
在过去一年里,通用大语言模型(LLM)的飞速发展引起了全球的关注。百度等科技巨头推出了各自的大模型,不断提高语言模型性能的上限。然而,业界对LLM所设定的目标不再局限于基本的问答功能,而是寻求利用大模型来执行更复杂、多样的任务。这就是Agent(智能体)概念的诞生背景。
Agent,可以理解为一个能够自主规划决策、综合运用多种工具以完成复杂任务的系统。在这个系统中,大语言模型充当着“核心调度器”的角色。该调度器负责解读用户的自然语言输入,规划出一连串可执行的动作,并依托记忆模块等其他组件和外部工具,逐步完成这些任务。
2024年,人工智能行业的焦点从通用大模型转向AI原生应用。这一技术变革,离不开AI Agent的深度参与。AI Agent的核心价值在于适应多变的环境和需求,以及做出有效决策及可靠操作,这预示着我们正在步入AGI(人工通用智能)时代。正如比尔·盖茨预言:“在未来五年内,这一切都将彻底改变。你无需针对不同任务切换应用,只需用日常语言与你的设备沟通,软件便能根据你分享的信息提供个性化反馈,因为它对你的生活有了更深入的了解。”
ERNIE SDK
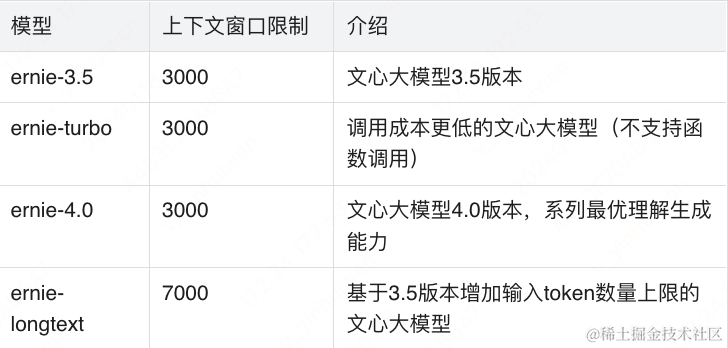
ERNIE SDK近日新增了一项强大的功能——Agent开发,标志着LLM开发进入了新的阶段。基于强大的文心大模型及其Function Calling(函数调用)功能,它为LLM应用开发提供了一个全新的视角。这一框架不仅解决了LLM应用开发中面临的核心挑战,而且通过文心大模型4.0展示了其卓越性能。ERNIE SDK针对几个关键问题提供了有效的解决方案:
1.Token输入数量限制: 传统的大模型分析总结大型文档时会受限于token输入数量的限制,ERNIE SDK提供了本地知识库检索的方式,使得处理大型文档问答任务更加方便。
2.业务API工具的融合: ERNIE SDK使集成现有业务API工具成为可能,拓宽了LLM应用的功能性和适应性。
3.数据源连接: ERNIE SDK能够通过定制工具查询如SQL数据库,连接多种数据源,为大模型提供更多的信息。其作为一个高效的开发框架,大幅提升了开发者的工作效率。依托飞桨星河社区的丰富预制组件,开发者可以直接利用现有资源,或者根据特定业务需求进行定制,为LLM应用的整个开发生命周期提供全面支持。
基于ERNIE SDK的Agent架构分析
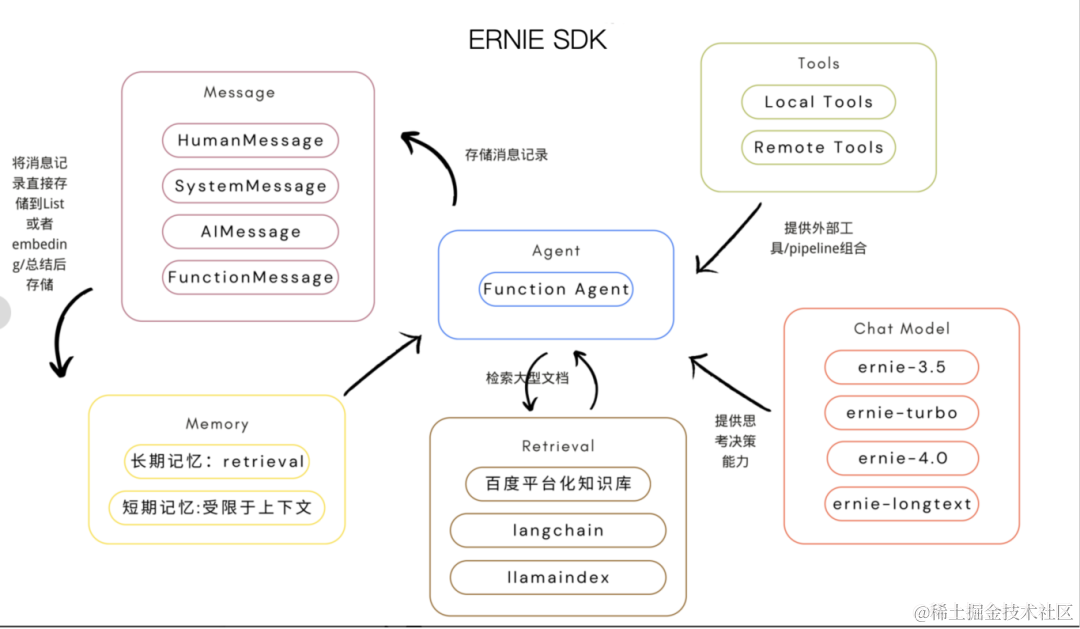
Agent
在一些复杂的场景下,我们需要根据用户输入灵活调用LLM及一系列所需工具,Agent为这样应用程序的实现提供了可能性。ERNIE SDK提供基于文心大模型的Function Calling能力驱动的Agent开发,开发者可以直接使用预置Agent,通过Chat Model、Tool和Memory进行实例化,也可以通过继承erniebot_agent.agents.Agent基类定制自己的Agent。
Chat Model(Agent的大脑)
ERNIE SDK中的Chat Model模块是进行思考决策的核心调度器,也就是百度研发的知识增强大语言模型:文心大模型。
Message(Agent输入输出信息封装)
开发者通过封装后的Message与Chat Model进行交互,能够让大语言模型理解输入的信息来源。

此模块使得用户输入与文心大模型的消息回馈更加规范,以便在后续的Memory模块中进行存储。
Memory(Agent的记忆)
大语言模型本身是没有记忆的,所以构建大模型应用很重要的一点就是给予Agent记忆功能。ERNIE SDK提供快速的记忆功能,能够将多轮对话当中的信息存入到一个List当中,然后传输到Chat Model的上下文窗口当中。不过,这种记忆模式也受限于文心大模型的输入Token。同时,ERNIE SDK也允许开发者构建更复杂的记忆模块,可参考的处理方法有:
-
Vector store-backed memory;每一轮对话的Message将会在embedding处理后存储至向量数据库当中,在后续的对话环境,根据用户输入的自然语言输入,进行语义向量近似检索找出最符合输入语义的记忆片段。这样的方式能够实现长期记忆,不再受限于文心大模型的上下文窗口限制。
-
Conversation summary memory;这种处理方法是在每轮对话后将对话信息调用Chat Model进行一次总结,并存储总结后的简短内容,从而减轻存储内容的压力。
-
LangChain/LlamaIndex;实现自定义记忆模块ERNIE SDK允许开发者自由集成LlamaIndex等框架,可以实现更复杂的记忆模块,利用LlamaIndex优秀的文档检索能力,能够做到更长期的记忆。
Tools(Agent的工具)
让Agent自主组合并使用复杂的外部工具来解决更复杂的问题,是未来AI应用大规模普及的关键;ERNIE SDK允许开发者使用飞桨星河社区已上线的30余个工具,快速构建复杂应用,也能够根据自己的业务需求定制本地工具。
Retrieval(Agent的知识库)
虽然通用大模型在训练过程中吸收了广泛的知识,但它们对特定领域或用户专有的业务知识了解有限。使用特定领域数据对大模型进行微调的成本过高,因此引入RAG(Retrieval Augmented Generation)技术,这一技术的核心是能迅速将外部知识库整合到大模型中,从而深入理解特定领域的专业知识。Retrieval模块的关键功能包括:
-
数据源加载,覆盖多种数据类型:
结构化数据,如SQL和Excel
非结构化数据,如PDF和PPT文档
半结构化数据,如Notion文档
-
数据的分块转化。
-
数据的向量化embedding处理。
-
将处理后的数据存储到向量数据库中。
-
通过近似向量检索,快速定位相关信息。ERNIE SDK的Retrieval模块不仅支持百度的文心百中搜索,还与LangChain和LlamaIndex的Retrieval组件兼容,大幅提升了数据处理的效率和准确性。
基于ERNIE SDK的Agent快速开发体验
现在,让我们一起快速了解如何开发一个Agent——文稿审核助手。这个Agent的主要功能是帮助我们审核各大平台上发布的文稿是否符合规范。
第一步,登录飞桨星河社区,并创建一个新的个人项目。使用社区提供的免费算力配置就足够了。
 第二步,登录飞桨星河社区后,点击本人的头像,在控制台中获取自己的访问令牌,飞桨为每个新注册的用户提供100万额度的免费Token。
第二步,登录飞桨星河社区后,点击本人的头像,在控制台中获取自己的访问令牌,飞桨为每个新注册的用户提供100万额度的免费Token。
为了安全管理您的敏感令牌信息,我们建议使用Dotenv。先安装Dotenv,随后将您的令牌保存在一个新建的.env文件中。注意,此文件默认在文件目录下是不可见的,若需查看,需要更改设置。

示例.env文件内容:

第三步,验证您的访问令牌是否可以正常使用:

如果一切正常,它会打印出您的访问令牌。新建一个文本文件文稿.txt,其中需包含自己要进行合规审核的文本内容。

第四步,构建基础的Agent(使用飞桨星河社区工具中心提供的预制工具)。

运行这段代码,您将看到Agent使用了[text-moderation/v1.2/text_moderation]工具来审核文稿内容,并输出审核结果。这样一来,一个简单的文稿审核助手的Agent开发就完成了。我们一同体验了基于ERNIE SDK的Agent的快速开发流程及其实用性。
多工具智能编排
继深度探索ERNIE SDK后,我们再来看看飞桨星河社区的多工具智能编排功能。飞桨星河社区不仅提供了细粒度的SDK,以支持技术开发者的详细需求,还引入了多工具智能编排功能。这意味着开发者可以基于强大的文心大模型,轻松整合各种外部工具,打造个性化的AI应用。相比起单纯使用ERNIE SDK,这种方法更快速、便捷,大大简化了开发过程。我们将使用多工具智能编排复现文稿审核助手。
首先,使用低代码开发创建应用后,选择智能编排。
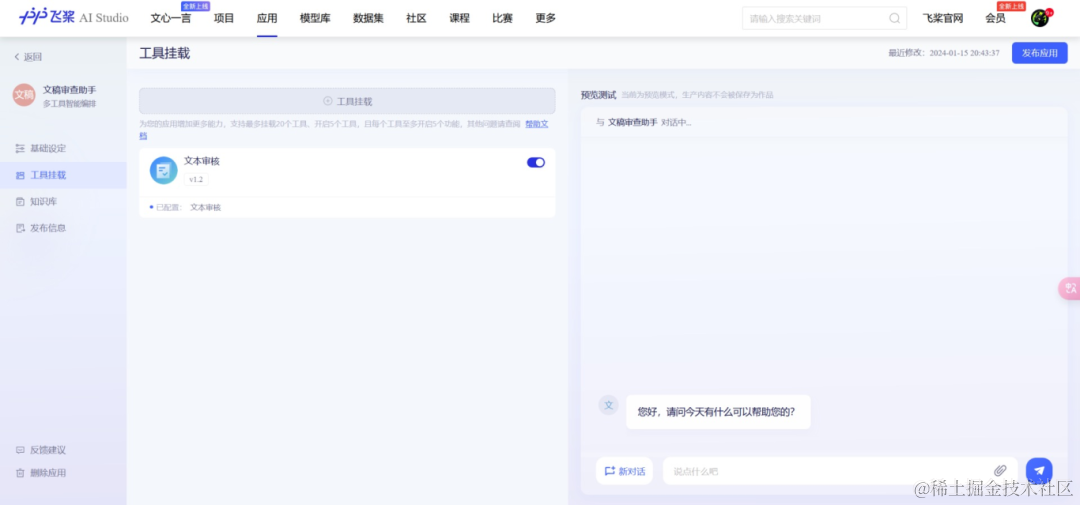
其次,在侧边栏工具挂载中点击挂载“文本审核工具”,这是飞桨星河社区工具中心提供的30多个预制工具之一,你也可以创建自己的工具。
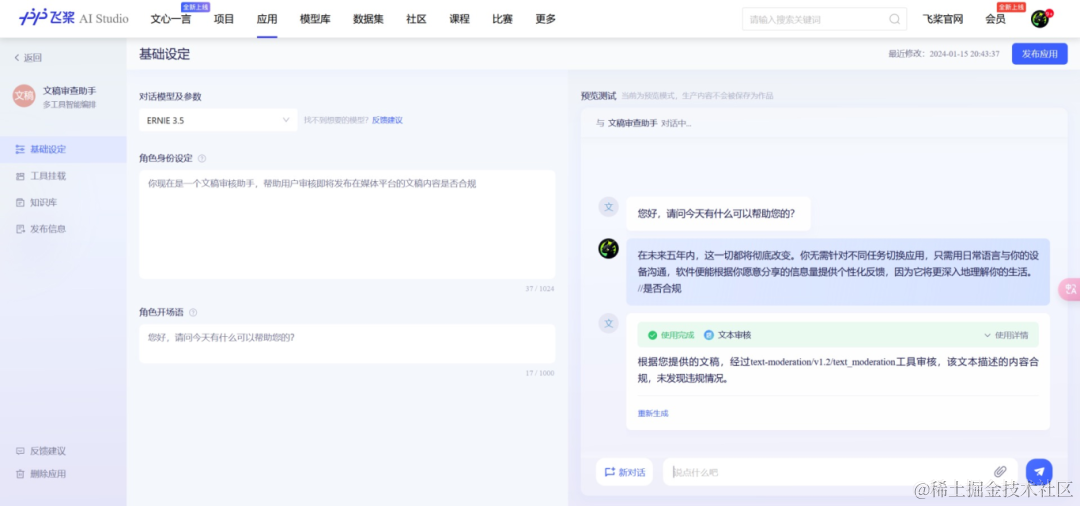
随后,在基础设定中对文稿助手进行角色身份设定。接着点击应用所有设置,就可以在侧边栏进行体验了。
值得一提的是,飞桨星河社区多工具智能编排对于非技术背景的团队成员极为友好。即使没有深入的编程知识,团队成员也能快速上手,轻松构建自己的AI应用。如上述文稿助手的创建只需要几分钟,这不仅加快了产品的迭代速度,还促进了团队内部的协作和创新。
目前,百度飞桨已经开放申请,访问飞桨星河社区邀测报名了解更多详情和申请使用。
随着通用大语言模型的发展和智能Agent技术的兴起,我们正迎来AI应用开发的新时代。从ERNIE SDK的深入探索,到飞桨星河社区多工具智能编排的应用,我们看到像百度飞桨ERNIE SDK这样的AI技术框架如何突破传统边界,为开发者提供了前所未有的便利和巨大的发展可能性。无论是有深厚技术背景的开发者还是非技术人员,都能在这个新时代中找到属于自己的空间,共同推动AI技术的进步及AI应用的普及。AI的未来,充满无限潜力。AI应用的广阔天地,等着我们去探索和创造。



模拟退火(Simulated Annealing)算法与源代码)
)



— 更换Neck网络之GFPN(源自DAMO-YOLO))


![P2895 [USACO08FEB] Meteor Shower S题解](http://pic.xiahunao.cn/P2895 [USACO08FEB] Meteor Shower S题解)




)


