文章目录
- 1 数据的加载
- 1.1 方式一:spark.read.format
- 1.1.1读取json数据
- 1.1.2 读取jdbc数据
- 1.2 方式二:spark.read.xxx
- 1.2.1 读取json数据
- 1.2.2 读取csv数据
- 1.2.3 读取txt数据
- 1.2.4 读取parquet数据
- 1.2.5 读取orc数据
- 1.2.6 读取jdbc数据
- 2 数据的保存
- 2.1 方式一:spark.write.format
- 2.1.1 读取orc数据
- 2.2 方式二:spark.write.xxx
- 2.2.1 写入到jdbc数据库中
SparkSQL提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的API,根据不同的参数读取和保存不用格式的数据。SparkSQL默认读取和保存的文件格式为parquet,parquet是一种能够有效存储嵌套数据的列式存储格式。
1 数据的加载
SparkSQL提供了两种方式可以加载数据
1.1 方式一:spark.read.format
- spark.read.format读取数据文件格式.load加载数据路径”
- 数据文件格式包括csv、jdbc、json、orc、parquet和textFile。
- 需要注意:在读取jdbc时需要在format和load之间添加多个option进行相应的JDBC参数设置【url、user、password.tablename】load中不用传递路经空参数即可
- 数据源为Parquet文件时,SparkSQL可以方便的执行所有的操作,不需要使用format
1.1.1读取json数据
json数据:
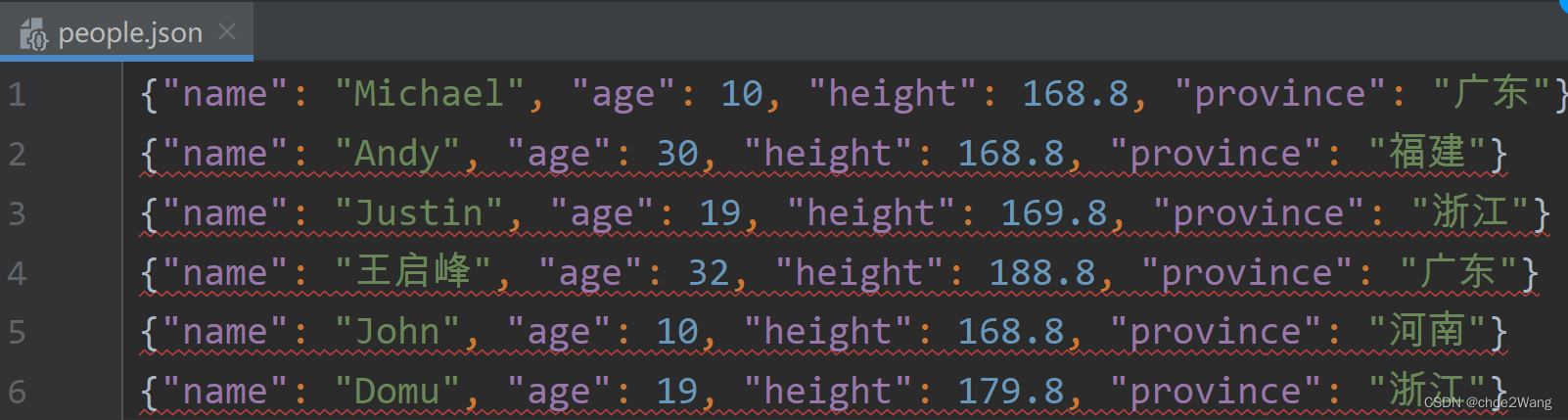
读取代码:
package _02SparkSQL
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}object _06SparkReadData {def main(args: Array[String]): Unit = {val session = SparkSession.builder().appName("SparkReadData").master("local[*]").getOrCreate()//使用第一种范式加载数据var frame: DataFrame = session.read.format("json").load("data/people.json")frame.printSchema()/*** 运行结果:root|-- age: long (nullable = true)|-- height: double (nullable = true)|-- name: string (nullable = true)|-- province: string (nullable = true)*/frame.show()/*** 运行结果:+---+------+-------+--------+|age|height| name|province|+---+------+-------+--------+| 10| 168.8|Michael| 广东|| 30| 168.8| Andy| 福建|| 19| 169.8| Justin| 浙江|| 32| 188.8| 王启峰| 广东|| 10| 168.8| John| 河南|| 19| 179.8| Domu| 浙江|+---+------+-------+--------+* */}
}
1.1.2 读取jdbc数据
读取代码:
package _02SparkSQL
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}object _06SparkReadData {def main(args: Array[String]): Unit = {val session = SparkSession.builder().appName("SparkReadData").master("local[*]").getOrCreate()// 如果读取的JDBC操作(即读取mysql中的数据)val frame = session.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/mydb1").option("dbtable","location_info").option("user","root").option("password","123456").load()frame.printSchema()}
}
1.2 方式二:spark.read.xxx
- 上述的书写方式太过项,所以SparksQL推出了更加便捷的方式spark.read.xxx加载数据路径”)
- XXX包括csv、jdbc、json、orc、parquet和text
- 需要注意:在读取jdbc时方法参数为三个分别为【url、tablename、properties对象】,其中properties对象中存储的是【user,password】
1.2.1 读取json数据
json数据:
读取代码:
package _02SparkSQL
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}object _06SparkReadData {def main(args: Array[String]): Unit = {val session = SparkSession.builder().appName("SparkReadData").master("local[*]").getOrCreate()//【推荐使用】第二种方式进行读取操作val frame = session.read.json("data/people.json")frame.printSchema()/**root|-- age: long (nullable = true)|-- height: double (nullable = true)|-- name: string (nullable = true)|-- province: string (nullable = true)*/frame.show()/**+---+------+-------+--------+|age|height| name|province|+---+------+-------+--------+| 10| 168.8|Michael| 广东|| 30| 168.8| Andy| 福建|| 19| 169.8| Justin| 浙江|| 32| 188.8| 王启峰| 广东|| 10| 168.8| John| 河南|| 19| 179.8| Domu| 浙江|+---+------+-------+--------+ */}}
1.2.2 读取csv数据
csv数据:
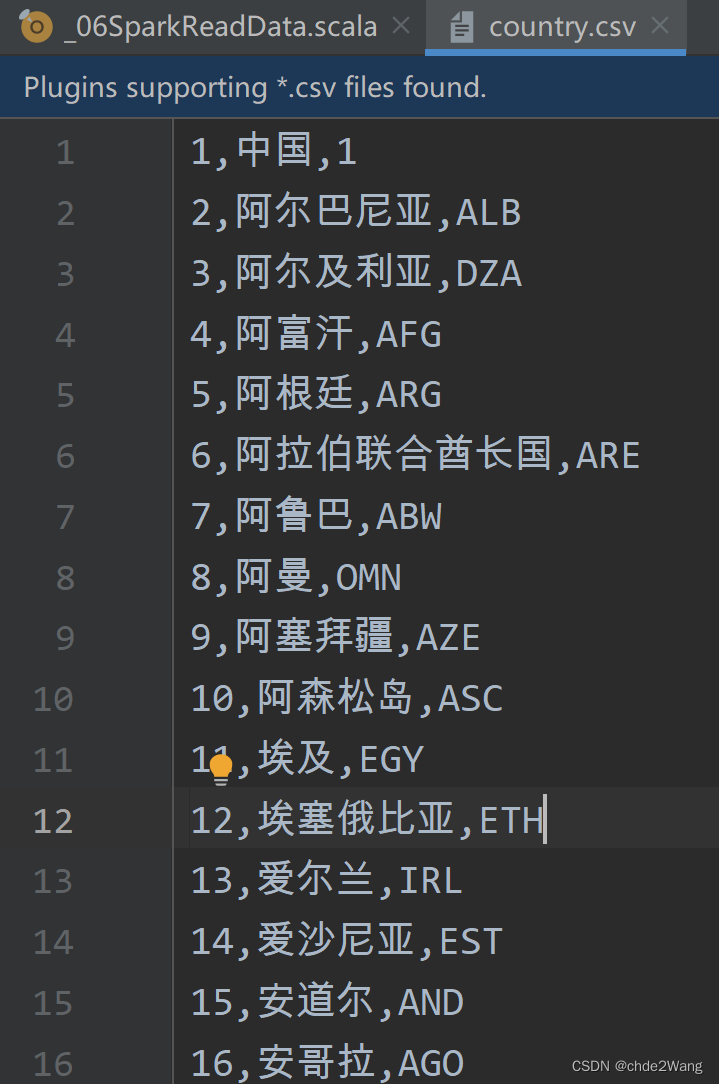
读取代码:
package _02SparkSQL
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}object _06SparkReadData {def main(args: Array[String]): Unit = {val session = SparkSession.builder().appName("SparkReadData").master("local[*]").getOrCreate()val frame = session.read.csv("data/country.csv")frame.printSchema()/**root|-- _c0: string (nullable = true)|-- _c1: string (nullable = true)|-- _c2: string (nullable = true)*/frame.show()/**+---+----------------+---+|_c0| _c1|_c2|+---+----------------+---+| 1| 中国| 1|| 2| 阿尔巴尼亚|ALB|| 3| 阿尔及利亚|DZA|| 4| 阿富汗|AFG|| 5| 阿根廷|ARG|| 6|阿拉伯联合酋长国|ARE|| 7| 阿鲁巴|ABW|| 8| 阿曼|OMN|| 9| 阿塞拜疆|AZE|| 10| 阿森松岛|ASC|| 11| 埃及|EGY|| 12| 埃塞俄比亚|ETH|| 13| 爱尔兰|IRL|| 14| 爱沙尼亚|EST|| 15| 安道尔|AND|| 16| 安哥拉|AGO|| 17| 安圭拉|AIA|| 18|安提瓜岛和巴布达|ATG|| 19| 澳大利亚|AUS|| 20| 奥地利|AUT|+---+----------------+---+*/}}
1.2.3 读取txt数据
txt数据:
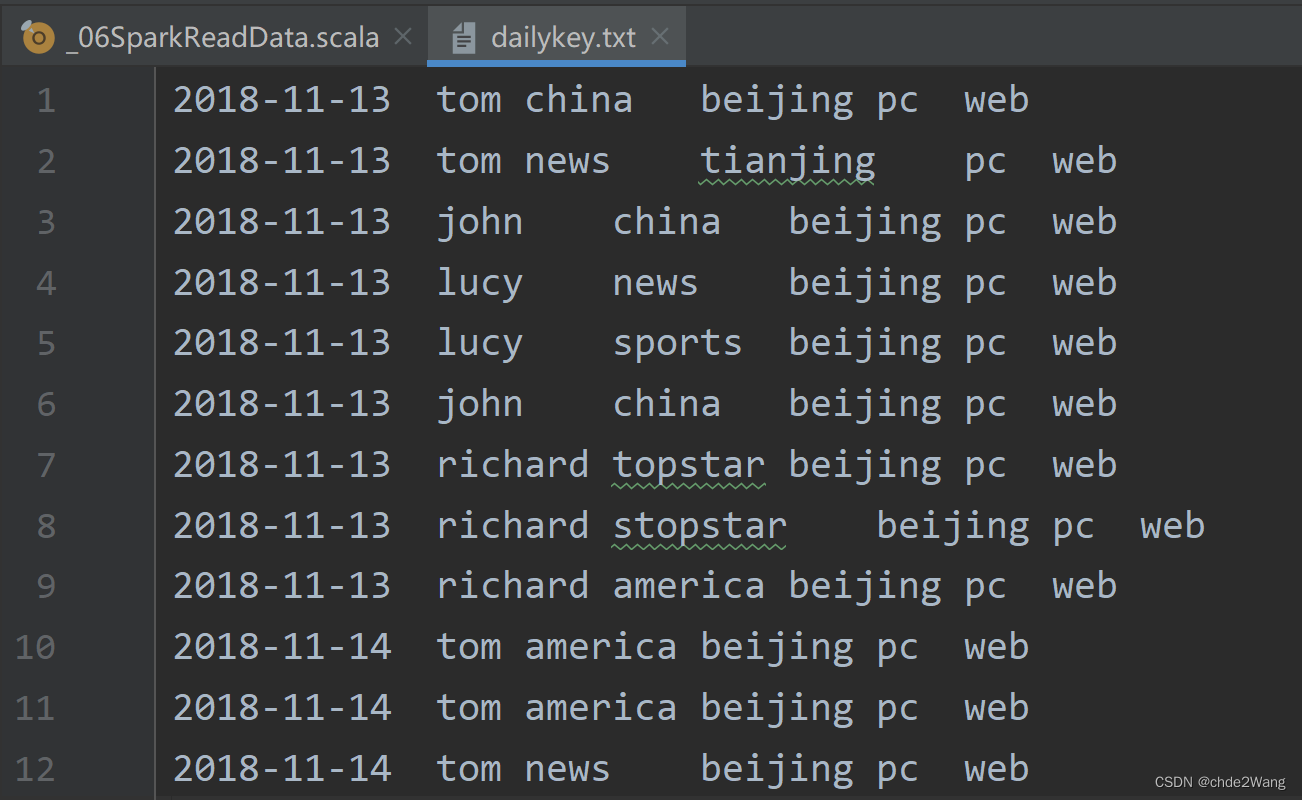
读取代码:
package _02SparkSQL
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}object _06SparkReadData {def main(args: Array[String]): Unit = {val session = SparkSession.builder().appName("SparkReadData").master("local[*]").getOrCreate()val frame = session.read.text("data/dailykey.txt")frame.printSchema()/**root|-- value: string (nullable = true)* */frame.show()/**+--------------------+| value|+--------------------+|2018-11-13\ttom\t...||2018-11-13\ttom\t...||2018-11-13\tjohn\...||2018-11-13\tlucy\...||2018-11-13\tlucy\...||2018-11-13\tjohn\...||2018-11-13\tricha...||2018-11-13\tricha...||2018-11-13\tricha...||2018-11-14\ttom\t...||2018-11-14\ttom\t...||2018-11-14\ttom\t...|+--------------------+* */}}1.2.4 读取parquet数据
package _02SparkSQL
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}object _06SparkReadData {def main(args: Array[String]): Unit = {val session = SparkSession.builder().appName("SparkReadData").master("local[*]").getOrCreate()val frame = session.read.parquet("data/users.parquet")frame.printSchema()/**root|-- name: string (nullable = true)|-- favorite_color: string (nullable = true)|-- favorite_numbers: array (nullable = true)| |-- element: integer (containsNull = true)*/frame.show()/*+------+--------------+----------------+| name|favorite_color|favorite_numbers|+------+--------------+----------------+|Alyssa| null| [3, 9, 15, 20]|| Ben| red| []|+------+--------------+----------------+*/}
}
1.2.5 读取orc数据
package _02SparkSQL
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}object _06SparkReadData {def main(args: Array[String]): Unit = {val session = SparkSession.builder().appName("SparkReadData").master("local[*]").getOrCreate()val frame = session.read.orc("data/student.orc")frame.printSchema()/**root|-- id: string (nullable = true)|-- name: string (nullable = true)|-- age: string (nullable = true)|-- gender: string (nullable = true)|-- course: string (nullable = true)|-- score: string (nullable = true)*/frame.show()/**+---+------+---+------+-------+-----+| id| name|age|gender| course|score|+---+------+---+------+-------+-----+| 12| 张三| 25| 男|chinese| 50|| 12| 张三| 25| 男| math| 60|| 12| 张三| 25| 男|english| 70|| 12| 李四| 20| 男|chinese| 50|| 12| 李四| 20| 男| math| 50|| 12| 李四| 20| 男|english| 50|| 12| 王芳| 19| 女|chinese| 70|| 12| 王芳| 19| 女| math| 70|| 12| 王芳| 19| 女|english| 70|| 13|张大三| 25| 男|chinese| 60|| 13|张大三| 25| 男| math| 60|| 13|张大三| 25| 男|english| 70|| 13|李大四| 20| 男|chinese| 50|| 13|李大四| 20| 男| math| 60|| 13|李大四| 20| 男|english| 50|| 13|王小芳| 19| 女|chinese| 70|| 13|王小芳| 19| 女| math| 80|| 13|王小芳| 19| 女|english| 70|+---+------+---+------+-------+-----+*/}
}1.2.6 读取jdbc数据
package _02SparkSQL
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}object _06SparkReadData {def main(args: Array[String]): Unit = {val session = SparkSession.builder().appName("SparkReadData").master("local[*]").getOrCreate()// 读取jdbc文件val properties = new Properties()properties.put("user","root")properties.put("password","123456")val frame = session.read.jdbc("jdbc:mysql://localhost:3306/mydb1","location-info",properties)frame.printSchema()frame.show()}
}
2 数据的保存
SparkSQL提供了两种方式可以保存数据
2.1 方式一:spark.write.format
- spark.write.format(“保存数据格式”).mode(“存储格式”).save(“存储数据路径”)
- 数据文件格式包括csv、jdbc、json、orc、parquet和textFile。
- 保存数据可以使用SaveMode,用来指明如何处理数据,使用mode()方法来设置
- SaveMode是一个枚举类,其中的常量包括:
| scala/java | Any Language | Meaning |
|---|---|---|
| SaveMode.ErrorifExists(default) | “error”(default) | 如果文件已经存在,则抛出异常 |
| SaveMode.Append | “append” | 如果文件已经存在,则追加 |
| SaveMode.Overwrite | “overwrite” | 如果文件已经存在,则覆盖 |
| SaveMode.Ignore | “ignore” | 如果文件已经存在,则忽略 |
需要注意:在读取jdbc时需要在format和save之间添加多个option进行相应的JDBC参数设置【url、user、password、tablename】save中不用传递路经空参数即可,可以不用设置mode
数据源为Parquet文件时,SparkSQL可以方便的执行所有的操作,不需要使用format
2.1.1 读取orc数据
package _02SparkSQL
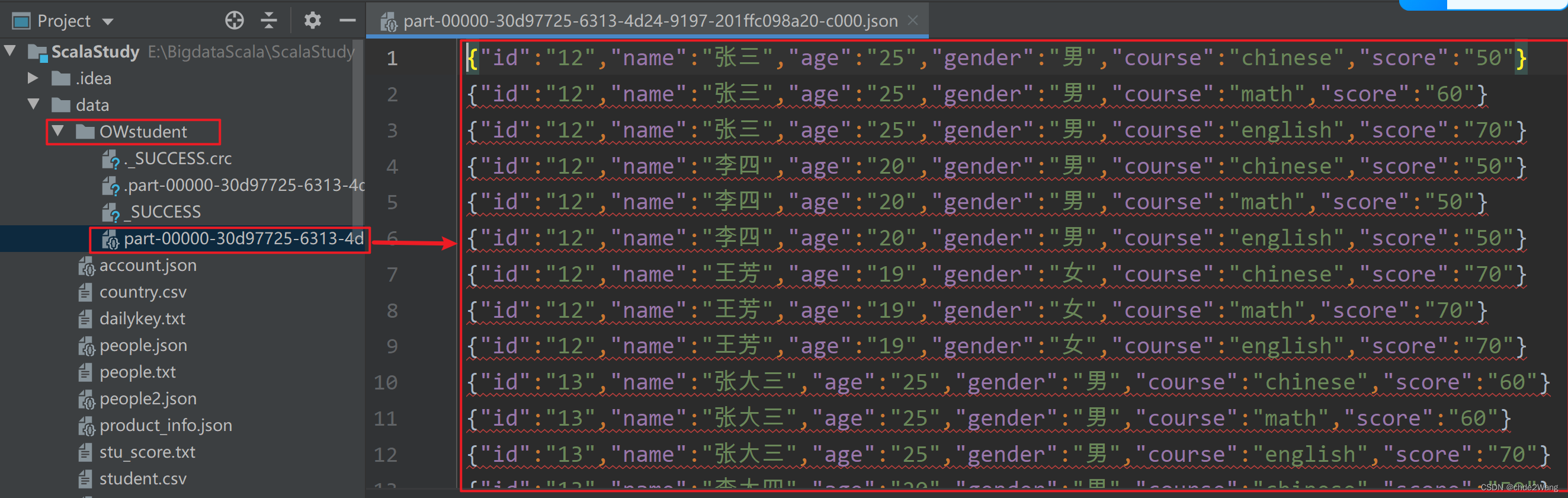
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}object _07SparkWriteData {def main(args: Array[String]): Unit = {//提供SparkSession对象val session = SparkSession.builder().appName("SparkWriteData").master("local").getOrCreate()//先读取数据var frame: DataFrame = session.read.orc("data/student.orc")//保存到某个路径下,OWstudent为文件夹,不需要文件名frame.write.format("json").mode(SaveMode.Overwrite).save("data/OWstudent")session.stop()}
}最后结果为:
2.2 方式二:spark.write.xxx
上述的书写方式太过繁项,所以SparksQL推出了更加便捷的方式:
- spark.write.xxx(“保存数据路径”)
- XXX包括csv、jdbc、json、orc、parquet和text
- 需要注意:在保存jdbc时方法参数为三个分别为【url、tablename、properties对象】,其中properties对象中存储的是【user,password】
- mode可以选择性设置
2.2.1 写入到jdbc数据库中
package _02SparkSQL
import java.util.Propertiesimport org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}object _07SparkWriteData {def main(args: Array[String]): Unit = {//提供SparkSession对象val session = SparkSession.builder().appName("SparkWriteData").master("local").getOrCreate()//先读取数据var frame: DataFrame = session.read.orc("data/student.orc")val properties = new Properties()properties.put("user","root")properties.put("password","123456")frame.write.mode(SaveMode.Append).jdbc("jdbc:mysql://localhost:3306/mydb1","student",properties)

:关系型数据库三范式介绍)

-从协议到抽象基类)










)



