小土堆Pytorch视频教程链接
声明: 博主本人技术力不高,这篇博客可能会因为个人水平问题出现一些错误,但作为小白,还是希望能写下一些碰到的坑,尽力帮到其他小白
1 环境配置
1.1 pycharm
pycharm建议使用2020的,2021版本开始UI界面升级,本人镜像源配置很久,但可安装包仍为空白,2020版本的可以在环境内直接换源,比较方便
pycharm的安装激活网上教程很多,这里不赘述
后面发现还是直接命令行创建虚拟环境再导到项目中更方便,而且还可以选择库的版本
1.2 anaconda
注:提示
1.3 cuda + pytorch
(1)创建虚拟环境
conda create -n pytorch12 python=3.6 # 这里环境名为pytorch,也可改为其他
(2)激活环境
# Anaconda Prompt窗口下 建议管理员权限
conda activate pytorch
pytorch官网

选择合适版本,复制代码进行安装
这里推荐使用 cuda 9.2
配置cuda 9.2
conda install pytorch torchvision cudatoolkit=9.2 -c pytorch -c defaults -c numba/label/dev
空间不足解决方法: 由于默认路径部分在C盘,所以可能会出现C盘空间不足的情况
# 解决方法:cmd窗口下
# 查看当前下载路径
conda info --base
# 自定义下载路径
conda config --prepend pkgs_dirs F:\anaconda3\pkgs # 这里改成自己的路径
项目中导入虚拟环境
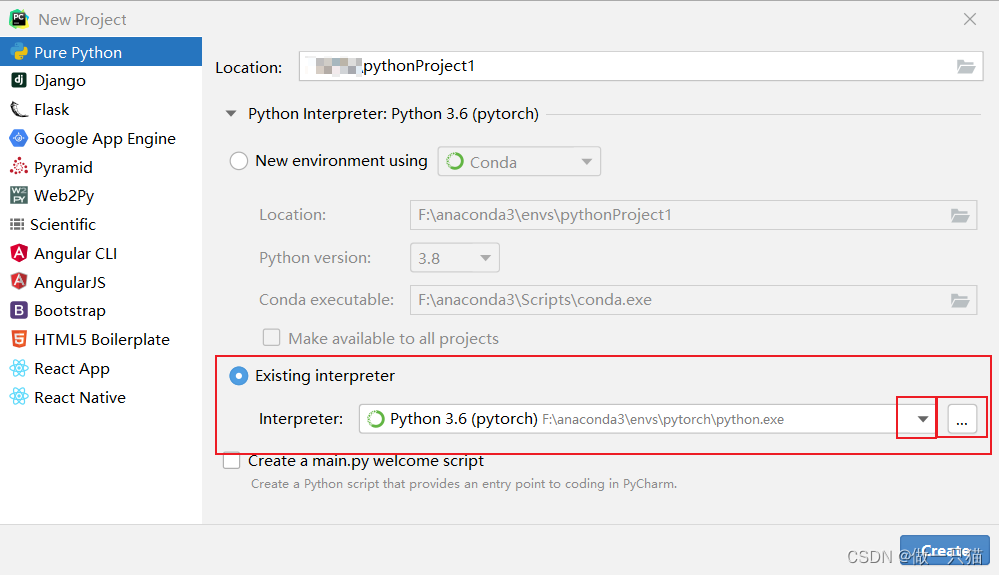
pycharm中新建项目,并选择编译器
项目路径自行选择,编译器选择刚刚创建的虚拟环境中的python.exe(路径详情见图)
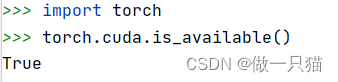
验证安装是否成功
import torch
torch.cuda.is_available()
Flase问题解决
这里如果为False有很多种原因
1 显卡驱动问题: 如果打开一个比较大的游戏或者其他图形处理类工具如PS等,任务管理器性能里GPU仍没工作,那么显卡驱动应该是出问题了,更新显卡驱动即可
2 CPUonly问题: 通过conda list查看已安装库,如果发现存在cpuonly,则是安装了cpu版本。这是conda魅力时刻,由于conda自身特性问题,它在查找不到要安装的文件时,会自动找寻合适的文件进行代替,这里似乎就是找不到GPU版本,进而安装了CPU版本
解决方法:
① 删除CPUonly
conda uninstall cpuonly
有博主说执行完这条代码后会自动安装GPU版本,但是我没有。我删除后再重新安装也仍是一样的问题
② 删除pytorch-mutex
conda uninstall pytorch-mutex
③ 删除numpy
conda uninstall numpy
注: ②和③都有点玄学,但有人说成功了,反正我没成功
④ 下载安装包并手动安装(我真正解决问题的一步)
下载Up课程资源:https://pan.baidu.com/s/1CvTIjuXT4tMonG0WltF-vQ?pwd=jnnp 提取码:jnnp

创建一个新的虚拟环境并启动,查看下载目录并修改下载目录(如果目录可用就不用改)
# 创建项目并启动
conda create -n pytorch2 python=3.6
conda activate pytorch2
# 查看当前下载路径
conda info --base
# 修改下载路径
conda config --prepend pkgs_dirs F:\anaconda3\pkgs # 这里改成自己的路径
再把网盘下好的两个文件拖到改目录中
再分别执行下面代码
conda install --use-local F:\anaconda3\pkgs\cudatoolkit-9.2-0.tar.bz2
conda install --use-local F:\anaconda3\pkgs\pytorch-1.3.0-py3.6_cuda92_cudnn7_0.tar.bz2
这里可能需要等待一段时间,显示done则成功
再回到pycharm中,按之前的步骤,创建一个新的项目,并导入我们新建的pytorch2虚拟环境,并重启pycharm
之后再验证即发现True了
博主本人到这一步就成功了,如果还是False,可以看看这篇博客,干脆安装成其他版本的CUDA
如果还不行,可能是你电脑是显卡不支持CUDA,再检查一下,如果不支持,用CPU也是可以跑的,当然速度会慢些
2 Python 法宝
2.1 Python 法宝
(1)Python3.6.3相当于一个package,package里面有不同的区域,不同的区域有不同的工具。
(2) Python语法有两大法宝:dir()、help() 函数。
- dir():查看torch包中有哪些区、有哪些工具
- help():使用说明书
import torch
print(torch.cuda.is_available())
help(torch.cuda.is_available) # 查看 torch.cuda.is_available 的用法
dir(torch) # 查看torch包中有哪些区、有哪些工具
2.2 代码输入优化设置
设置大小写统一补全
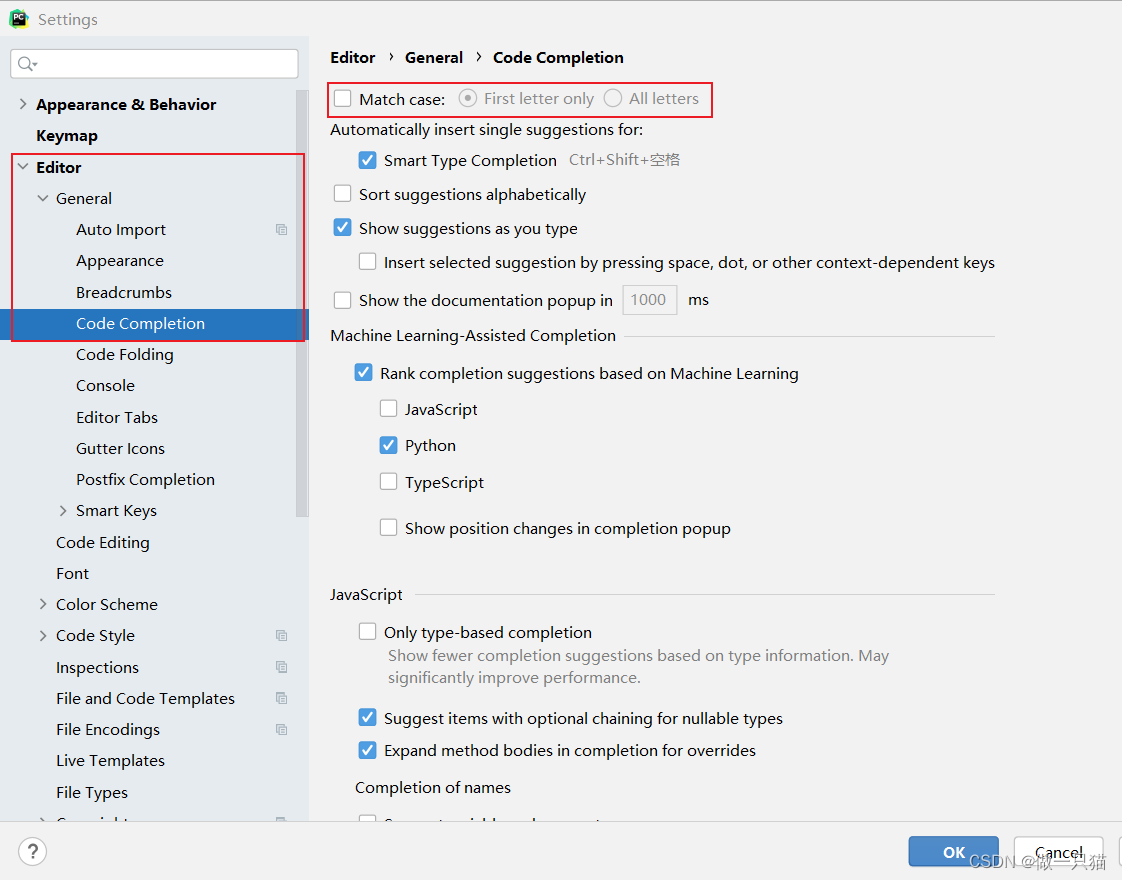
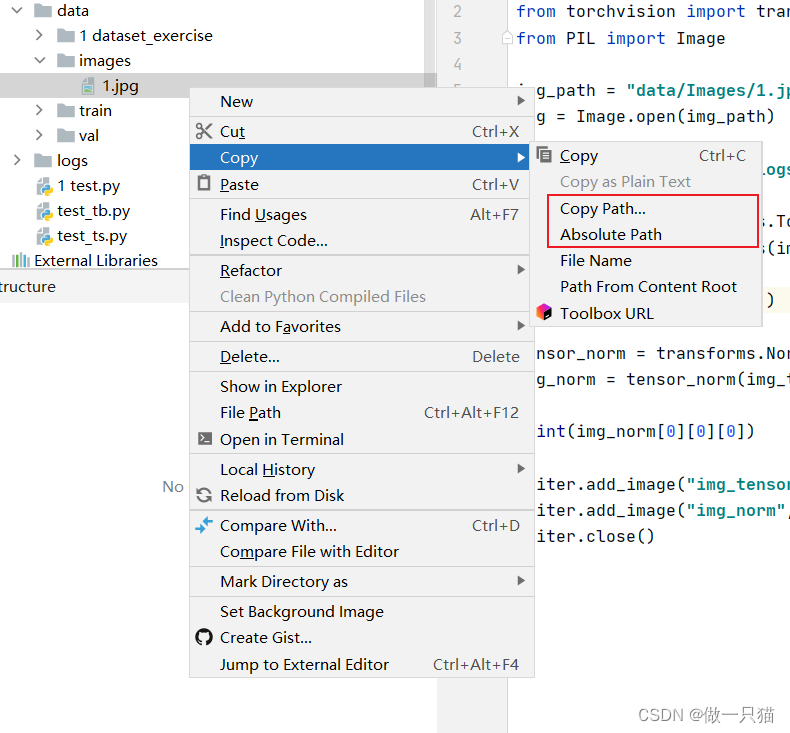
2.3 快速复制文件路径
复制 相对路径 / 绝对路径
3 Pytorch加载数据
蜜蜂数据集下载
3.1 加载数据方法及label形式
(1)Pytorch中加载数据需要Dataset、Dataloader。
- Dataset提供一种方式去获取每个数据及其对应的label(还有编号),以及告诉我们总共有多少个数据
- Dataloader为后面的网络提供不同的数据形式,它将一批一批数据进行一个打包
(2)label形式
- 文件夹名即为label。文件夹内存放若干条数据
- 一个文件夹存放数据,数据有编号,另一个文件夹存放数据对应编号的说明文本(txt),文本中有label
- 直接把label写在数据的名称上
from torch.utils.data import Dataset
help(Dataset)
3.2 通过路径加载数据
from PIL import Image
img_path = "data/1 dataset_exercise/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(img_path)
img.show()
注: 这里可能是因为anaconda问题,我始终无法连上镜像源,包括默认的,所以这里PIL无法导包,后用了下面这个解决方法:
# cmd终端 或 在anaconda prompt激活虚拟环境
conda config --show channels
conda config --remove-key channels
conda config --add channels https://repo.continuum.io/pkgs/free/
conda config --add channels https://repo.continuum.io/pkgs/main/
conda config --set show_channel_urls yes
pip install pillow
配置其他镜像源地址可参考这篇博客
3.3 python特殊方法补充
Python 中有很多特殊方法,这些特殊方法的命名都以双下划线 __开头和结尾,它们是 Python 中非常常用的特殊方法。通过定义这些方法,我们可以自定义对象的行为和操作,使得对象能够更好地适应我们的需求。以下是其中一部分的列表:
__init__(self[, args...]): 构造函数,用于在创建对象时进行初始化。
__repr__(self): 用于定义对象的字符串表示形式,通常用于调试和记录日志。
__str__(self): 用于定义对象的字符串表示形式,通常用于显示给终端用户。
__len__(self): 用于返回对象的长度,通常在对像被视为序列或集合时使用。
__getitem__(self, key): 用于实现索引操作,可以通过索引或切片访问对象中的元素。
__setitem__(self, key, value): 用于实现索引赋值操作,可以通过索引或切片为对象中的元素赋值。
__delitem__(self, key): 用于实现删除某个元素的操作,可以通过索引或切片删除对象中的元素。
__contains__(self, item): 用于检查对象是否包含某个元素,可以通过 in 关键字使用。
__enter__(self): 用于实现上下文管理器的进入操作,通常与 with 语句一起使用。
__exit__(self, exc_type, exc_value, traceback): 用于实现上下文管理器的退出操作,通常与 with 语句一起使用。
__call__(self[, args...]): 用于使对象能够像函数一样被调用,通常在创建可调用的类时使用。
__eq__(self, other): 用于定义对象相等的比较操作,可以通过 == 运算符使用。
__lt__(self, other): 用于定义对象小于的比较操作,可以通过 < 运算符使用。
__gt__(self, other): 用于定义对象大于的比较操作,可以通过 > 运算符使用。
__add__(self, other): 用于实现对象加法操作,可以通过 + 运算符使用。
__sub__(self, other): 用于实现对象减法操作,可以通过 - 运算符使用。
__mul__(self, other): 用于实现对象乘法操作,可以通过 * 运算符使用。
__truediv__(self, other): 用于实现对象除法操作,可以通过 / 运算符使用。
3.4 Dataset加载数据
from torch.utils.data import Dataset
from PIL import Image
import os # 自定义数据集类
class MyData(Dataset):def __init__(self, root_dir, label_dir):self.root_dir = root_dir # 记录数据集根目录的路径self.label_dir = label_dir # 记录数据集标签目录的名称self.path = os.path.join(self.root_dir, self.label_dir) # os.path.join可将两个字符串拼接成一个完整路径# 以获取数据集标签目录的完整路径self.img_path = os.listdir(self.path) # os.listdir() 函数用于获取指定目录下的所有文件和文件夹的名称列表# 以获取数据集标签目录下所有图像文件的路径def __getitem__(self, idx): # 获取数据集中指定索引位置的数据项img_name = self.img_path[idx] # 获取图像文件名img_item_path = os.path.join(self.root_dir, self.label_dir, img_name) # 获取该图像文件的完整路径img = Image.open(img_item_path) # 打开图像文件label = self.label_dir # 获取该图像文件所属的标签return img, label # 返回图像和标签def __len__(self): # 获取数据集的长度return len(self.img_path)root_dir = "data/1 dataset_exercise/hymenoptera_data/train" # 数据集根目录的路径
ants_label_dir = "ants" # 蚂蚁标签目录的名称
bees_label_dir = "bees" # 蜜蜂标签目录的名称
ants_dataset = MyData(root_dir, ants_label_dir) # 创建蚂蚁数据集对象
bees_dataset = MyData(root_dir, bees_label_dir) # 创建蜜蜂数据集对象
print(len(ants_dataset)) # 打印蚂蚁数据集的长度
print(len(bees_dataset)) # 打印蜜蜂数据集的长度
train_dataset = ants_dataset + bees_dataset # 合并蚂蚁和蜜蜂数据集,得到训练集
print(len(train_dataset)) # 打印训练集的长度img, label = train_dataset[200] # 自动调用__getitem__() 方法,获取训练集中第 200 个数据项的图像和标签
print("label:", label) # 打印该数据项的标签
img.show() # 显示该数据项的图像
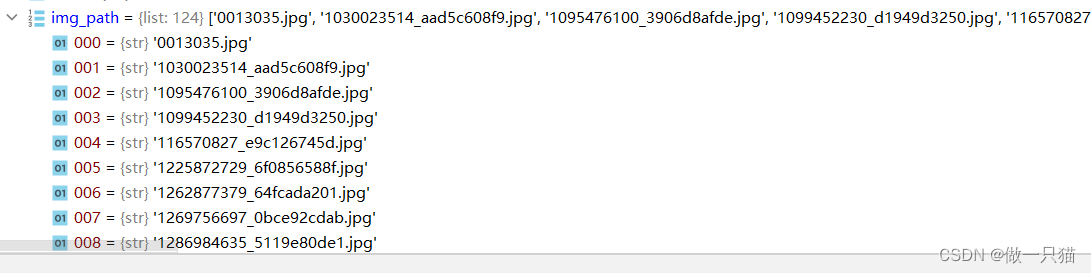
img_path如下图所示:
4 Tensorboard的使用
Tensorboad 可以用来查看loss是否按照我们预想的变化,或者查看训练到某一步输出的图像是什么样
4.1 安装
这里我用pycharm命令行直接安装会报错,提示权限不够
pip install tensorboard

遂还是用管理员模式打开anaconda prompt安装
4.2 Tensorboard 写日志
注: 对函数使用不清楚时,可把鼠标移到函数名上,并按ctrl+鼠标左键,会自动跳转到该函数的详细说明文档中
from torch.utils.tensorboard import SummaryWriter# 创建一个 SummaryWriter 对象,指定日志存储目录为 "logs"
writer = SummaryWriter("logs")for i in range(100):# 将 y=x 的函数值添加到 TensorBoard 中writer.add_scalar("y=x", i, i)# 关闭 SummaryWriter 对象
writer.close()
运行完后会在当前目录下创建一个logs文件夹
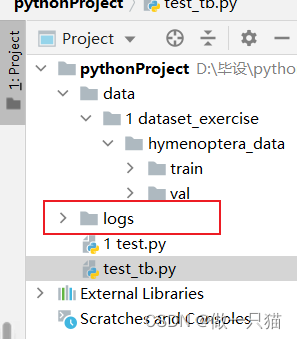
在pycharm终端运行
tensorboard --logdir=logs
# tensorboard --logdir=logs --port=6007 # 指定端口

网页打开后

4.3 Tensorboard 读图片
蚂蚁蜜蜂 / 练手数据集: 链接: https://pan.baidu.com/s/1jZoTmoFzaTLWh4lKBHVbEA 密码: 5suq
(1)查看add_image() ,发现数据类型是下面这几项

(2)重启Python console
(3)查看数据集数据类型
image_path = "data/train/ants_image/0013035.jpg"
from PIL import Image
img = Image.open(image_path)

或者直接
print(type(img))

发现数据类型不符合形式,这里可用opencv读取,读出来是numpy型,符合要求
pip install opencv-python
小土堆这里咕了,下面介绍用numpy.array()对PIL图片进行转换
(4)numpy.array()转换PIL图片
import numpy as np
img_array = np.array(img)
print(type(img_array))## <class 'numpy.ndarray'>
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as npimg_path1 = "data/train/ants_image/0013035.jpg"
img_PIL1 = Image.open(img_path1)
img_array1 = np.array(img_PIL1)img_path2 = "data/train/ants_image/5650366_e22b7e1065.jpg"
img_PIL2 = Image.open(img_path2)
img_array2 = np.array(img_PIL2)writer = SummaryWriter("logs")
# HWC是为了适应数据的shape 具体见下图
writer.add_image("test",img_array1,1,dataformats="HWC") # 1 表示该图片在第1步
writer.add_image("test",img_array2,2,dataformats="HWC") # 2 表示该图片在第2步
writer.close()
默认是CHW(即通道 高度 宽度):

下图可看到该图片是数据的shape是HWC

终端中输入
tensorboard --logdir=logs
再打开http://localhost:6006/
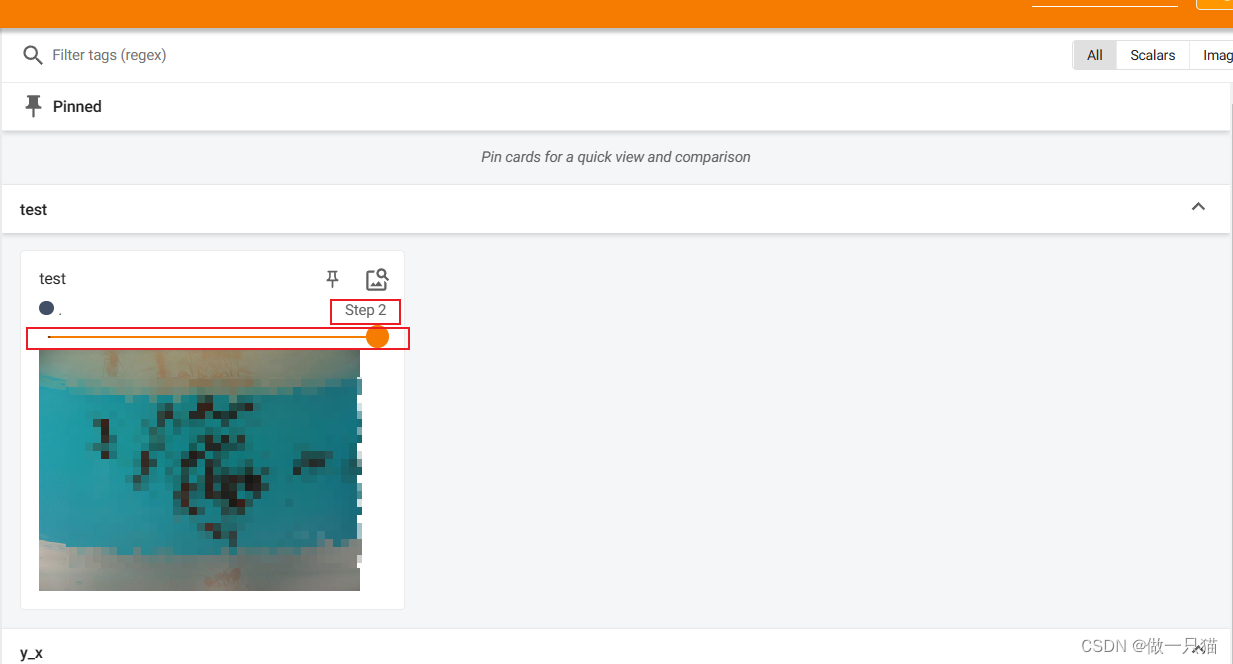
5 Tensorforms的使用
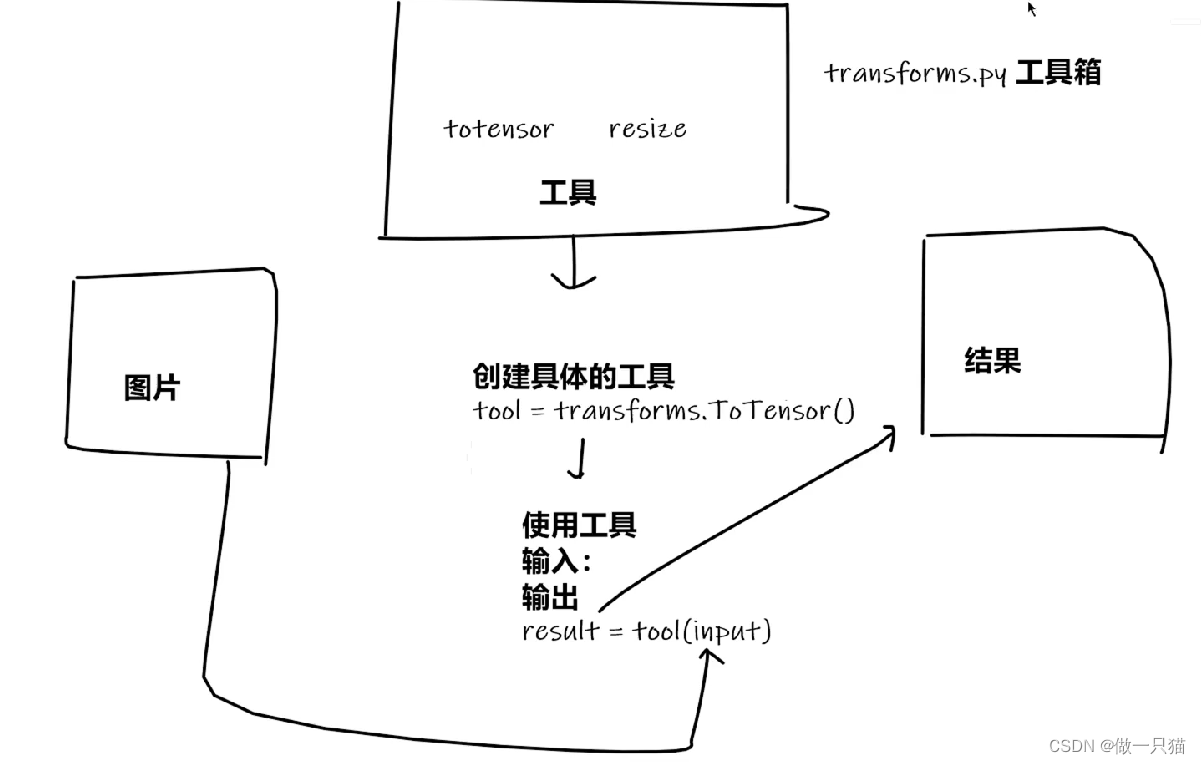
作用:
① Transforms当成工具箱的话,里面的class就是不同的工具。例如像totensor、resize这些工具
② Transforms拿一些特定格式的图片,经过Transforms里面的工具,获得我们想要的结果
5.1 查看方法
这里按理说torchvision应该是捆绑安装的,但是我的环境里没有,所以得自己再安装
pip download -d D:\pip_download --no-deps torchvision #c盘空间不足
pip install --no-index --find-links=D:\pip_download torchvision
from torchvision import transforms
from PIL import Imageimg_path = "Data/FirstTypeData/val/bees/10870992_eebeeb3a12.jpg"
img = Image.open(img_path)tensor_trans = transforms.ToTensor() # 创建 transforms.ToTensor类 的实例化对象
tensor_img = tensor_trans(img) # 调用 transforms.ToTensor类 的__call__的魔术方法
print(tensor_img)
ctrl+点击transforms

ctrl+再点击transforms
点击左下角structure
可以看到里面的方法,前几个比较常用

5.2 __call__的使用
ctrl + p:可直接查看函数所需参数
class Person:def __call__(self, name):print("__call__" + name)def hello(self, name):print("hello " + name)
person = Person()
person("zhangsan")
person.hello("lisi")# __call__ zhangsan
# helll lisi
5.3 transforms.Totensor使用
Tensor包装了神经网络需要的一些属性,比如反向传播、梯度等属性
# 为不被之前的Logs影响,可以把之前的Logs文件夹删掉
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Imageimg_path = "Data/FirstTypeData/val/bees/10870992_eebeeb3a12.jpg"
img = Image.open(img_path)writer = SummaryWriter("logs")tensor_trans = transforms.ToTensor() # 创建 transforms.ToTensor类 的实例化对象
tensor_img = tensor_trans(img) # 调用 transforms.ToTensor类 的__call__的魔术方法 writer.add_image("Temsor_img",tensor_img)
writer.close()
终端中输入
tensorboard --logdir=logs
再打开http://localhost:6006/
5.4 Normanize归一化
归一化原理:

img_tensor[0][0][0] # 红色通道的第一个像素值
img_tensor[1][0][0] # 绿色通道的第一个像素值
img_tensor[2][0][0] # 蓝色通道的第一个像素值
img_tensor[0][0][0],img_tensor[1][0][0],img_tensor[2][0][0]构成了一个像素点的rgb
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Imageimg_path = "data/Images/1.jpg" # 此处要用jpg,png有4个通道,会报错
img = Image.open(img_path)writer = SummaryWriter("logs")tensor_trans = transforms.ToTensor()
img_tensor = tensor_trans(img)print(img_tensor[0][0][0]) tensor_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 前为均值,后卫标准差 input[channel] = (input[channel] - mean[channel]) / std[channel]
img_norm = tensor_norm(img_tensor)print(img_norm[0][0][0])writer.add_image("img_tensor", img_tensor)
writer.add_image("img_norm", img_norm)
writer.close()
5.5 transforms.Resize()
transforms.Resize() 的作用是调整图像的大小到指定的尺寸
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Imageimg_path = "data/Images/1.jpg"
img = Image.open(img_path)
print(img) # PIL类型,且图片原始比例为 500×464writer = SummaryWriter("logs") # 将图片转为totensor类型
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img) # resize图片,PIL数据类型的 img -> resize -> PIL数据类型的 img_resize
trans_resize = transforms.Resize((512,512)) # 调整尺寸为512*512
img_resize = trans_resize(img)# PIL 数据类型的 PIL -> totensor -> img_resize tensor
img_resize = trans_totensor(img_resize)
print(img_resize.size()) writer.add_image("img_tensor",img_tensor)
writer.add_image("img_resize",img_resize)
writer.close()
5.6 transforms.Compose
transforms.Compose 的作用是将多个数据预处理操作组合在一起,方便地对数据进行一次性处理
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
import cv2img_path = "data/Images/1.jpg"
img = Image.open(img_path)
print(img)writer = SummaryWriter("logs") tensor_trans = transforms.ToTensor()
img_tensor = tensor_trans(img) trans_resize_2 = transforms.Resize(512) # PIL —— resize -> PIL —— totensor -> tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor]) # Compose函数中前面一个参数的输出 为 后面一个参数的输入,即trans_resize_2输出了pil,作为trans_totensor的输入img_resize_2 = trans_compose(img)
print(img_resize_2.size())
writer.add_image("img_tensor",img_tensor)
writer.add_image("img_resize_2",img_resize_2)
writer.close()
5.7 transforms.RandomCrop
transforms.RandomCrop 的作用是对输入图像进行随机裁剪,用于数据增强和提高模型的鲁棒性
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Imageimg_path = "data/images/1.jpg"
img = Image.open(img_path)print(img)writer = SummaryWriter("logs")tensor_trans = transforms.ToTensor()
img_tensor = tensor_trans(img)
writer.add_image("img_tensor",img_tensor)# trans_random = transforms.RandomCrop(312) # 随机裁剪成 312×312
trans_random = transforms.RandomCrop((312,100)) # 指定随机裁剪的宽和高为312和100
trans_compose_2 = transforms.Compose([trans_random,tensor_trans])
for i in range(10):img_crop = trans_compose_2(img)writer.add_image("RandomCrop",img_crop,i)print(img_crop.size())
5.8 关于方法的使用
- crtl + 点击查看函数输入文档或csdn等渠道查看官方文档
- 关注输入和输出类型
- 关注方法需要什么参数(或crtl + p )
- 不知道返回值类型时:
print()
print(type())
通过debug查看
6 torchvision数据集的使用
在pytorch官网查看可用数据集,如 torchivision-datasets
6.1 查看CIFAR10数据集内容
The CIFAR-10 dataset
import torchvision
# train=True是训练集,train=False是测试集,下方两个操作会自行处理数据集
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True) # root为存放数据集的路径
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True) print(test_set[0]) # 查看第一个数据
# 输出为 (<PIL.Image.Image image mode=RGB size=32x32 at 0x1C17D55B470>, 3) 可知第一个为img,第二个为 targetprint(test_set.classes) # 测试数据集有什么类型img, target = test_set[0] # 分别获得图片、target
print(img) # <PIL.Image.Image image mode=RGB size=32x32 at 0x1C17D55B470>,
print(target) # 3 print(test_set.classes[target]) # 即classes[3]
img.show()
若下载太慢,可复制运行窗口中的下载地址,打开迅雷进行下载,再把下载后的文件拖到对应文件夹位置;
若没有显示下载地址,则ctrl 点击数据集,到源代码中进行查看

Tensorboard查看内容
import torchvision
from torch.utils.tensorboard import SummaryWriterdataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True) # 将ToTensor应用到数据集中的每一张图片,每一张图片转为Tensor数据类型
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True) writer = SummaryWriter("logs")
for i in range(10):img, target = test_set[i]writer.add_image("test_set",img,i)print(img.size())writer.close() # 一定要把读写关闭,否则显示不出来图片
tensorboard --logdir=“logs”
6.2 Dataloader的使用
dataset 相当于有一副扑克牌,dataloader 则是从这副扑克牌中拿牌
查看dataloader的用法
torch.utils.data.DataLoader
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# batch_size=4 使得 img0, target0 = dataset[0]、img1, target1 = dataset[1]、img2, target2 = dataset[2]、img3, target3 = dataset[3],然后这四个数据作为Dataloader的一个返回 test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=True)
# 用for循环取出DataLoader打包好的四个数据
writer = SummaryWriter("logs")for epoch in range(2):step = 0for data in test_loader:imgs, targets = data # 每个data都是由4张图片组成,imgs.size 为 [4,3,32,32],四张32×32图片三通道,targets由四个标签组成 writer.add_images("Epoch:{}".format(epoch), imgs, step) # 注意是imagesstep = step + 1writer.close()
7 神经网络的构建
TORCH.NN(neural network)
7.1 神经网络的基本骨架
nn.MODUL
重写方法可通过将光标放在类中(如这里放在Tudui下一行),并在pycharm->code->generate->选择要重写的函数
import torch
from torch import nnclass Tudui(nn.Module):def __init__(self):super.__init__() # 继承父类的初始化def forward(self, input): # 将forward函数进行重写output = input + 1return outputtudui = Tudui()
x = torch.tensor(1.0) # 创建一个值为 1.0 的tensor
output = tudui(x)
print(output)
7.2 卷积层原理(选修)
Convolution Layers
7.2.1 卷积基本原理
(1)原理:
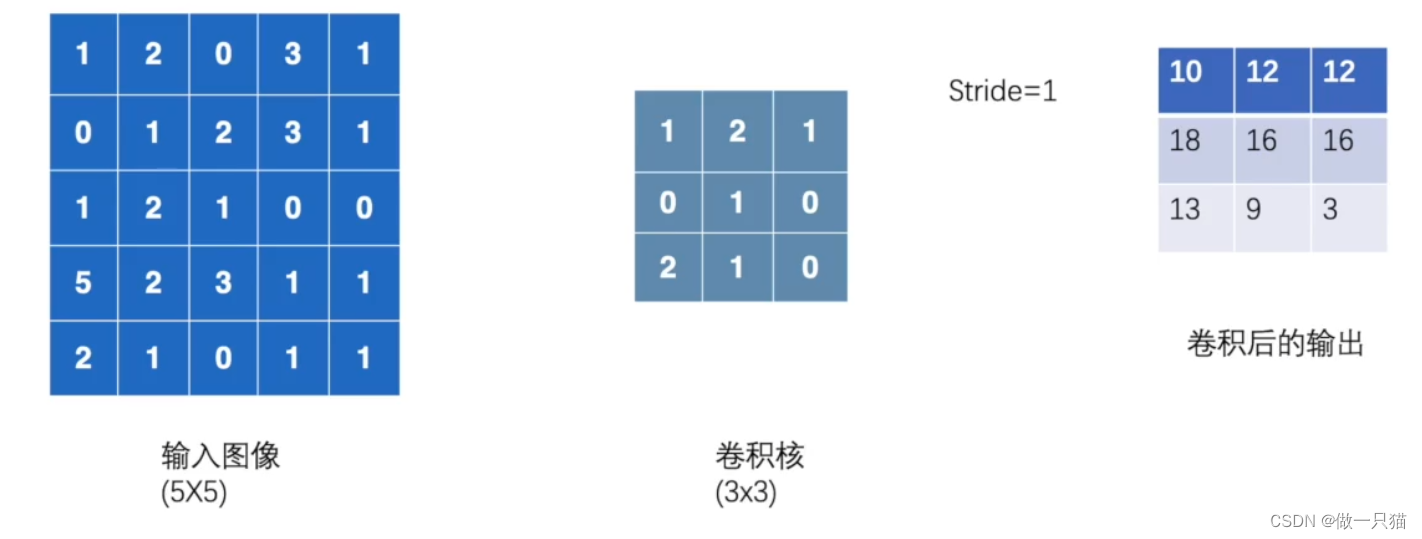
卷积运算包括输入图像和卷积核,按照设定的stride,
① 向右滑动stride格,到达边界后再向下滑动stride格
② 重复第①步,直到纵向也到达边界
具体运算逻辑如下:
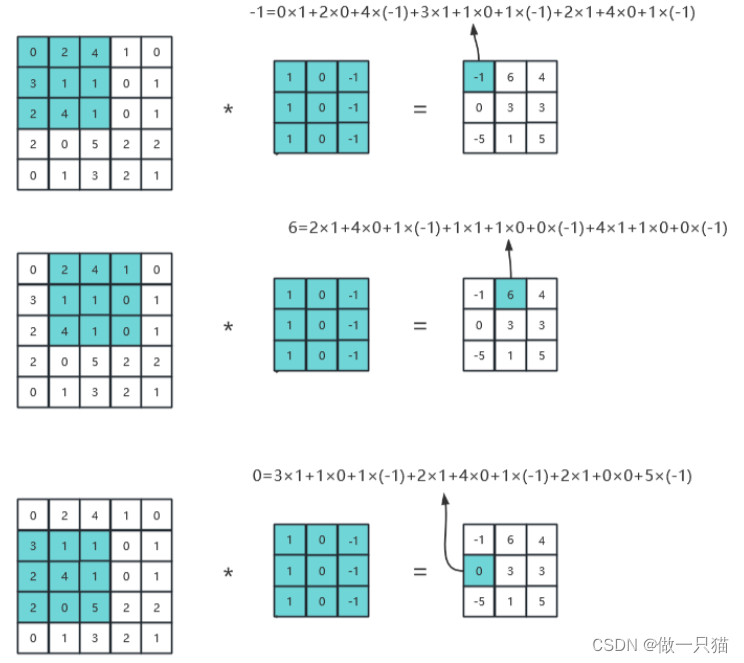
(2)动态示例:
stride为1
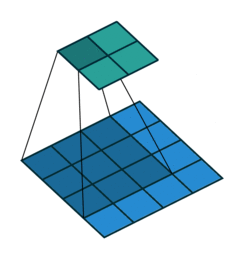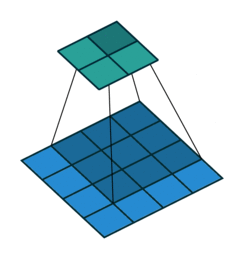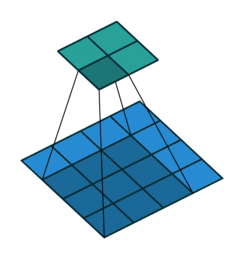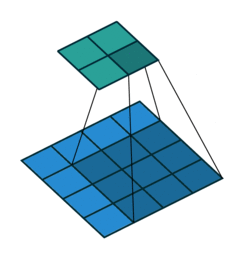
stride为2
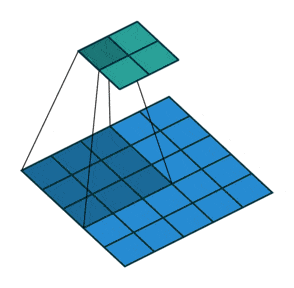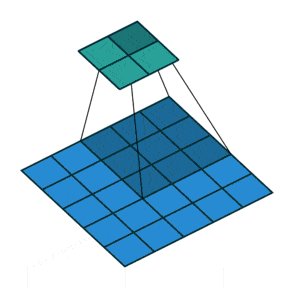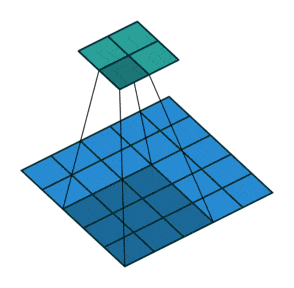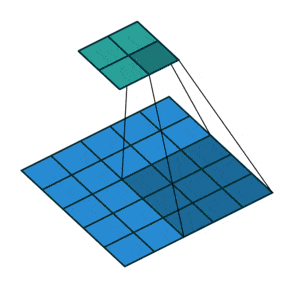
(3)代码实例:
import torch
import torch.nn.functional as Finput = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]])kernel = torch.tensor([[1, 2, 1],[0, 1, 0],[2, 1, 0]])print(input.shape) # torch.Size([5, 5])
print(kernel.shape) # torch.Size([3, 3])
input = torch.reshape(input, (1,1,5,5))
kernel = torch.reshape(kernel, (1,1,3,3))
print(input.shape) # torch.Size([1, 1, 5, 5])
print(kernel.shape) # torch.Size([1, 1, 3, 3])output = F.conv2d(input, kernel, stride=1)
print(output) # tensor([[[[10, 12, 12],# [18, 16, 16],# [13, 9, 3]]]])
7.2.2 padding
(1)原理:
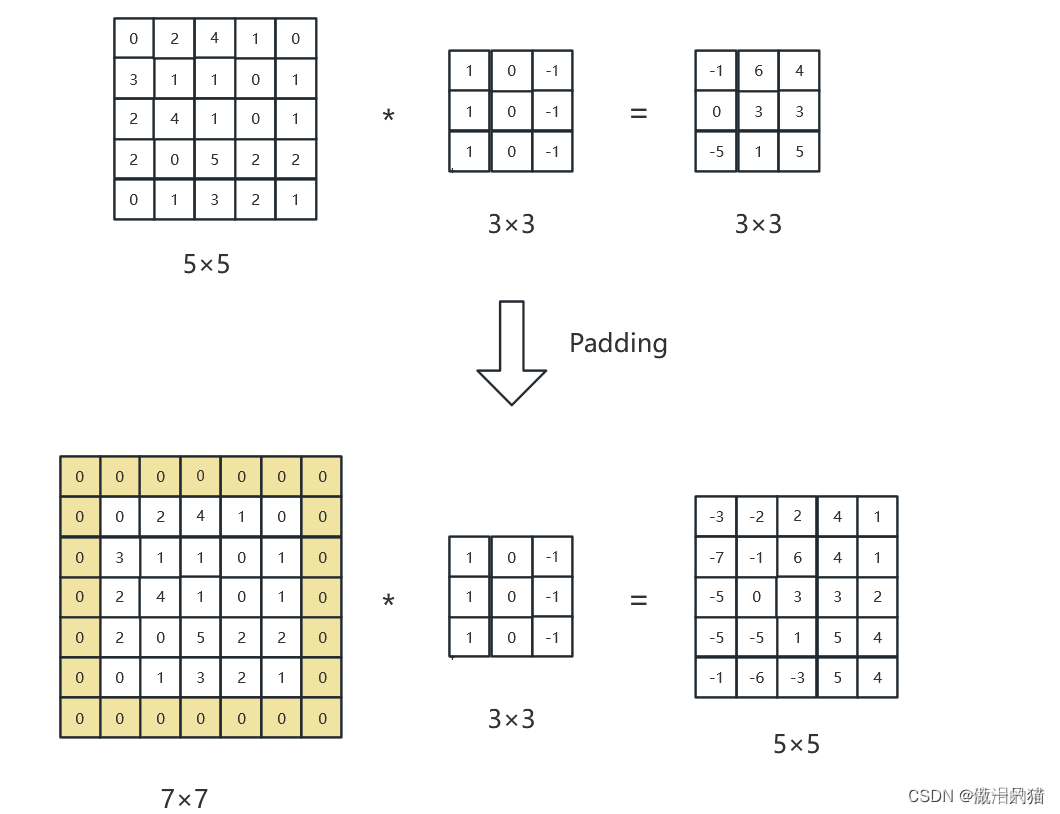
(2)动态示例:
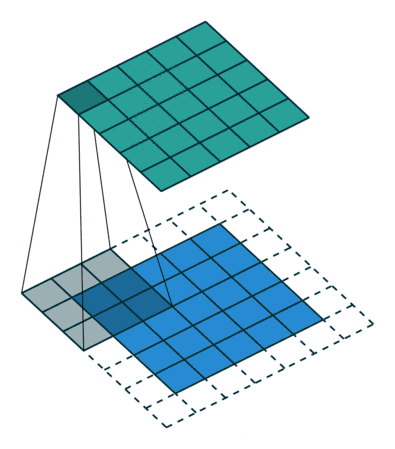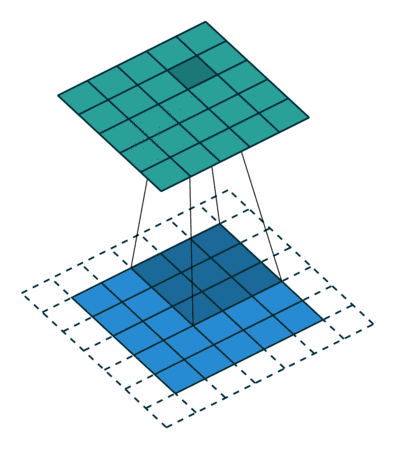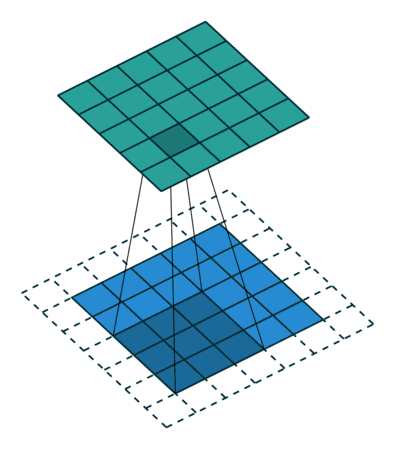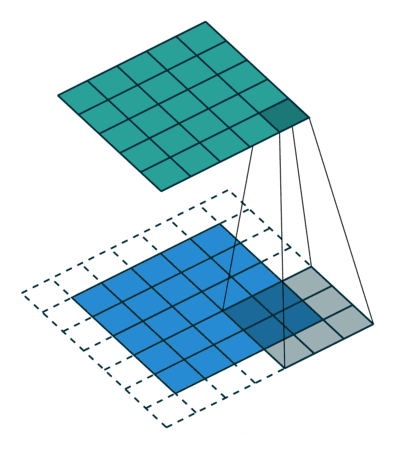
(3)代码实例:
import torch
import torch.nn.functional as Finput = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]])kernel = torch.tensor([[1, 2, 1],[0, 1, 0],[2, 1, 0]])print(input.shape)
print(kernel.shape)
input = torch.reshape(input, (1,1,5,5))
kernel = torch.reshape(kernel, (1,1,3,3))
print(input.shape)
print(kernel.shape)output3 = F.conv2d(input, kernel, stride=1, padding=1) # 周围只填充一层
print(output3)
7.2.3 卷积作用
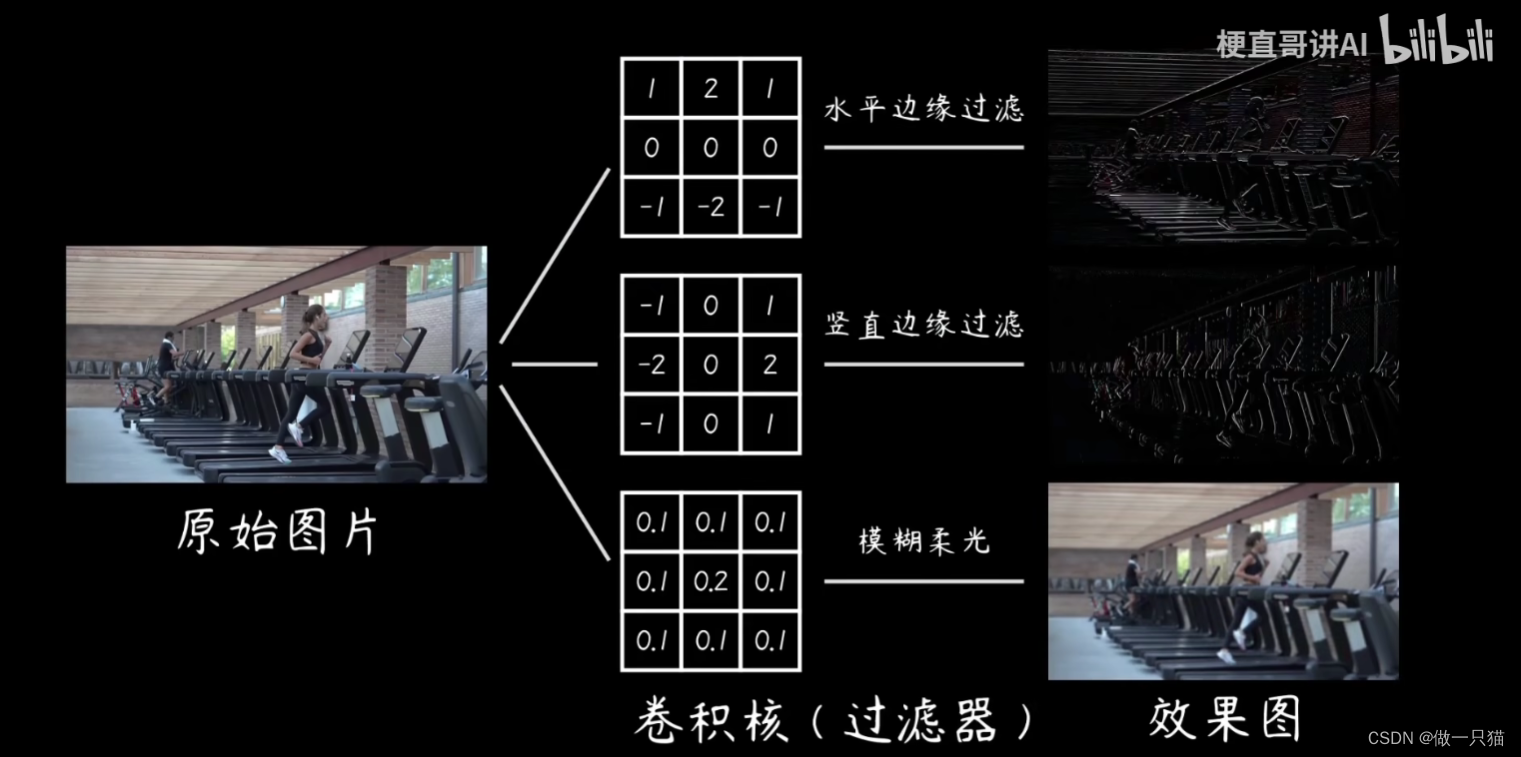
7.3 卷积实现
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0) # 彩色图像输入为3层,我们想让它的输出为6层,选3 * 3 的卷积 def forward(self,x):x = self.conv1(x)return xtudui = Tudui()
for data in dataloader:imgs, targets = dataoutput = tudui(imgs)print(imgs.shape) # 输入为3通道32×32的64张图片print(output.shape) # 输出为6通道30×30的64张图片
关于这里的通道,在我gpt了一段时间后,最后得到一段不确定是否正确的答案:
① 对于rbg图片,输入(in_channels)就为3通道,若为2通道会损失部分特征,当然最后怎么样还是以人为定义为准
② 当希望从3个输入通道得到6个输出通道(out_channels),通常会使用6个卷积核,每个卷积核在3个输入通道上进行卷积操作,即3通道每个通道先算出来一个结果,三个结果对应像素点数值相加形成一个特征图。重复此过程,就可以得到6个输出通道的特征图
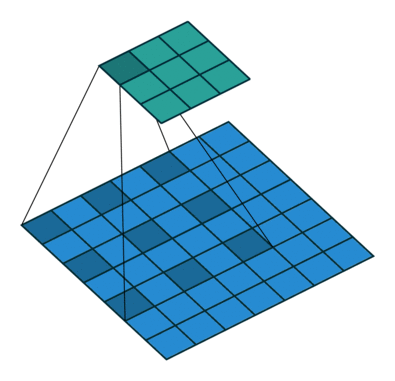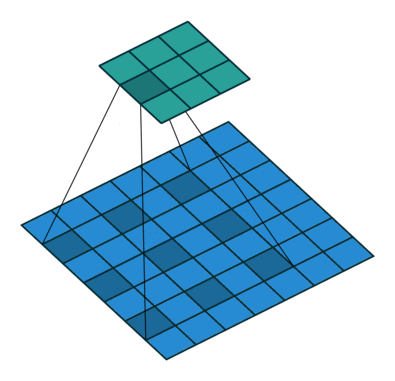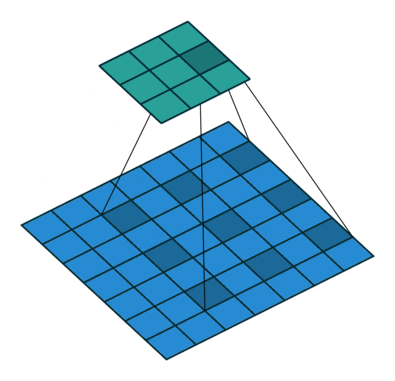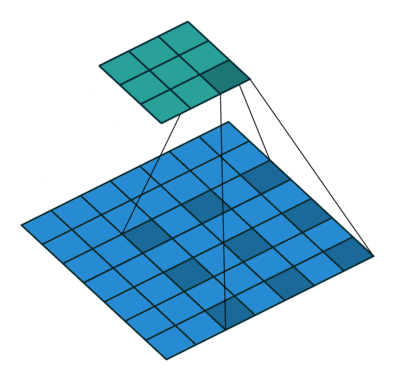
7.4 最大池化
Pooling layers
作用: 保留输入的特征,并减少数据量
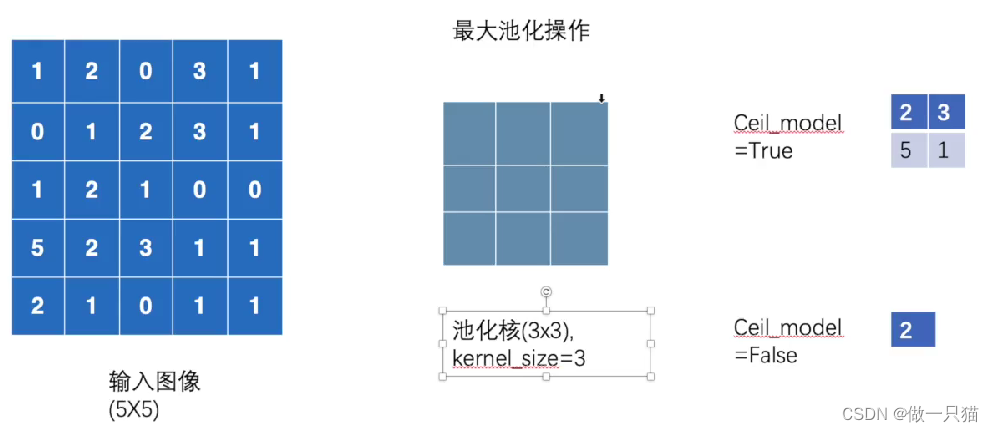
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, input):output = self.maxpool(input)return outputtudui = Tudui() # 即调用forward()
writer = SummaryWriter("logs")
step = 0for data in dataloader:imgs, targets = datawriter.add_images("input", imgs, step)output = tudui(imgs)writer.add_images("output", output, step)step = step + 1
7.5 非线性激活
Non-linear Activations (weighted sum, nonlinearity)
作用: 为神经网络引入非线性限制
7.5.1 torch.nn.ReLU 的运用
RELU
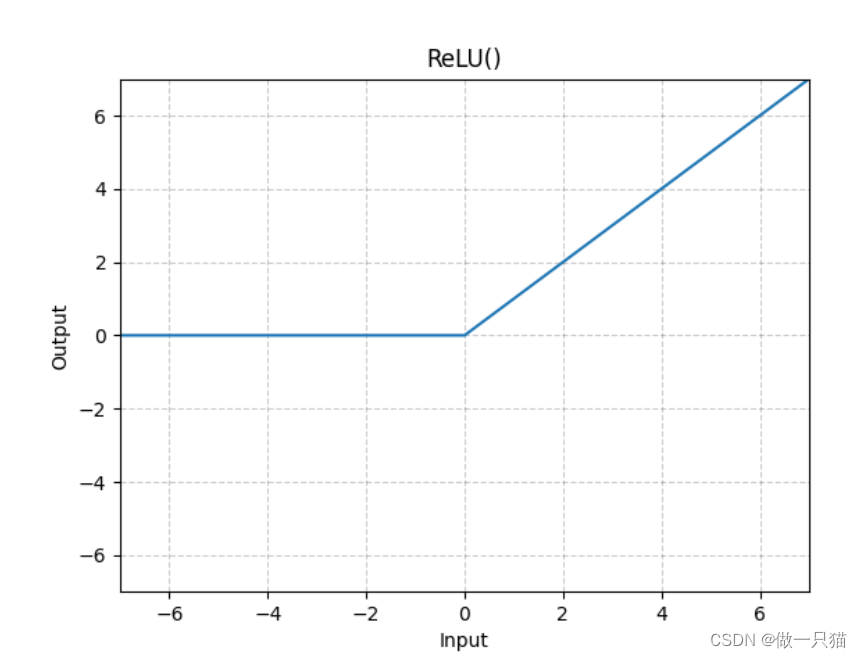
input小于0的数据output截断成0
关于inplace参数:
inplace为原地替换,
若为True,则变量的值被替换;
若为False,则会创建一个新变量,将函数处理后的值赋值给新变量,原始变量的值没有修改

import torch
from torch import nn
from torch.nn import ReLUinput = torch.tensor([[1, -0.5],[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.relu1 = ReLU()def forward(self, input):output = self.relu1(input)return outputtudui = Tudui()
output = tudui(input)
print(output)
可以发现小于0的 -0.5 和 -1 都被截断为 0

7.5.2 torch.nn.Sigmoid 的运用
torch.nn.Sigmoid
import torch
import torchvision
from torch import nn
from torch.nn import ReLU
from torch.nn import Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.relu1 = ReLU()self.sigmoid1 = Sigmoid()def forward(self, input):output = self.sigmoid1(input)return outputtudui = Tudui()
writer = SummaryWriter("logs")
step = 0for data in dataloader:imgs, targets = datawriter.add_images("input", imgs, global_step=step)output = tudui(imgs)writer.add_images("output", output, step)step = step + 1
tensorboard --logdir=“logs”
#这里提示
#TensorFlow installation not found - running with reduced feature set.
#Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
#不影响使用
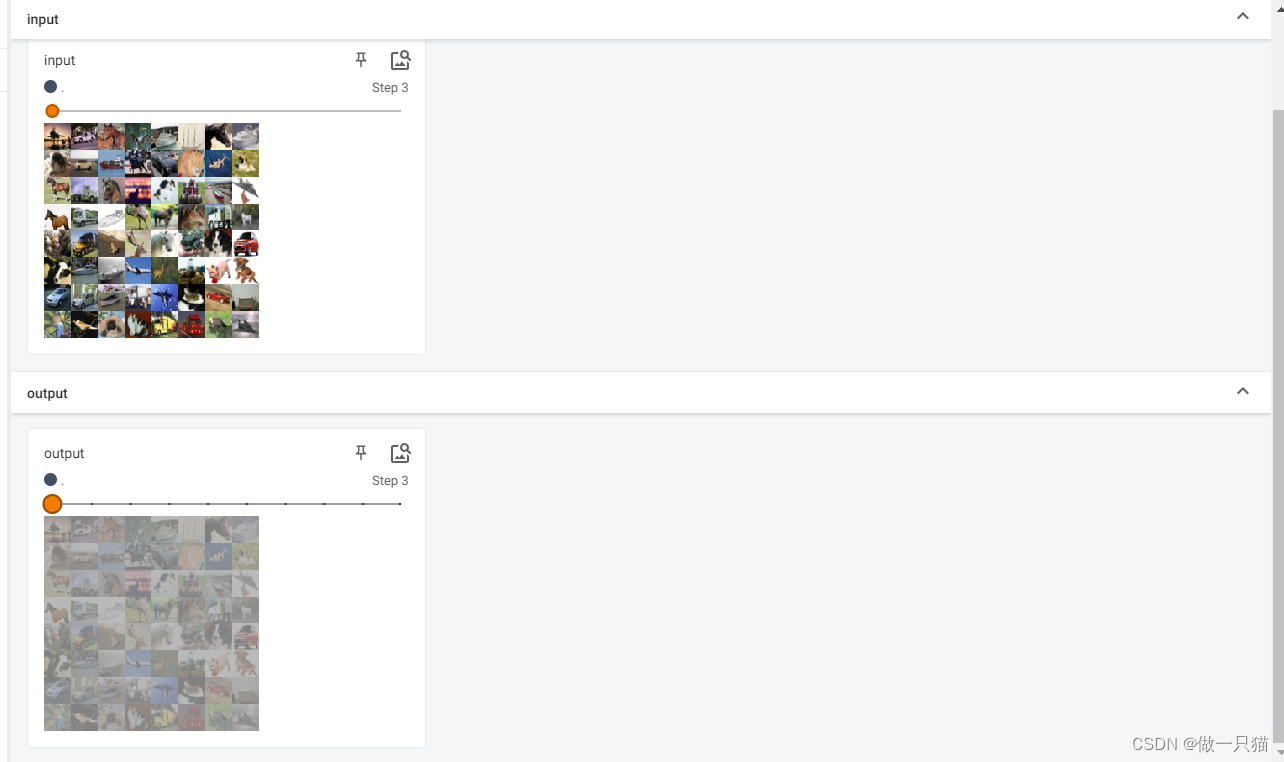
7.6 线性层及其他层
7.6.1 线性层
作用: 对输入数据进行线性变换和仿射变换,将输入数据映射到输出数据空间,使用较多
下列代码的作用是读取数据集,拉平为一维向量后,此时有199608个维度,再映射到更小的维度(10维度)
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.linear1 = Linear(196608,10)def forward(self, input):output = self.linear1(input)return outputtudui = Tudui()
writer = SummaryWriter("logs")
step = 0for data in dataloader:imgs, targets = dataprint(imgs.shape)writer.add_images("input", imgs, step)output = torch.reshape(imgs,(1,1,1,-1)) # 拉平方法一 # output = torch.flatten(imgs) # 拉平方法二print(output.shape)output = tudui(output)print(output.shape)writer.add_images("output", output, step)step = step + 1
关于196608:
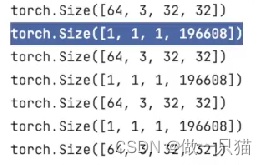
由 output = torch.reshape(imgs,(1,1,1,-1)) 结合64332*32计算得到
7.6.2 其它层
(1)Normalization Layers(正则化层)
Normalization Layers
作用: 经过正则化后可加快运行速度,用得不多
(2)Recurrent Layers
Recurrent Layers
作用: 文字识别多用,多数情况下不常用
(3)Transformer Layers
Transformer Layers
作用: 特定情况下使用
(4)Dropout Layers
Dropout Layers
作用: 随机将一些数按p概率设为0,防止过拟合
7.7 搭建小实战和Sequential 的使用
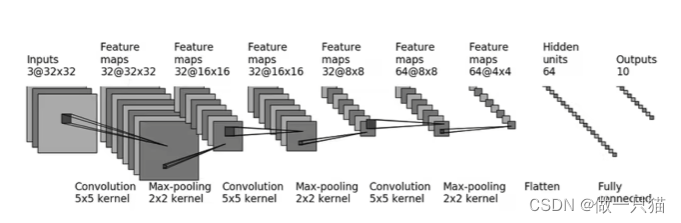
7.7.1 小实战
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linearclass Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.conv1 = Conv2d(3,32,5,padding=2) # in_channels out_channels kernel padding需计算,参照代码下图self.maxpool1 = MaxPool2d(2) # Max-pooling kernel为2*2self.cov2 = Conv2d(32,32,5,padding=2)self.maxpool2 = MaxPool2d(2)self.conv3 = Conv2d(32,64,5,padding=2)self.maxpool3 = MaxPool2d(2)self.flatten = Flatten() # 展平 这里可先展平而不运行☆代码,以获得展开维度self.linear1 = Linear(1024,64) # 64*4*4 = 1024 ☆self.Linear2 = Linear(64,10) # ☆def forward(self, x):x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.linear1(x) # ☆x = self.Linear2(x) # ☆return xtudui = Tudui()
input = torch.ones((64,3,32,32)) # 64batch_size 3通道 32*32
output = tudui(input)
print(output.shape)

7.7.2 Sequential 的使用
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequentialclass Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__() self.model1 = Sequential(Conv2d(3,32,5,padding=2),MaxPool2d(2),Conv2d(32,32,5,padding=2),MaxPool2d(2),Conv2d(32,64,5,padding=2),MaxPool2d(2),Flatten(),Linear(1024,64),Linear(64,10))def forward(self, x):x = self.model1(x)return xtudui = Tudui()
input = torch.ones((64,3,32,32))
output = tudui(input)
print(output.shape)writer.add_graph(tudui, input)
writer.close()
8 损失函数与反向传播
损失函数
- Loss损失函数一方面计算实际输出和目标之间的差距。
- Loss损失函数另一方面为我们更新输出提供一定的依据。
8.1 L1loss损失函数
差值的绝对值之和,再求平均值
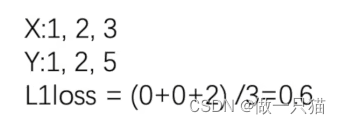
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss = L1Loss() # 默认为 maen
result = loss(inputs,targets)
print(result)
tensor(0.6667)
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss = L1Loss(reduction='sum') # 修改为sum,三个值的差值,然后取和
result = loss(inputs,targets)
print(result)
tensor(2.)
8.2 MSE损失函数
即平方差

import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs,targets)
print(result_mse)
tensor(1.3333)
8.3 交叉熵损失函数
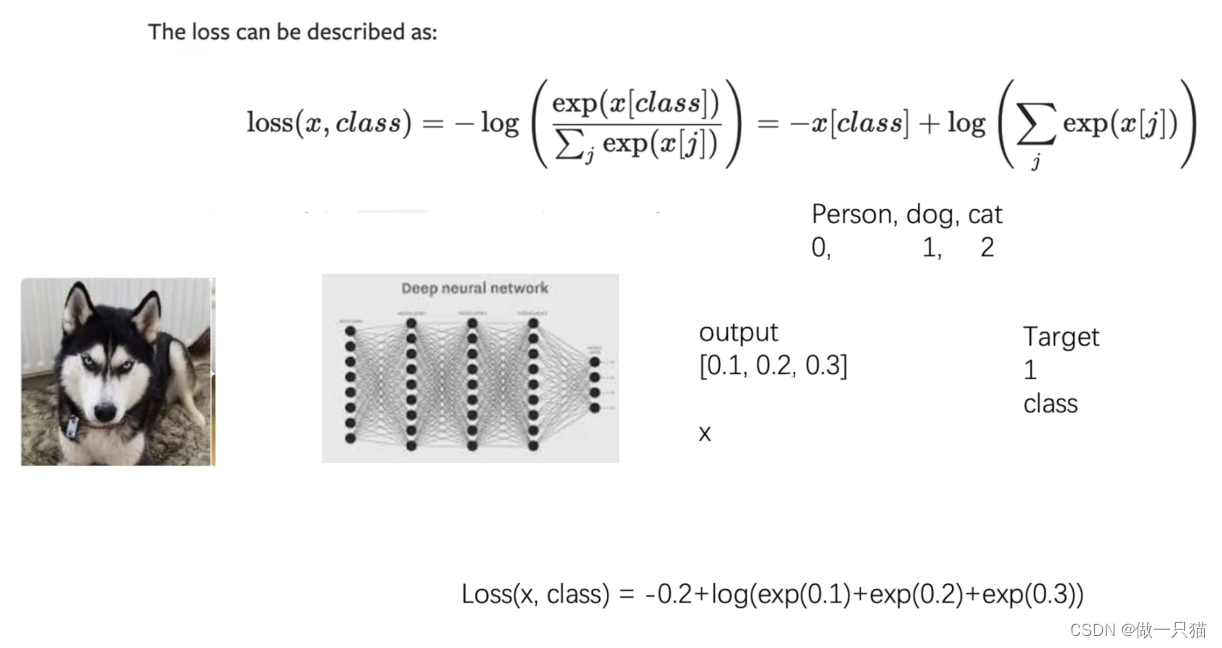
exp(i)就是e的i次方,e为2.7…
import torch
from torch.nn import L1Loss
from torch import nnx = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3)) # 1的 batch_size,有三类
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x,y)
print(result_cross)
tensor(1.1019)
8.4 运用交叉熵损失函数计算误差,反向传播
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__() self.model1 = Sequential(Conv2d(3,32,5,padding=2),MaxPool2d(2),Conv2d(32,32,5,padding=2),MaxPool2d(2),Conv2d(32,64,5,padding=2),MaxPool2d(2),Flatten(),Linear(1024,64),Linear(64,10) # 这里最后输出的是1行10列向量,符合loss()函数的要求)def forward(self, x):x = self.model1(x)return xloss = nn.CrossEntropyLoss() # 交叉熵
tudui = Tudui()
for data in dataloader:imgs, targets = dataoutputs = tudui(imgs)result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距print(result_loss)# 反向传播result_loss.backward() # 计算出来的 loss 值有 backward 方法属性,反向传播来计算每个节点的更新的参数。这里查看网络的属性 grad 梯度属性刚开始没有,反向传播计算出来后才有,后面优化器会利用梯度优化网络参数。 print("ok")
9 优化器 TORCH.OPTIM
TORCH.OPTIM
注: 这里我用了numpy-1.19.2版本报错,在anaconda中卸了后重装numpy就解决了问题(这里anaconda自动帮我安装了numpy-1.19.5)
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64, drop_last=True)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return xloss = nn.CrossEntropyLoss() # 交叉熵
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01) # 随机梯度下降优化器 lr为learning rate 即学习率# 一轮优化
#for data in dataloader:
# imgs, targets = data
# outputs = tudui(imgs)
# result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距
# optim.zero_grad() # 梯度清零 使用反向传播算法进行模型训练时,需要在每个训练批次之前将之前计算的梯度清零,以避免梯度累积影响下一次的参数更新
# result_loss.backward()
# optim.step()
# print(result_loss) # 查看一轮优化后的损失变化# 优化20轮
for epoch in range(20):running_loss = 0.0for data in dataloader:imgs, targets = dataoutputs = tudui(imgs)result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距optim.zero_grad() # 梯度清零result_loss.backward() # 反向传播,计算损失函数的梯度optim.step() # 根据梯度,对网络的参数进行调优running_loss = running_loss + result_lossprint(running_loss) # 每轮误差的总和
Debug:
如下图打上三个断点,并开始debug

向下运行两行代码(即40、41行),grad由none变化,出现参数
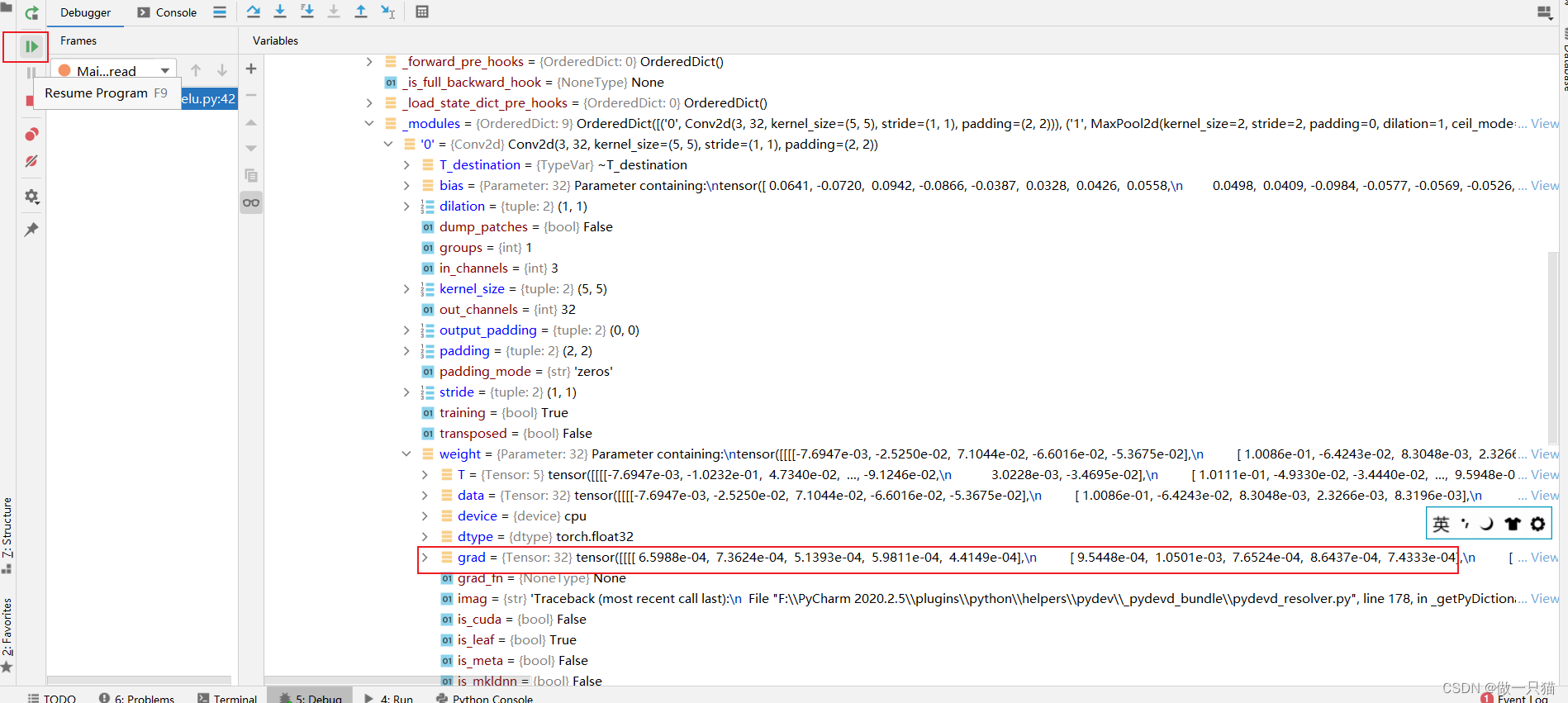
再向下运行一行代码(即42行代码)观察data变化
10 现有网络模型的使用及修改
10.1 载入模型
这里以vgg16模型为例,它是以ImageNet数据集进行训练得到的,但是该数据集无法通过Pycharm直接访问下载,而需要另外在网上下载数据集,并且数据集很大(140G),故这里不作下载,仅演示模型修改
import torchvision#trauin_data = torchvision.datasets.ImageNet("./dataset",split="train",download=True,transform=torchvision.transforms.ToTensor()) # 这个数据集无法公开访问
vgg16_true = torchvision.models.vgg16(pretrained=True) # pretrained 参数是用于控制是否加载预训练权重的参数 为true则会下载卷积层对应的参数是、池化层对应的参数等等,这些参数是利用ImageNet数据集预先训练得到的
vgg16_false = torchvision.models.vgg16(pretrained=False) # 没有预训练的参数
print("ok")
print(vgg16_true)
输出:
ok
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
10.2 按需修改模型
import torchvision
from torch import nndataset = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
vgg16_true = torchvision.models.vgg16(pretrained=True)# CIFAR10需要输出10个种类,需对模型进行修改以适应需求
# 方法1 :在VGG16后面添加一个线性层
vgg16_true.add_module('add_linear',nn.Linear(1000,10))
print(vgg16_true)# 方法2:直接修改VGG16的最后一个线性层
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096,10)
print(vgg16_false)
11 网络模型的保存与读取
11.1 保存模型
# model_save.py
# 保存方式1:保存网络模型结构
import torchvision
import torch
vgg16 = torchvision.models.vgg16(pretrained=False)
torch.save(vgg16,"vgg16_method1.pth")
print(vgg16)# 保存方式2:模型参数(官方推荐),保存参数为字典类型
import torchvision
import torch
vgg16 = torchvision.models.vgg16(pretrained=False)
torch.save(vgg16.state_dict(),"vgg16_method2.pth") #
print(vgg16)11.2 读取
# model_load.py
# 读取方式1:对应保存方式1
import torch
model1 = torch.load("vgg16_method1.pth")
print(model1)# 取方式2:对应保存方式2
model2 = torchvision.models.vgg16(pretrained=False)
model2.load_state_dict(torch.load("vgg16_method2.pth"))
print(model2)
11.3 保存方式1存在陷阱
# save.py
import torchclass Tudui(nn.Module):def __init__(self):super(Tudui,self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3)def forward(self,x):x = self.conv1(x)return xtudui = Tudui()
torch.save(tudui, "tudui_method1.pth")
# load.py
import torch
model = torch.load("./model/tudui_method1.pth") # 无法直接取方式一保存的网络结构
print(model)
load.py 需要作如下修改:
# load.py
# 修改1:from save.py import *
# 修改2:引入save.py中的类,而不需要实例化
class Tudui(nn.Module):def __init__(self):super(Tudui,self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3)def forward(self,x):x = self.conv1(x)return xmodel = torch.load("./model/tudui_method1.pth")
print(model)
12 完整的模型训练套路
12.1 CIFAR 10 model 网络模型
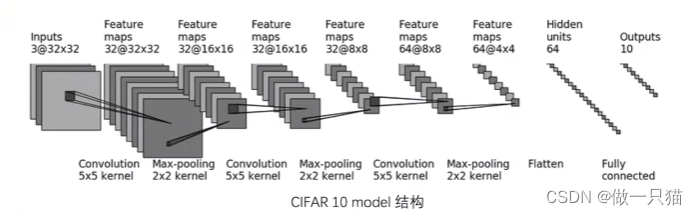
12.1 model.py
import torch
from torch import nn# 搭建神经网络
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__() self.model1 = nn.Sequential(nn.Conv2d(3,32,5,1,2), # 输入通道3,输出通道32,卷积核尺寸5×5,步长1,填充2 nn.MaxPool2d(2),nn.Conv2d(32,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(), # 展平后变成 64*4*4 了nn.Linear(64*4*4,64),nn.Linear(64,10))def forward(self, x):x = self.model1(x)return xif __name__ == '__main__':tudui = Tudui()input = torch.ones((64,3,32,32))output = tudui(input)print(output.shape) # 测试输出的尺寸是否符合需求
12.2 train.py
(1)item的作用
import torch
a = torch.tensor(5)
print(a)
print(a.item())
tensor(5)
5
(2)argmax()
import torch
outputs = torch.tensor([[0.1, 0.2],[0.05, 0.4]])
print(outputs.argmax(0)) # 返回纵向 每一列最大值的索引
print(outputs.argmax(1)) # 返回横向 每一行最大值的索引
preds = outputs.argmax(1)
targets = torch.tensor([0,1])
print((preds == targets) # 对应位置是否相等,相等则返回true
print((preds == targets).sum()) # 对应位置相等的个数
tensor([0, 1])
tensor([1, 1])
tensor([false, true])
tensor(1)
(3)tudui.train()和tudui.eval() :分别用于训练步骤和测试步骤,只对特定层起作用,本代码非必要
(4)完整代码
import torch
import torchvision
from model import *
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 1 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,则打印:训练数据集的长度为:10
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))# 2 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 3 创建网络模型
tudui = Tudui()# 4 损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵,fn 是 fuction 的缩写# 5 优化器
learning_rate = 1e-2 # 1e-2 = 1 * (10)^(-2) = 1 / 100 = 0.01
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate ) # 随机梯度下降优化器# 6 设置网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0# 训练的轮次
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")for i in range(epoch):print("-----第 {} 轮训练开始-----".format(i + 1))# 7 训练步骤开始# tudui.train() # 当网络中有dropout层、batchnorm等层时才起作用,本代码非必要for data in train_dataloader:imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets)# 优化器对模型调优optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播,计算损失函数的梯度optimizer.step() # 根据梯度,对网络的参数进行调优total_train_step = total_train_step + 1if total_train_step % 100 == 0:# print("训练次数:{},Loss:{}".format(total_train_step,loss)) # 方式1:获得无tensor的loss值print("训练次数:{},Loss:{}".format(total_train_step, loss.item())) # 方式2:获得loss数字值writer.add_scalar("train_loss", loss.item(), total_train_step)# 8 测试步骤开始(每一轮训练后都查看在测试数据集上的loss情况)# tudui.eval() # 当网络中有dropout层、batchnorm等层时才起作用,本代码非必要total_test_loss = 0 # 测试集总损失total_accuracy = 0 # 准确度with torch.no_grad(): # 测试无需梯度计算,节约内存for data in test_dataloader: # 测试数据集提取数据imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets) # 仅data数据在网络模型上的损失total_test_loss = total_test_loss + loss.item() # 所有lossaccuracy = (outputs.argmax(1) == targets).sum() # 准确度total_accuracy = total_accuracy + accuracy # 准确度总和print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1# 9 保存模型
torch.save(tudui, "./model/tudui_{}.pth".format(i)) # 保存每一轮训练后的结果
print("模型已保存")writer.close()
13 利用GPU训练
13.1 利用电脑显卡训练
找到 网络模型,数据(输入、标注),损失函数
加上.cuda(),下☆代码
同时增加time,以查看运行时间
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time # ☆class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model1 = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(), # 展平后变成 64*4*4 了nn.Linear(64 * 4 * 4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model1(x)return x# 1 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,则打印:训练数据集的长度为:10
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))# 2 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 3 创建网络模型
tudui = Tudui()
#if torch.cuda.is_available():
tudui = tudui.cuda() # ☆ 网络模型转移到cuda上# 4 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():loss_fn = loss_fn.cuda() # ☆ 损失函数转移到cuda上# 5 优化器
learning = 0.01 # 1e-2 就是 0.01 的意思
optimizer = torch.optim.SGD(tudui.parameters(), learning)# 6 设置网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮次
epoch = 10# 添加 tensorboard
writer = SummaryWriter("logs")
start_time = time.time() # ☆for i in range(epoch):print("-----第 {} 轮训练开始-----".format(i + 1))# 7 训练步骤开始tudui.train()for data in train_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs = imgs.cuda() # ☆ 数据放到cuda上targets = targets.cuda() # ☆ 数据放到cuda上outputs = tudui(imgs)loss = loss_fn(outputs, targets) # 计算实际输出与目标输出的差距# 优化器对模型调优optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:end_time = time.time() # ☆print(end_time - start_time) # ☆ 运行训练一百次后的时间间隔print("训练次数:{},Loss:{}".format(total_train_step, loss.item())) #writer.add_scalar("train_loss", loss.item(), total_train_step)# 8 测试步骤开始(每一轮训练后都查看在测试数据集上的loss情况)tudui.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs = imgs.cuda() # ☆ 数据放到cuda上targets = targets.cuda() # ☆ 数据放到cuda上outputs = tudui(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item() # 所有lossaccuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)total_test_step = total_test_step + 1torch.save(tudui, "./model/tudui_{}.pth".format(i))# torch.save(tudui.state_dict(),"tudui_{}.path".format(i)) # 保存方式二print("模型已保存")writer.close()
13.2 利用google colab训练
google colab
需要谷歌账号,每周免费30h,具体使用流程可以上网搜,或者看小土堆p30 10min处
13.3 选择GPU0 / 1 训练
删除cuda代码,增加.to(),即带☆的代码
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time# 定义训练的设备
#device = torch.device("cpu") # ☆
#device = torch.device("cuda") # ☆ 使用 GPU 方式一
#device = torch.device("cuda:0") # ☆ 使用 GPU 方式二,作用同上
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # ☆class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__() self.model1 = nn.Sequential(nn.Conv2d(3,32,5,1,2), nn.MaxPool2d(2),nn.Conv2d(32,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(), nn.Linear(64*4*4,64),nn.Linear(64,10))def forward(self, x):x = self.model1(x)return x# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True) # length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))# 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 创建网络模型
tudui = Tudui()
tudui = tudui.to(device) # ☆ 也可以不赋值,直接 tudui.to(device) # 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device) # ☆ 也可以不赋值,直接loss_fn.to(device)
# 优化器
learning = 0.01 # 1e-2 就是 0.01 的意思
optimizer = torch.optim.SGD(tudui.parameters(),learning) # 设置网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0# 训练的轮次
epoch = 10# 添加 tensorboard
writer = SummaryWriter("logs")
start_time = time.time()for i in range(epoch):print("-----第 {} 轮训练开始-----".format(i+1))# 训练步骤开始tudui.train() for data in train_dataloader:imgs, targets = data imgs = imgs.to(device) # ☆ 也可以不赋值,直接 imgs.to(device) targets = targets.to(device) # ☆ 也可以不赋值,直接 targets.to(device)outputs = tudui(imgs)loss = loss_fn(outputs, targets)# 优化器对模型调优optimizer.zero_grad() loss.backward() optimizer.step() total_train_step = total_train_step + 1if total_train_step % 100 == 0:end_time = time.time()print(end_time - start_time)print("训练次数:{},Loss:{}".format(total_train_step,loss.item())) writer.add_scalar("train_loss",loss.item(),total_train_step)# 测试步骤开始(每一轮训练后都查看在测试数据集上的loss情况)tudui.eval() total_test_loss = 0total_accuracy = 0with torch.no_grad(): for data in test_dataloader: imgs, targets = data imgs = imgs.to(device) # ☆ 也可以不赋值,直接 imgs.to(device)targets = targets.to(device) # ☆ 也可以不赋值,直接 targets.to(device)outputs = tudui(imgs)loss = loss_fn(outputs, targets) total_test_loss = total_test_loss + loss.item() # 所有lossaccuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step) total_test_step = total_test_step + 1torch.save(tudui, "./model/tudui_{}.pth".format(i))#torch.save(tudui.state_dict(),"tudui_{}.path".format(i)) print("模型已保存")writer.close()
14 完整的模型验证套路
14.1 训练30轮的模型
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time# 定义训练的设备
#device = torch.device("cpu")
device = torch.device("cuda") # 使用 GPU 方式一
#device = torch.device("cuda:0") # 使用 GPU 方式二
#device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# from model import * 相当于把 model中的所有内容写到这里,这里直接把 model 写在这里
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__() self.model1 = nn.Sequential(nn.Conv2d(3,32,5,1,2), # 输入通道3,输出通道32,卷积核尺寸5×5,步长1,填充2 nn.MaxPool2d(2),nn.Conv2d(32,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(), # 展平后变成 64*4*4 了nn.Linear(64*4*4,64),nn.Linear(64,10))def forward(self, x):x = self.model1(x)return x# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True) # length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,则打印:训练数据集的长度为:10
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))# 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 创建网络模型
tudui = Tudui()
tudui = tudui.to(device) # 也可以不赋值,直接 tudui.to(device) # 损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵,fn 是 fuction 的缩写
loss_fn = loss_fn.to(device) # 也可以不赋值,直接loss_fn.to(device)# 优化器
learning = 0.01 # 1e-2 就是 0.01 的意思
optimizer = torch.optim.SGD(tudui.parameters(),learning) # 随机梯度下降优化器 # 设置网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0# 训练的轮次
epoch = 30# 添加 tensorboard
writer = SummaryWriter("logs")
start_time = time.time()for i in range(epoch):print("-----第 {} 轮训练开始-----".format(i+1))# 训练步骤开始tudui.train() # 当网络中有dropout层、batchnorm层时,这些层能起作用for data in train_dataloader:imgs, targets = data imgs = imgs.to(device) # 也可以不赋值,直接 imgs.to(device)targets = targets.to(device) # 也可以不赋值,直接 targets.to(device)outputs = tudui(imgs)loss = loss_fn(outputs, targets) # 计算实际输出与目标输出的差距# 优化器对模型调优optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播,计算损失函数的梯度optimizer.step() # 根据梯度,对网络的参数进行调优total_train_step = total_train_step + 1if total_train_step % 100 == 0:end_time = time.time()print(end_time - start_time) # 运行训练一百次后的时间间隔print("训练次数:{},Loss:{}".format(total_train_step,loss.item())) # 方式二:获得loss值writer.add_scalar("train_loss",loss.item(),total_train_step)# 测试步骤开始(每一轮训练后都查看在测试数据集上的loss情况)tudui.eval() # 当网络中有dropout层、batchnorm层时,这些层不能起作用total_test_loss = 0total_accuracy = 0with torch.no_grad(): # 没有梯度了for data in test_dataloader: # 测试数据集提取数据imgs, targets = data # 数据放到cuda上imgs = imgs.to(device) # 也可以不赋值,直接 imgs.to(device)targets = targets.to(device) # 也可以不赋值,直接 targets.to(device)outputs = tudui(imgs)loss = loss_fn(outputs, targets) # 仅data数据在网络模型上的损失total_test_loss = total_test_loss + loss.item() # 所有lossaccuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step) total_test_step = total_test_step + 1torch.save(tudui, "./model/tudui_{}.pth".format(i)) # 保存每一轮训练后的结果#torch.save(tudui.state_dict(),"tudui_{}.path".format(i)) # 保存方式二 print("模型已保存")writer.close()
14.2 验证狗是否能够识别
从网上下载一张dog图片,进行验证
import torchvision
from PIL import Image
from torch import nn
import torchimage_path = "imgs/dog.png"
image = Image.open(image_path) # PIL类型的Image
image = image.convert("RGB") # 4通道的RGBA转为3通道的RGB图片
print(image)transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)), torchvision.transforms.ToTensor()])image = transform(image)
print(image.shape)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__() self.model1 = nn.Sequential(nn.Conv2d(3,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4,64),nn.Linear(64,10))def forward(self, x):x = self.model1(x)return xmodel = torch.load("model/tudui_29.pth",map_location=torch.device('cpu')) # 将GPU上训练的模型映射到CPU上
print(model)
image = torch.reshape(image,(1,3,32,32)) # 转为四维,符合网络输入需求
model.eval()
with torch.no_grad(): # 不进行梯度计算,减少内存计算output = model(image)
output = model(image)
print(output)
print(output.argmax(1)) # 概率最大类别的输出
14.3 验证飞机是否能够识别
同样找张plane图片进行验证
import torchvision
from PIL import Image
from torch import nn
import torchimage_path = "imgs/plane.png"
image = Image.open(image_path) # PIL类型的Image
image = image.convert("RGB") # 4通道的RGBA转为3通道的RGB图片
print(image)transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)), torchvision.transforms.ToTensor()])image = transform(image)
print(image.shape)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__() self.model1 = nn.Sequential(nn.Conv2d(3,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4,64),nn.Linear(64,10))def forward(self, x):x = self.model1(x)return xmodel = torch.load("model/tudui_29.pth",map_location=torch.device('cpu')) # GPU上训练的东西映射到CPU上
print(model)
image = torch.reshape(image,(1,3,32,32)) # 转为四维,符合网络输入需求
model.eval()
with torch.no_grad(): # 不进行梯度计算,减少内存计算output = model(image)
output = model(image)
print(output)
print(output.argmax(1)) # 概率最大类别的输出
15 查看开源项目
github 搜 Pytorch,选择start最多的
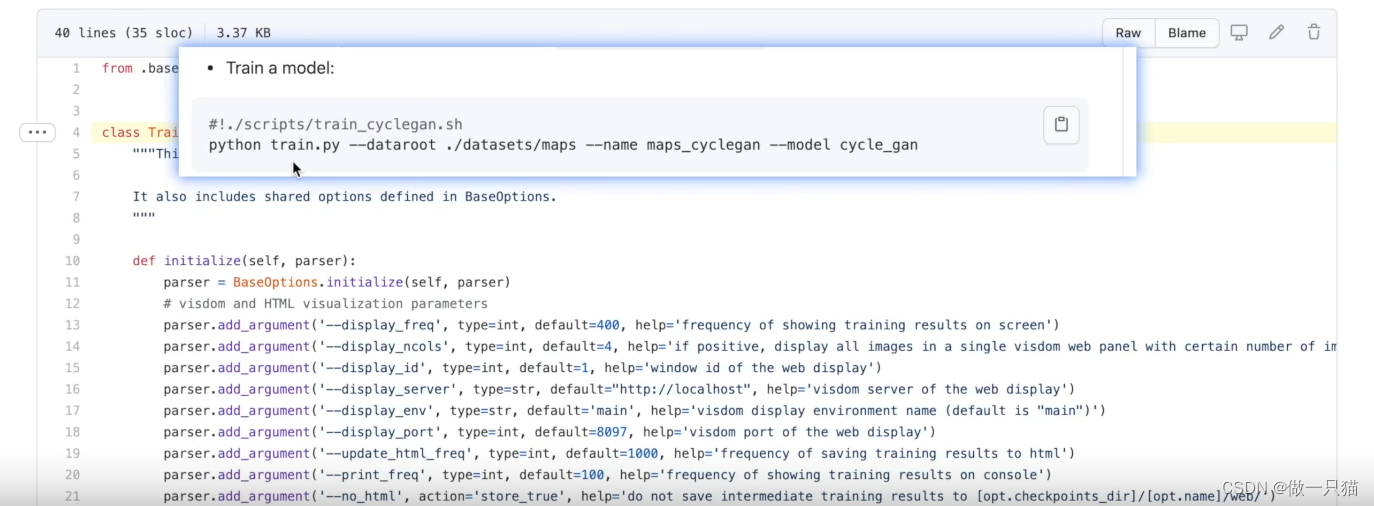
① 像运行Tensorboar一样,在Terminal终端,可以命令运行.py文件
② 如下图所示,Terminal终端运行.py文件时,–变量 后面的值是给变量进行赋值,赋值后再在.py文件中运行。例如 ./datasets/maps 是给前面的dataroot赋值,maps_cyclegan是给前面的name赋值,cycle_gan是给前面的model赋值
③ required表示必须需要指定参数,default表示有默认的参数了。Terminal终端命令语句,如果不对该默认变量新写入,直接调用默认的参数;如果对该默认变量新写入,则默认的参数被新写入的参数覆盖
)








)




-输入捕获模式测量脉冲)


)

