在生成人工智能领域工作最有价值的事情之一就是发现新兴技术如何融入新的解决方案。 举个例子:在为北美顶级金融服务公司之一设计对话式人工智能助手时,WillowTree 的数据和人工智能研究团队 (DART) 发现,将意图分类与大型语言模型 (LLM) 结合使用可以提高性能, 安全性和成本。
我们将意图分类和LLM与检索增强生成(RAG)系统的这种交织视为“部分意图分类”。 这种实践及其背后的故事表明,对于人工智能专业人士来说,创造性地思考并不断尝试新的解决方案是多么重要。
毕竟,像 GPT-4 这样强大的 LLM 以及 RAG 系统的开发使开发人员能够创建比依赖传统技术的聊天机器人功能更强大、更自给自足的聊天机器人。 然而,这些新模式和方法仍然存在风险。 它们可能会产生无信息或错误的输出(即人工智能幻觉),或者可能容易被越狱(即利用漏洞生成超出道德界限的内容)。
鉴于对答案可靠性和模型安全性的担忧仍然是业务和技术领导者最关心的问题,我们提出部分意图分类作为这些问题的缓解策略。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包
1、为什么我们转向意图分类
意图映射(intent mapping)使聊天机器人能够对符合特定用户意图的用户提示提供确定性的、精心策划的响应。 这样做为我们提供了对这些通常不可预测的系统的另一种控制手段。 这些用户意图通常涵盖常见问题 (FAQ)。
但意图分类(intent classification)还可以检测恶意或偏离主题的行为——旨在越狱系统或使其脱离其认可主题的提示。 因此,通过引入确定性用例识别,我们创建了针对越狱尝试的强大防御前线。
此外,意图分类还可以通过减少延迟和成本来提高聊天机器人的性能。 这是因为意图分类器仅依赖于提示的嵌入和轻量级模型,而不依赖于任何 LLM 完成。
2、将意图分类应用于金融服务AI助手
为了支持意图分类系统,我们首先需要一组通用意图。 我们可以像生成一组网页常见问题解答一样生成这些内容,甚至可以直接从现有的常见问题解答集合中提取它们。 这个想法是在你的意图集中捕获一组常见的用户提示。 为每个意图生成多个示例是必要的,这样你的模型就有足够的示例可供训练和测试。 考虑相同用户意图的这些变化:
- “我如何对信用卡收费提出异议?”
- “我最近的信用卡对账单上有可疑活动。”
- “我不承认信用卡购买。 我应该怎么办?”
这些意图中的每一个都需要在输入中识别出该意图时返回预定的输出。 在我们的例子中,我们通过检查嵌入的几何可分离性的验证来开始意图分类的实验。
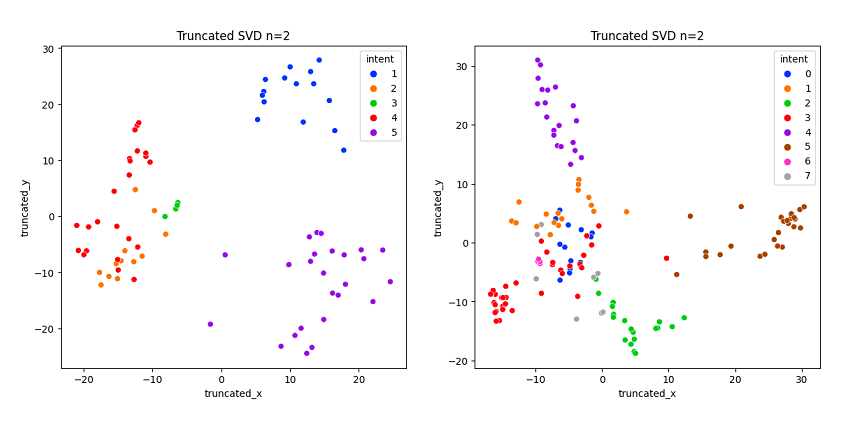
具有五个意图类别(左)和七个意图类别(右)的嵌入的截断 SVD 聚类的比较。 虽然左图显示类别的几何可分离性通常很强,但右图显示,随着添加更多类别,类别在缩小的空间中不易分离。
将 K 均值聚类与奇异值分解 (SVD) 和 t 分布随机邻域嵌入 (t-SNE) 聚类进行比较后,结果表明使用 K 最近邻 (KNN) 模型对原始 1,536 个数据进行分类 维度嵌入可能是有效的。 虽然最初的试验表现出很强的用户意图分类准确性,但重点不仅仅是每次都准确的意图映射。 意图分类器还必须处理不符合给定意图列表的提示。 这些可能是以下提示:
- 应导致 RAG
- 尝试越狱系统
- 尝试将聊天机器人拉出范围
为了使分类器能够处理未将所需意图与策划响应进行映射的提示,除了初始意图集之外,我们还必须创建新的类别:超出范围、越狱以及相关但非意图的提示。 我们不希望我们的聊天机器人处理超出范围和越狱的提示。 从现在起,我们将它们称为“不回答”提示,因为我们不希望聊天机器人回答它们。
至于相关但非意图的提示,这些属于我们的聊天机器人的权限范围,但不符合我们的意图类别。 这些提示应通过聊天机器人架构的其余部分发送,以便通过 RAG 进行答复。 根据这些新类别,我们将原始意图集称为“范围内”意图。
3、针对更大的意图类别进行调整
随着类别的增加,意图分类的准确性下降了。 此外,还提出了超出准确性的考虑因素。 现在,我们需要将不准确的分类分成几个不同的类别,每个类别都有自己的一组后果。 最重要的是,对训练集大小的考虑变得很重要。 更大的训练集可确保更多地覆盖每个意图、相关提示和非答案提示。
当然,完全覆盖是不可能的,并且增加训练集的规模会带来收益递减。 除了生成更多示例的成本和时间之外,增加用于检查用户提示的提示数量也会增加意图分类器的延迟和成本,这是我们想要改进的两个关键痛点。
4、基于启发式的系统增强了信心
在使用这组更加多样化的类别测试 KNN 时,我们发现在某些情况下,适合一个范围内意图的提示被错误地分类为另一个范围内意图,或者相关提示被分类为范围内意图。 还有一些非回答提示被归类为相关提示。 我们解决这些问题的方法是通过两种启发式方法修改分类器。
第一个启发式是模型对给定意图的预测的信心。 如果 KNN 预测提示与我们范围内的意图之一匹配,我们将计算 k 个最近邻与预测意图标签的余弦相似度之和。 这种方法试图测量提示与嵌入空间中预测意图的“接近度”。 如果确定提示足够接近(即,启发式值超过某个预定阈值),意图分类器将返回 KNN 的预测。 否则,预测将被忽略,提示将触发 RAG。
请注意,将其中一些发送到 RAG 会降低范围内意图被正确分类的百分比。 但它也减少了被错误分类为范围内意图的提示的百分比以及被错误分类为错误范围内意图的范围内意图的数量。
第二个启发式衡量模型对提示是非答案提示的置信度。 类似地,该启发式等于标记为非答案提示的 k 个最近邻居的余弦相似度之和。 如果此启发式高于某个阈值,则提示被归类为无答案,并且聊天机器人将返回预定响应,拒绝与用户的提示互动。
这种启发式方法并不需要一定程度的置信度来拒绝提示。 相反,它会拒绝任何会引起一定程度的确信它是非答案提示的提示。
5、仔细观察启发式的影响
下图中的彩色标签仅基于 KNN (k=5) 预测,未考虑阈值。 该图演示了阈值的用途。 例如,粉色和橙色点都是根据 KNN 错误映射到范围内意图的提示。 但如果我们合并显示的阈值,所有这些点都将被发送到 RAG,而不是返回错误的确定性响应。

阈值左侧的蓝点是正确分类的意图,它们也会发送到 RAG,但这只是我们对阈值所做的权衡。 我们还可以看到,我们的意图分类器会拒绝略高于拒绝阈值的紫色点,这将阻止我们的机器人回答这些不需要的提示。
6、精确率-召回率曲线帮助我们优化权衡
平衡上面讨论的权衡对于确定这些启发法的阈值或是否完全使用不同的阈值至关重要。 从最大化准确性的角度思考可能不是最好的方法。 向 RAG 发送真实的意图提示(无论如何它都可能收到足够的响应)以及对实际上并未引发该响应的提示给出预先设定的响应会产生不同的后果。
此外,将范围内的提示分类为越狱尝试并拒绝回答与由于意图分类器错过了而通过系统的其余部分发送越狱提示相比,会产生不同的后果。 通过精确率-召回率曲线可以最好地理解这些权衡。
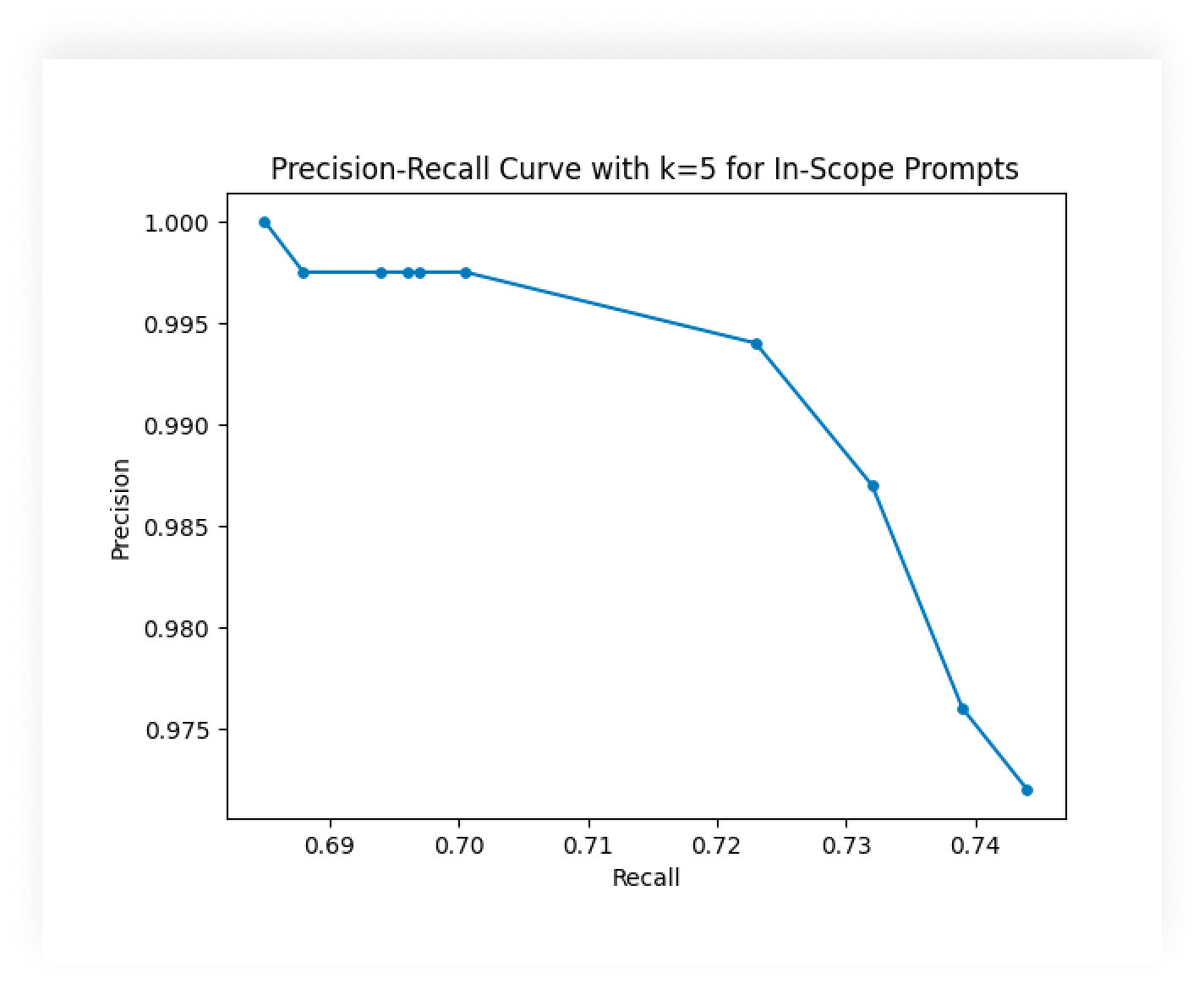
该图是精确召回曲线的示例。 每个点对应于范围内意图启发式的特定阈值。 这演示了如何降低阈值以增加发现的真实范围内意图的百分比,同时也会降低分类为正确的提示的百分比。
准确率,也称为真阳性率 (TPR),是正确分类的所有真实意图(或越狱/超出范围)提示的百分比。 召回率是被分类为意图(或越狱/超出范围)的所有提示中被正确分类的百分比。 这些需要单独查看意图和越狱/超出范围,因为它们依赖于不同的启发式。
在每种情况下,增加阈值都会导致更少的提示被分类为意图或越狱/超出范围。 此过程将导致精度降低,因为由于阈值较低,更真实的意图提示或真正的越狱/范围外提示将不会被分类。
然而,增加阈值也可能会增加分类器的召回率。 在意图阈值的情况下,需要更高的置信度才能将提示分类为意图。 因此,分类为意图的提示应该更准确,这就是召回率所衡量的。
转向越狱/超出范围阈值的情况,增加它将导致更高的置信度阈值,以自动将提示分类为越狱/超出范围提示。 从理论上讲,这应该会减少错误分类的提示数量。
7、寻找正确的AI解决方案需要一个团队
尽管生成式人工智能仅在过去一年就取得了巨大进步,但依赖生成式人工智能的聊天机器人仍然存在不可预测的因素。 如果你的对话式人工智能助手必须以敏感或精确的公司批准的方式处理一组特定的用户意图,那么部分意图分类是一个值得考虑的强大工具。
原文链接:部分意图分类 - BimAnt


)



)












)