面向磁盘的架构
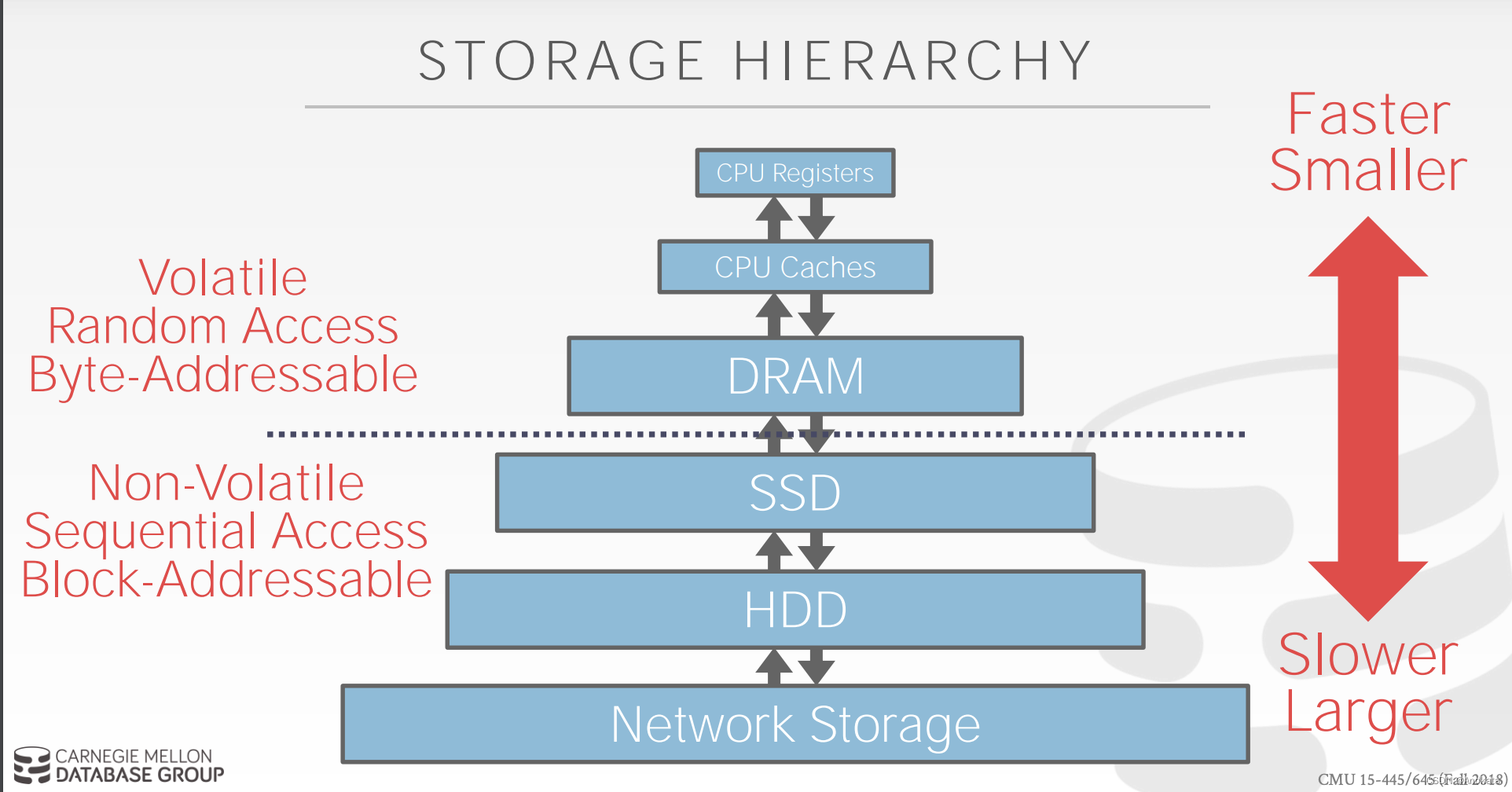
DBMS 假定数据库的主要存储位置位于非易失性磁盘【non-volatile disk】上。
DBMS 的组件管理非易失性【non-volatile】和易失性【volatile】存储之间的数据移动。
为了理解来回移动数据的影响,我们首先要先理解存储层次结构是什么样的。
存储层次【storage hierarchy】
顺序访问 VS 随机访问
HDD 上的随机访问比顺序访问慢得多。
传统的 DBMS 旨在最大化顺序访问。
- 算法尝试减少随机页的写入次数,以便数据存储在连续的块中。
- 同时分配多个页面称为区段【extent】。
为什么不使用OS能力
可以使用 mmap 将文件的内容映射到进程的地址空间。
操作系统负责移动数据,将文件页面移入和移出内存。
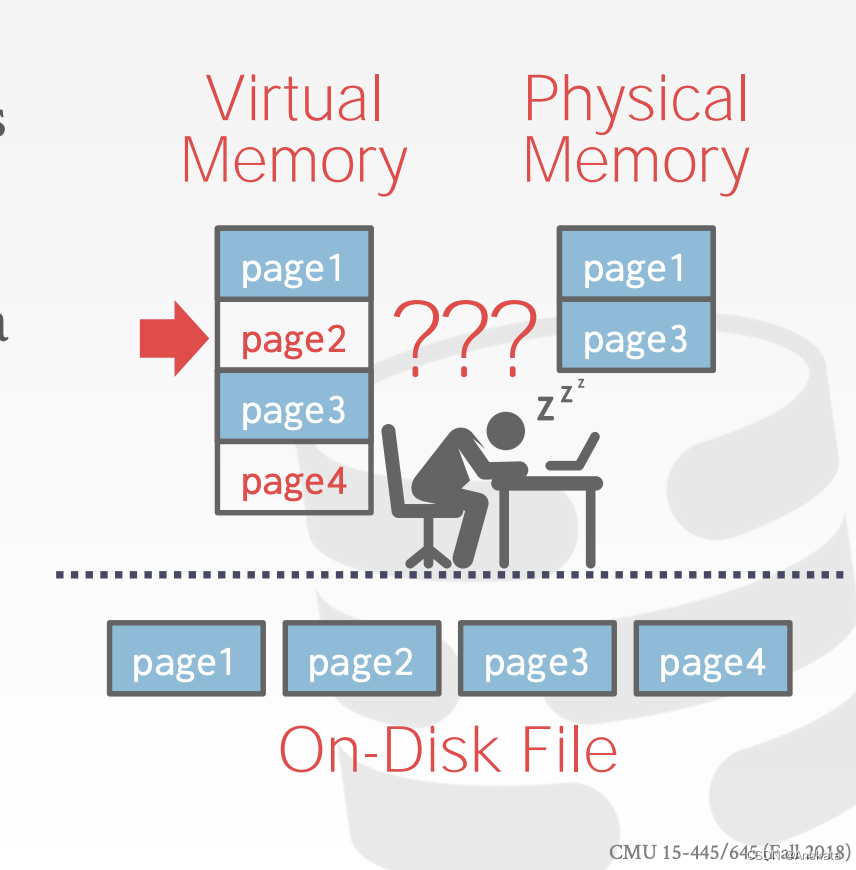
如果我们允许多个线程访问 mmap 文件,以隐藏页面错误【page fault】导致的停顿,这会怎么样?
这种方案对于只读访问来说已经足够好了。但是当有多个写入者时,这就很复杂了……
这个问题有一些解决方案:
→ madvise:告诉操作系统您希望如何读取某些页面。
→ mlock:告诉操作系统某些内存范围不能被换出【paged out】。
→ msync:告诉操作系统将内存范围刷新【flush】到磁盘。
DBMS(几乎)总是希望自己控制事情,并且可以在这方面做得更好。
→ 以正确的顺序将脏页【dirty page】刷新到磁盘。
→ 专门的预取【Specialized prefetching】。
→ 缓冲区替换策略。
→ 线程/进程调度。
操作系统不是你的朋友。
数据库存储面临的问题
问题1:DBMS如何在磁盘上的文件中表示数据库。
问题2:DBMS如何管理其内存并从磁盘来回移动数据。
本节课我们只讨论第一个问题。
今天的议程包括:
- 文件存储【File Storage】
- 页面布局【Page Layout】
- 页面布局【Page Layout】
文件存储
DBMS 将数据库存储为磁盘上的一个或多个文件。而操作系统对这些文件一无所知。
→ 可以从操作系统获得各种文件保护机制
→ 20 世纪 80 年代的早期系统在原始存储上使用自定义“文件系统”,但是这个代价太大,目前很少有用的
存储管理
存储管理器【storage manager】负责维护数据库的文件。
它将文件组织为页【pages】的集合。
→ 跟踪读取/写入页面的数据。
→ 跟踪可用空间。
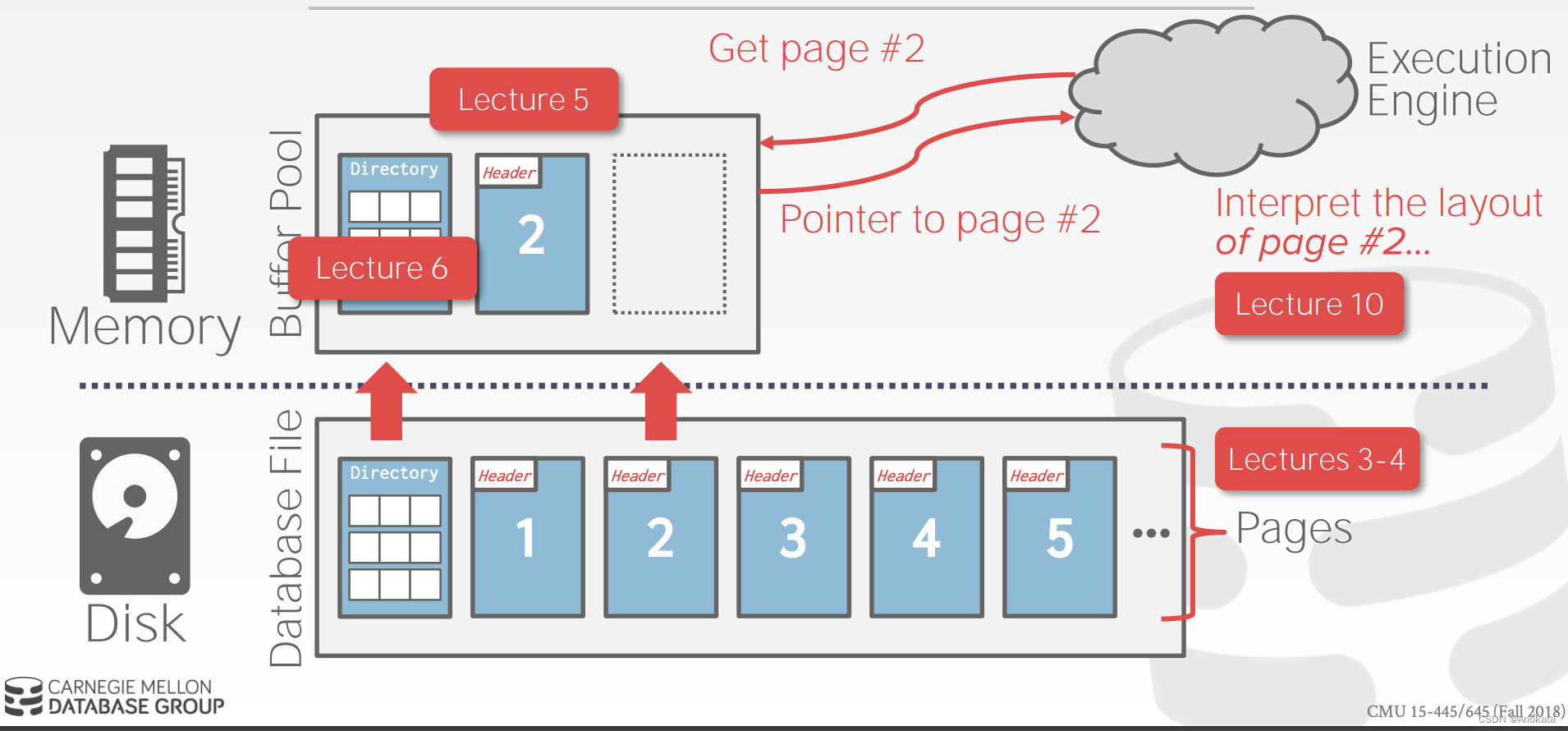
数据库页
页【page】是固定大小的数据块【a fixed-size block of data】。
→ 它可以包含元组、元数据、索引、日志记录……
→ 大多数系统不混合页面类型。
→ 有些系统要求页面是独立的/自包含【self-contained】的。
每个页都有一个唯一的标识符。
→ DBMS 使用间接层将页 ID 映射到物理位置。
注:我们在访问时只会制定要访问第几页,存储管理器负责解释页ID为具体的物理位置。
DBMS 中存在三种不同的“页”概念:
→ 硬件页面(通常为 4KB)
→ 操作系统页面(通常为 4KB)
→ 数据库页 (1-16KB)
硬件页大小是它可以保证的,我称之为故障安全写入【fail safe write】,你让它写一个页面,而这个页面在硬件上的大小是4kb,它保证要么全部写入,要么全部未写入。因此对于mysql,它使用16kb的页,而底层硬件只支持4kb的故障安全写入,因此必须提供额外的机制老保障数据正确写入。
页存储架构
不同的 DBMS 以不同的方式管理磁盘上文件中的页面。
→ 堆文件组织【Heap File Organization】
→ 顺序/排序文件组织【Sequential / Sorted File Organization】
→ 散列文件组织【Hashing File Organization】
在这个层次结构中,我们不需要知道页面内部是什么内容。
数据库堆
堆文件是一个无序的页面集合,其中元组以随机顺序存储。
→获取/删除页面
→还必须支持遍历所有页面。
需要元数据来跟踪哪些页面存在,哪些页面有空闲空间。
表示堆文件的两种方法:
→链表【linked list】
→页面目录【page dictionary】
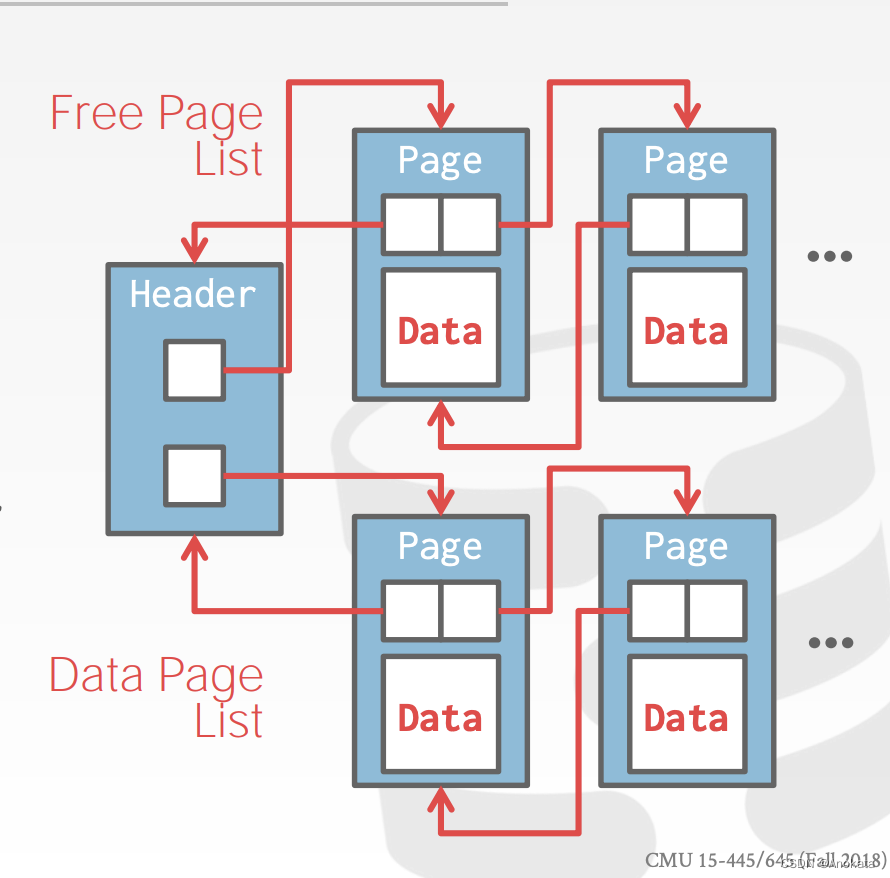
链表堆
在文件的开头维护一个标头页【header page】,其中存储了两个指针:
→ 空闲页列表【free page list.】的 HEAD。
→ 数据页列表【data page list】的 HEAD。
每个页都会跟踪其自身的空闲槽数。
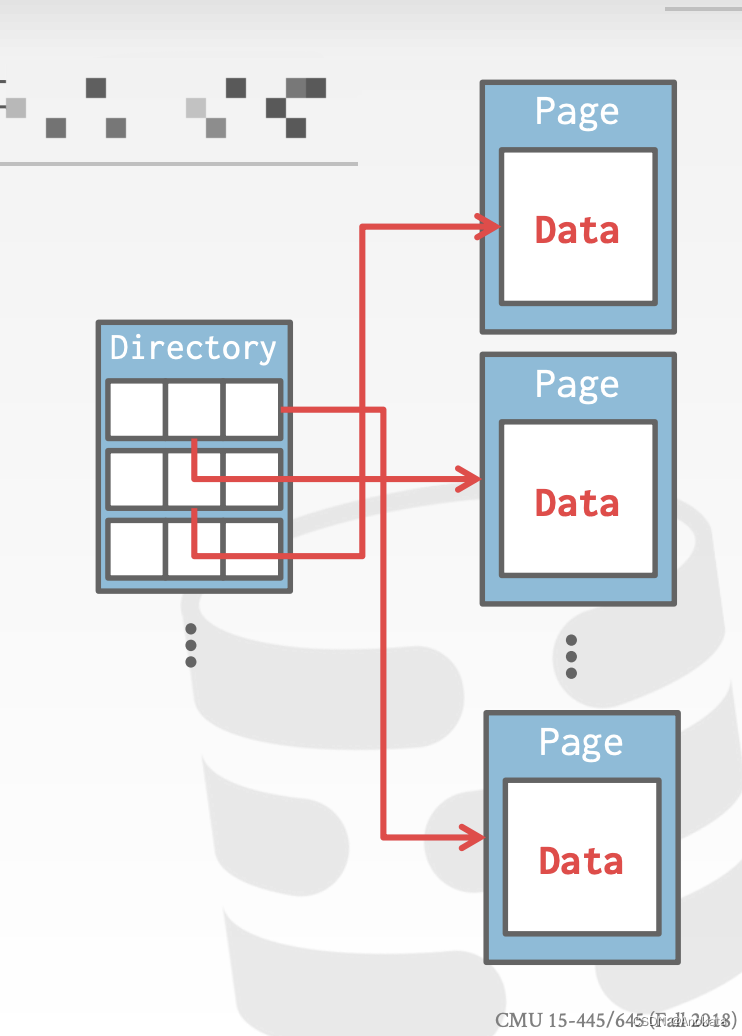
页目录
DBMS 维护特殊页【special pages 】来跟踪数据库文件中数据页【data pages】的位置。
该目录【directory】还记录每页的空闲槽【slot】数。
DBMS 必须确保目录页【directory pages】与数据【data pages】页同步。
页面布局
页头
每个页【page】都包含有关页内容的元数据标题。
→ 页大小【page size】
→ 校验和【Checksum】
→ 数据库管理系统版本【DBMS Version】
→ 事物可见性【Transaction Visibility】
→ 压缩信息【Compression Information】
某些系统要求页是独立/自包含的(例如 Oracle,其他很独多都不支持)。
页布局
对于任何页面存储架构,我们现在都需要了解如何组织存储在页面内部的数据。
→ 我们仍然假设我们只存储元组(索引或者日志记录也存储在页看里,稍后会单独讲)。
两种方法:
→ 面向元组【Tuple-oriented 】
→ 日志结构【Log-structured】
TUPLE STORAGE
如何在页面中存储元组?
稻草人想法:跟踪页面中元组的数量,然后将新元组附加到末尾。
→如果我们删除一个元组会发生什么?
→如果我们有一个可变长度属性会发生什么?

slotted页
最常见的布局方案称为slotted页。
槽数组【 slot array 】将“槽【slots】”映射到元组的起始位置偏移。
头文件【header】负责跟踪:
→ 已使用槽位的数量
→ 最后使用的槽位的起始位置的偏移量
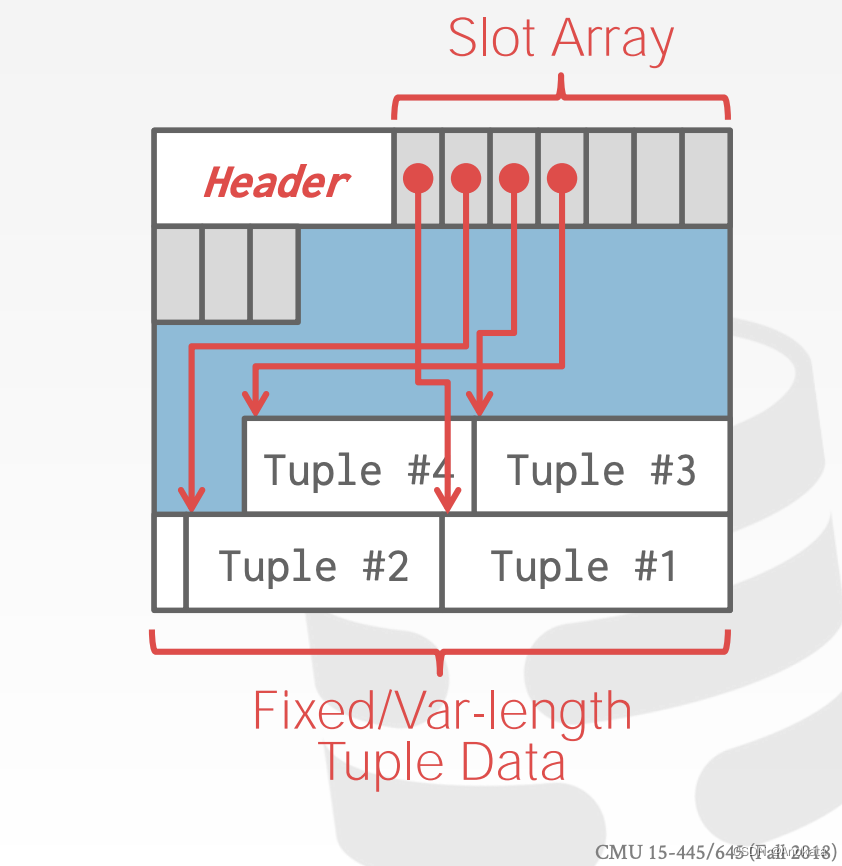
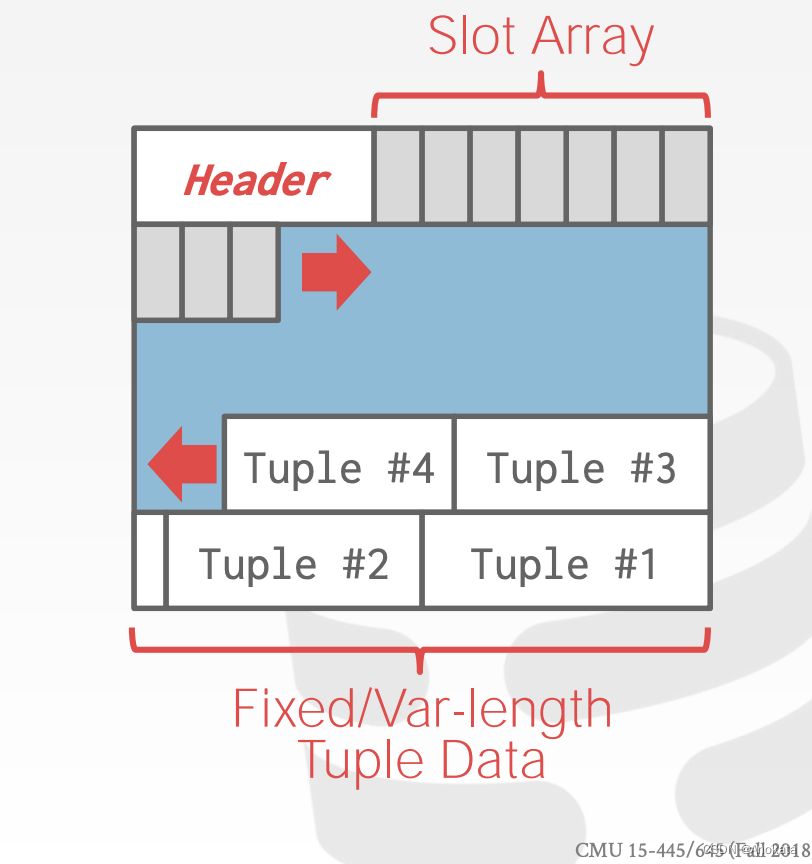
需要注意的是,槽数组与元组是相对的增长
日志结构文件组织【LOG-STRUCTURED FILE ORGANIZATION】
DBMS 不存储页中的元组,而是仅存储日志记录。
系统将日志记录附加到文件中,该文件记录了数据库如何被修改的:
→ 插入【Inserts】存储的是整个元组。
→ 删除【Delete】是将元组标记为已删除。
→ 更新【Updates】仅包含已修改属性的增量【delta】。

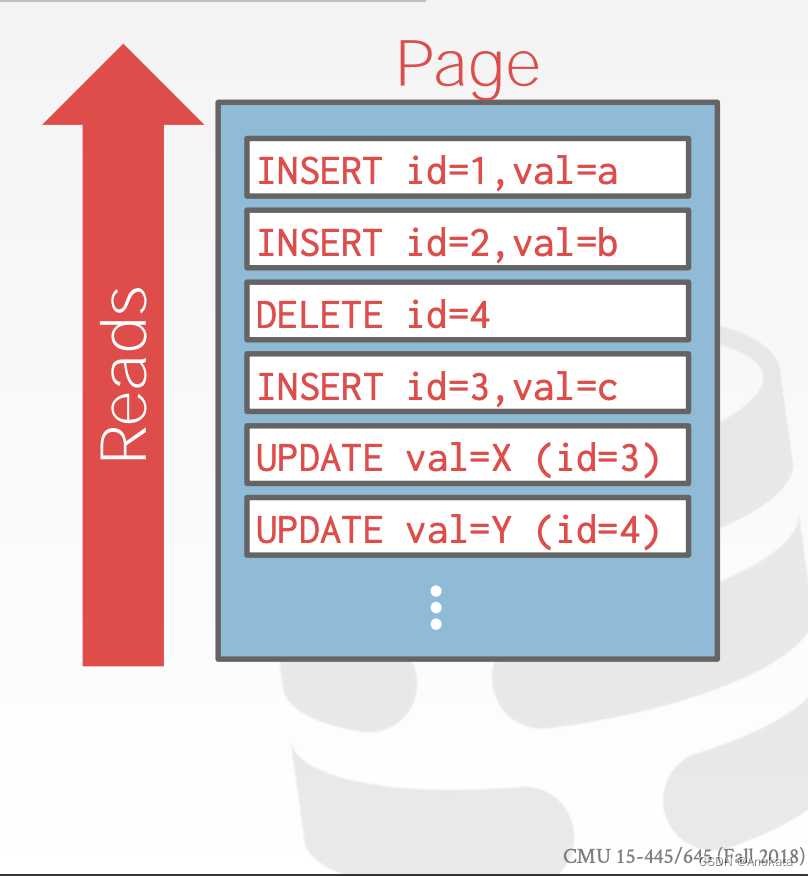
为了读取数据库中的记录,DBMS 向后扫描日志并“重新创建”元组以获得查找所需内容。
同时,构建索引以允许其跳转到日志中的指定位置。
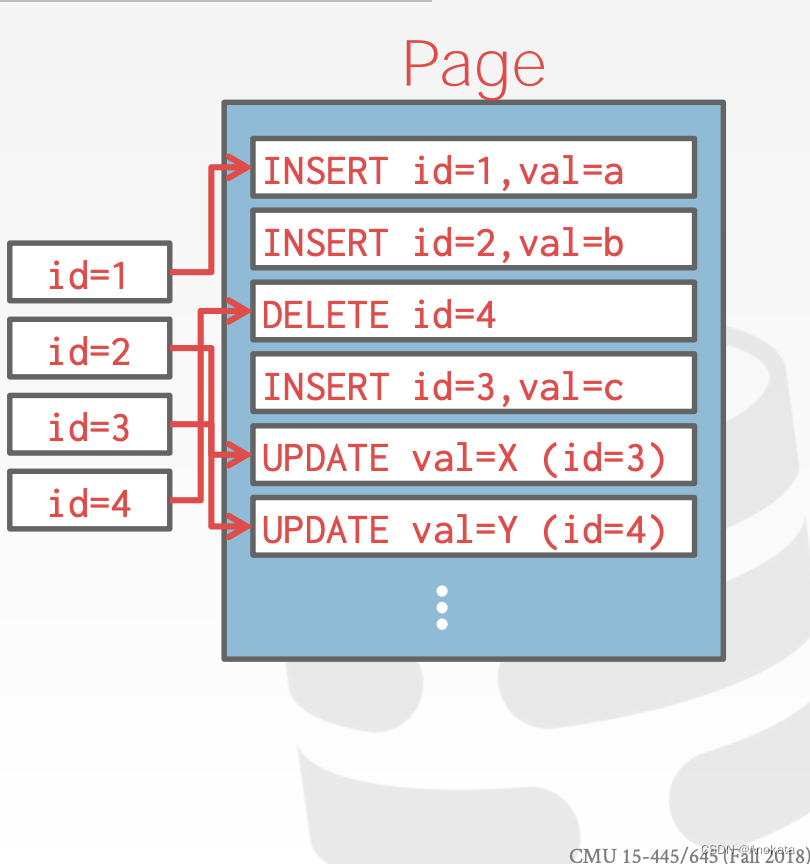

周期性的压缩文件,压缩通过删除不必要的记录将较大的日志文件合并为较小的文件。
Level Compaction
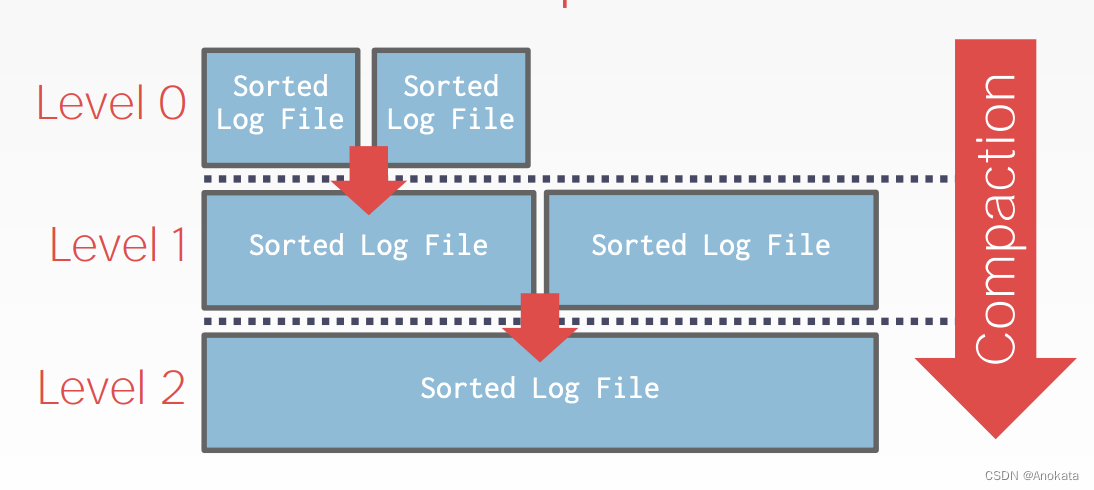
所有的写操作首先在这些日志文件【Sorted Log File】中结束,然后在某个时候,当您写入一定数量的文件时,您希望压缩它们并将它们组合成一个更大的排序日志文件【Sorted Log File】,并将它们放入下一级
Universal Compaction
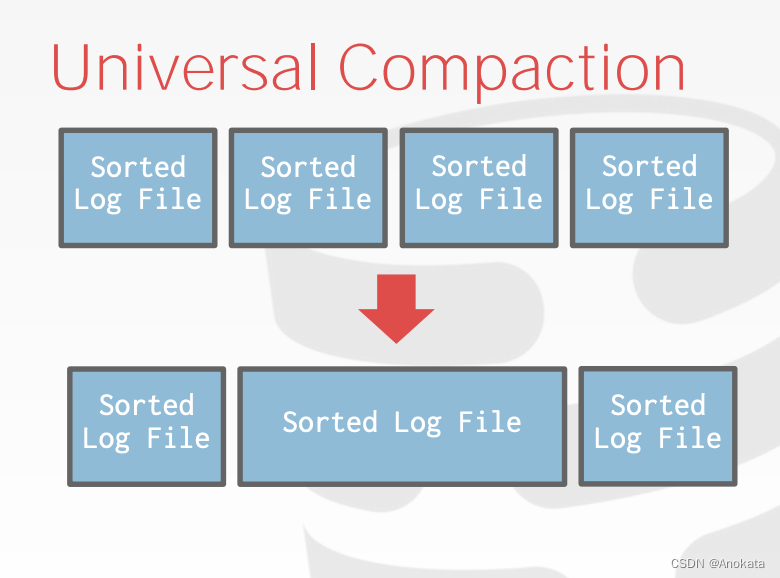
有一个单一的层次,基本上你要做的就是把两个不同的页面在空间上彼此相邻,然后你把它们合并成一个文件。
元组布局
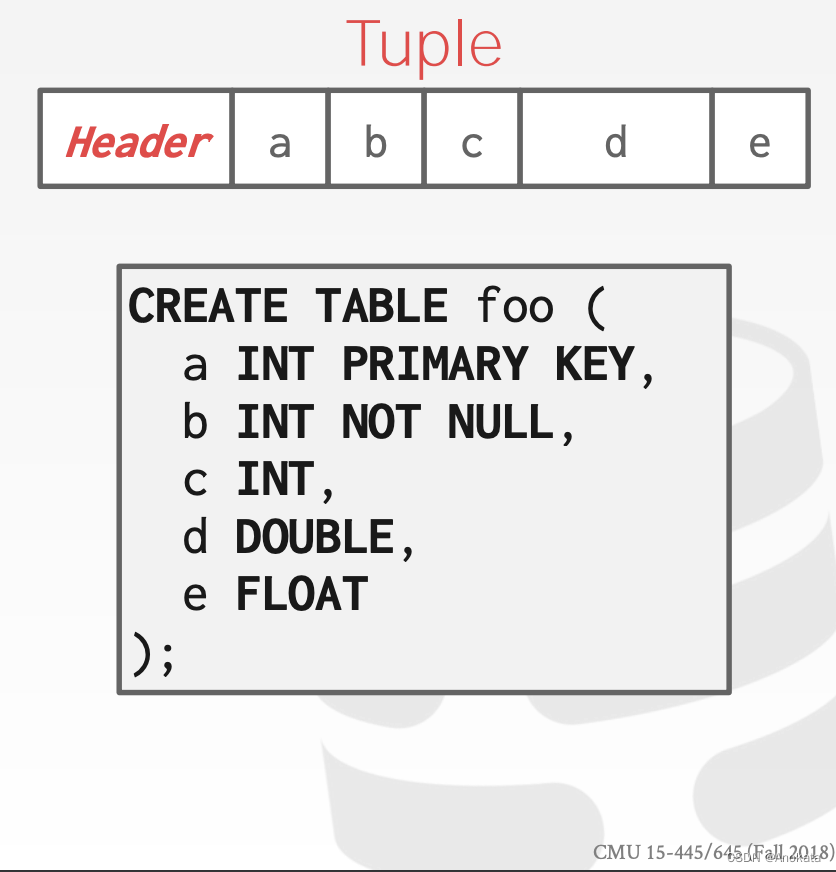
元组【tuple】本质上是一个字节序列。DBMS 的工作是将这些字节解释为属性类型【attribute types】和值【value】。
DBMS 的目录【catelog】包含关于表的模式信息【schema information】,系统使用这些表【schema】来确定元组【tuple】的布局。
元组头
每个元组都有一个头【header】,其中包含关于它的元数据。
→ 可见性信息(并发控制,即当前哪个事物正在读或者写该元组)
→ NULL 值的位图【bit map】。
我们不需要存储关于模式【schema】的元数据。
元组数据
属性【attribute】通常按照您在创建表时指定的顺序来存储。
这样做是出于软件工程的原因。
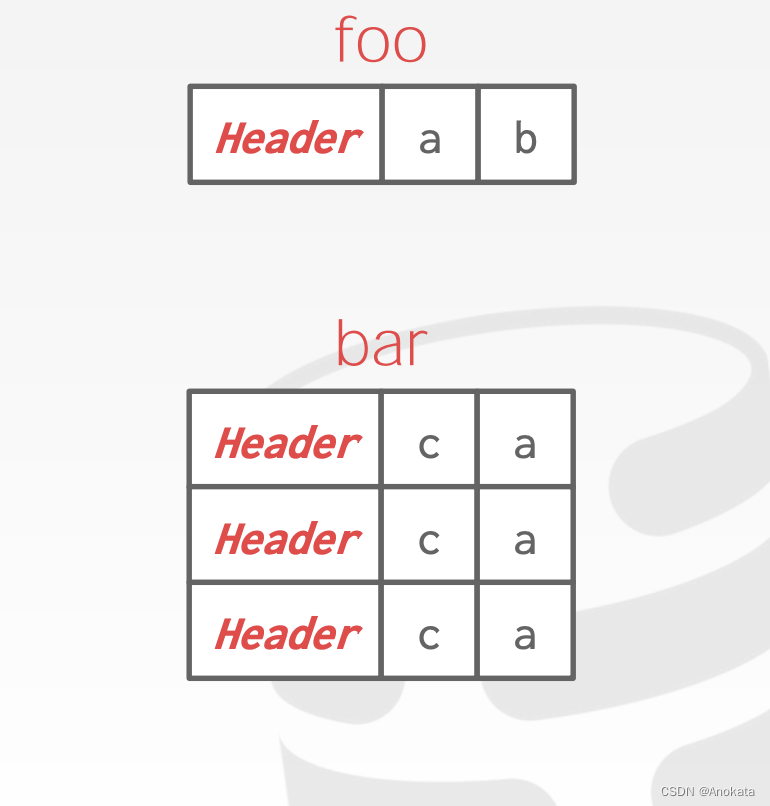
我们在 CMU 的新 DBMS 中自动重新排序属性……
通常,物理布局与内存布局可以不一致(物理层面你可以基于任何优化的目的而重新排排序属性,但是在逻辑层面我们希望可以看到一个与模式定义一致的布局),但是绝大部分的数据库都采用的都是一致的布局顺序(除了列式存储之外),这样会更简单。虽然某些内存数据库会对内存布局做某些重新组织,实现缓存对其,以达到性能优化的目的,但是对于磁盘存储而言,我们只是从磁盘中读取4kb的页,因此页是否对其对性能并无特别大的影响。
DENORMALIZED TUPLE DATA
可以对相关元组进行物理反规范化(例如“预连接”)并将它们一起存储在同一页【page】中。
→ 可能减少常见工作负载模式的 I/O 量。
→ 可能会使更新成本更高。
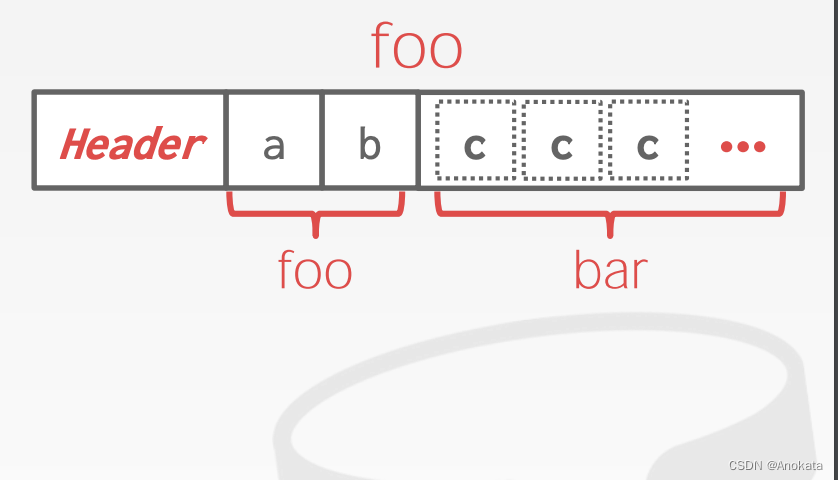
记录ID
DBMS 需要一种方法来跟踪各个元组。每个元组都分配有一个唯一的记录标识符。
→ 最常见的方法:page_id + 偏移量/槽位【offset/slot】,很多数据库在应用层面暴露这个信息,postgrep里叫ctid,oracle里叫rowid
→ 还可以包含文件位置信息。
应用程序不能依赖这些 id 来表示任何含义。
**面向磁盘的架构【DISK-ORIENTED ARCHITECTURE】
DBMS 假定数据库的主要存储位置位于非易失性磁盘上。
DBMS 的组件管理非易失性和易失性存储之间的数据移动。
数据表示
INTEGER/BIGINT/SMALLINT/TINYINT
→ C/C++ 表示
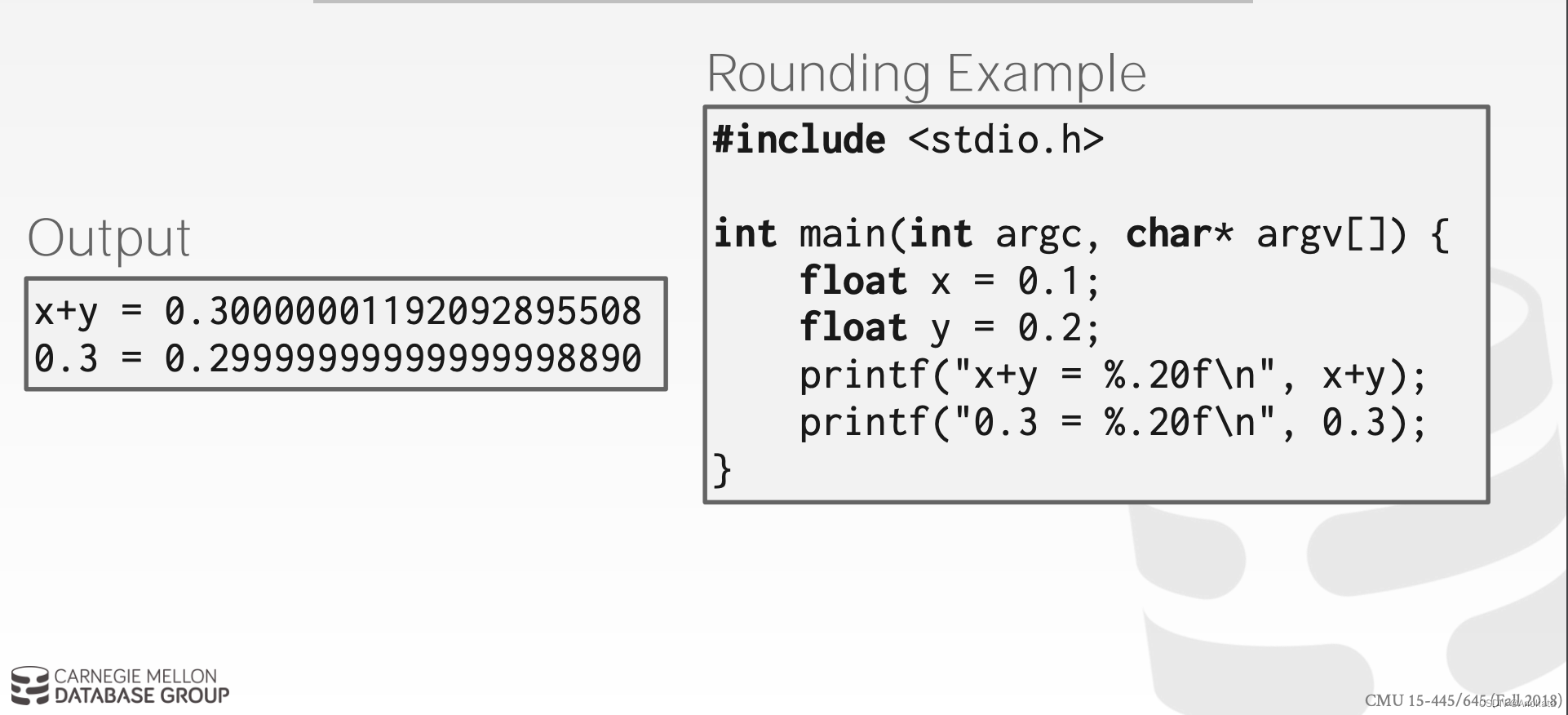
FLOAT/REAL vs. NUMERIC/DECIMAL
→ IEEE-754 Standard / Fixed-point Decimals
VARCHAR/VARBINARY/TEXT/BLOB
→ 带有长度的头【header】,后面跟数据字节。
TIME/DATE/TIMESTAMP
→ 从Unix纪元开始的32/64位整数(微)秒数
可变精度数字【VARIABLE PRECISION NUMBERS】
使用“本机”C/C++ 类型的不精确、可变精度的数值类型。
按照 IEEE-754 的规定直接存储。
通常比任意精度数字更快。
→ 示例:FLOAT【浮点型】, REAL/DOUBLE【实数/双精度】
固定精度数字【FIXED PRECISION NUMBERS】
具有任意精度和小数位数的数字数据类型。 当舍入误差不可接受时使用。
→ 示例:NUMERIC, DECIMAL
通常以精确的、可变长度的二进制表示形式存储,并附带额外的元数据。
→ 类似于 VARCHAR ,但不存储为字符串
栗子:Postgres
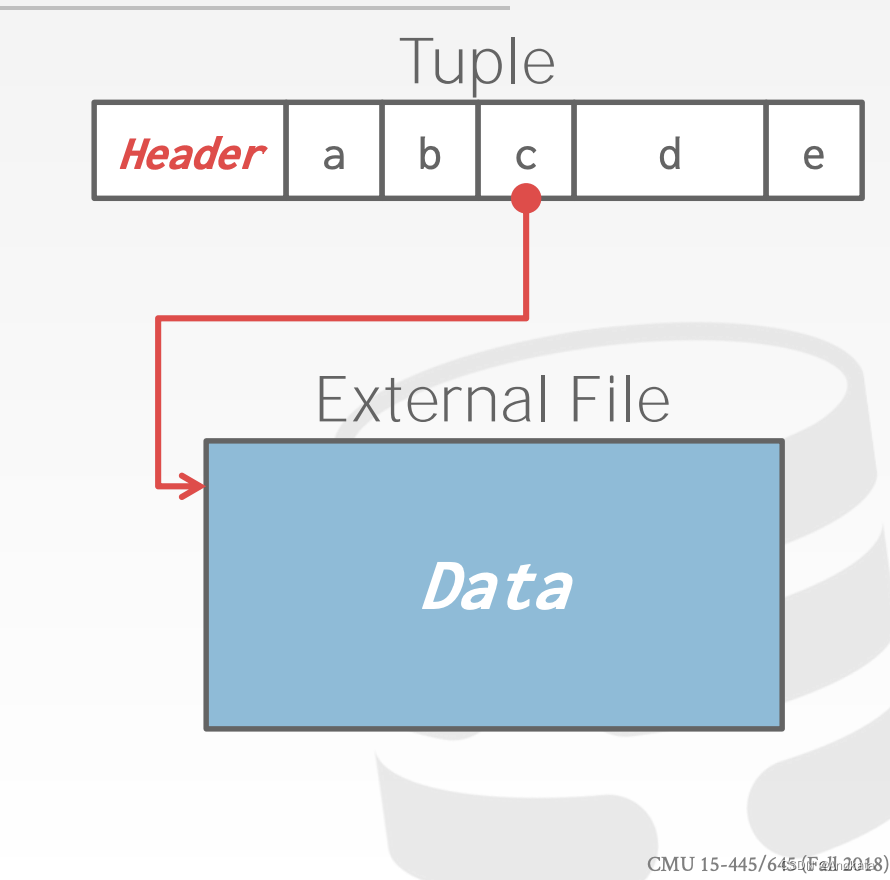
Large Value
大多数 DBMS 不允许元组超过单个页的大小。
为了存储大于页的值,DBMS 使用单独的溢出存储页【overflow storage pages】。
→ Postgres:TOAST (>2KB)
→ MySQL:Overflow(> 页大小的 1/2)

外部值存储【EXTERNAL VALUE STORAGE】
有些系统允许您在外部文件中存储非常大的值。被视为 BLOB 类型。
→ Oracle:BFILE 数据类型
→ 微软:FILESTREAM 数据类型
DBMS 无法操作外部文件的内容(这也是与前面大值存储不同的地方)。
→ 无持久性保护。
→ 无事物保护。
SYSTEM CATALOGS
DBMS 在其内部目录【catalog】中存储关于数据库的元数据,我们可以通过解释这些字节序列,来了解数据库,所以系统目录是关于数据的内部元数据。
- 表【table】、列【column】、索引【indexes】、视图【views】
- 用户和权限
- 内部统计数据
几乎每个DBMS都将自己的数据库目录存储在自己的数据库中(mysql的information_schema):
- 围绕元组包装对象抽象
- 用于“引导【bootstrapping】”目录表的专用代码
您可以查询 DBMS 内部的 INFORMATION_SCHEMA 目录,以获得关于数据库的信息。
- ANSI 标准的只读视图集,提供关于数据库中所有表、视图、列和过程的信息
各个 DBMS 还具有检索此信息的非标准快捷方式。
结论:
关系模型没有指定我们必须将元组的所有属性一起存储在单个页【page】中。
对于某些工作负载【workloads】来说,这实际上可能不是最佳布局。
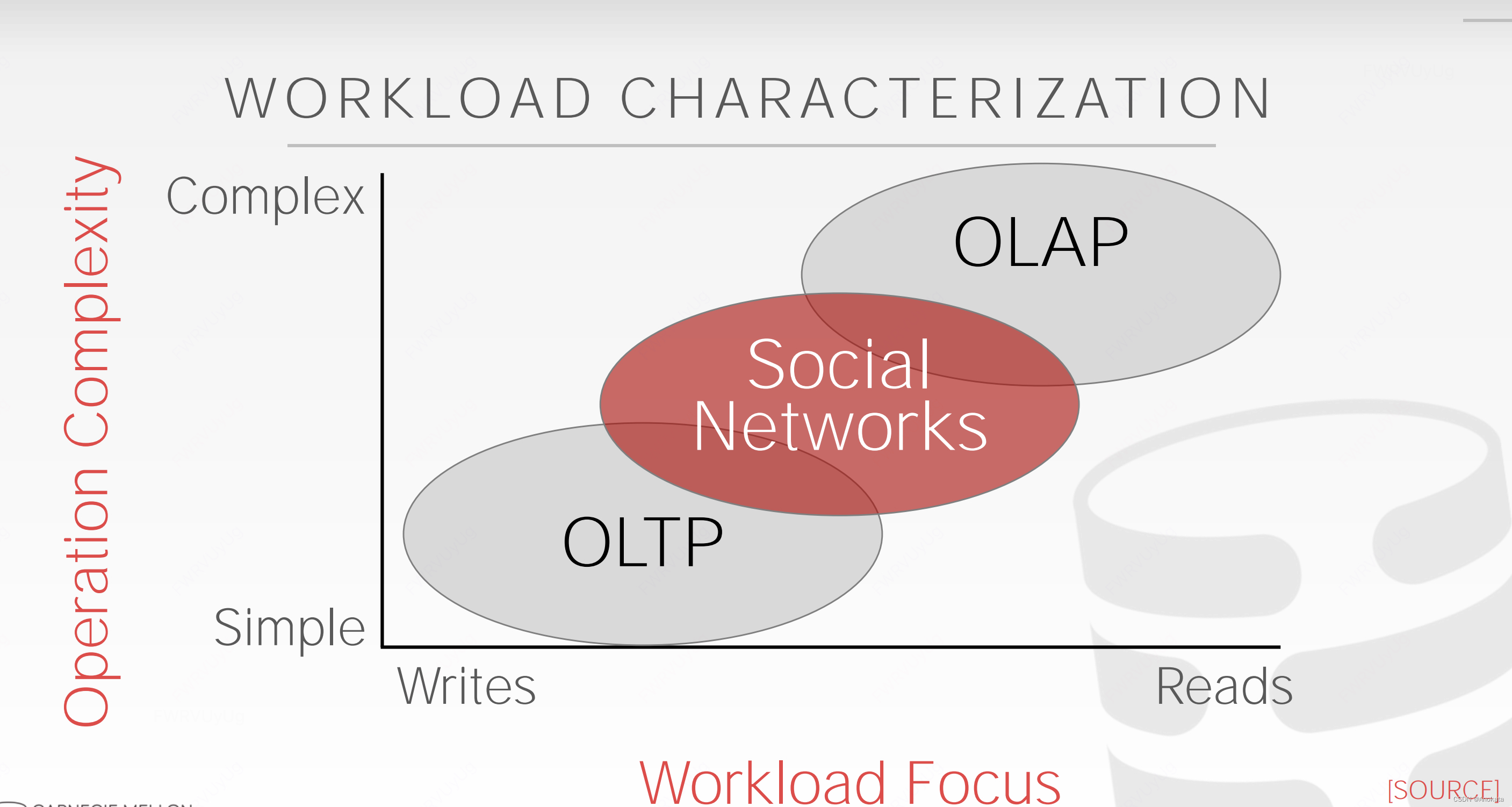
OLTP
在线交易处理【On-line Transaction Processing】:读取/更新与数据库中单个实体相关的少量数据的简单查询。
这通常是人们首先构建的应用程序类型。
OLAP
在线分析处理【On-line Analytical Processing:】: 读取跨越多个实体的大部分数据库的复杂查询。
您可以根据从 OLTP 应用程序收集的数据执行这些工作负载。
工作负载特征
DATA STORAGE MODELS
DBMS可以以不同的方式存储元组,这些不同的方式更适合 OLTP 或 OLAP 工作负载。
本学期到目前为止,我们一直在假设n元存储模型(又称行存储)。N-ARY STORAGE MODEL (NSM)
N-ARY STORAGE MODEL (NSM) 行存储
DBMS 将一个元组的所有属性连续地存储在一个页面中。
非常适合于仅在单个实体上运行的查询,并有大量插入工作负载的 OLTP 工作负载。
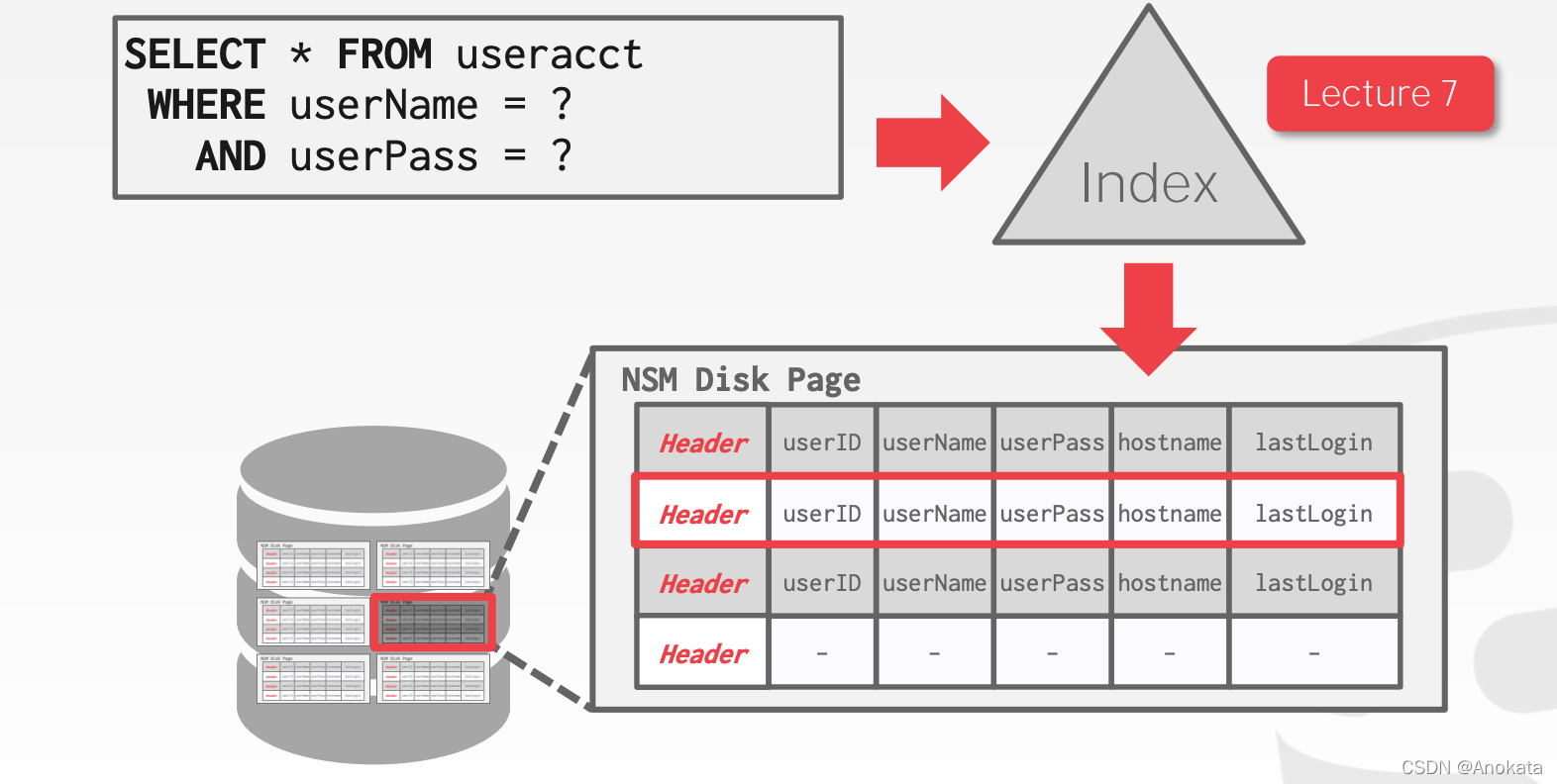
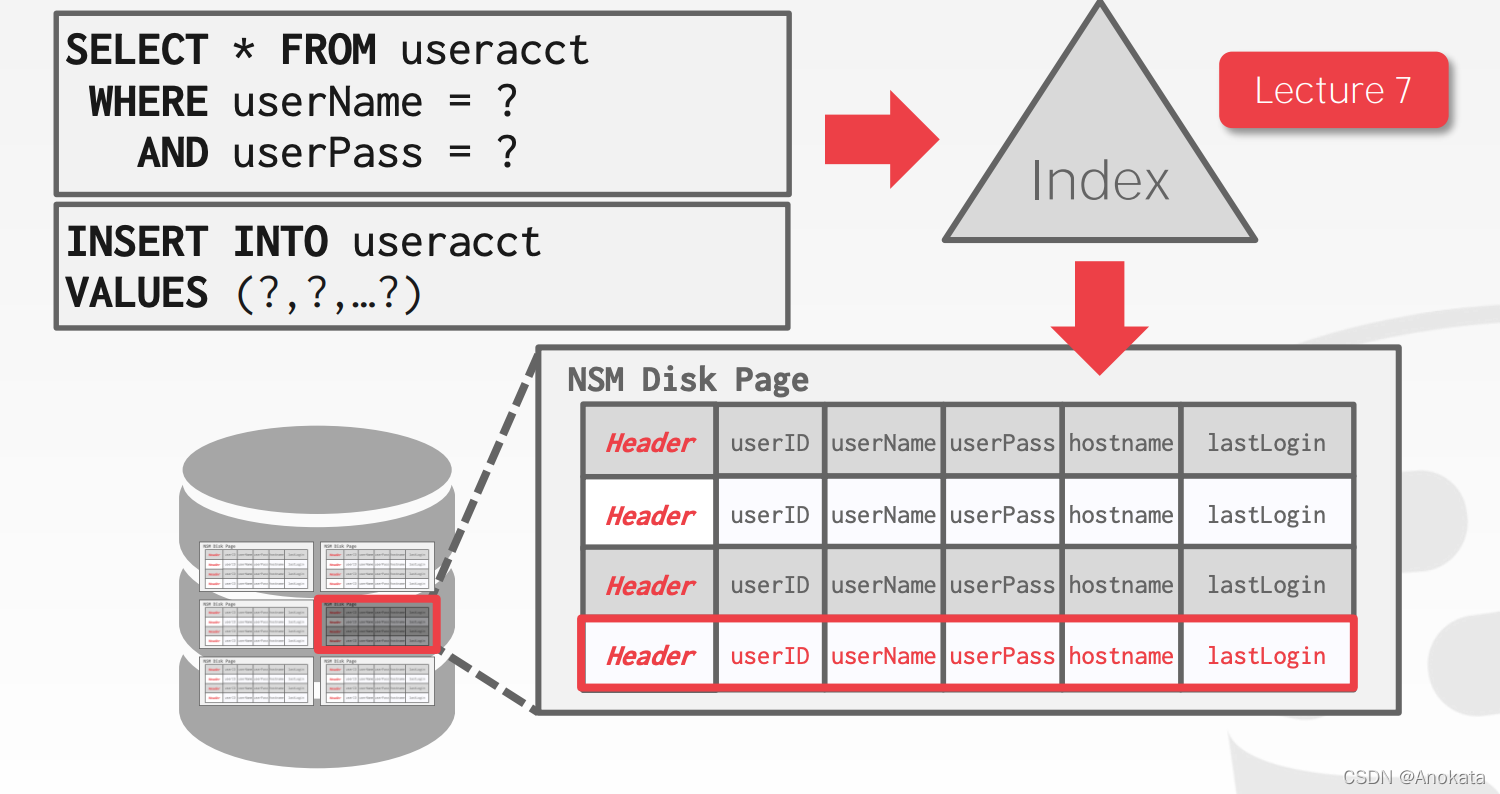
优点
→ 快速插入、更新和删除。
→ 适合需要整个元组的查询(元组的属性)。
缺点
→ 不适合扫描表的大部分和/或属性的子集。
DECOMPOSITION STORAGE MODEL (DSM) 列存储
DBMS 将所有元组的单个属性的值连续存储在一个页面中。也称为“列存储”。
非常适合只读查询对表属性的子集执行大型扫描的 OLAP 工作负载。
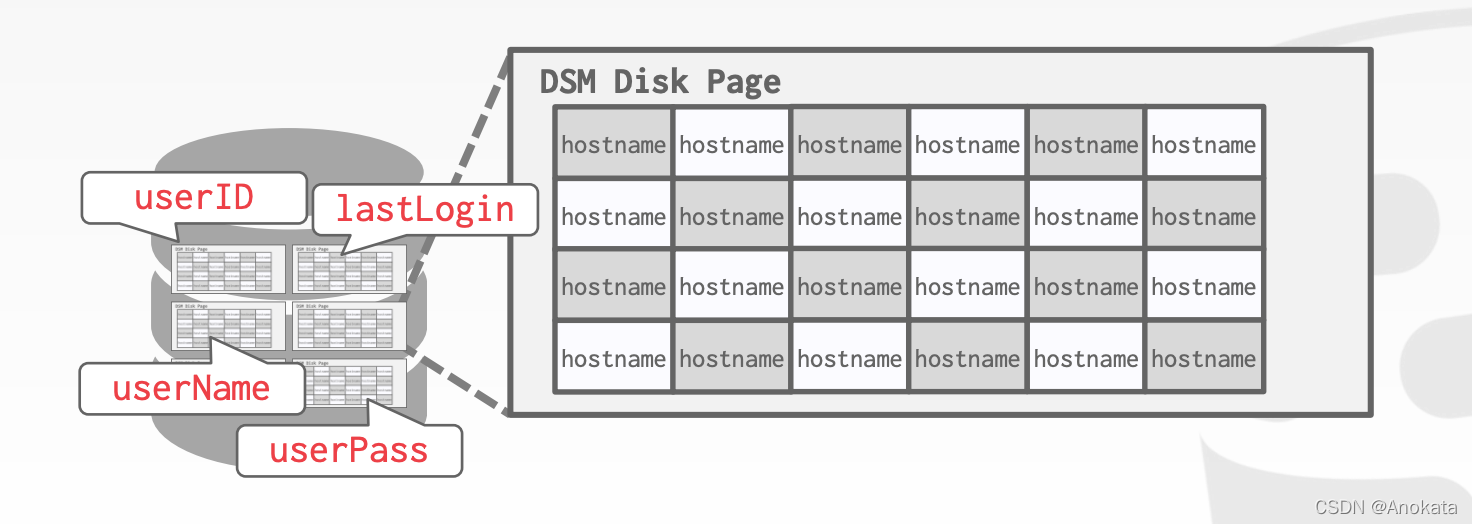
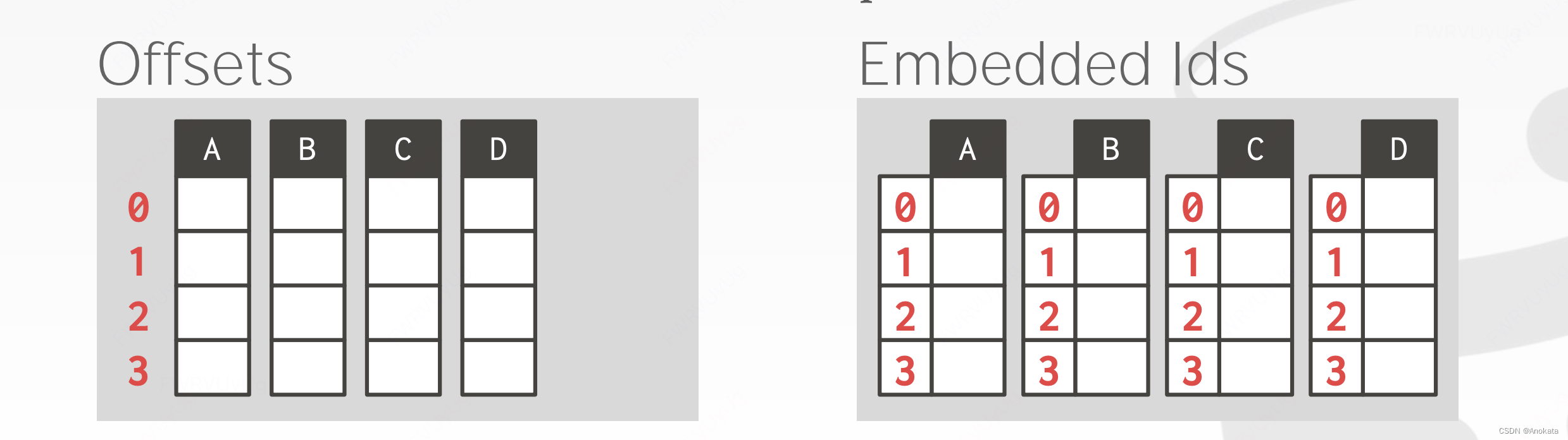
TUPLE IDENTIFICATION 元组识别
选择#1:固定长度偏移【Fixed-length Offsets】
→ 属性的每个值的长度都相同。
选择#2:嵌入元组 ID【Embedded Tuple Ids】
→ 每个值都与其元组 ID 一起存储在列中。
优点
→ 减少浪费的 I/O 量,因为 DBMS 只读取它需要的数据(属性)。
→ 更好的查询处理和数据压缩(稍后详细介绍)。
缺点
→ 由于元组分割/拼接,单点的查询、插入、更新和删除速度较慢。
结论
存储管理器并不是完全独立于DBMS的其他部分。为目标工作负载选择正确的存储模型很重要:
- OLTP =行存储
- OLAP =列存储


![[前端开发] CSS基础知识 [上]](http://pic.xiahunao.cn/[前端开发] CSS基础知识 [上])

杂项设备驱动实验)










No.21 - No.40)

实战)

