2.6 深度学习主流开源框架
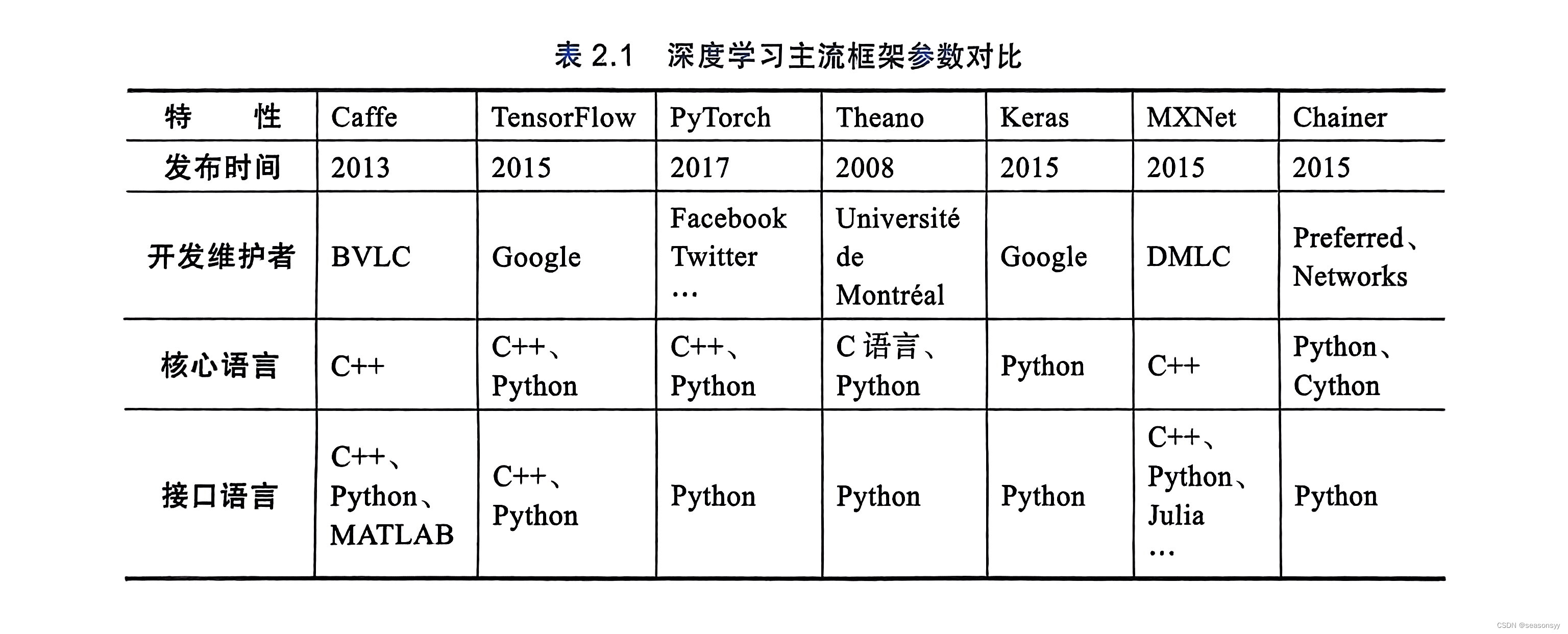
表2.1 深度学习主流框架参数对比
框架关键词总结
| 框架 | 关键词 | 基本数据结构(都是高维数组) |
|---|---|---|
| Caffe | “在工业中应用较为广泛”,“编译安装麻烦一点” | Blob |
| TensorFlow | “安装简单pip” | Tensor |
| Pytorch | “定位:快速实验研究”,“简单”,“灵活” | Tensor |
| Theano | × “用于处理大规模神经网络的训练”,“不支持移动设备”,“不能应用于工业环境”,“编译复杂模型时间非常久” | |
| Keras | “高度模块化”,“适合在探索阶段能快速尝试各种网络结构”,“从CPU上计算切换到GPU加速无需任何代码的改动”,“适用于复杂模型” | |
| MXNet | “轻量级”、“AWS官方推荐的深度学习框架”,“可在小内存上训练深度神经网络模型”,“可在移动设备上运行图像识别等任务” | |
| Chainer | “为复杂神经网络的实现提供了更大的灵活性”,“已在丰田汽车、松下和FANUC 等公司投入使用” |
2.6.1 Caffe简介
Caffe是基于C++语言以及CUDA开发的框架,支持MATLAB、Python接口和命令行,可以直接在GPU和CPU中进行切换,训练效率有保障,在工业中应用较为广泛。
优点:
- 在Caffe中,网络层通过C++定义,网络配置使用Protobu定义,可以较方便地进行深度网络的训练与测试。
- Caffe代码易懂、好理解、搞笑、使用、上手简单,比较成熟和完善,实现基础算法方法快捷,适合工业快速应用与部署。
- Caffe保留所有的有向无向环图,确保能正确的进行前向传播和反向传播,Caffe是一个典型的端到端的机器学习系统。
- √每一个Caffe网络都开始于数据层,结束于损失函数层。
结构:
Caffe通过Blob以四维数组的方式存储和传递数据。
Caffe还提供了一套完整的层类型。一个层(Layer)是一个神经网络层的本质,它采用一个或多个Blob作为输入并产生一个或多个Blob作为输出。
缺点:
-
编译安装稍微麻烦一点(相对于TenorFlow等使用pip一键安装的方式)
-
以Ubuntu16.04为例,官网的安装脚本足够用了,有一些依赖库。
-
装完之后,去Git上复制代码(https://github.com/BVLC/caffe),修改Makefile.config就可以编译安装了。
注意:对于GPU安装,还需要安装CUDA以及NVIDIA驱动
-
关键词:“在工业中应用较为广泛”,“编译安装麻烦一点”
2.6.2 TensorFlow简介
TensorFlow是Google Brain推出的开源机器学习库,与Caffe一样,主要用于深度学习的相关任务
结构:
- TensorFlow中的Tensor就是张量,代表N维数组,与Caffe中的blob是类似的。
- Flow是流,代表基于数据流图的计算。
神经网络的运算过程就是数据从一层流到下一层,TensorFlow更直接地强调了这个过程。
最大特点是计算图,即先定义好图,然后进行运算,因此所有的TensorFlow代码都包含两部分:
- 第一部分:创建计算图。表示计算的数据流,实际上就是定义好一些操作,可以将它看做Caffe中Prototxt的定义过程
- 第二部分:运行会话。执行图中的运算,可以看做Caffe中的训练过程,只是TensorFlow的会话比Caffe灵活很多。因为是Python接口,所以取中间的结果分析和debug等方便很多。
优点:
- 与Caffe相比,TensorFlow的安装简单很多,一个pip命令就可以解决。
- TensorFlow不止局限于神经网络,其数据流式图支持非常自由的算法表达,可以轻松实现深度学习以外的机器学习算法
- 在TensorFlow中定义新的节点时只需要写一个Python函数,如果没有对应的底层运算核,则需要编写C++或者CUDA代码来实现运算操作。
- TensorFlow还支持深度强化学习及其他计算密集的科学计算(如偏微分方程求解等)
缺点:
- TensorFlow采用静态图,先定义好图,然后再Session中运算。图一旦定义好后是不能随意修改的。目前,TensorFlow虽然也引入了动态图机制Eager Execution,只是不如Pytorch直观。
- TensorFlow学习成本高,对新手来说,Tensor、Variable、Session等概念众多,数据读取接口频繁更新,tf.nn、tf.layers、tf.contrib各自重复。
关键词:“安装简单pip”
2.6.3 PyTorch简介
Torch是纽约大学的一个机器学习开源框架,几年前在学术界非常流行。但是由于其初始只支持Lua语言,导致其没有普及。随着Python的生态越来越完善,Facebook人工智能研究院推出了Pytorch并将其开源。
- Pytorch不是简单地封装Torch并提供Python接口,而是对Tensor以上的所有代码进行了重构,同TensorFlow一样,增加了自动求导功能。
- Pytorch的定位是快速实验研究,因此可直接用Python写新层。之后Caffe2被全部并入PyTorch,如今已经成为非常流行的框架。
特点:
-
动态图计算
Pytorch就像是脚本语言,可以随时随地地修改,随处调试,没有一个类似编译的过程,比TensorFlow灵活很多
-
简单
从Tensor到Variable再到nn.Module,是从数据张量到网络的抽象层次的递进
注:在Pytorch中,Tensor的使用与NumPy的数组非常相似,二者可以互转且共享内存。
通过调用torch.cuda.is_available()函数,可以检查Pytorch中是否有可用的CUDA
关键词:“定位:快速实验研究”,“简单”,“灵活”
2.6.4 Theano简介
Theano由蒙特利尔大学Lisa Lab团队开发并维护,它是一个高性能的符号计算及深度学习库,用于处理大规模神经网络的训练。
优点:
- Theano整合了Numpy,可以直接使用ndarray等功能,无需直接进行CUDA编码即可方便地进行神经网络结构设计。【因为其核心是数学表达式编辑器,计算稳定性好,所以可以精确地计算输出值很小的函数(如log(1+x))】
- 支持Linux、MacOS、Windows
缺点:
- 没有底层C++的接口,模型的部署非常不方便,需要以来各种Python库,并且不支持各种移动设备,因此其几乎没有在工业生产环境中应用。
- 在CPU上的执行性能比较差,但在单GPU上的执行效率不错,性能和其他框架类似
- Theano运算时需要将用户的Python代码转换为CUDA代码,再编译为二进制可执行文件,编译复杂模型的时间非常久。
- Theano在导入时也比较慢,而且一旦设定了选择某块GPU,就无法切换到其他设备
关键词:× “用于处理大规模神经网络的训练”,“不支持移动设备”,“不能应用于工业环境”,“编译复杂模型时间非常久”
2.6.5 Keras简介
Keras是一个高度模块化的神经网络库,用Python实现,可以同时运行在TensorFlow和Theano上。
优点:
-
Keras无需额外的文件来定义模型,仅通过编程的方式改变模型结构和调整超参数,旨在让用户进行最快速的原型实验,因此适合在探索阶段快速地尝试各种网络结构。
-
Keras组件都是可插拔的模块,使用时只需要将一个个组件(如卷积层和激活函数等)连接起来即可,在Keras中通过几行代码就能实现MLP,AlexNet的实现也只需要十几行代码。
-
Keras专注于深度学习(Theano和TensorFlow的计算图支持更通用的计算)。同时支持卷积网络和循环网络,支持级联的模型或任意的图结构模型,从CPU上计算切换到GPU加速无需任何代码的改动。
-
节约尝试新网络结构的时间。
Keras底层使用的是Theano或TensorFlow,用Keras训练模型相比于前两者基本没有性能损耗(还可以享受前两者持续开发带来的性能提升),只是简化了编程的复杂度,节约了尝试新网络结构的时间。
即模型越复杂,使用Keras的收益越大,尤其是在高度依赖全职共享、多模型组合和多任务学习等模型上,Keras表现得非常突出。
缺点:
- 但是设计新模块或者新的Layer时则不太方便。
关键词:“高度模块化”,“适合在探索阶段能快速尝试各种网络结构”,“从CPU上计算切换到GPU加速无需任何代码的改动”,“适用于复杂模型”
2.6.6 MXNet简介
MXNet 是DMLC(Distributed Machine Learning Community)开发的一款开源的、轻量级、可移植、灵活的深度学习库,它让用户可以灵活地混合使用符号编程模式和指令式编程模式,以达到效率最大化,目前它已经是AWS官方推荐的深度学习框架。
优点:
-
MXNet是在各个框架中率先支持多GPU 和分布式的框架,同时其分布式性能也非常高。MXNet的核心是一个动态的依赖调度器,支持自动将计算任务并行化到多个GPU 或分布式集群(支持AWS、Azure、Yarn 等)上。
-
基于上层的计算图优化算法不仅加速了符号计算的过程,而且内存占用较小。开启镜像模式之后,甚至可以在小内存的GPU上训练深度神经网络模型,同样可以在移动设备(如Android和iOS)上运行基于深度学习的图像识别等任务。
缺点:
- 训练时间长
MXNet支持多语言封装,基本涵盖所有主流的脚本语言,如MATLAB、JavaScript、Julia、C++、Python 和R 语言等。虽然MXNet构造并训练网络的时间长于高度封装类框架 Keras 和PyTorch,但是明显短于Theano框架。
关键词:“轻量级”、“AWS官方推荐的深度学习框架”,“可在小内存上训练深度神经网络模型”,“可在移动设备上运行图像识别等任务”
2.6.7Chainer 简介
Chainer 是一个由Preferred Networks公司推出并获得英特尔支援,专门为高效研究和开发深度学习算法而设计的开源框架。Chainer使用纯Python 和NumPy提供了一个命令式的API,为复杂神经网络的实现提供了更大的灵活性。
优点:
- 在训练时“实时”构建计算图,非常适合此类复杂神经网络的构建。这种方法可以让用户在每次前向计算时根据条件更改计算图。同时也可以很容易地使用标准调试器和分析器来调试和重构基于Chainer 的代码。
- 支持最新的优化方法、序列化方法以及使用CuPy的由CUDA驱动的更快速的计算方法,目前已在丰田汽车、松下和FANUC 等公司投入使用。
关键词:“为复杂神经网络的实现提供了更大的灵活性”,“已在丰田汽车、松下和FANUC 等公司投入使用”
参考文献:
《深度学习之图像识别 核心算法与实战案例 (全彩版)》 言有三 著
出版社:清华大学出版社
出版时间:2023年7月第一版(第一次印刷)
ISBN:978-7-302-63527-7

)







)

)



![[AIGC codze] Kafka 的 rebalance 机制](http://pic.xiahunao.cn/[AIGC codze] Kafka 的 rebalance 机制)



