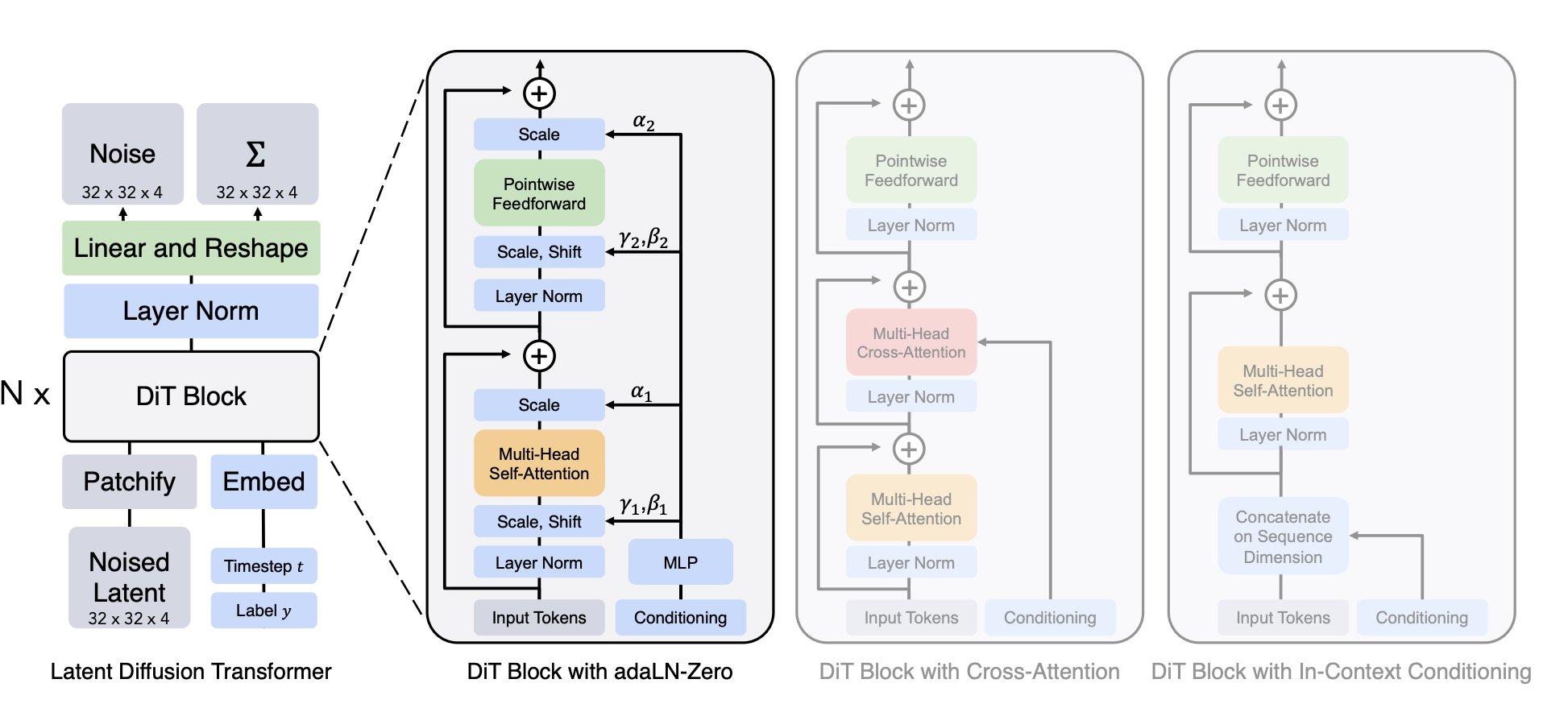
问:Sora 和之前 Runway 那些在架构上有啥区别呢?
答:简单来说 Runway 是基于扩散模型(Diffusion Model)的,而 Sora 是基于 Diffusion Transformer。
Runway、Stable Diffusion 是基于扩散模型(Diffusion Model),扩散模型(Diffusion Model)的训练过程是通过多个步骤逐渐向图片增加噪点,直到图片变成完全无结构的噪点图片,然后在生成图片的时候,基于一张完全噪点的图片,逐步减少噪点,直到还原出一张清晰的图片。
文本模型像 GPT-4 则是 Transformer 模型。Transformer 则是一套编码器和解码器的架构,将文本编码成数字向量,然后解码的时候从数字向量还原出文本。
Sora 则是一个融合了两者的 Diffusion Transformer 模型。通过 Transformer 的编码器 - 解码器架构处理含噪点的输入图像,并在每一步预测出更清晰的图像版本。编码器负责对含噪点的输入进行编码,而解码器则负责生成更清晰图像的预测。
GPT-4 被训练以处理一串 Token,并预测出下一个 Token。Sora 不是预测序列中的下一个文本,而是预测序列中的下一个“Patch”。
在文本预测生成中,基本单位是 Token,Token 很好理解,就是一个单词或者单词的一部分。Patch 的概念相对不那么好理解,不过今天看到一篇文章,作者举了个很好的例子。
想象一下《黑暗骑士》的电影胶片,将一卷胶片绕在一个金属盘上,然后挂在一个老式电影院的投影机上。
你把电影从盘中展开,然后剪下最前面的 100 帧。你挑出每一帧——这里是小丑疯狂大笑,那里是蝙蝠侠痛苦的表情——并进行以下不同寻常的操作:
你拿起一把 X-acto 精细刻刀,在第一帧电影胶片上剪出一个变形虫状的图案。你像处理精密仪器一样小心翼翼地用镊子提取这片形似变形虫的胶片,然后安全地保存起来。之后,你处理下一帧:在接下来的胶片上切出同样位置、同样形状的变形虫图案。你再次用镊子小心地取出这个新的变形虫形状的胶片——形状与前一个完全相同——并将其精确地放置在第一个之上。你这样做,直到完成所有的 100 帧。
你现在有了一个色彩斑斓的变形虫,沿着 Y 轴扩展。这是一座可以通过投影机播放《黑暗骑士》的小片段的胶片塔,就好像有人在投影机前握着拳头,只让电影的一小部分影像从拳心通过。
然后,这座胶片塔被压缩并转化为所谓的“Patch”——一种随时间变化的色块。
Patch 的创新之处——以及 Sora 之所以显得如此强大——在于它们让 OpenAI 能够在大量的图像和视频数据上训练 Sora。想象一下从每一个存在的视频中剪出的 Patch——无尽的胶片塔——被堆叠起来并输入到模型中。
以前的文本转视频方法需要训练时使用的所有图片和视频都要有相同的大小,这就需要大量的预处理工作来裁剪视频至适当的大小。但是,由于 Sora 是基于“Patch”而非视频的全帧进行训练的,它可以处理任何大小的视频或图片,无需进行裁剪。
因此,可以有更多的数据用于训练,得到的输出质量也会更高。例如,将视频预处理至新的长宽比通常会导致视频的原始构图丢失。一个在宽屏中心呈现人物的视频,裁剪后可能只能部分展示该人物。因为 Sora 能接收任何视频作为训练输入,所以其输出不会受到训练输入构图不良的影响。
在结合前面提到的 Diffusion Transformer 架构,OpenAI 可以在训练 Sora 时倾注更多的数据和计算资源,从而得到令人惊叹的效果。
另外 Sora 刚发布视频时,能模拟出咖啡在杯子里溅出的液体动力学,以至于有人以为是连接了游戏引擎,但实际上 Sora 还是基于生成式模型,这是因为 Sora 在训练时,使用了大量的视频数据,这些视频中包含了大量的物理规则,所以 Sora 能够模拟出液体动力学。这类似于 GPT-4 在训练时,使用了大量的代码来作为训练数据,所以 GPT-4 能够生成代码。
有两篇论文: 《Scalable Diffusion Models with Transformers》https://arxiv.org/abs/2212.09748 《Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution》https://arxiv.org/abs/2307.06304
包含更多专业细节。
顺便说一下,两篇论文好像都来自 Google,并且似乎 Sora 项目是在这两篇论文发表后才启动的。
还有电影 + 变形虫的例子来自《How Sora Works (And What It Means)》 How Sora Works (And What It Means)


![[AIGC codze] Kafka 的 rebalance 机制](http://pic.xiahunao.cn/[AIGC codze] Kafka 的 rebalance 机制)











-Linux ARM驱动编程第五天-ARM Linux编程之设备节点 (物联技术666))
)



