能力。
PHATGOOSE的有效性在t5系列模型上进行了测试,与之前专家或依赖单个PEFT模块的方法相比,在标准基准上的零样本泛化方面表现优异。有时它的表现也优于明确目标的多任务训练。
使用PHATGOOSE可以实现更加灵活的模型开发,使用同一个基础模型,针对不同的任务训练专家,并且只共享专家参数,然后将模型自动组合提高泛化能力。
PHATGOOSE方法为每个专家模块训练一个sigmoid门控单元,该单元学习哪些令牌应该使用哪些模块。这些单元被组合成一个路由器,在专家模块之间执行稀疏的top-k路由。并且这个方法还支持每个令牌和每个模块的路由,不像过去的检索方法只为每个输入选择单个专家模型。
作者的实验采用T5模型,专家模块在两个集合上训练:T0(36个数据集)和FLAN(166个数据集)。PHATGOOSE在零样本评估中优于过去的路由方法,如检索、合并和平均基线。
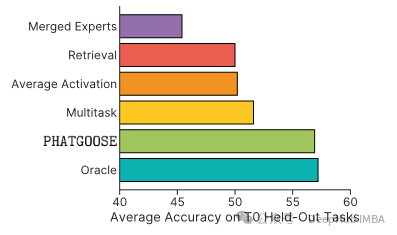
论文提出了一种很有前途的方法,将独立训练的专家模型以分散的方式组合在一起,提高零样本泛化能力,这是一个非常有意思的研究方向,并且提供了源代码,所以推荐仔细阅读。
但是目前有一个最大的问题就是它们的代码只针对T5这个模型,作者也在论文中提出了将在后续的工作中将这个方法与现有的LLM进行整合,所以目前我们还是只能使用T5来进行测试。
论文地址:
https://avoid.overfit.cn/post/e099b8f39fb44497b010d8b929169ac8


)


)




))

)






